Azure HDInsight business continuity architectures
This article gives a few examples of business continuity architectures you might consider for Azure HDInsight. Tolerance for reduced functionality during a disaster is a business decision that varies from one application to the next. It might be acceptable for some applications to be unavailable or to be partially available with reduced functionality or delayed processing for a period. For other applications, any reduced functionality could be unacceptable.
Note
The architectures presented in this article are in no way exhaustive. You should design your own unique architectures once you've made objective determinations around expected business continuity, operational complexity, and cost of ownership.
Apache Hive and Interactive Query
Hive Replication V2 is recommended for business continuity in HDInsight Hive and Interactive query clusters. The persistent sections of a standalone Hive cluster that need to be replicated are the Storage Layer and the Hive metastore. Hive clusters in a multi-user scenario with Enterprise Security Package need Microsoft Entra Domain Services and Ranger Metastore.
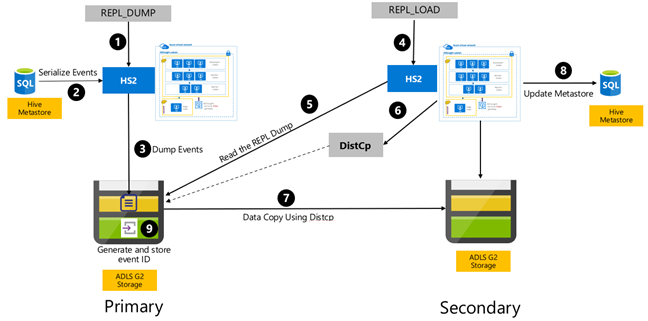
Hive event-based replication is configured between the primary and secondary clusters. This consists of two distinct phases, bootstrapping and incremental runs:
Bootstrapping replicates the entire Hive warehouse including the Hive metastore information from primary to secondary.
Incremental runs are automated on the primary cluster and the events generated during the incremental runs are played back on the secondary cluster. The secondary cluster catches up with the events generated from the primary cluster, ensuring that the secondary cluster is consistent with the primary cluster's events after the replication run.
The secondary cluster is needed only at the time of replication to run distributed copy, DistCp, but the storage and metastores need to be persistent. You could choose to spin up a scripted secondary cluster on-demand before replication, run the replication script on it, and then tear it down after successful replication.
The secondary cluster is usually read-only. You can make the secondary cluster read-write, but this adds additional complexity that involves replicating the changes from the secondary cluster to the primary cluster.
Hive event-based replication RPO & RTO
RPO: Data loss is limited to the last successful incremental replication event from primary to secondary.
RTO: The time between the failure and the resumption of upstream and downstream transactions with the secondary.
Apache Hive and Interactive Query architectures
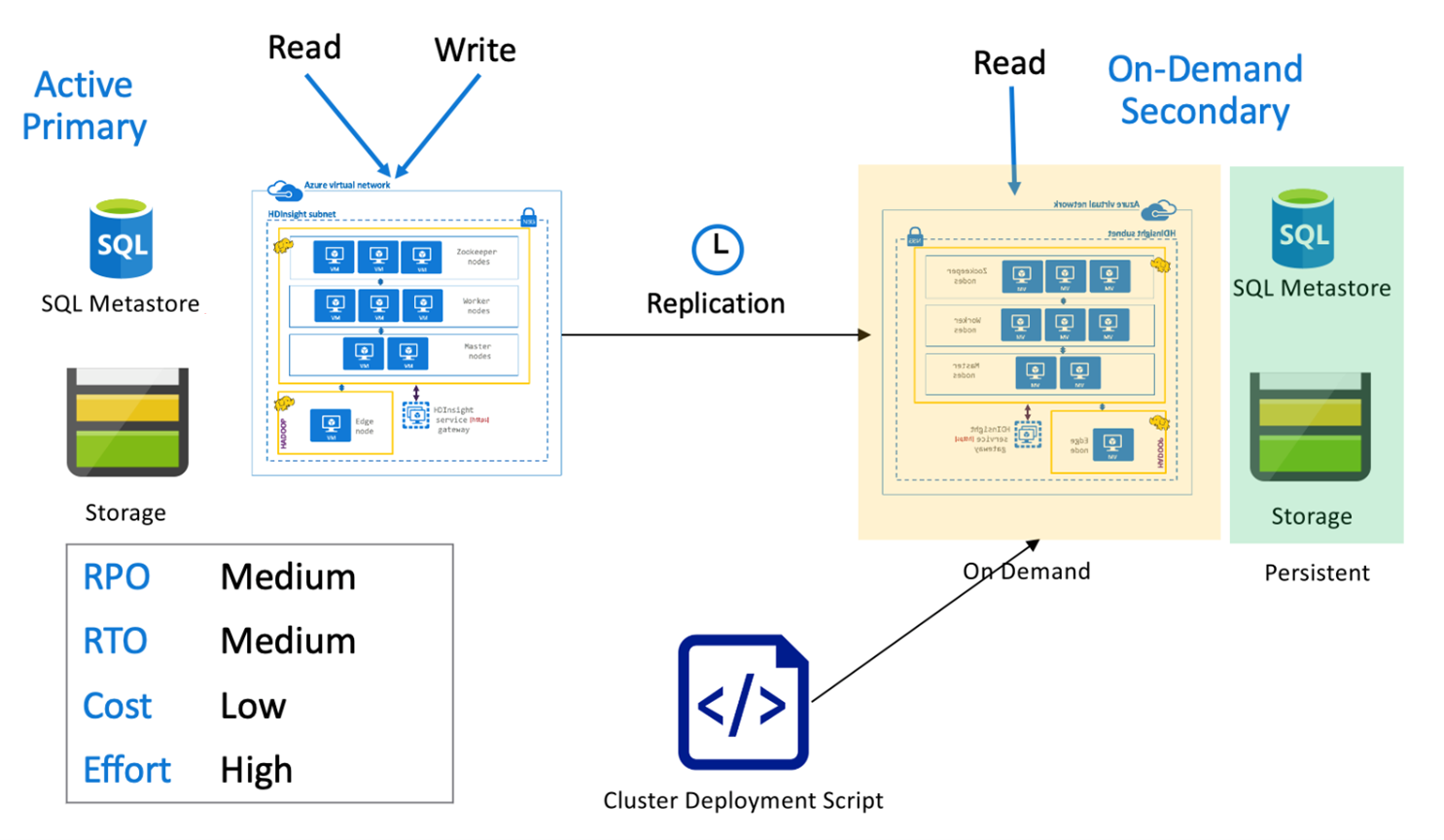
Hive active primary with on-demand secondary
In an active primary with on-demand secondary architecture, applications write to the active primary region while no cluster is provisioned in the secondary region during normal operations. SQL Metastore and Storage in the secondary region are persistent, while the HDInsight cluster is scripted and deployed on-demand only before the scheduled Hive replication runs.
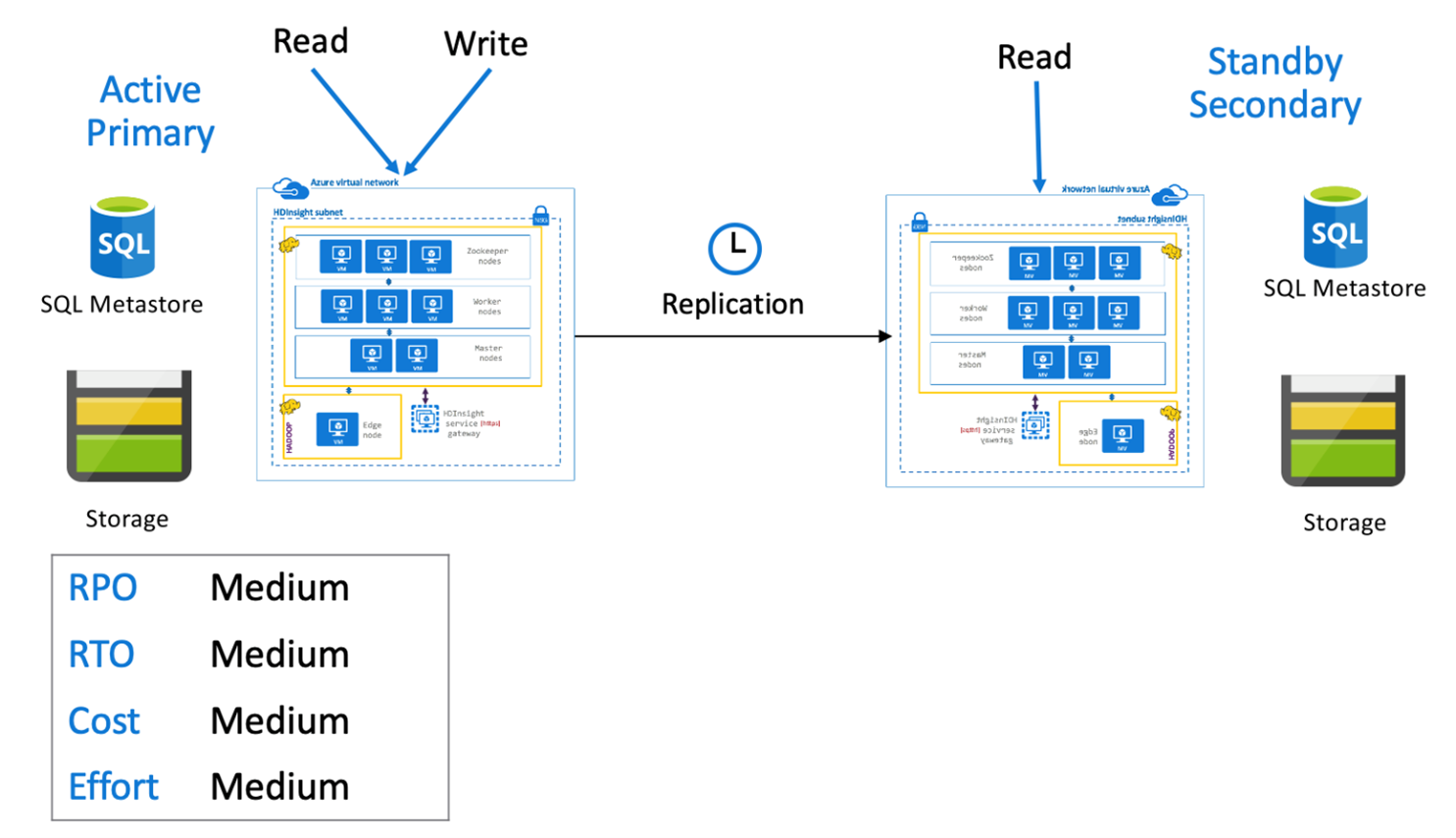
Hive active primary with standby secondary
In an active primary with standby secondary, applications write to the active primary region while a standby scaled down secondary cluster in read-only mode runs during normal operations. During normal operations, you could choose to offload region specific read operations to secondary.
For more information on Hive replication and code samples refer Apache Hive replication in Azure HDInsight clusters
Apache Spark
Spark workloads may or may not involve a Hive component. To enable Spark SQL workloads to read and write data from Hive, HDInsight Spark clusters share Hive custom metastores from Hive/Interactive query clusters in the same region. In such scenarios, cross region replication of Spark workloads must also accompany the replication of Hive metastores and storage. The failover scenarios in this section apply to both:
- Spark SQL on ACID tables using Hive Warehouse Connector(HWC) Setup using an HDInsight Interactive Query cluster.
- Spark SQL workload on non-ACID tables using a HDInsight Hadoop cluster.
For scenarios where Spark works in standalone mode, curated data and stored Spark Jars (for Livy jobs) need to be replicated from the primary region to the secondary region on a regular basis using Azure Data Factory's DistCP.
We recommend that you use version control systems to store Spark notebooks and libraries where they can easily be deployed on primary or secondary clusters. Ensure that notebook based and non-notebook based solutions are prepared to load the correct data mounts in the primary or secondary workspace.
If there are customer-specific libraries which are beyond what HDInsight provides natively, they must be tracked and periodically loaded into the standby secondary cluster.
Apache Spark replication RPO & RTO
RPO: The data loss is limited to the last successful incremental replication (Spark and Hive) from primary to secondary.
RTO: The time between the failure and the resumption of upstream and downstream transactions with the secondary.
Apache Spark architectures
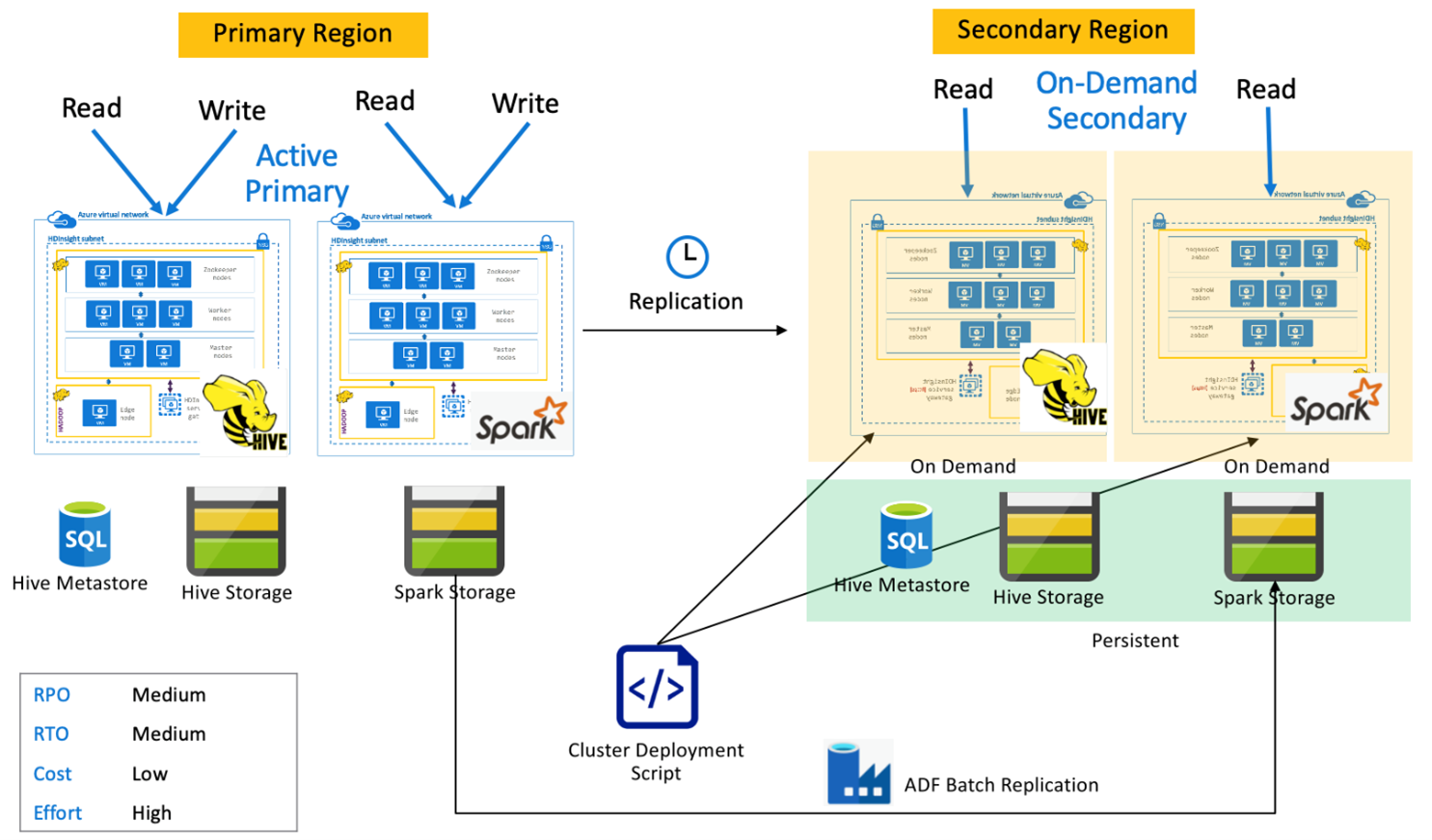
Spark active primary with on-demand secondary
Applications read and write to Spark and Hive Clusters in the primary region while no clusters are provisioned in the secondary region during normal operations. SQL Metastore, Hive Storage, and Spark Storage are persistent in the secondary region. The Spark and Hive clusters are scripted and deployed on-demand. Hive replication is used to replicate Hive Storage and Hive metastores while Azure Data Factory's DistCP can be used to copy standalone Spark storage. Hive clusters need to deploy before every Hive replication run because of the dependency DistCp compute.
Spark active primary with standby secondary
Applications read and write to Spark and Hive clusters in the primary region while standby scaled-down Hive and Spark clusters in read-only mode run in secondary region during normal operations. During normal operations, you could choose to offload region specific Hive and Spark read operations to secondary.

Apache HBase
HBase Export and HBase Replication are common ways of enabling business continuity between HDInsight HBase clusters.
HBase Export is a batch replication process that uses the HBase Export Utility to export tables from the primary HBase cluster to its underlying Azure Data Lake Storage Gen 2 storage. The exported data can then be accessed from the secondary HBase cluster and imported into tables which must preexist in the secondary. While HBase Export does offer table level granularity, in incremental update situations, the export automation engine controls the range of incremental rows to include in each run. For more information, see HDInsight HBase Backup and Replication.
HBase Replication uses near real-time replication between HBase clusters in a fully automated manner. Replication is done at the table level. Either all tables or specific tables can be targeted for replication. HBase replication is eventually consistent, meaning that recent edits to a table in the primary region may not be available to all the secondaries immediately. Secondaries are guaranteed to eventually become consistent with the primary. HBase replication can be set up between two or more HDInsight HBase clusters if:
- Primary and secondary are in the same virtual network.
- Primary and secondary are in different peered VNets in the same region.
- Primary and secondary are in different peered VNets in different regions.
For more information, see Set up Apache HBase cluster replication in Azure virtual networks.
There are a few other ways of performing backups of HBase clusters like copying the hbase folder, copy tables and Snapshots.
HBase RPO & RTO
HBase Export
- RPO: Data Loss is limited to the last successful batch incremental import by the secondary from the primary.
- RTO: The time between failure of the primary and resumption of I/O operations on the secondary.
HBase Replication
- RPO: Data Loss is limited to the last WalEdit Shipment received at the secondary.
- RTO: The time between failure of the primary and resumption of I/O operations on the secondary.
HBase architectures
HBase replication can be set up in three modes: Leader-Follower, Leader-Leader and Cyclic.
HBase Replication: Leader – Follower model
In this cross-region set up, replication is unidirectional from the primary region to the secondary region. Either all tables or specific tables on the primary can be identified for unidirectional replication. During normal operations, the secondary cluster can be used to serve read requests in its own region.
The secondary cluster operates as a normal HBase cluster that can host its own tables and can serve reads and writes from regional applications. However, writes on the replicated tables or tables native to secondary are not replicated back to the primary.
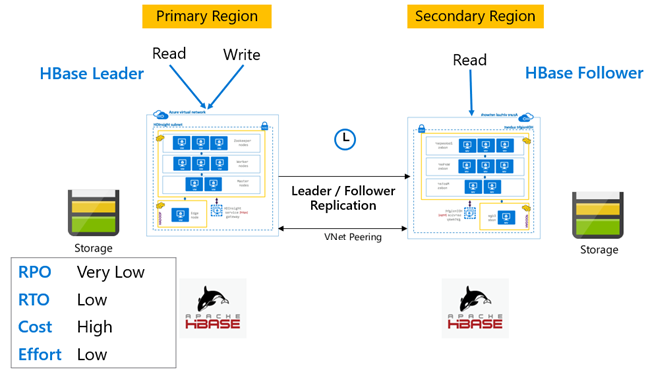
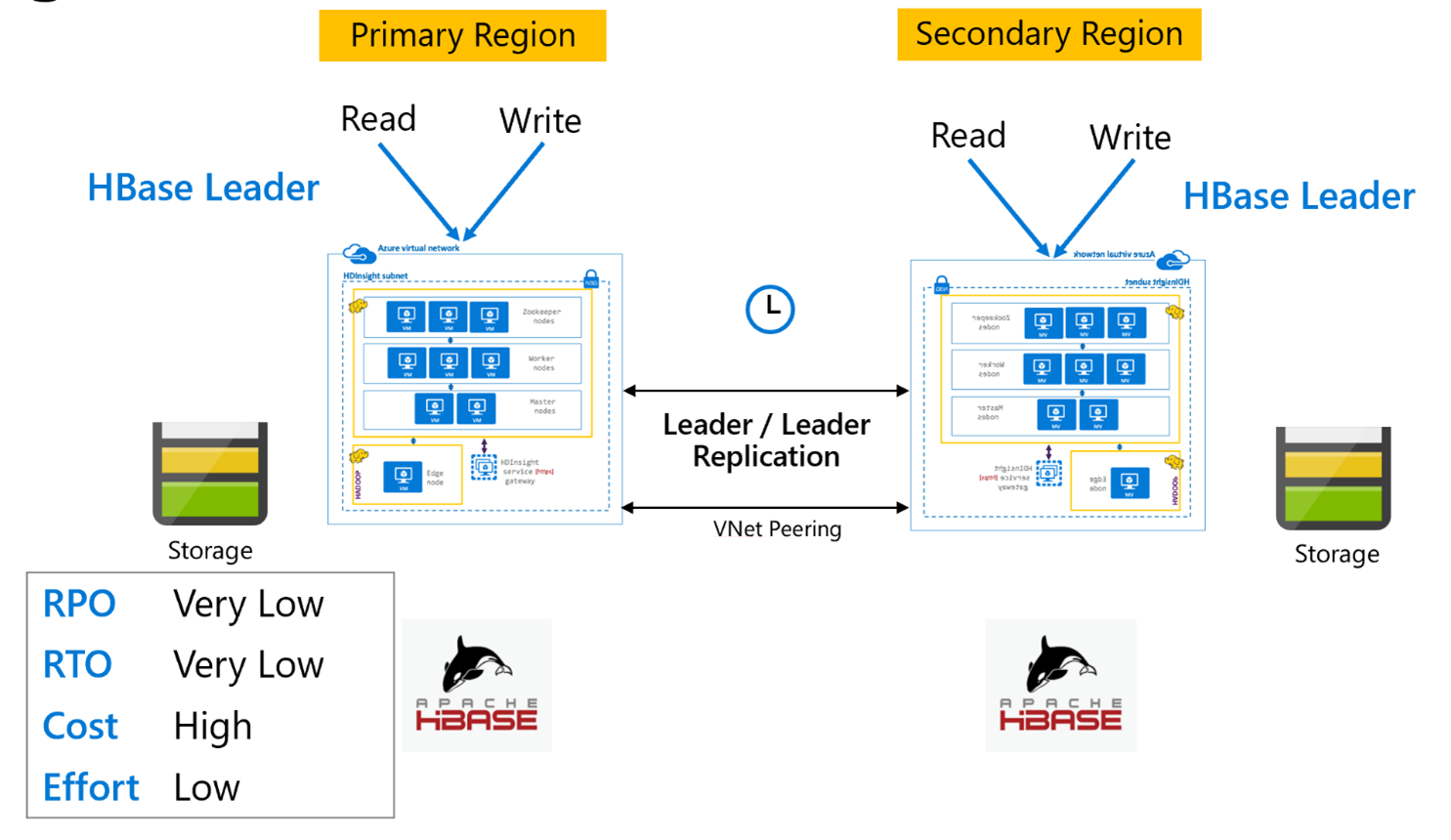
HBase Replication: Leader – Leader model
This cross-region set up is very similar to the unidirectional set up except that replication happens bidirectionally between the primary region and the secondary region. Applications can use both clusters in read–write modes and updates are exchanges asynchronously between them.
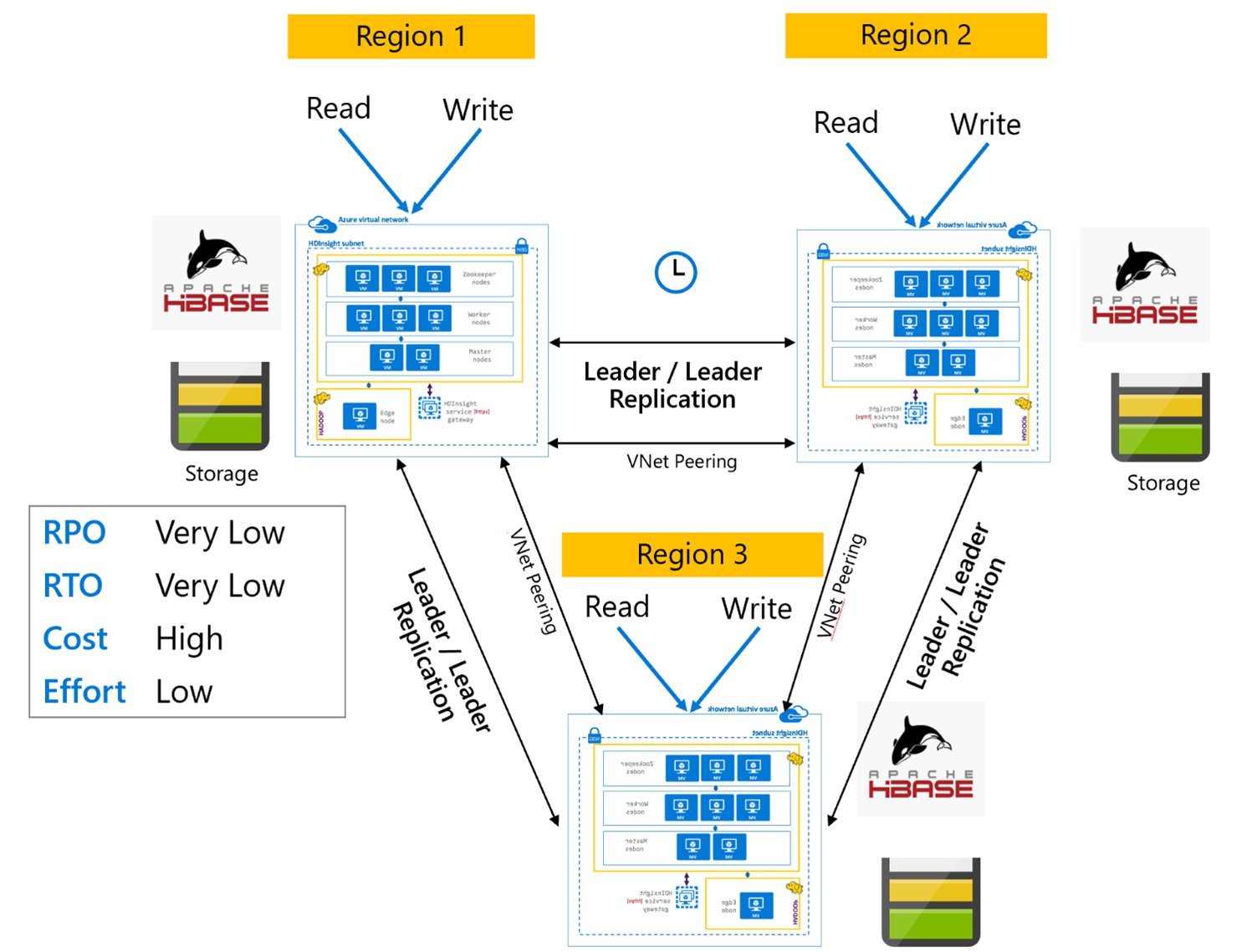
HBase Replication: Multi-Region or Cyclic
The Multi-Region/Cyclic replication model is an extension of HBase Replication and could be used to create a globally redundant HBase architecture with multiple applications which read and write to region specific HBase clusters. The clusters can be set up in various combinations of Leader/Leader or Leader/Follower depending on business requirements.
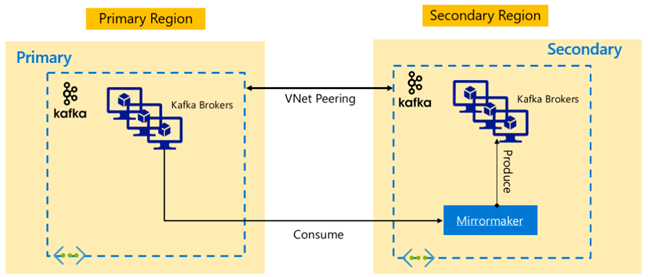
Apache Kafka
To enable cross region availability HDInsight 4.0 supports Kafka MirrorMaker which can be used to maintain a secondary replica of the primary Kafka cluster in a different region. MirrorMaker acts as a high-level consumer-producer pair, consumes from a specific topic in the primary cluster and produces to a topic with the same name in the secondary. Cross cluster replication for high availability disaster recovery using MirrorMaker comes with the assumption that Producers and Consumers need to fail over to the replica cluster. For more information, see Use MirrorMaker to replicate Apache Kafka topics with Kafka on HDInsight
Depending on the topic lifetime when replication started, MirrorMaker topic replication can lead to different offsets between source and replica topics. HDInsight Kafka clusters also support topic partition replication which is a high availability feature at the individual cluster level.
Apache Kafka architectures
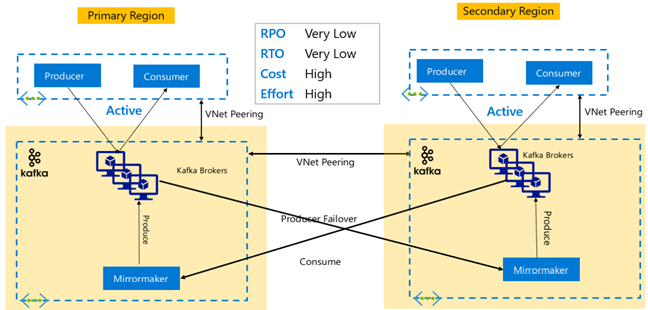
Kafka Replication: Active – Passive
Active-Passive setup enables asynchronous unidirectional mirroring from Active to Passive. Producers and Consumers need to be aware of the existence of an Active and Passive cluster and must be ready to fail over to the Passive in case the Active fails. Below are some advantages and disadvantages of Active-Passive setup.
Advantages:
- Network latency between clusters does not affect the Active cluster's performance.
- Simplicity of unidirectional replication.
Disadvantages:
- The Passive cluster may remain underutilized.
- Design complexity in incorporating failover awareness in application producers and consumers.
- Possible data loss during failure of the Active cluster.
- Eventual consistency between topics between Active and Passive clusters.
- Failbacks to Primary may lead to message inconsistency in topics.
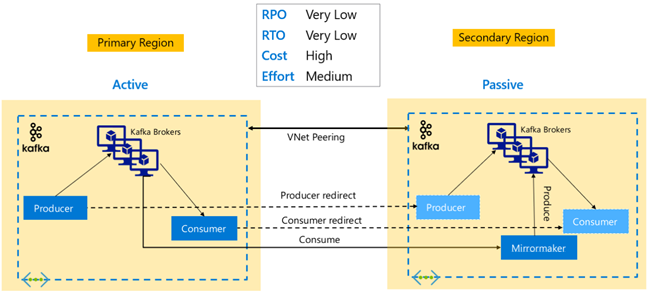
Kafka Replication: Active – Active
Active-Active set up involves two regionally separated, VNet peered HDInsight Kafka clusters with bidirectional asynchronous replication with MirrorMaker. In this design, messages consumed by the consumers in the primary are also made available to consumers in secondary and vice versa. Below are some advantages and disadvantages of Active-Active setup.
Advantages:
- Because of their duplicated state, failovers and failbacks are easier to execute.
Disadvantages:
- Set up, management, and monitoring is more complex than Active-Passive.
- The problem of circular replication needs to addressed.
- Bidirectional replication leads to higher regional data egress costs.
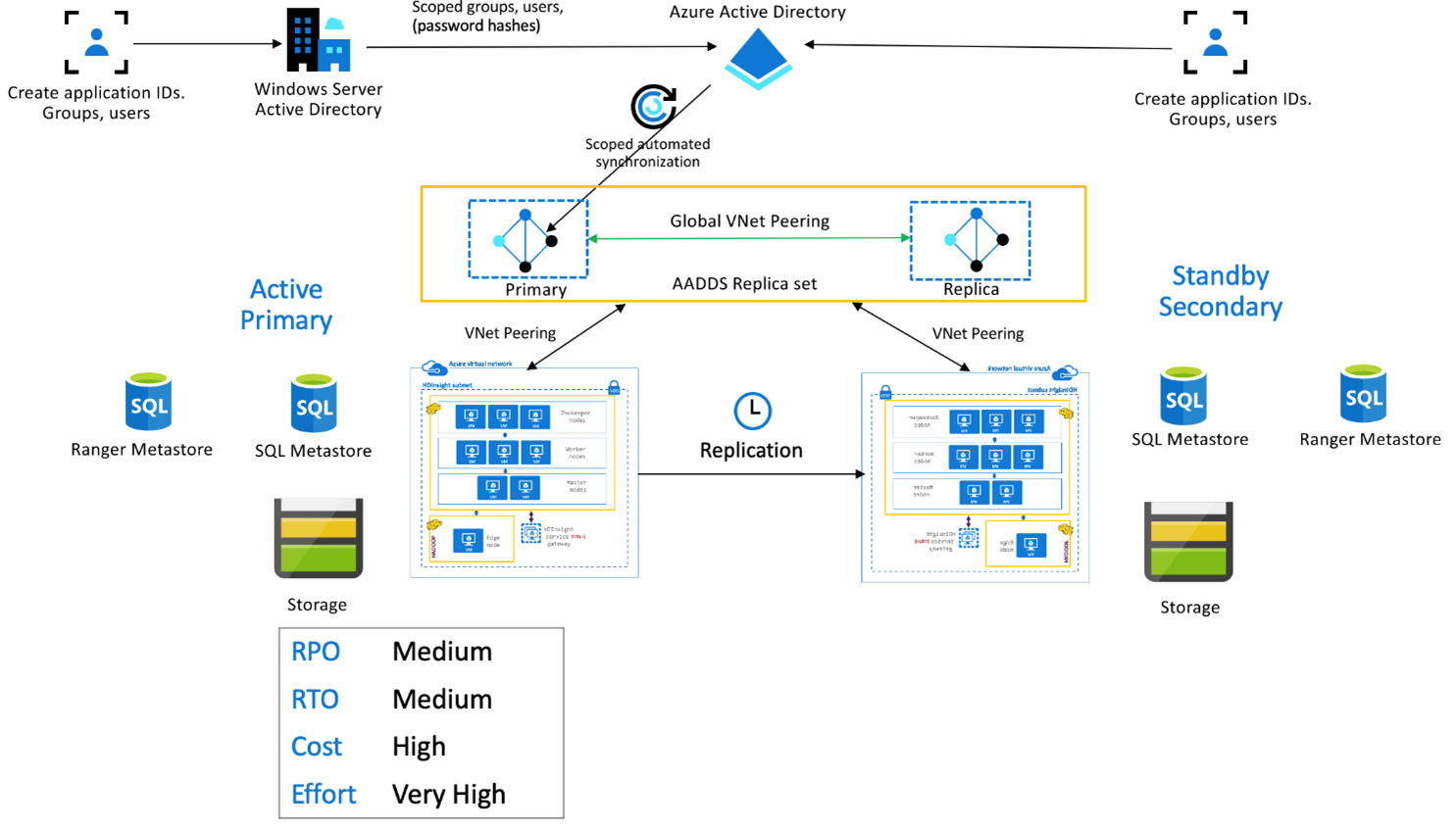
HDInsight Enterprise Security Package
This set up is used to enable multi-user functionality in both primary and secondary, as well as Microsoft Entra Domain Services replica sets to ensure that users can authenticate to both clusters. During normal operations, Ranger policies need to be set up in the Secondary to ensure that users are restricted to Read operations. The below architecture explains how an ESP enabled Hive Active Primary – Standby Secondary set up might look.
Ranger Metastore replication:
Ranger Metastore is used to persistently store and serve Ranger policies for controlling data authorization. We recommend that you maintain independent Ranger policies in primary and secondary and maintain the secondary as a read replica.
If the requirement is to keep Ranger policies in sync between primary and secondary, use Ranger Import/Export to periodically back-up and import Ranger policies from primary to secondary.
Replicating Ranger policies between primary and secondary can cause the secondary to become write-enabled, which can lead to inadvertent writes on the secondary leading to data inconsistencies.
Next steps
To learn more about the items discussed in this article, see:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for