Troubleshoot XMLA endpoint connectivity
XMLA endpoints in Power BI rely on the native Analysis Services communication protocol for access to Power BI semantic models. Because of this, XMLA endpoint troubleshooting is much the same as troubleshooting a typical Analysis Services connection. However, some differences around Power BI-specific dependencies apply.
Before you begin
Before troubleshooting an XMLA endpoint scenario, be sure to review the basics covered in Semantic model connectivity with the XMLA endpoint. Most common XMLA endpoint use cases are covered there. Other Power BI troubleshooting guides, such as Troubleshoot gateways - Power BI and Troubleshooting Analyze in Excel, can also be helpful.
Enabling the XMLA endpoint
The XMLA endpoint can be enabled on both Power BI Premium, Premium Per User, and Power BI Embedded capacities. On smaller capacities, such as an A1 capacity with only 2.5 GB of memory, you might encounter an error in Capacity settings when trying to set the XMLA Endpoint to Read/Write and then selecting Apply. The error states "There was an issue with your workload settings. Try again in a little while.".
Here are a couple things to try:
- Limit the memory consumption of other services on the capacity, such as Dataflows, to 40% or less, or disable an unnecessary service completely.
- Upgrade the capacity to a larger SKU. For example, upgrading from an A1 to an A3 capacity solves this configuration issue without having to disable Dataflows.
Keep in-mind, you must also enable the tenant-level Export data setting in the Power BI Admin Portal. This setting is also required for the Analyze in Excel feature.
Establishing a client connection
After enabling the XMLA endpoint, it's a good idea to test connectivity to a workspace on the capacity. To learn more, see Connecting to a Premium workspace. Also, be sure to read the section Connection requirements for helpful tips and information about current XMLA connectivity limitations.
Connecting with a service principal
If you've enabled tenant settings to allow service principals to use Power BI APIs, as described in Enable service principals, you can connect to an XMLA endpoint by using a service principal. Keep in mind the service principal requires the same level of access permissions at the workspace or semantic model level as regular users.
To use a service principal, be sure to specify the application identity information in the connection string as:
User ID=<app:appid@tenantid>Password=<application secret>
For example:
Data Source=powerbi://api.powerbi.com/v1.0/myorg/Contoso;Initial Catalog=PowerBI_Dataset;User ID=app:91ab91bb-6b32-4f6d-8bbc-97a0f9f8906b@19373176-316e-4dc7-834c-328902628ad4;Password=6drX...;
If you receive the following error:
"We cannot connect to the semantic model due to incomplete account information. For service principals, make sure you specify the tenant ID together with the app ID using the format app:<appId>@<tenantId>, then try again."
Make sure you specify the tenant ID together with the app ID using the correct format.
It's also valid to specify the app ID without the tenant ID. However, in this case, you must replace the myorg alias in the data source URL with the actual tenant ID. Power BI can then locate the service principal in the correct tenant. But, as a best practice, use the myorg alias and specify the tenant ID together with the app ID in the User ID parameter.
Connecting with Microsoft Entra B2B
With support for Microsoft Entra business-to-business (B2B) in Power BI, you can provide external guest users with access to semantic models over the XMLA endpoint. Make sure the Share content with external users setting is enabled in the Power BI Admin portal. To learn more, see Distribute Power BI content to external guest users with Microsoft Entra B2B.
Deploying a semantic model
You can deploy a tabular model project in Visual Studio (SSDT) to a workspace assigned to a Premium capacity, much the same as to a server resource in Azure Analysis Services. However, when deploying there are some additional considerations. Be sure to review the section Deploy model projects from Visual Studio (SSDT) in the semantic model connectivity with the XMLA endpoint article.
Deploying a new model
In the default configuration, Visual Studio attempts to process the model as part of the deployment operation to load data into the semantic model from the data sources. As described in Deploy model projects from Visual Studio (SSDT), this operation can fail because data source credentials cannot be specified as part of the deployment operation. Instead, if credentials for your data source aren't already defined for any of your existing semantic models, you must specify the data source credentials in the semantic model settings using the Power BI user interface (Semantic models > Settings > Data source credentials > Edit credentials). Having defined the data source credentials, Power BI can then apply the credentials to this data source automatically for any new semantic model, after metadata deployment has succeeded and the semantic model has been created.
If Power BI cannot bind your new semantic model to data source credentials, you will receive an error stating "Cannot process database. Reason: Failed to save modifications to the server." with the error code "DMTS_DatasourceHasNoCredentialError", as shown below:
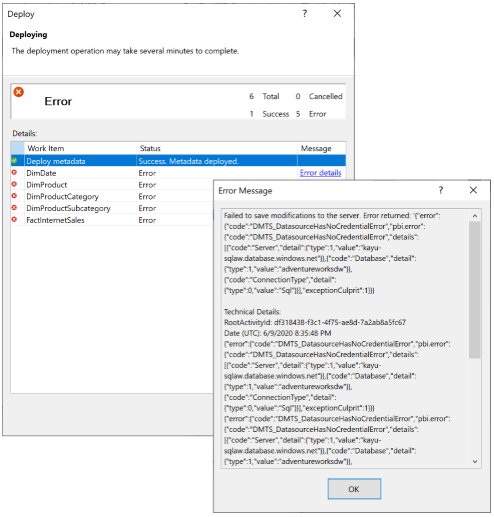
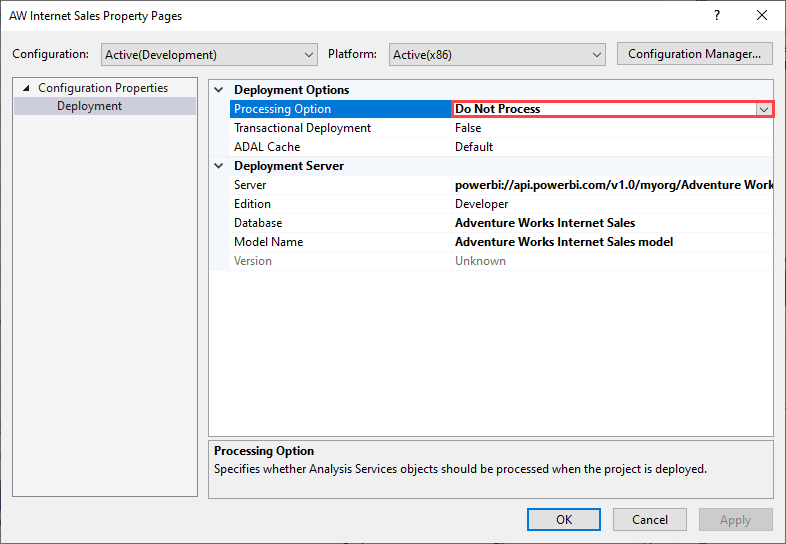
To avoid the processing failure, set the Deployment Options > Processing Options to Do not Process, as shown in the following image. Visual Studio then deploys only metadata. You can then configure the data source credentials, and click on Refresh now for the semantic model in the Power BI user interface.
New project from an existing semantic model
Creating a new tabular project in Visual Studio by importing the metadata from an existing semantic model is not supported. However, you can connect to the semantic model by using SQL Server Management Studio, script out the metadata, and reuse it in other tabular projects.
Migrating a semantic model to Power BI
It's recommended you specify the 1500 (or higher) compatibility level for tabular models. This compatibility level supports the most capabilities and data source types. Later compatibility levels are backwards compatible with earlier levels.
Supported data providers
At the 1500 compatibility level, Power BI supports the following data source types:
- Provider data sources (legacy with a connection string in the model metadata).
- Structured data sources (introduced with the 1400 compatibility level).
- Inline M declarations of data sources (as Power BI Desktop declares them).
It's recommended you use structured data sources, which Visual Studio creates by default when going through the Import data flow. However, if you are planning to migrate an existing model to Power BI that uses a provider data source, make sure the provider data source relies on a supported data provider. Specifically, the Microsoft OLE DB Driver for SQL Server and any third-party ODBC drivers. For OLE DB Driver for SQL Server, you must switch the data source definition to the .NET Framework Data Provider for SQL Server. For third-party ODBC drivers that might be unavailable in the Power BI service, you must switch to a structured data source definition instead.
It's also recommended you replace the outdated Microsoft OLE DB Driver for SQL Server (SQLNCLI11) in your SQL Server data source definitions with the .NET Framework Data Provider for SQL Server.
The following table provides an example of a .NET Framework Data Provider for SQL Server connection string replacing a corresponding connection string for the OLE DB Driver for SQL Server.
| OLE DB Driver for SQL Server | .NET Framework Data Provider for SQL Server |
|---|---|
Provider=SQLNCLI11;Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW;Trusted_Connection=yes; |
Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW2016;Integrated Security=SSPI;Encrypt=true;TrustServerCertificate=false |
Cross-referencing partition sources
Just as there are multiple data source types, there are also multiple partition source types a tabular model can include to import data into a table. Specifically, a partition can use a query partition source or an M partition source. These partition source types, in turn, can reference provider data sources or structured data sources. While tabular models in Azure Analysis Services support cross-referencing these various data source and partition types, Power BI enforces a more strict relationship. Query partition sources must reference provider data sources, and M partition sources must reference structured data sources. Other combinations are not supported in Power BI. If you want to migrate a cross-referencing semantic model, the following table describes supported configurations:
| Data source | Partition source | Comments | Supported with XMLA endpoint |
|---|---|---|---|
| Provider data source | Query partition source | The AS engine uses the cartridge-based connectivity stack to access the data source. | Yes |
| Provider data source | M partition source | The AS engine translates the provider data source into a generic structured data source and then uses the Mashup engine to import the data. | No |
| Structured data source | Query partition source | The AS engine wraps the native query on the partition source into an M expression and then uses the Mashup engine to import the data. | No |
| Structured data source | M partition source | The AS engine uses the Mashup engine to import the data. | Yes |
Data sources and impersonation
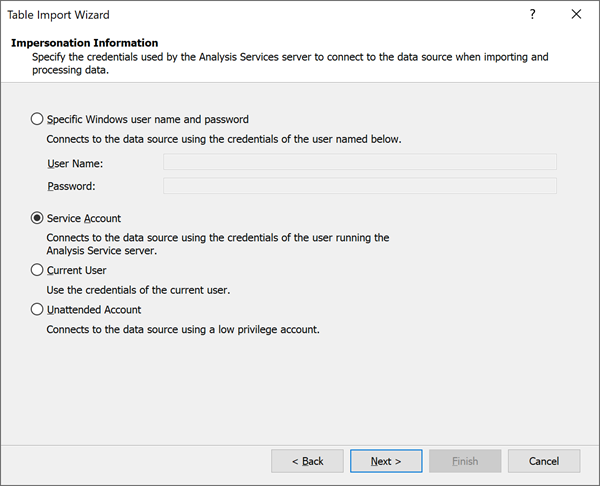
Impersonation settings you can define for provider data sources are not relevant for Power BI. Power BI uses a different mechanism based on semantic model settings to manage data source credentials. For this reason, make sure you select Service Account if you are creating a Provider Data Source.
Fine-grained processing
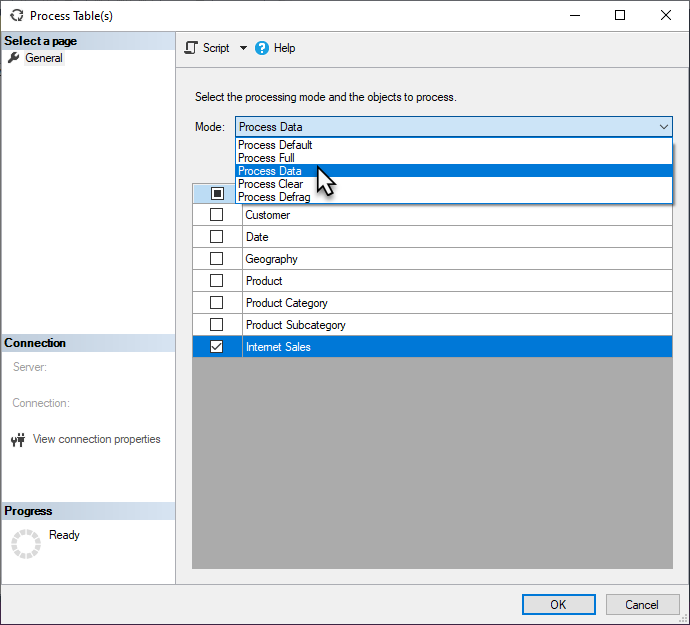
When triggering a scheduled refresh or on-demand refresh in Power BI, Power BI typically refreshes the entire semantic model. In many cases, it's more efficient to perform refreshes more selectively. You can perform fine-grained processing tasks in SQL Server Management Studio (SSMS) as shown below, or by using third-party tools or scripts.
Overrides in Refresh TMSL command
Overrides in Refresh command (TMSL) allow users choosing a different partition query definition or data source definition for the refresh operation.
Email subscriptions
Semantic models that are refreshed using an XMLA endpoint don't trigger an email subscription.
Errors on Premium capacity
Connect to Server error in SSMS
When connecting to a Power BI workspace with SQL Server Management Studio (SSMS), the following error may be displayed:
TITLE: Connect to Server
------------------------------
Cannot connect to powerbi://api.powerbi.com/v1.0/[tenant name]/[workspace name].
------------------------------
ADDITIONAL INFORMATION:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId:
Date (UTC): 10/6/2021 1:03:25 AM (Microsoft.AnalysisServices.AdomdClient)
------------------------------
The remote server returned an error: (400) Bad Request. (System)
When connecting to a Power BI workspace with SSMS, ensure the following:
- The XMLA endpoint setting is enabled for your tenant's capacity. To learn more, see Enable XMLA read-write.
- The Allow XMLA endpoints and Analyze in Excel with on-premises semantic models setting is enabled in Tenant settings.
- You're using the latest version of SSMS. Download the latest.
Query execution in SSMS
When connected to a workspace in a Power BI Premium or a Power BI Embedded capacity, SQL Server Management Studio may display the following error:
Executing the query ...
Error -1052311437: We had to move the session with ID '<Session ID>' to another Power BI Premium node. Moving the session temporarily interrupted this trace - tracing will resume automatically as soon as the session has been fully moved to the new node.
This is an informational message that can be ignored in SSMS 18.8 and higher because the client libraries will reconnect automatically. Note that client libraries installed with SSMS v18.7.1 or lower do not support session tracing. Download the latest SSMS.
Executing a large command using the XMLA endpoint
When executing a large command using the XMLA endpoint, you may encounter the following error:
Executing the query ...
Error -1052311437:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId: 3716c0f7-3d01-4595-8061-e6b2bd9f3428
Date (UTC): 11/13/2020 7:57:16 PM
Run complete
When using SSMS v18.7.1 or lower to perform a long running (>1 min) refresh operation on a semantic model in a Power BI Premium or a Power BI Embedded capacity, SSMS may display this error even though the refresh operation succeeds. This is due to a known issue in the client libraries where the status of the refresh request is incorrectly tracked. This is resolved in SSMS 18.8 and higher. Download the latest SSMS.
This error can also occur when a very large request needs to be redirected to a different node in the Premium cluster. It's often seen when you try to create or alter a semantic model using a large TMSL script. In such cases, the error can usually be avoided by specifying the Initial Catalog to the name of the database before executing the command.
When creating a new database, you can create an empty semantic model, for example:
{
"create": {
"database": {
"name": "DatabaseName"
}
}
}
After you create the new semantic model, specify the Initial Catalog and then make changes to the semantic model.
Other client applications and tools
Client applications and tools such as Excel, Power BI Desktop, SSMS, or external tools connecting to and working with semantic models in Power BI Premium capacities may cause the following error: The remote server returned an error: (400) Bad Request.. The error can be caused especially if an underlying DAX query or XMLA command is long running. To mitigate potential errors, be sure to use the most recent applications and tools that install recent versions of the Analysis Services client libraries with regular updates. Regardless of application or tool, the minimum required client library versions to connect to and work with semantic models in a Premium capacity through the XMLA endpoint are:
| Client Library | Version |
|---|---|
| MSOLAP | 15.1.65.22 |
| AMO | 19.12.7.0 |
| ADOMD | 19.12.7.0 |
Editing role memberships in SSMS
When using the SQL Server Management Studio (SSMS) v18.8 to edit a role membership on a semantic model, SSMS may display the following error:
Failed to save modifications to the server.
Error returned: ‘Metadata change of current operation cannot be resolved, please check the command or try again later.’
This is due to a known issue in the app services REST API. This will be resolved in an upcoming release. In the meantime, to get around this error, in Role Properties, click Script, and then enter and execute the following TMSL command:
{
"createOrReplace": {
"object": {
"database": "AdventureWorks",
"role": "Role"
},
"role": {
"name": "Role",
"modelPermission": "read",
"members": [
{
"memberName": "xxxx",
"identityProvider": "AzureAD"
},
{
"memberName": “xxxx”
"identityProvider": "AzureAD"
}
]
}
}
}
Publish Error - Live connected semantic model
When republishing a live connected semantic model utilizing the Analysis Services connector, the following error, "There is an existing report/semantic model with the same name. Please delete or rename the existing semantic model and retry." may be shown.
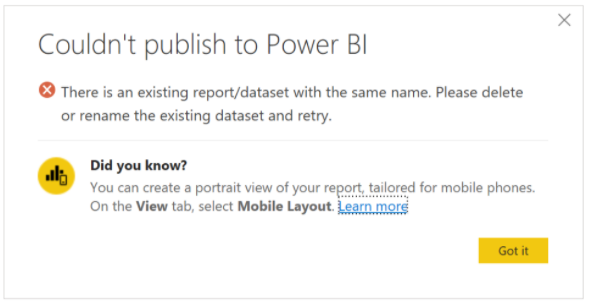
This is due to the semantic model being published having a different connection string but having the same name as the existing semantic model. To resolve this issue, either delete or rename the existing semantic model. Also be sure to republish any apps that are dependent on the report. If necessary, downstream users should be informed to update any bookmarks with the new report address to ensure they access the latest report.
Workspace/server alias
Unlike Azure Analysis Services, server name aliases are not supported for Premium workspaces.
DISCOVER_M_EXPRESSIONS
The DMV DISCOVER_M_EXPRESSIONS data management view (DMV) is currently not supported in Power BI using the XMLA Endpoint. Applications can use the Tabular object model (TOM) to obtain M expressions used by the data model.
Resource governing command memory limit in Premium
Premium capacities use resource governing to ensure no single semantic model operation can exceed the amount of available memory resources for the capacity - determined by SKU. For example, a P1 subscription has an effective memory limit per item of 25 GB, for a P2 subscription the limit is 50 GB, and for a P3 subscription the limit is 100 GB. In addition to semantic model (database) size, the effective memory limit also applies to underlying semantic model command operations like Create, Alter, and Refresh.
The effective memory limit for a command is based on the lesser of the capacity's memory limit (determined by SKU) or the value of the DbpropMsmdRequestMemoryLimit XMLA property.
For example, for a P1 capacity, if:
DbpropMsmdRequestMemoryLimit = 0 (or unspecified), the effective memory limit for the command is 25 GB.
DbpropMsmdRequestMemoryLimit = 5 GB, the effective memory limit for the command is 5 GB.
DbpropMsmdRequestMemoryLimit = 50 GB, the effective memory limit for the command is 25 GB.
Typically, the effective memory limit for a command is calculated on the memory allowed for the semantic model by the capacity (25 GB, 50 GB, 100 GB) and how much memory the semantic model is already consuming when the command starts executing. For example, a semantic model using 12 GB on a P1 capacity allows an effective memory limit for a new command of 13 GB. However, the effective memory limit can be further constrained by the DbPropMsmdRequestMemoryLimit XMLA property when optionally specified by an application. Using the previous example, if 10 GB is specified in the DbPropMsmdRequestMemoryLimit property, then the command’s effective limit is further reduced to 10 GB.
If the command operation attempts to consume more memory than allowed by the limit, the operation can fail, and an error is returned. For example, the following error describes an effective memory limit of 25 GB (P1 capacity) has been exceeded because the semantic model already consumed 12 GB (12288 MB) when the command started execution, and an effective limit of 13 GB (13312 MB) was applied for the command operation:
"Resource governing: This operation was canceled because there wasn’t enough memory to finish running it. Either increase the memory of the Premium capacity where this semantic model is hosted or reduce the memory footprint of your semantic model by doing things like limiting the amount of imported data. More details: consumed memory 13312 MB, memory limit 13312 MB, database size before command execution 12288 MB. Learn more: https://go.microsoft.com/fwlink/?linkid=2159753."
In some cases, as shown in the following error, "consumed memory" is 0 but the amount shown for "database size before command execution" is already greater than the effective memory limit. This means the operation failed to begin execution because the amount of memory already used by the semantic model is greater than the memory limit for the SKU.
"Resource governing: This operation was canceled because there wasn’t enough memory to finish running it. Either increase the memory of the Premium capacity where this semantic model is hosted or reduce the memory footprint of your semantic model by doing things like limiting the amount of imported data. More details: consumed memory 0 MB, memory limit 25600 MB, database size before command execution 26000 MB. Learn more: https://go.microsoft.com/fwlink/?linkid=2159753."
To potentially avoid exceeding the effective memory limit:
- Upgrade to a larger Premium capacity (SKU) size for the semantic model.
- Reduce the memory footprint of your semantic model by limiting the amount of data loaded with each refresh.
- For refresh operations through the XMLA endpoint, reduce the number of partitions being processed in parallel. Too many partitions being processed in parallel with a single command can exceed the effective memory limit.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for