What is Windows Server software-defined storage?
Software-defined storage is one of the foundational building blocks of Azure Stack HCI. However, unlike Hyper-V or Failover Clustering, software-defined storage isn't an individual server role or a feature. Instead, it consists of different technologies that frequently complement each other. You can combine these technologies to implement various storage virtualization scenarios such as guest clustering or HCI. These technologies include Storage Spaces, Cluster Shared Volumes (CSV), Server Message Block (SMB), SMB Multichannel, SMB Direct, Scale Out File Server (SOFS), Storage Spaces Direct (S2D), and Storage Replica. To use Azure Stack HCI in your proof-of-concept environment, you'll rely on most of these technologies.
Note
This is not a comprehensive list but is sufficient to gain a basic understanding of the core software-defined storage functionality in Azure Stack HCI.
What is software-defined storage?
Software-defined storage uses storage virtualization to separate storage management and presentation from the underlying physical hardware. One of the primary benefits of this approach is that it simplifies the provisioning and accessing of storage resources.
Reasons for using software-defined storage
With software-defined storage, implementing virtualized workloads no longer requires configuration of logical unit numbers (LUNs) and Storage Area Networks (SAN) switches according to third-party vendor specifications. Instead, you can manage storage in the same, consistent manner regardless of its underlying hardware. In addition, you have the option of replacing proprietary and expensive technologies with flexible and economical hardware-based solutions. Rather than relying on dedicated SANs for highly available and high-performing storage, you can use local disks by using enhancements in remote file sharing protocols and high-bandwidth, low-latency networking.
Storage spaces are the simplest example of software-defined storage in non-clustered scenarios.
Storage spaces
A storage space is a storage-virtualization capability that Microsoft has built into Azure Stack HCI, Windows Server, and Windows 10. The storage spaces feature consists of two components:
- Storage pools are a collection of physical disks aggregated into a logical disk that you can manage as a single entity. A storage pool can contain physical disks of any type and size.
- Storage spaces are virtual disks that you can create from free space in a storage pool. Virtual disks are equivalent to LUNs on a SAN.
Reasons for using storage spaces
The most common reasons for using storage spaces include:
- Increasing storage resiliency levels, such as mirroring and parity. The resiliency of Virtual disks resembles Redundant Array of Independent Disks (RAID) technologies.
- Improving storage performance by using storage tiers. Storage tiers allow you to optimize the use of different disk types in a storage space. For example, you could use fast but small-capacity solid-state drives (SSDs) with slower, but large-capacity hard disks. When you use this combination of disks, Storage Spaces automatically moves data that is accessed frequently to the faster disks. then, it moves data that is accessed less often to the slower disks.
- Improving storage performance by using write-back caching. The purpose of write-back caching is to optimize writing data to the disks in a storage space. Write-back caching works with storage tiers. If the server that is running the storage space detects a peak in disk-writing activity, it automatically starts writing data to the faster disks.
- Increasing storage efficiency by using thin provisioning. Thin provisioning enables storage to be allocated readily on an as needed basis. In a traditional fixed storage allocation method, large portions of storage capacity are preallocated but might remain unused. Thin provisioning optimizes any available storage, by reclaiming storage that is no longer needed with a process known as trim.
The simplest example of software-defined storage in clustered scenarios is Cluster Shared Volumes (CSV).
Cluster Shared Volumes
CSV is a clustered file system that enables multiple nodes of a failover cluster to simultaneously read from and write to the same set of storage volumes. The CSV volumes map to subdirectories within the C:\ClusterStorage\directory on each cluster node. This mapping allows cluster nodes to access the same content through the same file system path. While each node can independently read from and write to individual files on a given volume, a single cluster node serves a special role of the CSV owner (or, coordinator) of that volume. You have the option of assigning an individual volume to a specific owner. However, a failover cluster automatically distributes CSV ownership between cluster nodes.
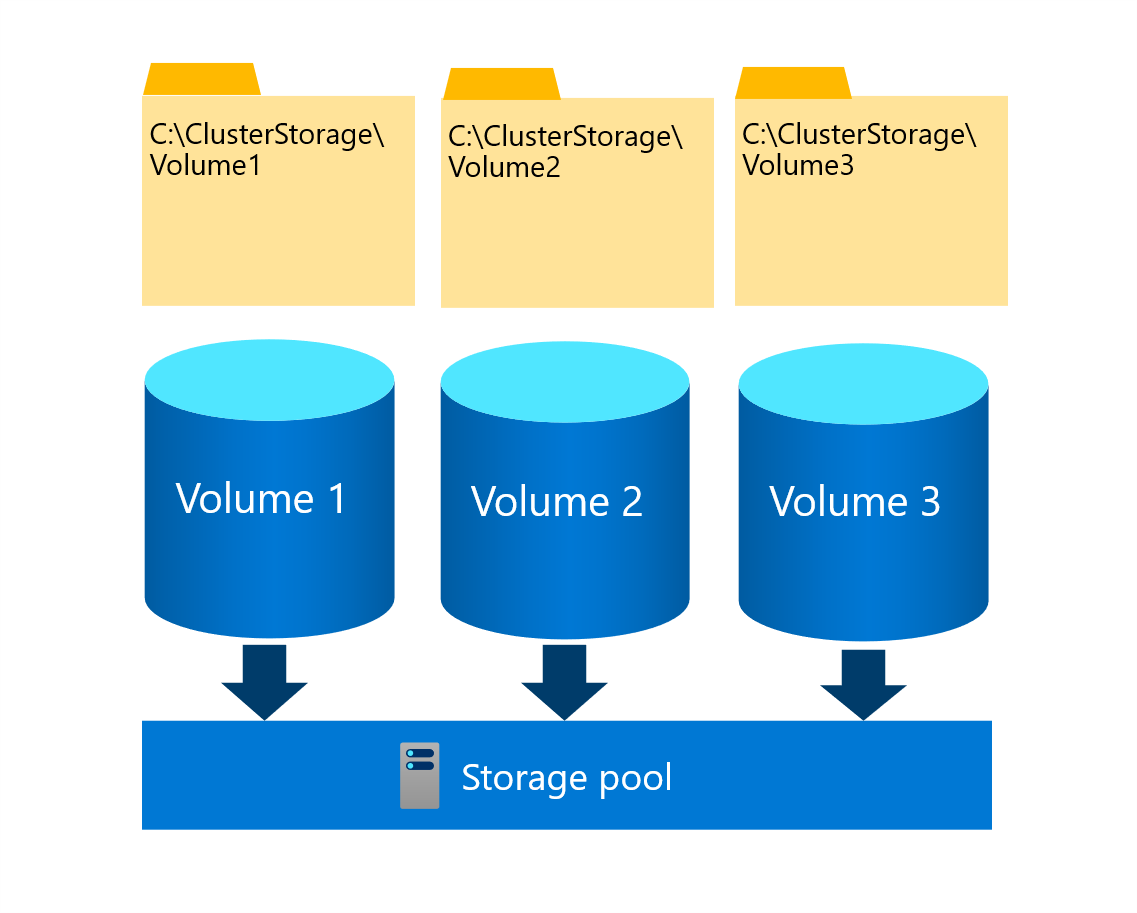
When changes to file system metadata take place on a CSV volume, the owner is responsible for implementing them, managing their orchestration, and synchronizing them across all cluster nodes with access to that volume. Such changes include creating or deleting a file. However, standard write and read operations to open files on a CSV volume doesn't affect metadata. Effectively, each cluster node with direct connectivity to the underlying storage can perform them independently, without relying on the CSV owner of that volume.
Reasons for using CSV
The most common uses of CSV include:
- Clustered Hyper-V VMs.
- Scale-out file shares hosting application data accessible via SMB 3.x.
Server Message Block 3.x
The SMB protocol is a network file sharing protocol that provides access to files over a traditional Ethernet network via TCP/IP transport protocol. SMB serves as one of the core components of software-defined storage technologies. Microsoft introduced SMB version 3.0 in Windows Server 2012 and has been incrementally improving it in subsequent releases.
Reasons for using SMB
The most common uses of SMB include:
- Storage for VM disk files (Hyper-V over SMB). Hyper-V can store VM files, such as configuration, VM disk files, and checkpoints in file shares over the SMB 3.x protocol. You can use these VM files for both standalone file servers and clustered file servers that use Hyper-V together with shared file storage for the cluster.
- Microsoft SQL Server over SMB. SQL Server can store user database files on SMB file shares.
- Traditional storage for end-user data. The SMB 3.x protocol supports the traditional information worker workloads.
SMB 3.x provides support for SMB Multichannel and SMB Direct.
SMB Multichannel
SMB Multichannel is part of the implementation of the SMB 3.x protocol, which significantly improves network performance and availability for devices running Windows Server or Azure Stack HCI cluster nodes operating as file servers. SMB Multichannel allows such servers to take advantage of multiple network connections to provide the following capabilities:
- Increased throughput. The file server can simultaneously transmit more data using multiple connections. SMB Multichannel is beneficial when using servers with multiple, high-speed network adapters.
- Automatic configuration. SMB Multichannel automatically discovers multiple available network paths and dynamically adds connections as required.
- Network fault tolerance. If an existing connection is terminated because of an issue along one of the network paths to an SMB 3.x server. SMB 3.x clients have a built-in ability to automatically fail over to another one.
SMB Direct
SMB Direct optimizes the use of remote direct memory access (RDMA) network adapters for SMB traffic, allowing them to function at full speed with low latency and low CPU utilization. SMB Direct is suitable for scenarios in which workloads such as Hyper-V or Microsoft SQL Server rely on remote SMB 3.x file servers to emulate local storage. SMB Direct is available and enabled by default on all currently supported versions of Windows Server and Azure Stack HCI.
SMB Multichannel is responsible for detecting the RDMA capabilities of network adapters necessary to enable SMB Direct. It automatically creates two RDMA connections per interface. SMB clients automatically detect and use multiple network connections if an appropriate configuration is identified.
SMB 3.x technologies and CSV serve as the basis for SOFS.
Scale-Out File Servers
SOFS is a CSV-based failover clustering feature. When you configure the File Services server role as a cluster role, you can set it up as File Server for general use, or as Scale-Out File Server for application data. The former option implements highly available shared folders accessible through one of the cluster nodes. If that node fails, another node takes ownership of the role and its resources, maintaining the availability of the shared folders. However, clients always access them through a single node. SOFS implements a different approach, in which shared folders reside on a CSV-based volume.
Reasons for using SOFS
SOFS provides the following benefits:
- Improved scaling. Because clients access shared folders via multiple nodes, if the volume of access requests increases, you can add another node to the SOFS.
- Load-balanced utilization. All failover cluster nodes can accept and process client read and write requests targeting one or more SOFS. When you combine their bandwidth and processor power, you can achieve higher utilization rates than with any single node. A single cluster node is no longer a potential bottleneck, because SOFS can support as many clients as all the cluster nodes can collectively facilitate.
- Nondisruptive maintenance, updates, and node failures. Fixing disk corruption issues, performing maintenance, updating, or restarting a failover cluster node doesn't affect the availability of an SOFS. SOFS also provides transparent failover triggered by a node failure.
You can also use SOFS to implement guest clustering.
Guest clustering
You configure guest failover clustering similar to physical-server failover clustering, except that the cluster nodes are VMs. In this scenario, you create two or more VMs and implement failover clustering within the guest operating systems. The application or service can then take advantage of high availability between the VMs. Although you can place the VMs on a single host, in production scenarios, you should use separate failover clustering–enabled Hyper-V host computers. After you implement failover clustering at both the host and VM levels, you can restart the resource, regardless of whether a VM or a host node fails.
Hyper-V VMs can use shared storage that you can connect to by using Fibre Channel or Internet SCSI (iSCSI) from the clustered VMs. Alternatively, you can configure shared storage on the clustered Hyper-V hosts by using the shared virtual hard disk feature and then attach the shared disks to clustered VMs.
You can use shared virtual hard disk in the following scenarios:
- CSV on the Hyper-V host cluster. In this scenario, all virtual machine files, including the shared virtual hard disk files are stored on a CSV that is configured as shared storage for clustered VMs.
- SOFS on a separate storage cluster. This scenario uses SMB file-based storage as the location of the shared virtual hard disk files.
In both scenarios, you can implement storage by using Storage Spaces Direct.
Storage Spaces Direct
Storage Spaces Direct represents the evolution of storage spaces. It applies storage spaces, failover clustering, CSVs, and SMB 3.x to implement virtualized, highly available clustered storage by using local disks on each of the Storage Spaces Direct cluster nodes. It's suitable for hosting highly available workloads, including VMs and SQL Server databases. Storage Spaces Direct eliminates the need for attaching storage devices to multiple cluster nodes in failover clustering scenarios.
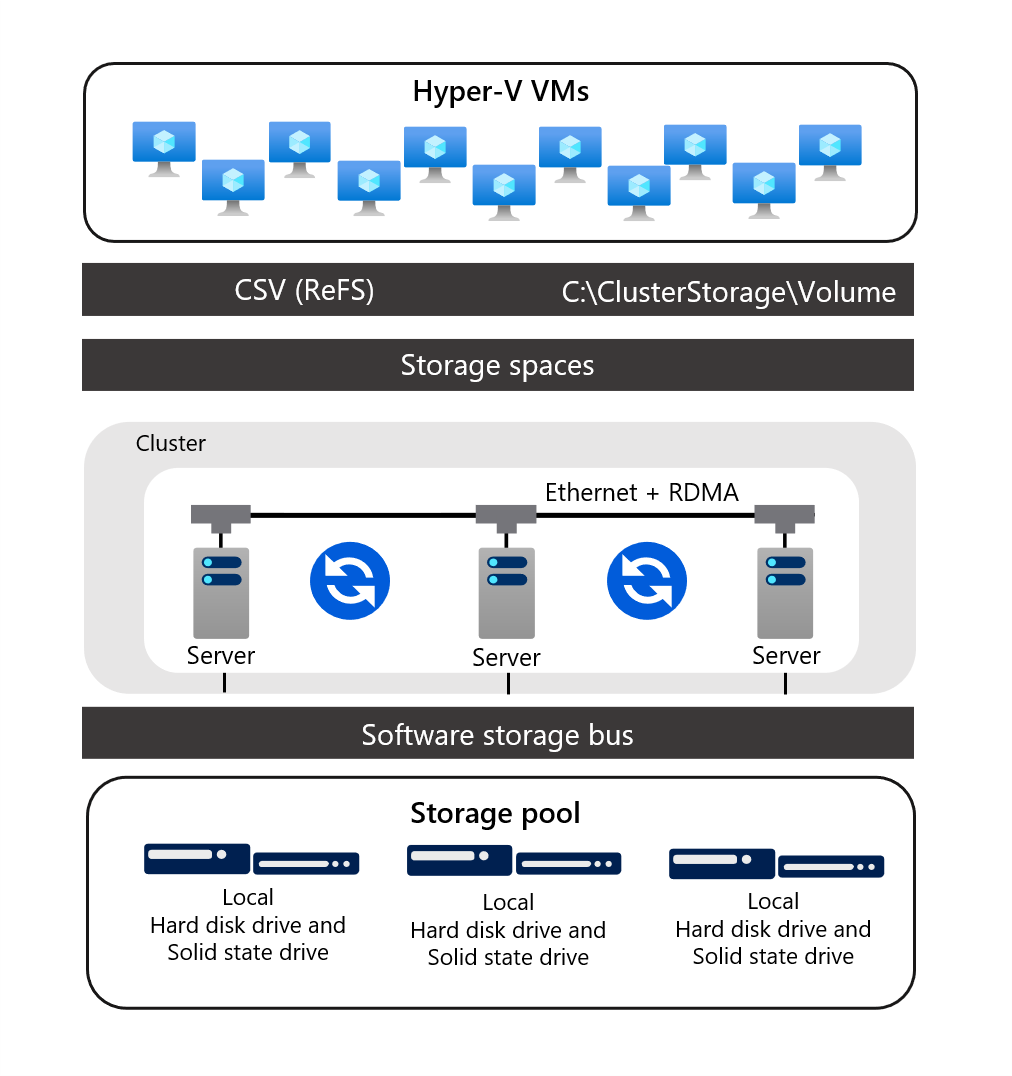
Using local disks in this manner requires a high-bandwidth, low-latency network between the nodes. To satisfy this requirement, you should deploy redundant network connections in combination with high-end RDMA network adapters. This architecture allows you to benefit from technologies such as SMB 3.x, SMB Direct, and SMB Multichannel to deliver high-speed, low-latency, CPU-efficient storage access.
Hyper-V workload models of Storage Spaces Direct
There are two deployment models of Hyper-V workloads using Storage Spaces Direct:
- Disaggregated. In the disaggregated model, the Hyper-V hosts (compute) are in a separate cluster from the Storage Spaces Direct hosts (storage). You configure Hyper-V VMs to store their files in the storage cluster by relying on SOFS, allowing you to scale the Hyper-V cluster (compute) and S2D-based cluster (storage) independently.
- Hyperconverged. In the hyperconverged model, the cluster nodes operate as both Hyper-V hosts (compute) and Storage Spaces Direct hosts (storage). This deployment model has compute and storage colocated on the same set of cluster nodes. To scale up the cluster, you need to increase the number of its nodes.
Note
Azure Stack HCI is an example of the hyperconverged model, which does not use SOFS.
To provide extra resiliency for your Hyper-V workloads, you can use Storage Replica.
Storage Replica
Storage Replica enables storage-agnostic, block-level, synchronous or asynchronous replication between servers or clusters across different physical locations.
Reasons for using Storage Replica
You can use Storage Replica to create stretched failover clusters that span two distinct physical sites, with all nodes staying in sync. Synchronous replication replicates volumes between sites in relative proximity to each other. Replication is crash-consistent, which helps ensure zero data loss at the file system–level during a failover. Asynchronous replication enables replication across longer distances in cases where network round-trip latency exceeds 5 milliseconds (ms), but it's subject to data loss. The extent of data loss depends on the lag of replication between the source and target volumes.
Note
Azure Stack HCI stretched clusters use Storage Replica.