Azure Data Manager for Energy indexing and search workflows
All data and associated metadata ingested into the platform are indexed to enable search. The metadata is accessible to ensure awareness even when the data isn't available.
Indexer Service
The Indexer Service provides a mechanism for indexing documents that contain structured and unstructured data.
Note
This service is not a public service and only meant to be called internally by other core platform services.
Indexing workflow
The below diagram illustrates the Indexing workflow:
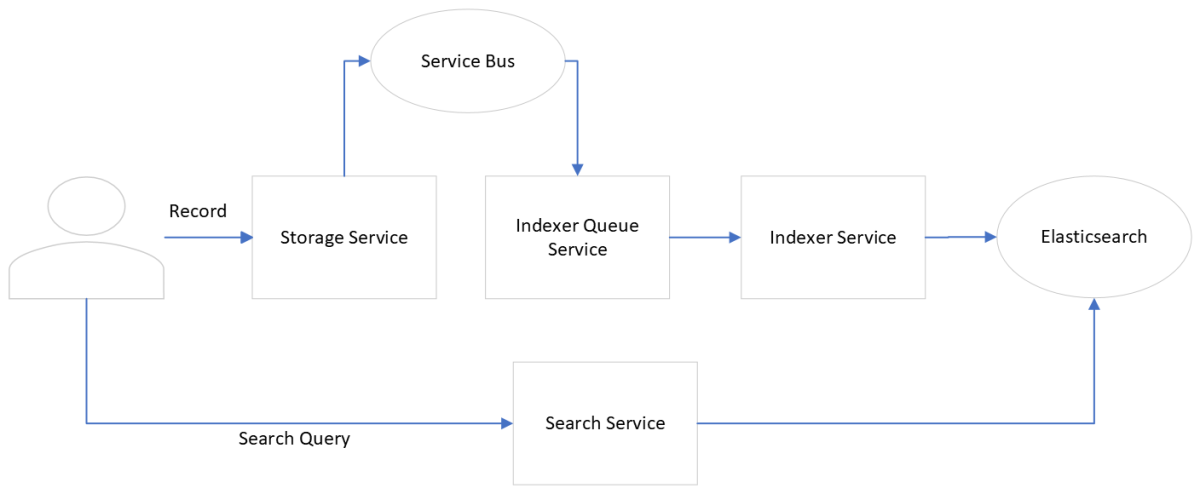
When a customer loads data into the platform, the associated metadata is ingested using the Storage service. The Storage service provides a set of APIs to manage the entire metadata lifecycle such as ingestion (persistence), modification, deletion, versioning, retrieval, and data schema management. Each storage metadata record created by the Storage service contains a kind parameter that refers to an underlying schema. This schema determines the attributes that will be indexed by the Indexer service.
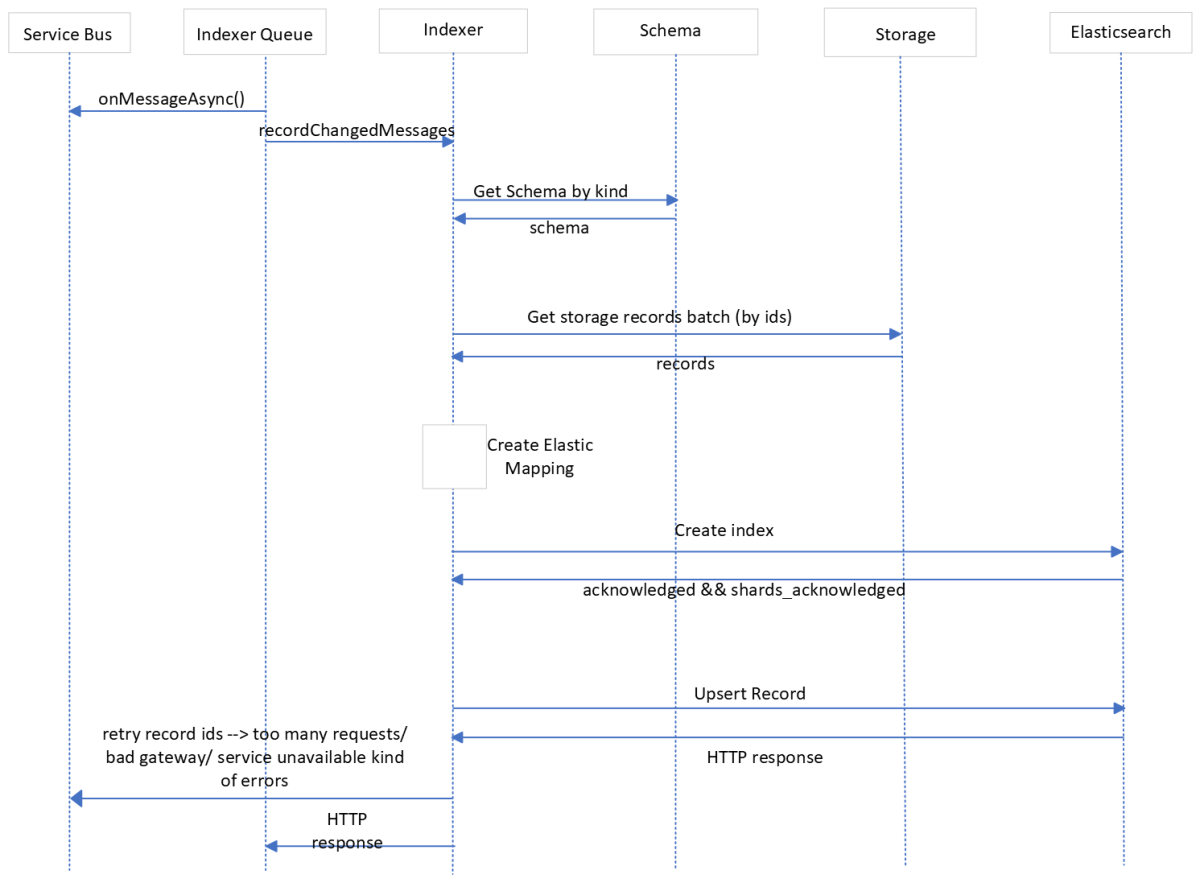
When the Storage service creates a metadata record, it raises a recordChangedMessages event that is collected in the Azure Service Bus (message queue). The Indexer queue service pulls the message from the Azure Service Bus, performs basic validation and sends it over to the Indexer service. If there are any failures in sending the messages to the Indexer service, the Indexer queue service retries sending the message up to a maximum allowed configurable retry count. If the retry attempts fail, a negative acknowledgment is sent to the Azure Service Bus, which then archives the message.
When the recordChangedMessages event is received by the Indexer Service, it fetches the required schemas from the schema cache or through the Schema service APIs. The Indexer Service then creates a new index within Elasticsearch (if not already present), and then sends a bulk query to create or update the records as needed. If the response from Elasticsearch is a failure response of type service unavailable or request timed out, then the Indexer Service creates recordChangedMessages for these failed record IDs and puts the message in the Azure Service Bus. These messages will again be pulled by the Indexer Queue service and will follow the same flow as before.
For more information, see Indexer service OSDU™ documentation provides information on indexer service
Search workflow
Search service provides a mechanism for discovering indexed metadata documents. The Search API supports full-text search on string fields, range queries on date, numeric, or string field, etc. along with geo-spatial searches.
When metadata records are loaded onto the Platform using Storage service, we can configure permissions for viewers and owners of the metadata records under the acl field. The viewers and owners are assigned via groups as defined in the Entitlement service. When performing a search as a user, the matched metadata records will only show up for users who are assigned to the Group.
For a detailed tutorial on Search service, refer Search service OSDU™ documentation
Reindex workflow
Reindex API allows users to reindex a kind without reingesting the records via storage API. For detailed information, refer to Reindex OSDU™ documentation
OSDU™ is a trademark of The Open Group.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for