Training
Module
Run prompts with Semantic Kernel - Training
This module explores Semantic Kernel SDK plugins. Learn how plugins to the SDK are used to accomplish customized tasks and create intelligent applications.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Semantic Kernel provides many different components, that can be used individually or together. This article gives an overview of the different components and explains the relationship between them.
The Semantic Kernel AI service connectors provide an abstraction layer that exposes multiple AI service types from different providers via a common interface. Supported services include Chat Completion, Text Generation, Embedding Generation, Text to Image, Image to Text, Text to Audio and Audio to Text.
When an implementation is registered with the Kernel, Chat Completion or Text Generation services will be used by default, by any method calls to the kernel. None of the other supported services will be used automatically.
Tip
For more information on using AI services see Adding AI services to Semantic Kernel.
The Semantic Kernel Vector Store connectors provide an abstraction layer that exposes vector stores from different providers via a common interface. The Kernel does not use any registered vector store automatically, but Vector Search can easily be exposed as a plugin to the Kernel in which case the plugin is made available to Prompt Templates and the Chat Completion AI Model.
Tip
For more information on using memory connectors see Adding AI services to Semantic Kernel.
Plugins are named function containers. Each can contain one or more functions. Plugins can be registered with the kernel, which allows the kernel to use them in two ways:
Functions can easily be created from many sources, including from native code, OpenAPI specs, ITextSearch implementations for RAG scenarios, but also from prompt templates.
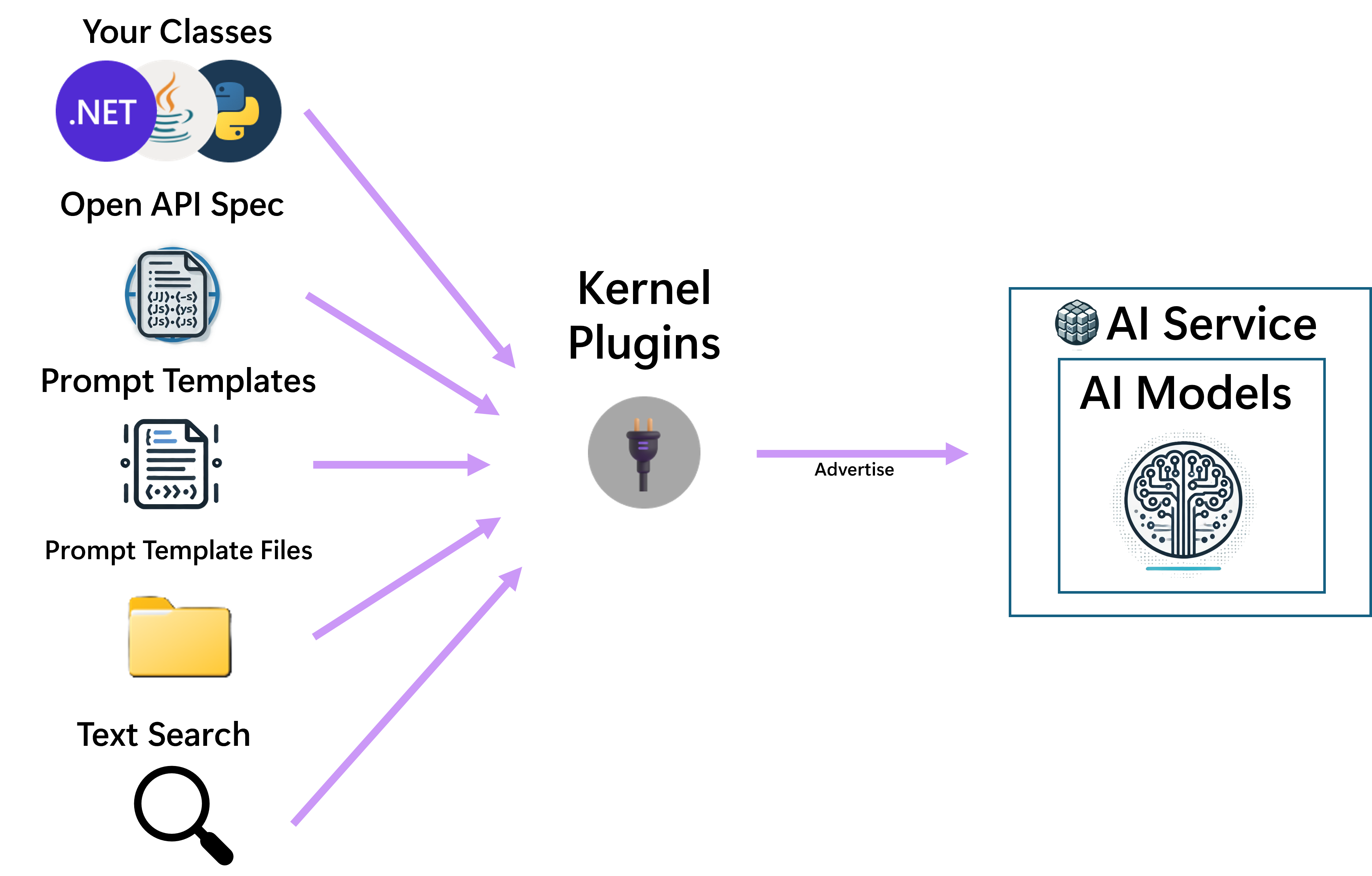
Tip
For more information on different plugin sources see What is a Plugin?.
Tip
For more information on advertising plugins to the chat completion AI see Function calling with chat completion.
Prompt templates allow a developer or prompt engineer to create a template that mixes context and instructions for the AI with user input and function output. E.g. the template may contain instructions for the Chat Completion AI model, and placeholders for user input, plus hardcoded calls to plugins that always need to be executed before invoking the Chat Completion AI model.
Prompt templates can be used in two ways:
When a prompt template is used, it will first be rendered, plus any hardcoded function references that it contains will be executed. The rendered prompt will then be passed to the Chat Completion AI model. The result generated by the AI will be returned to the caller. If the prompt template had been registered as a plugin function, the function may have been chosen for execution by the Chat Completion AI model and in this case the caller is Semantic Kernel, on behalf of the AI model.
Using prompt templates as plugin functions in this way can result in rather complex flows. E.g. consider the scenario where a prompt template A is registered as a plugin.
At the same time a different prompt template B may be passed to the kernel to start the chat completion flow. B could have a hardcoded call to A.
This would result in the following steps:
B rendering starts and the prompt execution finds a reference to AA is rendered.A is passed to the Chat Completion AI model.B.B completes.B is passed to the Chat Completion AI model.Also consider the scenario where there is no hardcoded call from B to A.
If function calling is enabled, the Chat Completion AI model may still decide that A should be invoked
since it requires data or functionality that A can provide.
Registering prompt templates as plugin functions allows for the possibility of creating functionality that is described using human language instead of actual code. Separating the functionality into a plugin like this allows the AI model to reason about this separately to the main execution flow, and can lead to higher success rates by the AI model, since it can focus on a single problem at a time.
See the following diagram for a simple flow that is started from a prompt template.

Tip
For more information on prompt templates see What are prompts?.
Filters provide a way to take custom action before and after specific events during the chat completion flow. These events include:
Filters need to be registered with the kernel to get invoked during the chat completion flow.
Note that since prompt templates are always converted to KernelFunctions before execution, both function and prompt filters will be invoked for a prompt template. Since filters are nested when more than one is available, function filters are the outer filters and prompt filters are the inner filters.

Tip
For more information on filters see What are Filters?.
Training
Module
Run prompts with Semantic Kernel - Training
This module explores Semantic Kernel SDK plugins. Learn how plugins to the SDK are used to accomplish customized tasks and create intelligent applications.
Documentation
Add chat completion services to Semantic Kernel
Learn how to add gpt-4, Mistral, Google, and other chat completion services to your Semantic Kernel project.
Add AI services to Semantic Kernel
Learn how to bring multiple AI services to your Semantic Kernel project.
In-depth Semantic Kernel Demos
Go deeper with additional Demos to learn how to use Semantic Kernel.