Mechanics and guidelines of lease, cluster, and health check timeouts for Always On availability groups
Differences in hardware, software, and cluster configurations as well as different application requirements for uptime and performance require specific configuration for lease, cluster, and health check timeout values. Certain applications and workloads require more aggressive monitoring to limit downtime following hard failures. Others require more tolerance for transient network issues and waits from high resource usage and are okay with slower failovers.
Multiple services on each node work to detect failures. The cluster service could detect quorum loss, the resource DLL could detect an issue surfaced by Always On health detection, or manual failover may be initiated directly on the primary instance. The cluster service, the resource host, and the SQL Server instance synchronize with each other via RPC, shared memory, and T-SQL. In most scenarios, these services successfully communicate, however this communication is not perfectly reliable even between services on the same machine. Furthermore, the availability group (AG) needs to be able to withstand system wide events like network and disk failures, which may prevent communication or interrupt functionality. With many failure cases and without fully dependable communication between services, the AG depends on various failover detection mechanisms to detect and respond to failures independently of each other so the cluster state is always consistent for all nodes.
Cluster node and resource detection
Each node in the cluster runs a single cluster service, which operates the failover cluster and monitors all cluster resources. The resource host operates as a separate process and is the interface between the cluster service and cluster resources. The resource host performs operations on cluster resources when called upon by the cluster service. Cluster aware applications like SQL Server provide custom interfaces to the resource monitor via resource DLLs. The resource DLL implements online and offline operations and health monitoring for custom resources. The resource host is a child process of the cluster service and is killed whenever the cluster service is killed.
For SQL Server, the AG resource DLL determines the health of the AG based on the AG lease mechanism and Always On health detection. The AG resource DLL exposes the resource health through the IsAlive operation. The resource monitor polls IsAlive at the cluster heartbeat interval, which is set by the CrossSubnetDelay and SameSubnetDelay cluster-wide values. On a primary node, the cluster service initiates failovers whenever the IsAlive call to the resource DLL returns that the AG is not healthy.
The cluster service sends heartbeats to other nodes in the cluster and acknowledges heartbeats received from them. When a node detects a communication failure from a series of unacknowledged heartbeats, it broadcasts a message causing all reachable nodes to reconcile their views of cluster node health. This event, called a regroup event, maintains consistency of the cluster state across nodes. Following a regroup event, if quorum is lost then all cluster resources including AGs in this partition are taken offline. All nodes in this partition are transitioned to a resolving state. If a partition exists, which holds a quorum, the AG will be assigned to one node in the partition and become the primary replica while all other nodes will be secondary replicas.
Always On health detection
The Always On resource DLL monitors the status of internal SQL Server components. sp_server_diagnostics reports the health of these components SQL Server on an interval controlled by HealthCheckTimeout. sp_server_diagnostics reports health status of five instance level components: system, resource, query processing, io subsystem and events. It also reports the health of each AG. Upon each update, the resource DLL updates the health status of the AG resource based upon the failure level of the AG. When data is returned by sp_server_diagnostics, it shows each component as either in a clean, warning, error or unknown state with some XML data describing the state of the component. For health detection, the resource DLL only takes action if a component is in an error state.
If health detection fails to report an update to the resource DLL for multiple intervals then the AG is determined unhealthy and will report failures on IsAlive calls.
Lease mechanism
Unlike other failover mechanisms, the SQL Server instance plays an active role in the lease mechanism. The lease mechanism is used as a Looks-Alive validation between the Cluster resource host and the SQL Server process. The mechanism is used to ensure that the two sides (the Cluster Service and SQL Server service) are in frequent contact, checking each other's state and ultimately preventing a split-brain scenario. When bringing the AG online as the primary replica, the SQL Server instance spawns a dedicated lease worker thread for the AG. The lease worker shares a small region of memory with the resource host containing lease renewal and lease stop events. The lease worker and resource host work in a circular fashion, signaling their respective lease renewal event and then sleeping, waiting for the other party to signal its own lease renewal event or stop event. Both the resource host and the SQL Server lease thread maintain a time-to-live value, which is updated each time the thread wakes up after being signaled by the other thread. If the time-to-live is reached while waiting for the signal, the lease expires and then replica transitions to the resolving state for that specific AG. If the lease stop event is signaled, then the replica transitions to a resolving role.
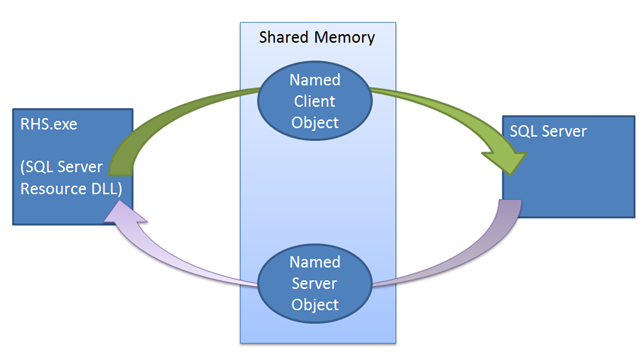
The lease mechanism enforces synchronization between SQL Server and Windows Server Failover Cluster. When a failover command is issued the cluster service makes an offline call to the resource DLL of the current primary replica. The resource DLL first attempts to take the AG offline using a stored procedure. If this stored procedure fails or times-out, the failure is reported back to the cluster service, which then issues a terminate command. The terminate again attempts to execute the same stored procedure, but the cluster this time does not wait for the resource DLL to report success or failure before bringing the AG online on a new replica. If this second procedure call fails, then the resource host will have to rely on the lease mechanism to take the instance offline. When the resource DLL is called to take the AG offline, the resource DLL signals the lease stop event, waking up the SQL Server lease worker thread to take the AG offline. Even if this stop event is not signaled, the lease will expire, and the replica will transition to the resolving state.
The lease is primarily a synchronization mechanism between the primary instance and the cluster, but it can also create failure conditions where there was otherwise no need to fail over. For example, high CPU, out-of-memory conditions (low virtual memory, process paging), SQL process not responding while generating a memory dump, system not responding, cluster (WSFC) going offline (e.g due to quorum loss) can prevent lease renewal from the SQL instance and causing a restart or failover.
Guidelines for cluster timeout values
Carefully consider the tradeoffs and understand the consequences of using less aggressive monitoring of your SQL Server cluster. Increasing cluster timeout values will increase tolerance of transient network issues but will slow down reactions to hard failures. Increasing timeouts to deal with resource pressure or large geographical latency, will increase the time to recover from hard, or non-recoverable failures as well. While this is acceptable for many applications, it is not ideal in all cases.
The default settings are optimized for quickly reacting to symptoms of hard failures and limiting downtime, but these settings can also be overly aggressive for certain workloads and configurations. It is not recommended to lower any of the LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThreshold, or HealthCheckTimeout beyond their default values. The correct settings for each deployment will vary and likely take a longer period of fine-tuning to discover. When making changes to any of these values, make them gradually and with consideration of the relationships and dependencies between these values.
Relationship between cluster timeout and lease timeout
The primary function of the lease mechanism is to take the SQL Server resource offline if the cluster service cannot communicate with the instance while performing a failover to another node. When the cluster performs the offline operation on the AG cluster resource, the cluster service makes an RPC call to rhs.exe to take the resource offline. The resource DLL uses stored procedures to tell SQL Server to take the AG offline, but this stored procedure could fail or timeout. The resource host also stops its own lease renewal thread during the offline call. In the worst-case, SQL Server will cause the lease to expire in ½ * LeaseTimeout and transition the instance to a resolving state. Failovers can be initiated by multiple different parties, but it is vitally important that the view of the cluster state is consistent across the cluster and across SQL Server instances. For example, imagine a scenario where the primary instance loses connection with the rest of the cluster. Each node in the cluster will determine a failure at similar times due to the cluster timeout values, but only the primary node can interact with the primary SQL Server instance to force it to give up the primary role.
From the primary node's perspective, the cluster service will have lost quorum and the service will begin to terminate itself. The cluster service will issue an RPC call to the resource host to terminate the process. This terminate call is responsible for taking the AG offline on the SQL Server instance. This offline call is done via T-SQL, but cannot guarantee that the connection will be successfully established between SQL and the resource DLL.
From the perspective of the rest of the cluster, there is currently no primary replica and it will vote and establish a single new primary for the remaining nodes in the cluster. If stored procedure that was called by the resource DLL, fails or times-out, the cluster could be vulnerable to a split brain scenario.
The lease timeout prevents split brain scenarios in the face of communication errors. Even if all communication fails, the resource DLL process will terminate and be unable to update the lease. Once the lease expires, it will take the AG offline on its own. The instance of SQL Server needs to be aware that it no longer hosts the primary replica before the cluster establishes a new one. Since the rest of the cluster, which is responsible for choosing a new primary replica has no means of coordinating with the current primary replica, the timeout values ensures that a new primary replica is not established before the current primary takes itself offline.
When the cluster fails over, the instance of SQL Server that hosts the previous primary replica must transition to a resolving state before the new primary replica comes online. The SQL Server lease thread at any point has a remaining time-to-live of ½ * LeaseTimeout, because whenever the lease is renewed the new time-to-live is updated to the LeaseInterval or ½ * LeaseTimeout. If the cluster service or the resource host stalls or terminates without signaling the lease stop event, the cluster will declare the primary node dead after SameSubnetThreshold\ SameSubnetDelay milliseconds. Within this time, the lease must expire so the primary is guaranteed to be offline. Because the max time-to-live for the lease timeout is ½ * LeaseTimeout, ½ * LeaseTimeout must be less than SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold \<= CrossSubnetThreshold and SameSubnetDelay \<= CrossSubnetDelay should be true of all SQL Server clusters.
Health check timeout operation
The health check timeout is more flexible because no other failover mechanism depends on it directly. The default value of 30 seconds sets the sp_server_diagnostics interval at 10 seconds, with a minimum value for 15 seconds for timeout and a 5 second interval. More generally, the sp_server_diagnostics update interval is always 1/3 * HealthCheckTimeout. When the resource DLL does not receive a new set of health data at an interval, it will continue to use the health data from the previous interval to determine the current AG and instance health. Increasing the health check timeout value will make the primary more tolerant of CPU pressure, which can prevent sp_server_diagnostics from providing new data at each interval, however, it will rely on outdated data health checks for longer. Regardless of the timeout value, once data is received indicating the replica is not healthy, the next IsAlive call will return that the instance is unhealthy and the cluster service will initiate a failover.
The failure condition level of the AG changes the failure conditions for the health check. For any failure level, if the AG element is reported unhealthy by sp_server_diagnostics then the health check will fail. Each level inherits all the failure conditions from the levels below it.
| Level | Condition under which the instance is considered dead |
|---|---|
| 1: OnServerDown | Health check takes no action if any resources fail besides the AG. If AG data is not received within 5 intervals, or 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | If no data is received from sp_server_diagnostics for the HealthCheckTimeout |
| 3: OnCriticalServerError | (Default) If the system component reports an error |
| 4: OnModerateServerError | If the resource component reports an error |
| 5: OnAnyQualifiedFailureConitions | If the query processing component reports an error |
Updating Cluster and Always On Timeout Values
Cluster Values
There are four values in the WSFC configuration that are responsible for determining cluster timeout values
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
The delay values determine the wait time between heartbeats from the cluster service, and the threshold values set the number of heartbeats that can receive no acknowledgement from the target node or resource before the object is declared dead by the cluster. If there is no successful heartbeat between nodes in the same subnet for more than SameSubnetDelay \* SameSubnetThreshold milliseconds, then the node is determined dead. The same is true of cross subnet communication using the cross-subnet values.
To list all current cluster values, on any node in the target cluster open an elevated PowerShell terminal. Run the following command:
Get-Cluster | fl *
To update any of these values, run the following command in an elevated PowerShell terminal:
(Get-Cluster).<ValueName> = <NewValue>
When increasing the Delay * Threshold product to make the cluster timeout more tolerant, it is more effective to first increase the delay value before increasing the threshold. By increasing the delay, the time between each heartbeat is increased. More time between heartbeats, allows for more time for transient network issues to resolve themselves and decrease network congestion relative to sending more heartbeats in the same period.
Lease Timeout
The lease mechanism is controlled by a single value specific to each AG in a WSFC cluster. A lease timeout may result in the following errors:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
To modify the lease time out value, use the Failover Cluster Manager and follow these steps:
In the roles tab, find the target AG role. Select the target AG role.
Right-click the AG resource at the bottom of the window and select Properties.
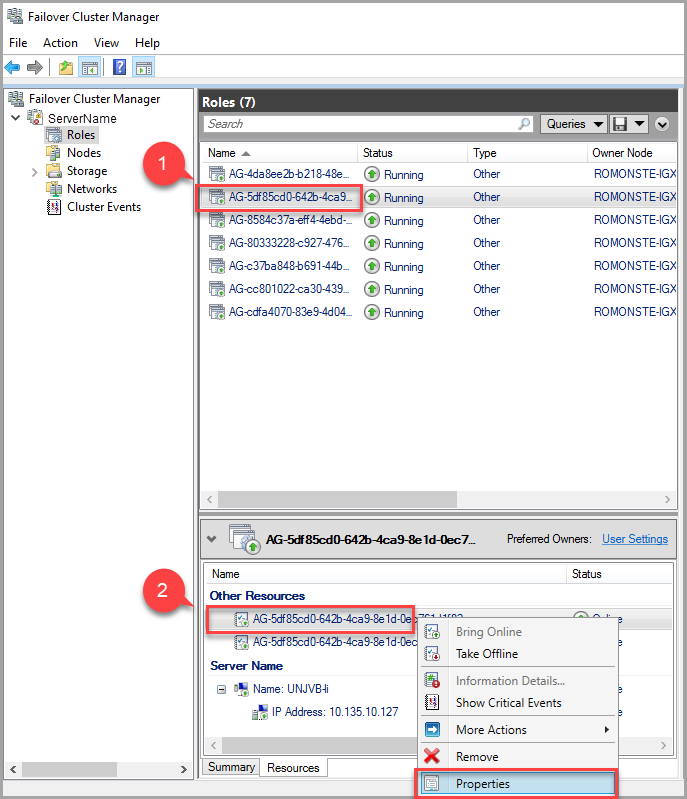
In the popup window, navigate to the properties tab and there will be a list of values specific to this AG. Click the LeaseTimeout value to change it.
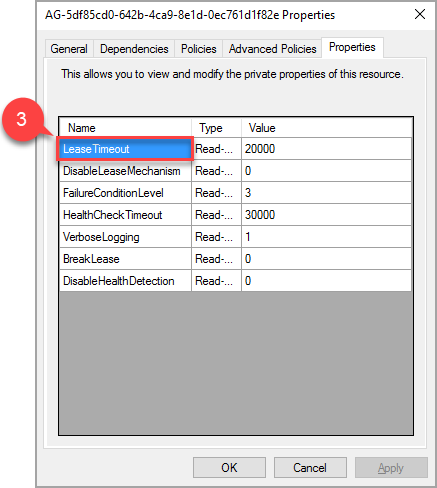
Depending on the AG's configuration there may be additional resources for listeners, shared disks, file shares, etc., these resources do not require any additional configuration.
Note
The new value of property 'LeaseTimeout' will take effect after the resource is taken offline and brought online again.
Health Check Values
Two values control the Always On health check: FailureConditionLevel and HealthCheckTimeout. The FailureConditionLevel indicates the tolerance level to specific failure conditions reported by sp_server_diagnostics and the HealthCheckTimeout configures the time the resource DLL can go without receiving an update from sp_server_diagnostics. The update interval for sp_server_diagnostics is always HealthCheckTimeout / 3.
To configure the failover condition level, use the FAILURE_CONDITION_LEVEL = <n> option of the CREATE or ALTER AVAILABILITY GROUP statement, where <n> is an integer between 1 and 5. The following command sets the failure condition level to 1 for AG 'AG1':
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
To configure the health check timeout, use the HEALTH_CHECK_TIMEOUT option of the CREATE or ALTER AVAILABILITY GROUP statements. The following command sets the health check timeout to 60000 milliseconds for AG AG1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Summary of Timeout Guidelines
It is not advised to lower any timeout values below their default values
The lease interval (½ * LeaseTimeout) must be shorter than SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Timeout setting | Purpose | Between | Uses | IsAlive & LooksAlive | Causes | Outcome |
|---|---|---|---|---|---|---|
| Lease timeout Default: 20000 |
Prevent splitbrain | Primary to Cluster (HADR) |
Windows event objects | Used in both | OS not responding, low virtual memory, working set paging, generating dump, pegged CPU, WSFC down (loss of quorum) | AG resource offline-online, failover |
| Session timeout Default: 10000 |
Inform of communication issue between Primary and Secondary | Secondary to Primary (HADR) |
TCP Sockets (messages sent via DBM endpoint) | Used in neither | Network communication, Issues on secondary - down, OS not responding, resource contention |
Secondary - DISCONNECTED |
| HealthCheck timeout Default: 30000 |
Indicate timeout while trying to determine health of the Primary replica | Cluster to Primary (FCI & HADR) |
T-SQL sp_server_diagnostics | Used in both | Failure conditions met, OS not responding, low virtual memory, working set trim, generating dump, WSFC (loss of quorum), scheduler issues (dead locked schedulers) | AG resource Offline-online or Failover, FCI restart/failover |
See Also
Active Secondaries: Backup on Secondary Replicas (Always On Availability Groups)
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for