Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article describes a component in Azure Machine Learning designer. Use the Extract N-Gram Features from Text component to featurize unstructured text data.
Configuration of the Extract N-Gram Features from Text component
The component supports the following scenarios for using an n-gram dictionary:
Create a new n-gram dictionary from a column of free text.
Use an existing set of text features to featurize a free text column.
Score or deploy a model that uses n-grams.
Create a new n-gram dictionary
Add the Extract N-Gram Features from Text component to your pipeline, and connect the dataset that has the text you want to process.
Use Text column to choose a column of string type that contains the text you want to extract. Because results are verbose, you can process only a single column at a time.
Set Vocabulary mode to Create to indicate that you're creating a new list of n-gram features.
Set N-Grams size to indicate the maximum size of the n-grams to extract and store.
For example, if you enter 3, unigrams, bigrams, and trigrams will be created.
Weighting function specifies how to build the document feature vector and how to extract vocabulary from documents.
Binary Weight: Assigns a binary presence value to the extracted n-grams. The value for each n-gram is 1 when it exists in the document, and 0 otherwise.
TF Weight: Assigns a term frequency (TF) score to the extracted n-grams. The value for each n-gram is its occurrence frequency in the document.
IDF Weight: Assigns an inverse document frequency (IDF) score to the extracted n-grams. The value for each n-gram is the log of corpus size divided by its occurrence frequency in the whole corpus.
IDF = log of corpus_size / document_frequencyTF-IDF Weight: Assigns a term frequency/inverse document frequency (TF/IDF) score to the extracted n-grams. The value for each n-gram is its TF score multiplied by its IDF score.
Set Minimum word length to the minimum number of letters that can be used in any single word in an n-gram.
Use Maximum word length to set the maximum number of letters that can be used in any single word in an n-gram.
By default, up to 25 characters per word or token are allowed.
Use Minimum n-gram document absolute frequency to set the minimum occurrences required for any n-gram to be included in the n-gram dictionary.
For example, if you use the default value of 5, any n-gram must appear at least five times in the corpus to be included in the n-gram dictionary.
Set Maximum n-gram document ratio to the maximum ratio of the number of rows that contain a particular n-gram, over the number of rows in the overall corpus.
For example, a ratio of 1 would indicate that, even if a specific n-gram is present in every row, the n-gram can be added to the n-gram dictionary. More typically, a word that occurs in every row would be considered a noise word and would be removed. To filter out domain-dependent noise words, try reducing this ratio.
Important
The rate of occurrence of particular words is not uniform. It varies from document to document. For example, if you're analyzing customer comments about a specific product, the product name might be very high frequency and close to a noise word, but be a significant term in other contexts.
Select the option Normalize n-gram feature vectors to normalize the feature vectors. If this option is enabled, each n-gram feature vector is divided by its L2 norm.
Submit the pipeline.
Use an existing n-gram dictionary
Add the Extract N-Gram Features from Text component to your pipeline, and connect the dataset that has the text you want to process to the Dataset port.
Use Text column to select the text column that contains the text you want to featurize. By default, the component selects all columns of type string. For best results, process a single column at a time.
Add the saved dataset that contains a previously generated n-gram dictionary, and connect it to the Input vocabulary port. You can also connect the Result vocabulary output of an upstream instance of the Extract N-Gram Features from Text component.
For Vocabulary mode, select the ReadOnly update option from the drop-down list.
The ReadOnly option represents the input corpus for the input vocabulary. Rather than computing term frequencies from the new text dataset (on the left input), the n-gram weights from the input vocabulary are applied as is.
Tip
Use this option when you're scoring a text classifier.
For all other options, see the property descriptions in the previous section.
Submit the pipeline.
Build inference pipeline that uses n-grams to deploy a real-time endpoint
A training pipeline which contains Extract N-Grams Feature From Text and Score Model to make prediction on test dataset, is built in following structure:
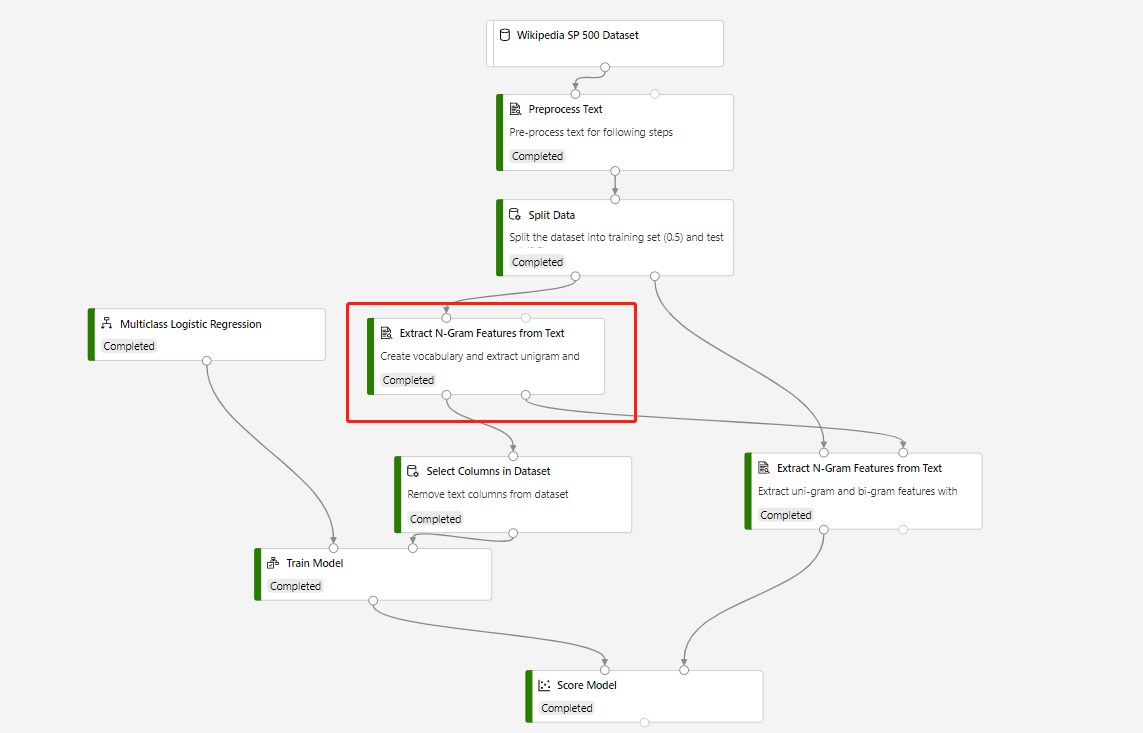
Vocabulary mode of the circled Extract N-Grams Feature From Text component is Create, and Vocabulary mode of the component which connects to Score Model component is ReadOnly.
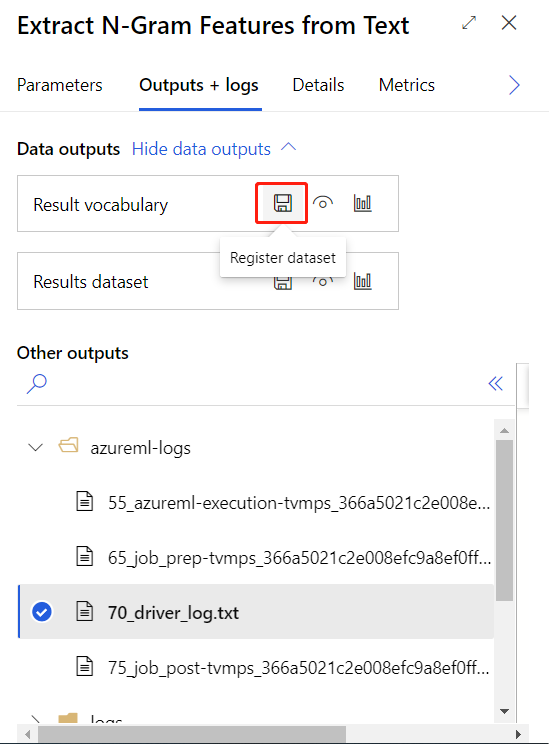
After submitting the training pipeline above successfully, you can register the output of the circled component as dataset.
Then you can create real-time inference pipeline. After creating inference pipeline, you need to adjust your inference pipeline manually like following:
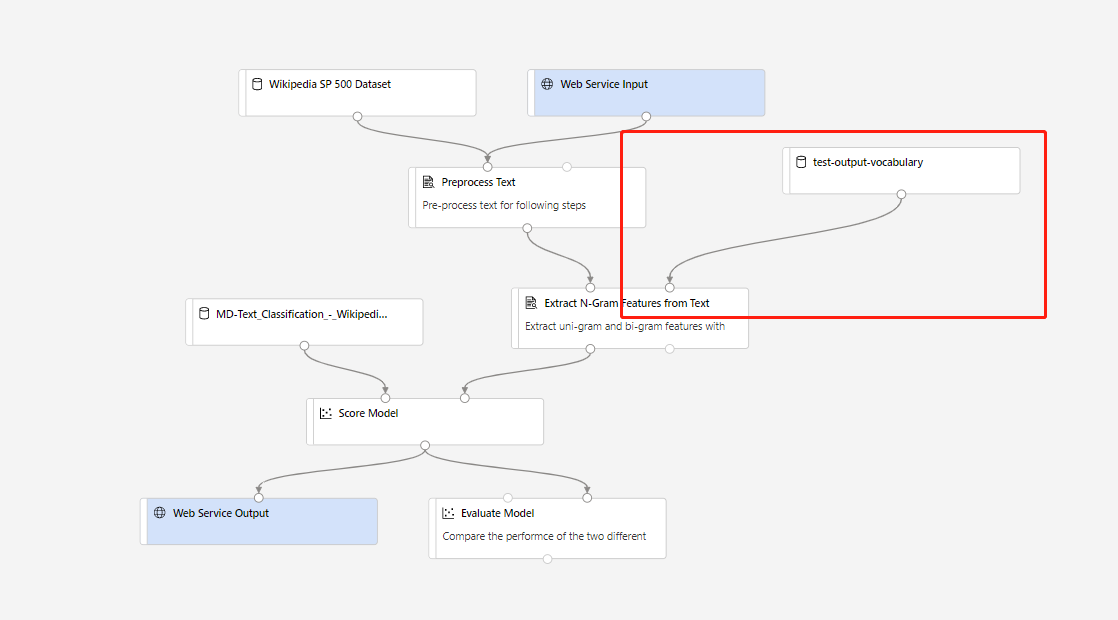
Then submit the inference pipeline, and deploy a real-time endpoint.
Results
The Extract N-Gram Features from Text component creates two types of output:
Result dataset: This output is a summary of the analyzed text combined with the n-grams that were extracted. Columns that you didn't select in the Text column option are passed through to the output. For each column of text that you analyze, the component generates these columns:
- Matrix of n-gram occurrences: The component generates a column for each n-gram found in the total corpus and adds a score in each column to indicate the weight of the n-gram for that row.
Result vocabulary: The vocabulary contains the actual n-gram dictionary, together with the term frequency scores that are generated as part of the analysis. You can save the dataset for reuse with a different set of inputs, or for a later update. You can also reuse the vocabulary for modeling and scoring.
Result vocabulary
The vocabulary contains the n-gram dictionary with the term frequency scores that are generated as part of the analysis. The DF and IDF scores are generated regardless of other options.
- ID: An identifier generated for each unique n-gram.
- NGram: The n-gram. Spaces or other word separators are replaced by the underscore character.
- DF: The term frequency score for the n-gram in the original corpus.
- IDF: The inverse document frequency score for the n-gram in the original corpus.
You can manually update this dataset, but you might introduce errors. For example:
- An error is raised if the component finds duplicate rows with the same key in the input vocabulary. Be sure that no two rows in the vocabulary have the same word.
- The input schema of the vocabulary datasets must match exactly, including column names and column types.
- The ID column and DF column must be of the integer type.
- The IDF column must be of the float type.
Note
Don't connect the data output to the Train Model component directly. You should remove free text columns before they're fed into the Train Model. Otherwise, the free text columns will be treated as categorical features.
Next steps
See the set of components available to Azure Machine Learning.