Azure Digital Twins data history (with Azure Data Explorer)
Data history is an integration feature of Azure Digital Twins. It allows you to connect an Azure Digital Twins instance to an Azure Data Explorer cluster so that graph updates are automatically historized to Azure Data Explorer. These historized updates include twin property updates, twin lifecycle events, and relationship lifecycle events.
Once graph updates are historized to Azure Data Explorer, you can run joint queries using the Azure Digital Twins plugin for Azure Data Explorer to reason across digital twins, their relationships, and time series data. This can be used to look back in time at what the state of the graph used to be, or to gain insights into the behavior of modeled environments. You can also use these queries to power operational dashboards, enrich 2D and 3D web applications, and drive immersive augmented/mixed reality experiences to convey the current and historical state of assets, processes, and people modeled in Azure Digital Twins.
For more of an introduction to data history, including a quick demo, watch the following IoT show video:
Messages emitted by data history are metered under the Message pricing dimension.
Prerequisites: Resources and permissions
Data history requires the following resources:
- Azure Digital Twins instance, with a system-assigned managed identity enabled.
- Event Hubs namespace containing an event hub.
- Azure Data Explorer cluster containing a database. The cluster must have public network access enabled.
These resources are connected into the following flow:
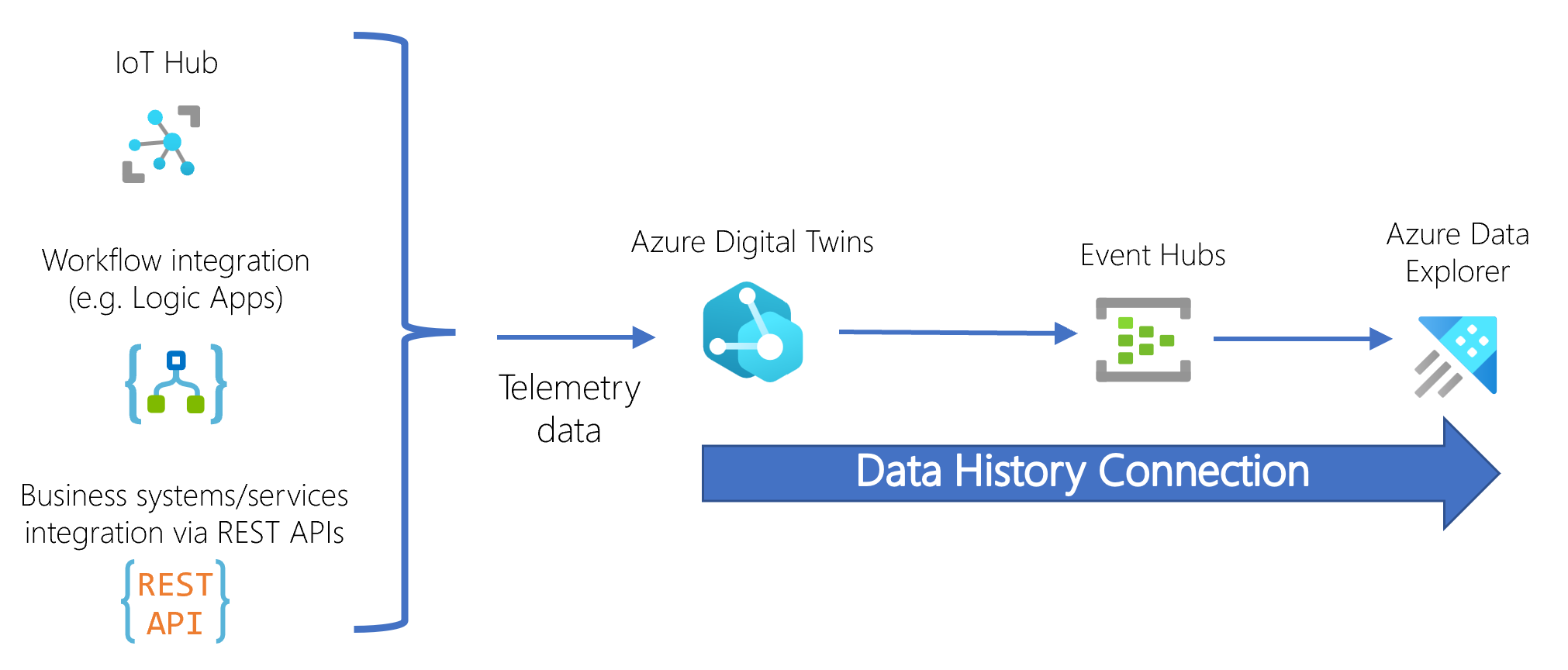
When the digital twin graph is updated, the information passes through the event hub into the target Azure Data Explorer cluster, where Azure Data Explorer stores the data as a timestamped record in the corresponding table.
When working with data history, it's recommended to use the 2023-01-31 version or later of the APIs. With the 2022-05-31 version, only twin properties (not twin lifecycle or relationship lifecycle events) can be historized. With earlier versions, data history is not available.
Required permissions
In order to set up a data history connection, your Azure Digital Twins instance must have the following permissions to access the Event Hubs and Azure Data Explorer resources. These roles enable Azure Digital Twins to configure the event hub and Azure Data Explorer database on your behalf (for example, creating a table in the database). These permissions can optionally be removed after data history is set up.
- Event Hubs resource: Azure Event Hubs Data Owner
- Azure Data Explorer cluster: Contributor (scoped to either the entire cluster or specific database)
- Azure Data Explorer database principal assignment: Admin (scoped to the database being used)
Later, your Azure Digital Twins instance must have the following permission on the Event Hubs resource while data history is being used: Azure Event Hubs Data Sender (you can also opt instead to keep Azure Event Hubs Data Owner from data history setup).
These permissions can be assigned using the Azure CLI or Azure portal.
If you'd like to restrict network access to the resources involved in data history (your Azure Digital Twins instance, event hub, or Azure Data Explorer cluster), you should set those restrictions after setting up the data history connection. For more information about this process, see Restrict network access to data history resources.
Create and manage data history connection
This section contains information for creating, updating, and deleting a data history connection.
Create a data history connection
Once all the resources and permissions are set up, you can use the Azure CLI, Azure portal, or the Azure Digital Twins SDK to create the data history connection between them. The CLI command set is az dt data-history.
The command will always create a table for historized twin property events, which can use the default name or a custom name that you provide. Twin property deletions can optionally be included in this table. You can also provide table names for relationship lifecycle events and twin lifecycle events, and the command will create tables with those names to historize those event types.
For step-by-step instructions on how to set up a data history connection, see Create a data history connection.
History from multiple Azure Digital Twins instances
If you'd like, you can have multiple Azure Digital Twins instances historize updates to the same Azure Data Explorer cluster.
Each Azure Digital Twins instance will have its own data history connection targeting the same Azure Data Explorer cluster. Within the cluster, instances can send their twin data to either...
- a separate set of tables in the Azure Data Explorer cluster.
- the same set of tables in the Azure Data Explorer cluster. To do this, specify the same Azure Data Explorer table names while creating the data history connections. In the data history table schemas, the
ServiceIdcolumn in each table will contain the URL of the source Azure Digital Twins instance, so you can use this field to resolve which Azure Digital Twins instance emitted each record in shared tables.
Update a properties-only data history connection
Prior to February 2023, the data history feature only historized twin property updates. If you have a properties-only data history connection from that time, you can update it to historize all graph updates to Azure Data Explorer (including twin properties, twin lifecycle events, and relationship lifecycle events).
This will require creating new tables in your Azure Data Explorer cluster for the new types of historized updates (twin lifecycle events and relationship lifecycle events). For twin property events, you can decide whether you want the new connection to continue using the same table from your original data history connection to store twin property updates going forward, or if you want the new connection to use an entirely new set of tables. Then, follow the instructions below for your preference.
If you want to continue using your existing table for twin property updates: Use the instructions in Create a data history connection to create a new data history connection with the new capabilities. The data history connection name can be the same as the original one, or a different name. Use the parameter options to provide new names for the two new event type tables, and to pass in the original table name for the twin property updates table. The new connection will override the old one, and continue to use the original table for future historized twin property updates.
If you want to use all new tables: First, delete your original data history connection. Then, use the instructions in Create a data history connection to create a new data history connection with the new capabilities. The data history connection name can be the same as the original one, or a different name. Use the parameter options to provide new names for all three event type tables.
Delete a data history connection
You can use the Azure CLI, Azure portal, or Azure Digital Twins APIs and SDKs to delete a data history connection. The CLI command is az dt data-history connection delete.
Deleting a connection also gives the option to clean up resources associated with the data history connection (for the CLI command, the optional parameter to add is --clean true). If you use this option, the command will delete the resources within Azure Data Explorer that are used to link your cluster to your event hub, including data connections for the database and the ingestion mappings associated with your table. The "clean up resources" option will not delete the actual event hub and Azure Data Explorer cluster used for the data history connection.
The cleanup is a best-effort attempt, and requires the account running the command to have delete permission for these resources.
Note
If you have multiple data history connections that share the same event hub or Azure Data Explorer cluster, using the "clean up resources" option while deleting one of these connections may disrupt your other data history connections that rely on these resources.
Data types and schemas
Data history historizes three types of events from your Azure Digital Twins instance into Azure Data Explorer: relationship lifecycle events, twin lifecycle events, and twin property updates (which can optionally include twin property deletions). Each of these event types is stored in its own table inside the Azure Data Explorer database, meaning data history keeps three tables total. You can specify custom names for the tables when you set up the data history connection.
The rest of this section describes the three Azure Data Explorer tables in detail, including the data schema for each table.
Twin property updates
The Azure Data Explorer table for twin property updates has a default name of AdtPropertyEvents. You can leave the default name when you're creating the connection, or specify a custom table name.
The time series data for twin property updates is stored with the following schema:
| Attribute | Type | Description |
|---|---|---|
TimeStamp |
DateTime | The date/time the property update message was processed by Azure Digital Twins. This field is set by the system and isn't writable by users. |
SourceTimeStamp |
DateTime | An optional, writable property representing the timestamp when the property update was observed in the real world. This property can only be written using the 2022-05-31 version of the Azure Digital Twins APIs/SDKs and the value must comply to ISO 8601 date and time format. For more information about how to update this property, see Update a property's sourceTime. |
ServiceId |
String | The service instance ID of the Azure IoT service logging the record |
Id |
String | The twin ID |
ModelId |
String | The DTDL model ID (DTMI) |
Key |
String | The name of the updated property |
Value |
Dynamic | The value of the updated property |
RelationshipId |
String | When a property defined on a relationship (as opposed to twins or devices) is updated, this field is populated with the ID of the relationship. When a twin property is updated, this field is empty. |
RelationshipTarget |
String | When a property defined on a relationship (as opposed to twins or devices) is updated, this field is populated with the twin ID of the twin targeted by the relationship. When a twin property is updated, this field is empty. |
Action |
String | This column only exists if you choose to historize property delete events. If so, this column contains the type of twin property event (update or delete) |
Below is an example table of twin property updates stored to Azure Data Explorer.
TimeStamp |
SourceTimeStamp |
ServiceId |
Id |
ModelId |
Key |
Value |
RelationshipTarget |
RelationshipID |
|---|---|---|---|---|---|---|---|---|
| 2022-12-15 20:23:29.8697482 | 2022-12-15 20:22:14.3854859 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 130 | ||
| 2022-12-15 20:23:39.3235925 | 2022-12-15 20:22:26.5837559 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 140 | ||
| 2022-12-15 20:23:47.078367 | 2022-12-15 20:22:34.9375957 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 130 | ||
| 2022-12-15 20:23:57.3794198 | 2022-12-15 20:22:50.1028562 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 123 |
Representing properties with multiple fields
You may need to store a property with multiple fields. These properties are represented with a JSON object in the Value attribute of the schema.
For instance, if you're representing a property with three fields for roll, pitch, and yaw, data history will store the following JSON object as the Value: {"roll": 20, "pitch": 15, "yaw": 45}.
Twin lifecycle events
The Azure Data Explorer table for twin lifecycle events has a custom name that you'll specify when creating the data history connection.
The time series data for twin lifecycle events is stored with the following schema:
| Attribute | Type | Description |
|---|---|---|
TwinId |
String | The twin ID |
Action |
String | The type of twin lifecycle event (create or delete) |
TimeStamp |
DateTime | The date/time the twin lifecycle event was processed by Azure Digital Twins. This field is set by the system and isn't writable by users. |
ServiceId |
String | The service instance ID of the Azure IoT service logging the record |
ModelId |
String | The DTDL model ID (DTMI) |
Below is an example table of twin lifecycle updates stored to Azure Data Explorer.
TwinId |
Action |
TimeStamp |
ServiceId |
ModelId |
|---|---|---|---|---|
| PasteurizationMachine_A01 | Create | 2022-12-15 07:14:12.4160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| PasteurizationMachine_A02 | Create | 2022-12-15 07:14:12.4210 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| SaltMachine_C0 | Create | 2022-12-15 07:14:12.5480 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:SaltMachine;1 |
| PasteurizationMachine_A02 | Delete | 2022-12-15 07:15:49.6050 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
Relationship lifecycle events
The Azure Data Explorer table for relationship lifecycle events has a custom name that you'll specify when creating the data history connection.
The time series data for relationship lifecycle events is stored with the following schema:
| Attribute | Type | Description |
|---|---|---|
RelationshipId |
String | The relationship ID. This field is set by the system and isn't writable by users. |
Name |
String | The name of the relationship |
Action |
The type of relationship lifecycle event (create or delete) | |
TimeStamp |
DateTime | The date/time the relationship lifecycle event was processed by Azure Digital Twins. This field is set by the system and isn't writable by users. |
ServiceId |
The service instance ID of the Azure IoT service logging the record | |
Source |
The source twin ID. This is the ID of the twin where the relationship originates. | |
Target |
The target twin ID. This is the ID of the twin where the relationship arrives. |
Below is an example table of relationship lifecycle updates stored to Azure Data Explorer.
RelationshipId |
Name |
Action |
TimeStamp |
ServiceId |
Source |
Target |
|---|---|---|---|---|---|---|
| PasteurizationMachine_A01_feeds_Relationship0 | feeds | Create | 2022-12-15 07:16:12.7120 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | SaltMachine_C0 |
| PasteurizationMachine_A02_feeds_Relationship0 | feeds | Create | 2022-12-15 07:16:12.7160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A02 | SaltMachine_C0 |
| PasteurizationMachine_A03_feeds_Relationship0 | feeds | Create | 2022-12-15 07:16:12.7250 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A03 | SaltMachine_C1 |
| OsloFactory_contains_Relationship0 | contains | Delete | 2022-12-15 07:16:13.1780 | dairyadtinstance.api.wcus.digitaltwins.azure.net | OsloFactory | SaltMachine_C0 |
End-to-end ingestion latency
Azure Digital Twins data history builds on the existing ingestion mechanism provided by Azure Data Explorer. Azure Digital Twins will ensure that graph update events are made available to Azure Data Explorer within less than two seconds. Extra latency may be introduced by Azure Data Explorer ingesting the data.
There are two methods in Azure Data Explorer for ingesting data: batch ingestion and streaming ingestion. You can configure these ingestion methods for individual tables according to your needs and the specific data ingestion scenario.
Streaming ingestion has the lowest latency. However, due to processing overhead, this mode should only be used if less than 4 GB of data is ingested every hour. Batch ingestion works best if high ingestion data rates are expected. Azure Data Explorer uses batch ingestion by default. The following table summarizes the expected worst-case end-to-end latency:
| Azure Data Explorer configuration | Expected end-to-end latency | Recommended data rate |
|---|---|---|
| Streaming ingestion | <12 sec (<3 sec typical) | <4 GB / hr |
| Batch ingestion | Varies (12 sec-15 m, depending on configuration) | >4 GB / hr |
The rest of this section contains details for enabling each type of ingestion.
Batch ingestion (default)
If not configured otherwise, Azure Data Explorer will use batch ingestion. The default settings may lead to data being available for query only 5-10 minutes after an update to a digital twin was performed. The ingestion policy can be altered, such that the batch processing occurs at most every 10 seconds (at minimum; or 15 minutes at maximum). To alter the ingestion policy, the following command must be issued in the Azure Data Explorer query view:
.alter table <table_name> policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
Ensure that <table_name> is replaced with the name of the table that was set up for you. MaximumBatchingTimeSpan should be set to the preferred batching interval. It may take 5-10 minutes for the policy to take effect. You can read more about ingestion batching at the following link: Kusto IngestionBatching policy management command.
Streaming ingestion
Enabling streaming ingestion is a 2-step process:
- Enable streaming ingestion for your cluster. This action only has to be done once. (Warning: Doing so will have an effect on the amount of storage available for hot cache, and may introduce extra limitations). For instructions, see Configure streaming ingestion on your Azure Data Explorer cluster.
- Add a streaming ingestion policy for the desired table. You can read more about enabling streaming ingestion for your cluster in the Azure Data Explorer documentation: Kusto IngestionBatching policy management command.
To enable streaming ingestion for your Azure Digital Twins data history table, the following command must be issued in the Azure Data Explorer query pane:
.alter table <table_name> policy streamingingestion enable
Ensure that <table_name> is replaced with the name of the table that was set up for you. It may take 5-10 minutes for the policy to take effect.
Visualize historized properties
Azure Digital Twins Explorer, a developer tool for visualizing and interacting with Azure Digital Twins data, offers a Data history explorer feature for viewing historized properties over time in a chart or a table. This feature is also available in 3D Scenes Studio, an immersive 3D environment for giving Azure Digital Twins the visual context of 3D assets.

For more detailed information about using the data history explorer, see Validate and explore historized properties.
Note
If you encounter issues selecting a property in the visual data history explorer experience, this might mean there's an error in some model in your instance. For example, having non-unique enum values in the attributes of a model will break this visualization feature. If this happens, review your model definitions and make sure all properties are valid.
Next steps
Once twin data has been historized to Azure Data Explorer, you can use the Azure Digital Twins query plugin for Azure Data Explorer to run queries across the data. Read more about the plugin here: Querying with the Azure Data Explorer plugin.
Or, dive deeper into data history with creation instructions and an example scenario: Create a data history connection.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for