Create an index in Azure AI Search
In Azure AI Search, query requests target the searchable text in a search index.
In this article, learn the steps for defining and publishing a search index. Creating an index establishes the physical data structures on your search service. Once the index definition exists, loading the index follows as a separate task.
Prerequisites
Write permissions. Permission can be granted through an admin API key on the request. Alternatively, if you're using role-based access control, send a request as a member of the Search Contributor role.
An understanding of the data you want to index. Creating an index is a schema definition exercise, so you should have a clear idea of which source fields you want to make searchable, retrievable, filterable, facetable, and sortable (see the schema checklist for guidance).
You must also have a unique field in source data that can be used as the document key (or ID) in the index.
A stable index location. Moving an existing index to a different search service isn't supported out-of-the-box. Revisit application requirements and make sure that your existing search service, its capacity and location, are sufficient for your needs.
Finally, all service tiers have index limits on the number of objects that you can create. For example, if you're experimenting on the Free tier, you can only have three indexes at any given time. Within the index itself, there are limits on the number of complex fields and collections.
Document keys
A search index has one required field: a document key. A document key is the unique identifier of a search document. In Azure AI Search, it must be a string, and it must originate from unique values in the data source that's providing the content to be indexed. A search service doesn't generate key values, but in some scenarios (such as the Azure table indexer) it synthesizes existing values to create a unique key for the documents being indexed.
During incremental indexing, where new and updated content is indexed, incoming documents with new keys are added, while incoming documents with existing keys are either merged or overwritten, depending on whether index fields are null or populated.
Schema checklist
Use this checklist to assist the design decisions for your search index.
Review naming conventions so that index and field names conform to the naming rules.
Review supported data types. The data type affects how the field is used. For example, numeric content is filterable but not full text searchable. The most common data type is
Edm.Stringfor searchable text, which is tokenized and queried using the full text search engine.Identify a document key. A document key is an index requirement. It's a single string field and it's populated from a source data field that contains unique values. For example, if you're indexing from Blob Storage, the metadata storage path is often used as the document key because it uniquely identifies each blob in the container.
Identify the fields in your data source that contribute searchable content in the index. Searchable content includes short or long strings that are queried using the full text search engine. If the content is verbose (small phrases or bigger chunks), experiment with different analyzers to see how the text is tokenized.
Field attribute assignments determine both search behaviors and the physical representation of your index on the search service. Determining how fields should be specified is an iterative process for many customers. To speed up iterations, start with sample data so that you can drop and rebuild easily.
Identify which source fields can be used as filters. Numeric content and short text fields, particularly those with repeating values, are good choices. When working with filters, remember:
Filterable fields can optionally be used in faceted navigation.
Filterable fields are returned in arbitrary order, so consider making them sortable as well.
Determine whether to use the default analyzer (
"analyzer": null) or a different analyzer. Analyzers are used to tokenize text fields during indexing and query execution.For multi-lingual strings, consider a language analyzer.
For hyphenated strings or special characters, consider specialized analyzers. One example is keyword that treats the entire contents of a field as a single token. This behavior is useful for data like zip codes, IDs, and some product names. For more information, see Partial term search and patterns with special characters.
Note
Full text search is conducted over terms that are tokenized during indexing. If your queries fail to return the results you expect, test for tokenization to verify the string actually exists. You can try different analyzers on strings to see how tokens are produced for various analyzers.
Create an index
When you're ready to create the index, use a search client that can send the request. You can use the Azure portal or REST APIs for early development and proof-of-concept testing.
During development, plan on frequent rebuilds. Because physical structures are created in the service, dropping and re-creating indexes is necessary for many modifications. You might consider working with a subset of your data to make rebuilds go faster.
Index design through the portal enforces requirements and schema rules for specific data types, such as disallowing full text search capabilities on numeric fields.
Sign in to the Azure portal.
In the search service Overview page, choose either option for creating a search index:
- Add index, an embedded editor for specifying an index schema
- Import data wizard
The wizard is an end-to-end workflow that creates an indexer, a data source, and a finished index. It also loads the data. If this is more than what you want, use Add index instead.
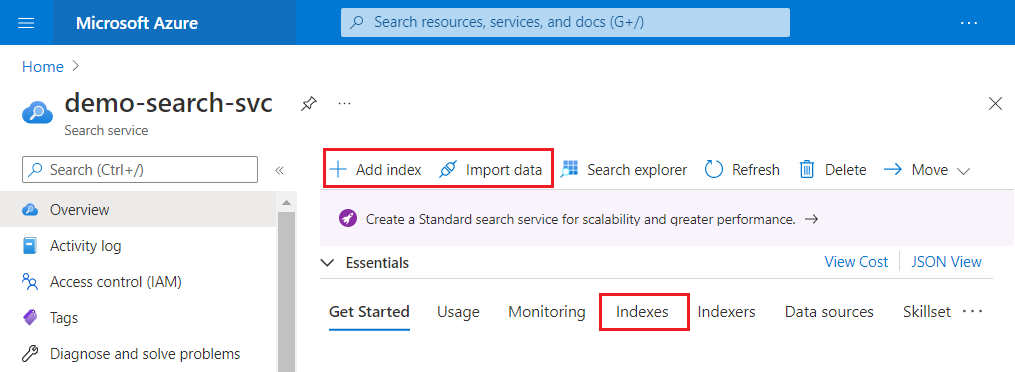
The following screenshot highlights where Add index and Import data appear on the command bar. After an index is created, you can find it again in the Indexes tab.
Tip
After creating an index in the portal, you can copy the JSON representation and add it to your application code.
Set corsOptions for cross-origin queries
Index schemas include a section for setting corsOptions. By default, client-side JavaScript can't call any APIs because browsers prevent all cross-origin requests. To allow cross-origin queries through to your index, enable CORS (Cross-Origin Resource Sharing) by setting the corsOptions attribute. For security reasons, only query APIs support CORS.
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
The following properties can be set for CORS:
allowedOrigins (required): This is a list of origins that are allowed access to your index. JavaScript code served from these origins is allowed to query your index (assuming the caller provides a valid key or has permissions). Each origin is typically of the form
protocol://<fully-qualified-domain-name>:<port>although<port>is often omitted. For more information, see Cross-origin resource sharing (Wikipedia).If you want to allow access to all origins, include
*as a single item in the allowedOrigins array. This isn't a recommended practice for production search services but it's often useful for development and debugging.maxAgeInSeconds (optional): Browsers use this value to determine the duration (in seconds) to cache CORS preflight responses. This must be a non-negative integer. A longer cache period delivers better performance, but it extends the amount of time a CORS policy needs to take effect. If this value isn't set, a default duration of five minutes is used.
Allowed updates on existing indexes
Create Index creates the physical data structures (files and inverted indexes) on your search service. Once the index is created, your ability to effect changes using Update Index is contingent upon whether your modifications invalidate those physical structures. Most field attributes can't be changed once the field is created in your index.
Alternatively, you can create an index alias that serves as a stable reference in your application code. Instead of updating your code, you can update an index alias to point to newer index versions.
To minimize churn in the design process, the following table describes which elements are fixed and flexible in the schema. Changing a fixed element requires an index rebuild, whereas flexible elements can be changed at any time without impacting the physical implementation.
| Element | Can be updated? |
|---|---|
| Name | No |
| Key | No |
| Field names and types | No |
| Field attributes (searchable, filterable, facetable, sortable) | No |
| Field attribute (retrievable) | Yes |
| Analyzer | You can add and modify custom analyzers in the index. Regarding analyzer assignments on string fields, you can only modify searchAnalyzer. All other assignments and modifications require a rebuild. |
| Scoring profiles | Yes |
| Suggesters | No |
| cross-origin resource sharing (CORS) | Yes |
| Encryption | Yes |
Next steps
Use the following links to become familiar with loading an index with data, or extending an index with a synonyms map.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for