Streaming at scale in HDInsight
Real-time big data solutions act on data that is in motion. Typically, this data is most valuable at its time of arrival. If the incoming data stream becomes greater than can be handled at that moment, you may need to throttle down resources. Alternatively, an HDInsight cluster can scale up to meet your streaming solution by adding nodes on demand.
In a streaming application, one or more data sources are generating events (sometimes in the millions per second) that need to be ingested quickly without dropping any useful information. The incoming events are handled with stream buffering, also called event queuing, by a service such as Apache Kafka or Event Hubs. After you collect the events, you can then analyze the data using a real-time analytics system within the stream processing layer. The processed data can be stored in long-term storage systems, like Azure Data Lake Storage, and displayed in real time on a business intelligence dashboard, such as Power BI, Tableau, or a custom web page.
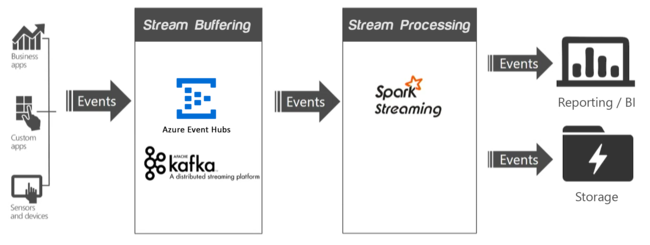
Apache Kafka
Apache Kafka provides a high-throughput, low-latency message queueing service, and is now part of the Apache suite of Open Source Software (OSS). Kafka uses a publish and subscribe messaging model and stores streams of partitioned data safely in a distributed, replicated cluster. Kafka scales linearly as throughput increases.
For more information, see Introducing Apache Kafka on HDInsight.
Spark Streaming
Spark Streaming is an extension to Spark, which allows you to reuse the same code that you use for batch processing. You can combine both batch and interactive queries in the same application. Unlike Spark, Streaming provides stateful exactly once processing semantics. When used in combination with the Kafka Direct API, which ensures that all Kafka data received on Spark Streaming exactly once, it's possible to achieve end-to-end exactly once guarantees. One of Spark Streaming's strengths is its fault-tolerant capabilities, recovering faulted nodes rapidly when multiple nodes are being used within the cluster.
For more information, see What is Apache Spark Streaming?.
Scaling a cluster
Although you can specify the number of nodes in your cluster during creation, you may want to grow or shrink the cluster to match the workload. All HDInsight clusters allow you to change the number of nodes in the cluster. Spark clusters can be dropped with no loss of data, as all data is stored in Azure Storage or Data Lake Storage.
There are advantages to decoupling technologies. For instance, Kafka is an event buffering technology, so it's very IO intensive and doesn't need much processing power. In comparison, stream processors such as Spark Streaming are compute-intensive, requiring more powerful VMs. By having these technologies decoupled into different clusters, you can scale them independently while best utilizing the VMs.
Scale the stream buffering layer
The stream buffering technologies Event Hubs and Kafka both use partitions, and consumers read from those partitions. Scaling the input throughput requires scaling up the number of partitions, and adding partitions provides increasing parallelism. In Event Hubs, the partition count can't be changed after deployment so it's important to start with the target scale in mind. With Kafka, it's possible to add partitions, even while Kafka is processing data. Kafka provides a tool to reassign partitions, kafka-reassign-partitions.sh. HDInsight provides a partition replica rebalancing tool, rebalance_rackaware.py. This rebalancing tool calls the kafka-reassign-partitions.sh tool in such a way that each replica is in a separate fault domain and update domain, making Kafka rack aware and increasing fault tolerance.
Scale the stream processing layer
Apache Spark Streaming support adding worker nodes to their clusters, even while data is being processed.
Apache Spark uses three key parameters for configuring its environment, depending on application requirements: spark.executor.instances, spark.executor.cores, and spark.executor.memory. An executor is a process that is launched for a Spark application. An executor runs on the worker node and is responsible for carrying out the application's tasks. The default number of executors and the executor sizes for each cluster are calculated based on the number of worker nodes and the worker node size. These numbers are stored in the spark-defaults.conffile on each cluster head node.
These three parameters can be configured at the cluster level, for all applications that run on the cluster, and can also be specified for each individual application. For more information, see Managing resources for Apache Spark clusters.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for