Migrate data from Cassandra to an Azure Cosmos DB for Apache Cassandra account by using Azure Databricks
APPLIES TO:
![]() Cassandra
Cassandra
API for Cassandra in Azure Cosmos DB has become a great choice for enterprise workloads running on Apache Cassandra for several reasons:
No overhead of managing and monitoring: It eliminates the overhead of managing and monitoring settings across OS, JVM, and YAML files and their interactions.
Significant cost savings: You can save costs with the Azure Cosmos DB, which includes the cost of VMs, bandwidth, and any applicable licenses. You don't have to manage datacenters, servers, SSD storage, networking, and electricity costs.
Ability to use existing code and tools: The Azure Cosmos DB provides wire protocol-level compatibility with existing Cassandra SDKs and tools. This compatibility ensures that you can use your existing codebase with the Azure Cosmos DB for Apache Cassandra with trivial changes.
There are many ways to migrate database workloads from one platform to another. Azure Databricks is a platform as a service (PaaS) offering for Apache Spark that offers a way to perform offline migrations on a large scale. This article describes the steps required to migrate data from native Apache Cassandra keyspaces and tables into the Azure Cosmos DB for Apache Cassandra by using Azure Databricks.
Prerequisites
Review the basics of connecting to an Azure Cosmos DB for Apache Cassandra.
Review the supported features in the Azure Cosmos DB for Apache Cassandra to ensure compatibility.
Ensure you've already created empty keyspaces and tables in your target Azure Cosmos DB for Apache Cassandra account.
Provision an Azure Databricks cluster
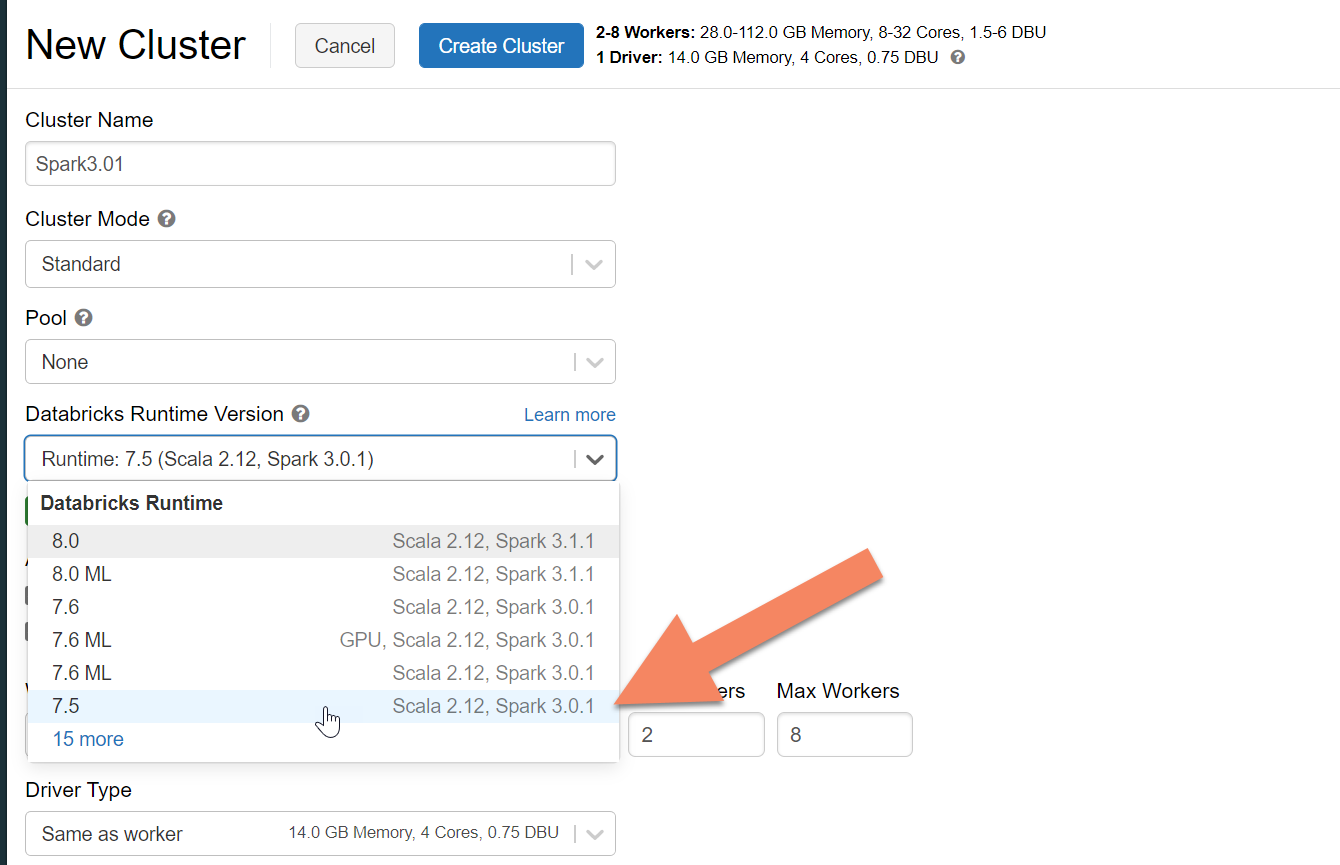
You can follow instructions to provision an Azure Databricks cluster. We recommend selecting Databricks runtime version 7.5, which supports Spark 3.0.
Add dependencies
You need to add the Apache Spark Cassandra Connector library to your cluster to connect to both native and Azure Cosmos DB Cassandra endpoints. In your cluster, select Libraries > Install New > Maven, and then add com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 in Maven coordinates.
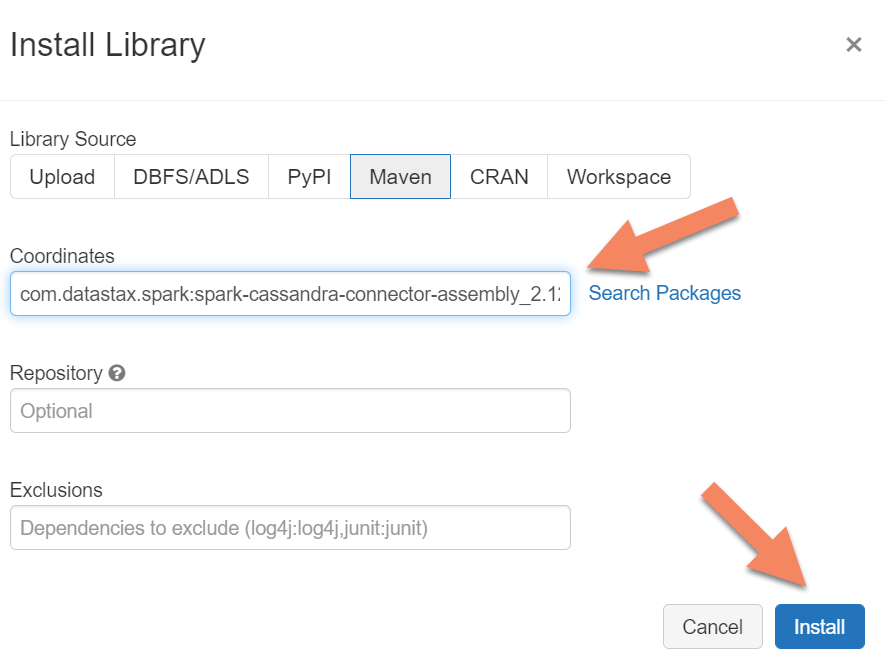
Select Install, and then restart the cluster when installation is complete.
Note
Make sure that you restart the Databricks cluster after the Cassandra Connector library has been installed.
Warning
The samples shown in this article have been tested with Spark version 3.0.1 and the corresponding Cassandra Spark Connector com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0. Later versions of Spark and/or the Cassandra connector may not function as expected.
Create Scala Notebook for migration
Create a Scala Notebook in Databricks. Replace your source and target Cassandra configurations with the corresponding credentials, and source and target keyspaces and tables. Then run the following code:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Note
The spark.cassandra.output.batch.size.rows and spark.cassandra.output.concurrent.writes values and the number of workers in your Spark cluster are important configurations to tune in order to avoid rate limiting. Rate limiting happens when requests to Azure Cosmos DB exceed provisioned throughput or request units (RUs). You might need to adjust these settings, depending on the number of executors in the Spark cluster and potentially the size (and therefore RU cost) of each record being written to the target tables.
Troubleshoot
Rate limiting (429 error)
You might see a 429 error code or "request rate is large" error text even if you reduced settings to their minimum values. The following scenarios can cause rate limiting:
Throughput allocated to the table is less than 6,000 request units. Even at minimum settings, Spark can write at a rate of around 6,000 request units or more. If you have provisioned a table in a keyspace with shared throughput, it's possible that this table has fewer than 6,000 RUs available at runtime.
Ensure that the table you are migrating to has at least 6,000 RUs available when you run the migration. If necessary, allocate dedicated request units to that table.
Excessive data skew with large data volume. If you have a large amount of data to migrate into a given table but have a significant skew in the data (that is, a large number of records being written for the same partition key value), then you might still experience rate limiting even if you have several request units provisioned in your table. Request units are divided equally among physical partitions, and heavy data skew can cause a bottleneck of requests to a single partition.
In this scenario, reduce to minimal throughput settings in Spark and force the migration to run slowly. This scenario can be more common when you're migrating reference or control tables, where access is less frequent and skew can be high. However, if a significant skew is present in any other type of table, you might want to review your data model to avoid hot partition issues for your workload during steady-state operations.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for