Using low priority VMs in batch deployments
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure Batch Deployments supports low priority VMs to reduce the cost of batch inference workloads. Low priority VMs enable a large amount of compute power to be used for a low cost. Low priority VMs take advantage of surplus capacity in Azure. When you specify low priority VMs in your pools, Azure can use this surplus, when available.
The tradeoff for using them is that those VMs may not always be available to be allocated, or may be preempted at any time, depending on available capacity. For this reason, they are most suitable for batch and asynchronous processing workloads where the job completion time is flexible and the work is distributed across many VMs.
Low priority VMs are offered at a significantly reduced price compared with dedicated VMs. For pricing details, see Azure Machine Learning pricing.
How batch deployment works with low priority VMs
Azure Machine Learning Batch Deployments provides several capabilities that make it easy to consume and benefit from low priority VMs:
- Batch deployment jobs consume low priority VMs by running on Azure Machine Learning compute clusters created with low priority VMs. Once a deployment is associated with a low priority VMs' cluster, all the jobs produced by such deployment will use low priority VMs. Per-job configuration is not possible.
- Batch deployment jobs automatically seek the target number of VMs in the available compute cluster based on the number of tasks to submit. If VMs are preempted or unavailable, batch deployment jobs attempt to replace the lost capacity by queuing the failed tasks to the cluster.
- Low priority VMs have a separate vCPU quota that differs from the one for dedicated VMs. Low-priority cores per region have a default limit of 100 to 3,000, depending on your subscription offer type. The number of low-priority cores per subscription can be increased and is a single value across VM families. See Azure Machine Learning compute quotas.
Considerations and use cases
Many batch workloads are a good fit for low priority VMs. Although this may introduce further execution delays when deallocation of VMs occurs, the potential drops in capacity can be tolerated at expenses of running with a lower cost if there is flexibility in the time jobs have to complete.
When deploying models under batch endpoints, rescheduling can be done at the mini batch level. That has the extra benefit that deallocation only impacts those mini-batches that are currently being processed and not finished on the affected node. Every completed progress is kept.
Creating batch deployments with low priority VMs
Batch deployment jobs consume low priority VMs by running on Azure Machine Learning compute clusters created with low priority VMs.
Note
Once a deployment is associated with a low priority VMs' cluster, all the jobs produced by such deployment will use low priority VMs. Per-job configuration is not possible.
You can create a low priority Azure Machine Learning compute cluster as follows:
Create a compute definition YAML like the following one:
low-pri-cluster.yml
$schema: https://azuremlschemas.azureedge.net/latest/amlCompute.schema.json
name: low-pri-cluster
type: amlcompute
size: STANDARD_DS3_v2
min_instances: 0
max_instances: 2
idle_time_before_scale_down: 120
tier: low_priority
Create the compute using the following command:
az ml compute create -f low-pri-cluster.yml
Once you have the new compute created, you can create or update your deployment to use the new cluster:
To create or update a deployment under the new compute cluster, create a YAML configuration like the following:
$schema: https://azuremlschemas.azureedge.net/latest/batchDeployment.schema.json
endpoint_name: heart-classifier-batch
name: classifier-xgboost
description: A heart condition classifier based on XGBoost
type: model
model: azureml:heart-classifier@latest
compute: azureml:low-pri-cluster
resources:
instance_count: 2
settings:
max_concurrency_per_instance: 2
mini_batch_size: 2
output_action: append_row
output_file_name: predictions.csv
retry_settings:
max_retries: 3
timeout: 300
Then, create the deployment with the following command:
az ml batch-endpoint create -f endpoint.yml
View and monitor node deallocation
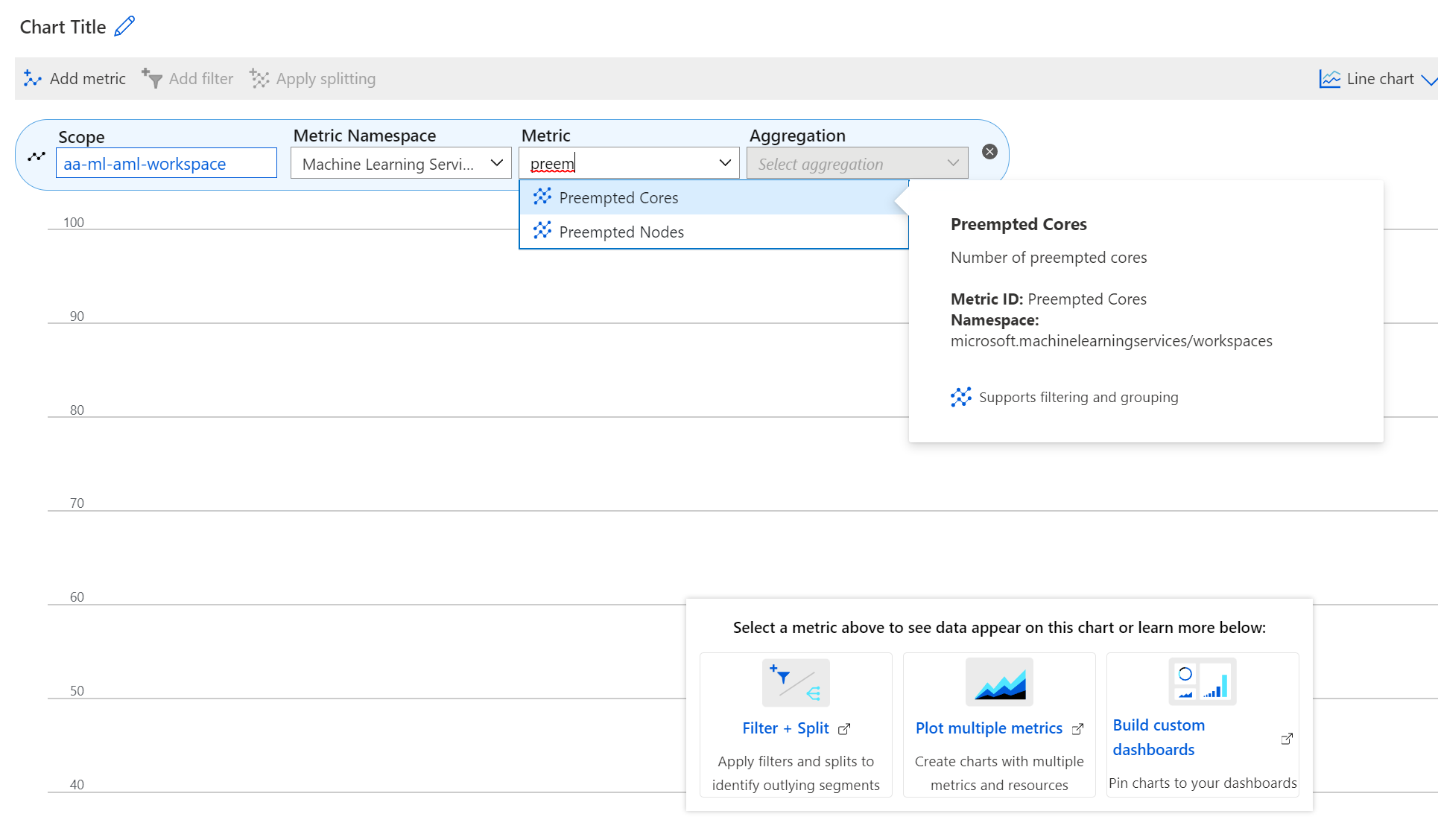
New metrics are available in the Azure portal for low priority VMs to monitor low priority VMs. These metrics are:
- Preempted nodes
- Preempted cores
To view these metrics in the Azure portal
- Navigate to your Azure Machine Learning workspace in the Azure portal.
- Select Metrics from the Monitoring section.
- Select the metrics you desire from the Metric list.
Limitations
- Once a deployment is associated with a low priority VMs' cluster, all the jobs produced by such deployment will use low priority VMs. Per-job configuration is not possible.
- Rescheduling is done at the mini-batch level, regardless of the progress. No checkpointing capability is provided.
Warning
In the cases where the entire cluster is preempted (or running on a single-node cluster), the job will be cancelled as there is no capacity available for it to run. Resubmitting will be required in this case.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for