Autoscale for Azure API for FHIR
Important
Azure API for FHIR will be retired on September 30, 2026. Follow the migration strategies to transition to Azure Health Data Services FHIR service by that date. Due to the retirement of Azure API for FHIR, new deployments won't be allowed beginning April 1, 2025. Azure Health Data Services FHIR service is the evolved version of Azure API for FHIR that enables customers to manage FHIR, DICOM, and MedTech services with integrations into other Azure services.
Azure API for FHIR, as a managed service, allows customers to persist with Fast Healthcare Interoperability Resources (FHIR®) compliant healthcare data and exchange it securely through the service API. To accommodate different transaction workloads, customers can use manual scale or autoscale.
Azure API for FHIR provides scaling capabilities at database and compute level.
Auto scale at Database level
By default, Azure API for FHIR is set to manual for database scaling. This option works well when the transaction workloads are known and consistent. Customers can adjust the throughput RU/s through the portal up to 100,000 and submit a request to increase the limit.
The autoscale feature is designed to scale Azure resources including the database throughput automatically according to the workloads, eliminating possible bottlenecks in the data layer.
Lets understand how to enable autoscaling at database level with next sections
Guidance to enable autoscale
In general, customers should consider autoscale when their workloads vary significantly and are unpredictable.
To enable the autoscale feature, customer needs to create a one-time support ticket to request it through Azure portal. The Microsoft support team enables the autoscale feature based on the support priority.
Note
The autoscale feature isn't available from the Azure portal.
Autoscale for RU/s
When autoscale is enabled, the system calculates and sets the initial Tmax value. The scalability is governed by the maximum throughput RU/s value, or Tmax, and scales between 0.1 *Tmax (or 10% Tmax) and Tmax RU/s. The Tmax increases automatically as the total data size grows. To ensure maximum scalability, the Tmax value should be kept as-is. However, customers can request that the value be changed to something between 10% and 100% of the Tmax value.
You can increase the max RU/s or Tmax value and go as high as the service supports. When the service is busy, the throughput RU/s are scaled up to the Tmax value. When the service is idle, the throughput RU/s are scaled down to 10% Tmax value.
You can also decrease the max RU/s or Tmax value. When you lower the max RU/s, the minimum value you can set it to is: MAX (4000, highest max RU/s ever provisioned / 10, current storage in GB * 400), rounded to the nearest 1000 RU/s.
- Example 1: You have 1-GB data and the highest provisioned
RU/sis 10,000. The minimum value is Max (4000, 10,000/10, 1x400) = 4000. The first number, 4000, is used. - Example 2: You have 20-GB data and the highest provisioned
RU/sis 100,000. The minimum value is Max (4000, 100,000/10, 20x400) = 10,000. The second number, 100,000/10 =10,000, is used. - Example 3: You have 80-GB data and the highest provisioned RU/s is 300,000. The minimum value is Max (4000, 300,000/10, 80x400) = 32,000. The third number, 80x400=32,000, is used.
You can adjust the max RU/s or Tmax value through the portal if it's a valid number and no greater than 100,000 RU/s. You can create a support ticket to request Tmax value larger than 100,000.
Note
As data storage grows, the system will automatically increase the max throughput to the next highest RU/s that can support that level of storage.
Autoscale at Compute Level
Autoscaling policies defined for FHIR service compute level consists:
- Scaling Trigger
Scaling Trigger describes when scaling of the service will be performed. Conditions that are defined in the trigger are checked periodically to determine if a service should be scaled or not. All triggers that are currently supported are Average CPU, Max Worker Thread, Average LogWrite, Average data IO.
- Scaling mechanism
The scaling mechanism is applied if the trigger check determines that scaling is necessary. Additionally, the scaling trigger won't be evaluated again until the scaling interval has expired, which is set to one minute for Azure API for FHIR.
To ensure the best possible outcome, we recommend customers to gradually increase their request rate to match the expected push rate, rather than pushing all requests at once.
FAQ
How to estimate throughput RU/s required?
The data size is one of several factors used in calculating the total throughput RU/s required for manual scale and autoscale. You can find the data size using the Metrics menu option under Monitoring. Start a new chart and select Cosmos DB Collection Size in the Metric dropdown box and Max in the "Aggregation" box.
Screenshot of metrics_new_chart ](media/cosmosdb/metrics-new-chart.png#lightbox)
{kind=link}
You should be able to see the Max data collection size over the time period selected. Change the "Time Range" if necessary, for example from "Last 30 minutes" to "Last 48 Hours".
Screenshot of cosmosdb_collection_size ](media/cosmosdb/cosmosdb-collection-size.png#lightbox)
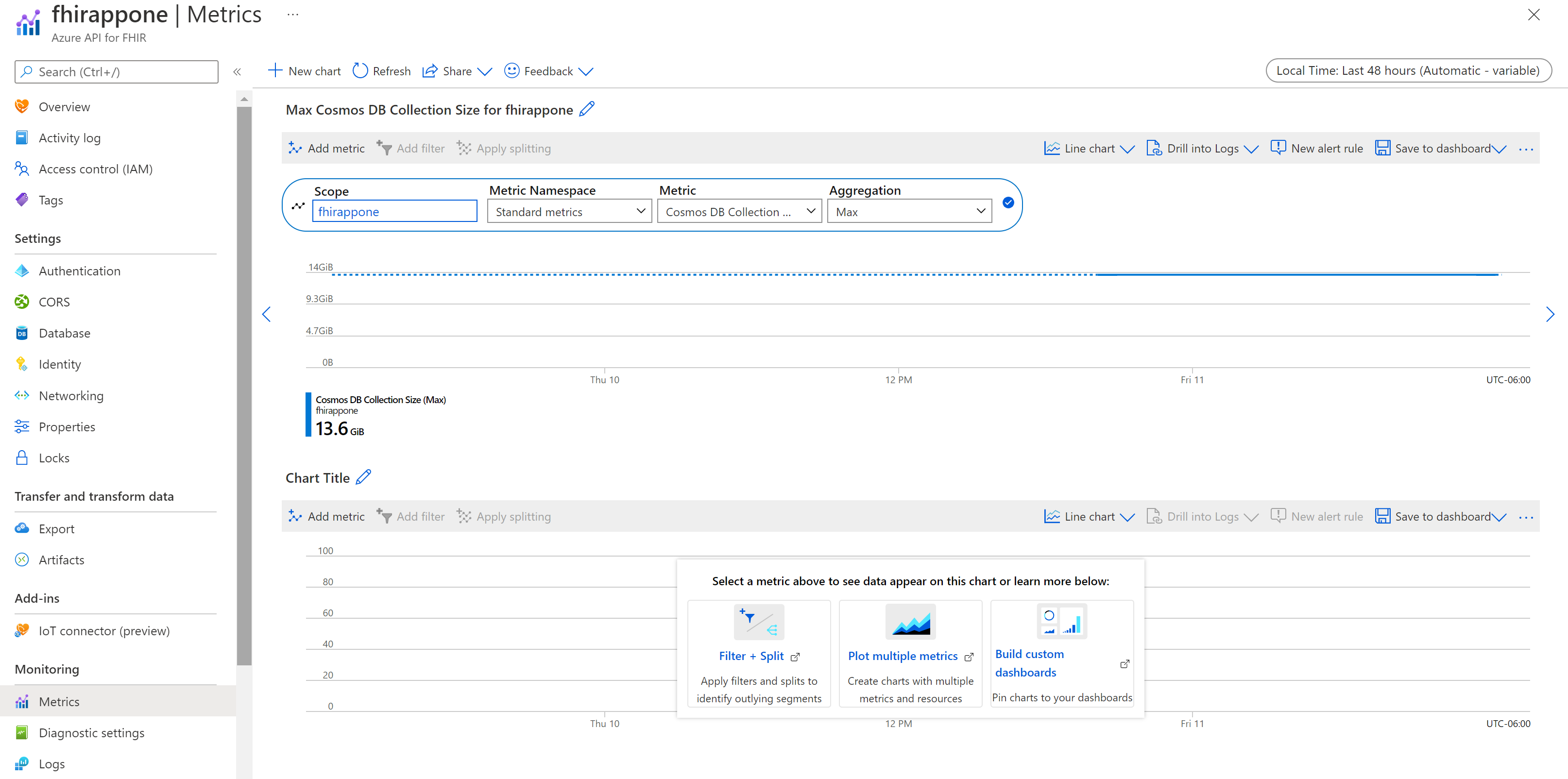{kind=link}
Use the formula to calculate required RU/s.
- Manual scale: storage in GB * 40
- Autoscale: storage in GB * 400
Keep in mind that this is only an estimate based on data size and that there are other factors that affect the required RU/s.
I enabled autoscale how can I migrate to scaling manually?
A support ticket is required to change autoscale to manual scale and specify the throughput RU/s. The minimum value for manual scale you can set it to is: MAX (400, highest max RU/s ever provisioned / 100, current storage in GB * 40), rounded to the nearest 1000 RU/s. The numbers used here are different from those used in autoscale.
Once the change is completed, the new billing rates are based on manual scale.
What is the cost impact of autoscale?
The autoscale feature incurs costs because of managing the provisioned throughput units automatically. The actual costs depend on hourly usage, but keep in mind that there are minimum costs of 10% of Tmax for reserved throughput RU/s. However, this cost increase doesn't apply to storage and runtime costs. For information about pricing, see Azure API for FHIR pricing.
Next steps
In this document, you learned about the autoscale feature for Azure API for FHIR. For an overview about Azure API for FHIR, see
FHIR® is a registered trademark of HL7 and is used with the permission of HL7.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for