Windows HPC Server 2008
High Performance Computing in the Real World
Joshua M. Kunken
At a Glance:
- Setting up and managing the compute cluster
- Submitting jobs to the HPC scheduler using Windows PowerShell
- Processing spreadsheet data on the server
- Making processed data available to end users
Contents
Why HPC 2008?
Hit the Floor Running
Accessing the Compute Cluster
Administration
Taking Advantage of Windows PowerShell
Application Development
Server/cluster-side Processing of Spreadsheets
Client-side Access to Processed Data
A Very Large Dataset
Windows HPC Server 2008 (HPC 2008), the latest Microsoft parallel computing package, was specifically designed for use in compute-intensive environments, which exactly describes our research laboratory. This article describes the deployment of a wide variety of Microsoft technologies, in particular HPC 2008, in the development of a custom system that enables the automated processing of data generated from an imaging device in a life science laboratory.
The system is capable of performing unattended and automated Excel spreadsheet data analysis, including nonlinear regression. Where such analysis would typically require a research scientist to spend 10 to 15 minutes per experiment, it now takes less than half an hour to process 96 experiments at a time (without human intervention—and error). It takes even less time if a computing cluster is used.
Our solution also uses a small set of Windows PowerShell scripts, deployed on the HPC 2008 compute cluster, that process en masse hundreds of gigabytes worth of XML files within a very short time frame. The aim is to illustrate how you can leverage Microsoft High Performance Compute Cluster 2008 along with other Microsoft technologies to readily develop applications capable of performing high-level analysis and processing of file types routinely used in a variety of fields ranging from finance to medicine.
Why HPC 2008?
Our decision to use HPC 2008 was based on several factors. First, HPC 2008 integrates very well with our existing Active Directory infrastructure. This enables us to allow existing Active Directory users, distributed across different geographic locations, to submit jobs as well as extend their access rights across the cluster using their existing username/password pairs. There is no need for them to have multiple credentials to submit jobs across the cluster as well as log on to their workstations.
Second, lab scientists deal with Excel spreadsheets constantly to keep track of experimental results and to perform further analyses. We needed to process Excel spreadsheets computationally and it would be difficult to do so on a non-Windows platform. Third, we could execute applications developed on the Microsoft .NET Framework using C#, which made it easier to perform calculations on data extracted from Excel spreadsheets on a Windows compute cluster. Finally, we could also use such applications to easily transmit information to SQL Server database tables.
Hit the Floor Running
HPC 2008 makes it fairly easy to take off-the-shelf hardware and set up a compute cluster. With a relatively small cluster, it takes only hours to get all of the compute nodes up and running and communicating with the head (or master) node. And due to the nature of parallel computing, it takes the same amount of time to deploy HPC 2008 and Windows Server 2008 to a small set of perhaps eight compute nodes as to a set ranging in the hundreds.
After setting up our head node with Windows Server 2008 and HPC 2008, we were able to quickly join it to our Active Directory domain (running on Windows Server 2003 R2). We then created a hard disk image (containing a copy of Windows Server 2008 along with HPC 2008) based on the head node, and deployed the disk image across our many compute nodes. Using the HPC 2008 Network Configuration wizard (see Figure 1), we selected a network topology in which our head node was accessible via public IP address while the compute nodes received non-public IP addresses from the head node via the DHCP role deployed on Windows Server 2008. You can also easily deploy the many other roles such as DNS, WINS, and RAS that are relevant to setting up a compute cluster either in standalone mode or joined to a Windows domain.
Figure 1 Selecting a network topology
Accessing the Compute Cluster
Windows Server 2008 comes with a brand-new version of the Remote Desktop Connection ( RDC) application, mstsc.exe. With RDC, system administrators can connect to and control other Windows hosts ( Windows Vista clients as well as Windows Server clients) through a graphical client directly over a TCP/IP connection. Windows Vista also comes with a new version of RDC that makes it easy to access the HPC 2008 compute cluster's head node and compute nodes. When logged on to the head node, cluster administrators can add new nodes, remove nodes, deploy or cancel jobs across nodes, and perform many other administrative functions.
The HPC Cluster Manager console gives the cluster administrator, as well as those with appropriate privileges, a user-friendly interface for submitting jobs and tasks manually (see Figure 2). This is where you specify the working directory, path to executables, output folders, and advanced parameters, as well as the minimum and maximum number of CPU cores, compute nodes, node groups, and node types.
Figure 2 Specifying a job in the console
Administration
With the built-in HPC Cluster Manager, you can easily configure and administer cluster compute nodes, monitor which jobs are running on which nodes, determine which nodes are in use at capacity at any given moment, and control which job types are running on any particular node. Further, the cluscfg utility allows users to obtain at-a-glance statistics, including how many processors are in-use, how many are idle, and which compute nodes require maintenance.
The clusrun command lets you explore the number of jobs running at any given time, as well as quickly see how many compute nodes and CPUs are currently in use. You can also open the HPC Cluster Manager console to view the list of jobs running on the cluster as a whole, as well as jobs still in queue, jobs that have completed, and those that are stalling. If jobs are stalling, you can drill down on a single job or task to investigate the cause.
In our experience, the typical causes of failed jobs on the compute cluster include poorly mounted file shares or trust not set on shares across multiple compute nodes; poorly set access control list permissions; and inadequate permission settings for execution of Windows PowerShell scripts across compute nodes. Resolving these issues is relatively straightforward.
The HPC Cluster Manager console allows you to see the health of all compute nodes in a single snapshot as well as in the more visually intuitive heat map view. Here, you can quickly get a glimpse of how resources are being consumed on each node by all of the jobs submitted. Diagnostics tests can also be performed across all compute nodes at once (see Figure 3) and the results from these tests provide the cluster administrator with relevant information for resolving issues across the whole set of nodes or for individual groups. Further, HPC 2008 also provides very useful graphical displays showing compute cluster usage across a variety of time periods (Figure 4). These pie charts and key performance indicators let relevant decision makers determine whether server and IT resources are properly allocated.
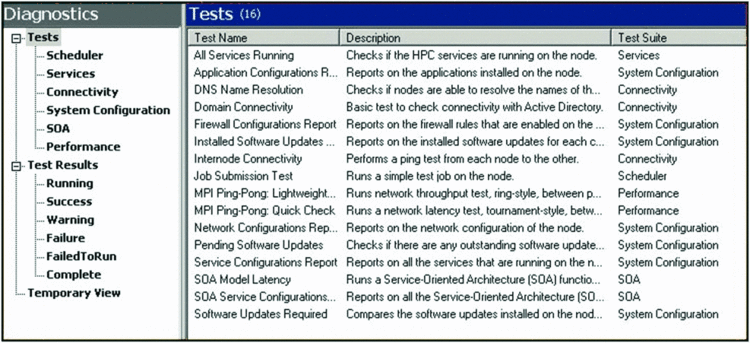
Figure 3 Tests can be performed across all compute nodes at once.
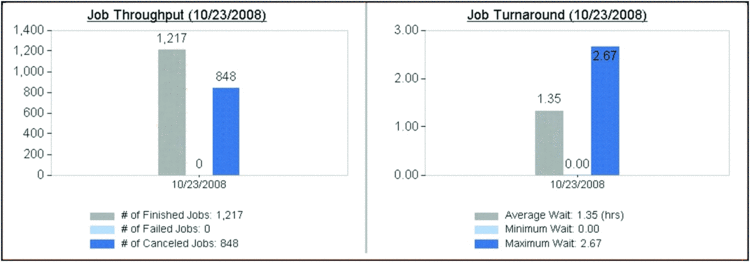
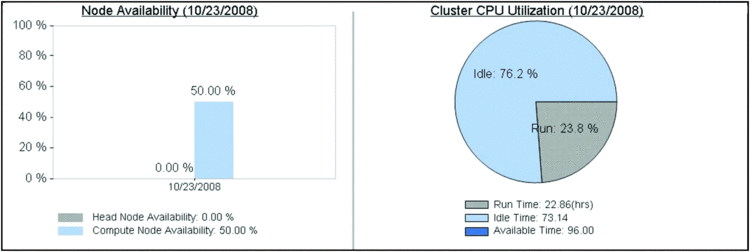
Figure 4 Useful information is readily available.
Taking Advantage of Windows PowerShell
With HPC 2008, you can not only submit jobs interactively to the scheduler via the HPC Cluster Manager console, you can also do this via the command line or through Windows PowerShell, enabling users to automate jobs via the Task Scheduler, C# system calls, or Windows PowerShell calls.
Our project makes use of a primary Windows PowerShell script that queries a networked file share. The share serves as an input directory of files waiting to be processed that were deposited by the imaging system subsequent to experiments being performed. The script proceeds by checking an output directory for post-process output files. If input files have not yet been processed (that is, if output files are not found within the output directory), the script generates individual child scripts specifically for submitting individual jobs to the HPC scheduler via the command line. The main Windows PowerShell script then iteratively submits all such child scripts to the scheduler by piping them into job.exe, the HPC command-line job submission executable. The job scheduler lets you submit any job or task to the HPC compute cluster using a variety of arguments, giving you a flexible set of options for running an application on the cluster.
Application Development
Our core software development efforts relied on Visual Studio Professional 2008, which provides the ability to develop console, Windows, and Web applications. Visual Studio enables developers to design a visually appealing graphical user interface while simultaneously working on the underlying business logic within the same project.
For our project, we developed several applications based on the same core business logic to suit different needs. We started with a Windows presentation Foundation ( WPF) application for processing our input Excel spreadsheets, thus enabling our researchers to manually test different initial fitting parameters to determine whether a larger set of experiments ( based on similar fitting parameters) could be processed automatically on the HPC compute cluster.
Next, we built a console application to actually run on the HPC compute cluster; it accepts a number of arguments, including a file path to an input spreadsheet, as well as seed fitting parameters. Windows PowerShell provides the arguments to the application while simultaneously submitting the task to the HPC compute cluster via the command line. The console application, running on every individual compute node, processes the input spreadsheets while also generating output spreadsheets containing the solutions and simultaneously performing SQL Server INSERT queries to keep track of results from all experiments. The .Net Framework 3.0 System.IO.Packaging API is leveraged on every node to process the spreadsheets for their content. Once values are obtained from the input sheets, C# is used to handle the rest.
We also developed a more graphical WPF application that lets researchers view results sent to SQL Server from the HPC compute cluster. A subset of the experiments undertaken in our laboratory is performed within standard 96-well plates routinely used in structural biology, and the user interface of the WPF application reflects the physical plate configuration (see Figure 5). Users need only click on one well to retrieve results for the single experiment trial. Clicking on a well initiates SQL Server queries against several database tables to retrieve results previously processed on the HPC compute cluster and submitted to the tables. We also used a ListView control holding a GridView control to provide a high-level overview of all 96 trials for a single experiment. Researchers can obtain a sortable table displaying all fitting parameters and statistical analyses for their processed experiments. This table becomes available as soon as the HPC compute cluster finishes processing the respective spreadsheets. Finally, we made use of SSH tunnels within the application, enabling end users to securely track their experimental results from outside the lab.
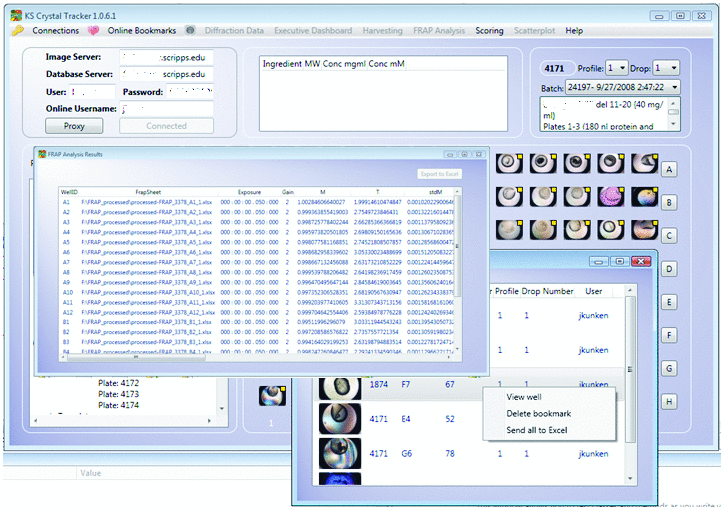
Figure 5 The application’s graphical interface
HPC Resources
| Windows HPC Server 2008 |
|
| Windows HPC TechCenter technet.microsoft.com/en-us/hpc/ |
|
| Windows HPC Community Portal windowshpc.net/Pages/ |
|
| The Windows HPC Team Blog blogs.technet.com/WindowsHPC/ |
|
| Evaluate Windows HPC Server 2008 technet.microsoft.com/en-us/cc835241.aspx |
|
| An Introduction to Windows Compute Cluster Server technet.microsoft.com/en-us/magazine/2008.02.ccs.aspx |
|
| Scripting for Windows HPC |
|
| Windows HPC Server Deployment, Management, and Administration social.microsoft.com/Forums/en-US/windowshpcitpros/threads/ |
Server/cluster-side Processing of Spreadsheets
Researchers in our laboratory are keen on observing changes in conditions over very brief timescales within each of the 96 wells used in the experiments. Conditional changes are recorded using digital cameras attached to microscopes. Software then converts digital imagery information to numerical intensity levels, on a temporal basis, which are then stored within Excel spreadsheets. These spreadsheets can be processed manually and the resulting data is fitted, via nonlinear regression, with carefully crafted mathematical functions.
The point of fitting the experimental data with regression curves is to determine fitting parameters, which can shed light on the experimental changes in conditions. However, the painstaking process behind calculations and curve fitting requires, at minimum, 10 minutes per well and carries the potential for human error as well as the tedium associated with cut-and-paste operations.
Within Task Scheduler (the snap-in replacing Scheduled Tasks in Windows Server 2008), we enable the server-side application to run at predefined intervals. If the main Windows PowerShell script finds unprocessed spreadsheets on the file server, it generates a job submission script that is then deployed to the job scheduler, which then calls on the server-side processing application (residing on every compute node through a shared folder) to process the unprocessed data.
SQL Server, running on a remote server, is used to organize results obtained after processing Excel spreadsheet data per each experiment (that is, per plate well ). Our scientists are interested in viewing both the raw spreadsheet output and an intuitive visual representation of experimental results in a user-friendly format, which we provide. The server-side application not only generates results spreadsheets containing the nonlinear regression parameters, associated statistics (goodness of fit and so forth), and curve plots, it also executes SQL queries storing the same information into an associated database table containing data for all experiments. This lets end users query information more efficiently (via GUI ), rather than laboriously searching through many files worth of spreadsheets.
Client-side Access to Processed Data
The graphical application we developed to facilitate end users' viewing of processed data is used to execute remote queries against the SQL Server containing processed results and to present query results to end users in a friendly format. Moreover, end users can export results from SQL Server to Excel spreadsheets directly from the GUI, allowing them to incorporate their results into publications and presentations. The ability to export results to a new Excel spreadsheet depends on results from SQL Server being bound through a DataSet data structure to a ListView control in the application. Researchers can now view experiment results from a consolidated perspective that they were not able to leverage before. Whereas it would normally take a lab member 16 hours to process a single 96-well plate (at 10 minutes per well), it now takes a fraction of that time.
A Very Large Dataset
In addition to leveraging HPC 2008 in automating the processing of Excel spreadsheets generated from our imaging system, we also use the Windows compute cluster to process queries against datasets containing tens of thousands of content-rich XML files. Our XML library consists of 300GB worth of XML files, each containing more than one hundred nodes or fields against which we can perform queries. Clearly, with such a large dataset, it becomes unfeasible to import our XML library into a single SQL Server database instance while also keeping it current.
Database performance suffers as soon as database files exceed a certain size threshold (more than 100GB). Consequently, sharing our XML library across a large number of compute nodes and distributing the sum of our queries across all compute cluster nodes results in minimal query turnaround time for such a large search space. At the same time, by storing the contents of the library on a single file server share, we keep dataset maintenance overhead to a minimum.
Joshua M. Kunken serves as system developer and administrator at The Scripps Research Institute in La Jolla, California. He earned his Bachelor's degree at the University of California, Berkeley. You can reach Josh at jkunken@scripps.edu. The work described in this article was supported by the Accelerated Technologies Center for Gene to 3D Structure.