Explore the architecture and components of Cluster Shared Volumes
When implementing and working with CSV, it's important to understand its architecture and components.
CSV architecture
CSV consists of shared volumes mapped to subdirectories within the C:\ClusterStorage\ directory on each cluster node. This approach provides a single namespace, with all CSV content available via the same name and path on any node in a cluster.
Note
CSV Volume Manager is a software component in the CSV file system stack responsible for exposing CSV volumes as subdirectories within the C:\ClusterStorage\ directory.
One of the key modules of the CSV file system stack is the CSV Volume Manager. This is the driver that makes sure that the CSVs are presented as local volumes. In the following diagram, each volume in the storage pool has its own file system directory. For example, C:\ClusterStorage\Volume 1 folder maps to Volume1.
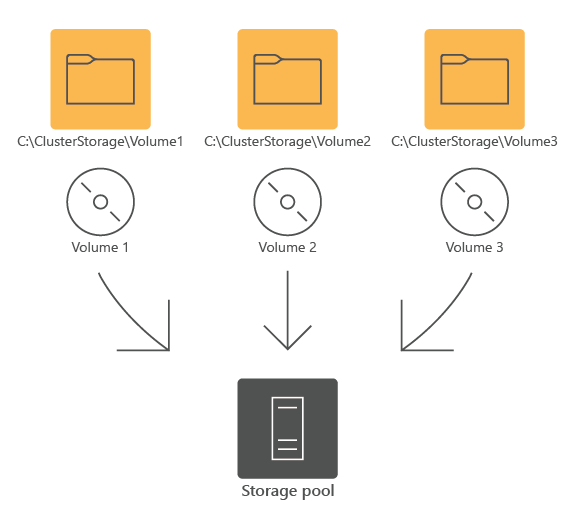
While each node can independently read from and write to individual files on the volume, a single node functions as the CSV owner (or, coordinator) of the volume. That node hosts the mount of the volume. You have the option of assigning an individual volume to a specific owner, however, a failover cluster automatically distributes CSV ownership between cluster nodes. The distribution mechanism considers the number of CSVs that each node owns. The cluster service rebalances the ownership following such changes as adding, removing, or restarting a node.
Note
Failover Cluster Manager labels the coordinator node of a CSV volume as Owner Node in the Disks panel. This is also the designation that appears in the output of the Get-ClusterSharedVolume Windows PowerShell cmdlet.
When changes to file system metadata take place on a CSV volume, the owner is responsible for implementing them and managing their orchestration, synchronizing them across all cluster nodes with access to that volume. Such changes include, for example, starting, creating, migrating, or deleting a VM which disk files reside on the volume. The owner uses its NTFS or ReFS stack to apply the changes and relies on SMB 3.x to replicate them to other cluster nodes with connectivity to the underlying storage. Metadata changes don't involve direct communication from non-owner cluster nodes to the shared storage hosting the volume, as illustrated in the following image.
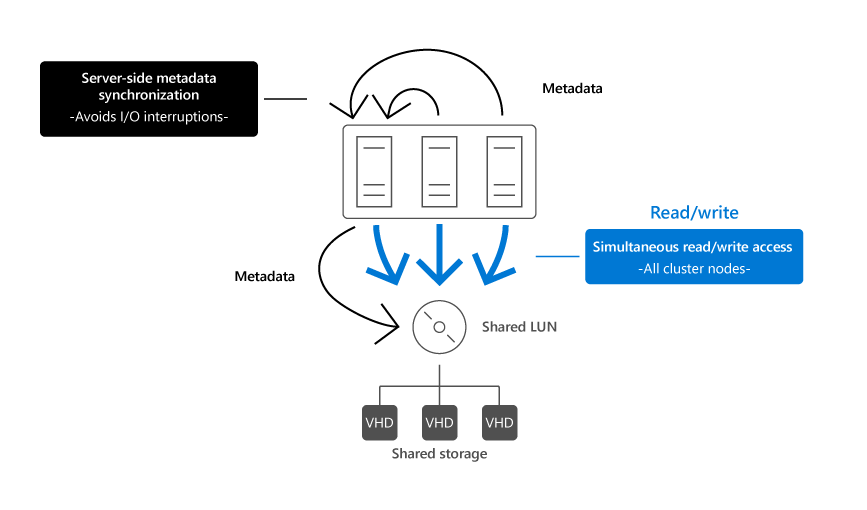
On the other hand, standard write and read operations to open files on a CSV volume doesn't affect metadata. Effectively, each cluster node with connectivity to the underlying storage can perform them independently, without relying on the CSV owner of that volume. Such operations, unlike metadata updates, constitute overwhelming majority of storage activity. Direct I/O bypasses the volume stack, which includes the NTFS or ReFS specific components and directly reaches the underlying storage. As a result, the CSV architecture optimizes I/O performance while still preserving file system integrity.
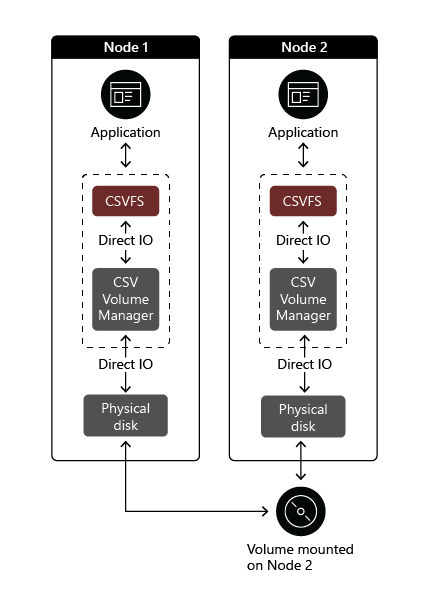
The owner node also minimizes negative impact of storage connectivity failures and storage operations that prevent a given node from communicating directly with the storage. In case of such events, a node that needs to communicate with the underlying storage redirects disk I/O through a cluster network to the owner node of the corresponding volume. If the current coordinator node experiences a storage connectivity failure, all disk I/O operations are temporarily queued while the cluster automatically assigns the coordinator role to a new node.
CSV supports two I/O redirection modes, depending on the type of event that triggered a switch from the direct mode:
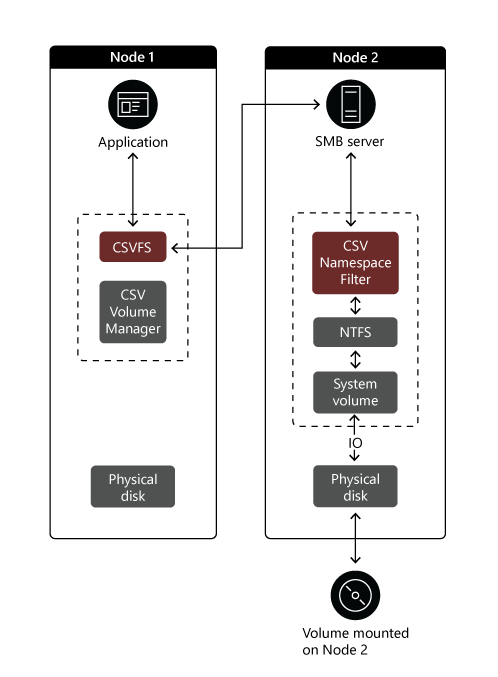
File system redirection. This might happen when a third-party backup application performs a snapshot of a CSV volume. In this case, redirection takes place at the file system level. I/O operations traverse CSVFS on the originating node and travel via SMB to the owner node. From there, they reach the target disk via the NTFS or ReFS file system stack, which resembles the path of metadata updates. The following image illustrates this scenario. Node 1 represents the cluster node which operates in the file system redirection mode. Node 2 serves the role of the node owner.
Block redirection. This happens when a node loses connectivity to a volume, however, the volume remains online. Redirection takes place at the block level. In this case, I/O operations also traverse CSVFS on the originating node and travel via SMB to the owner node. However, they bypass the NTFS or ReFS stack on the owner node, similarly, to Direct I/O, which significantly improves their performance. The following image illustrates this scenario. As before, Node 1 represents the cluster node which operates in the file system redirection mode. Node 2 serves the role of the node owner.
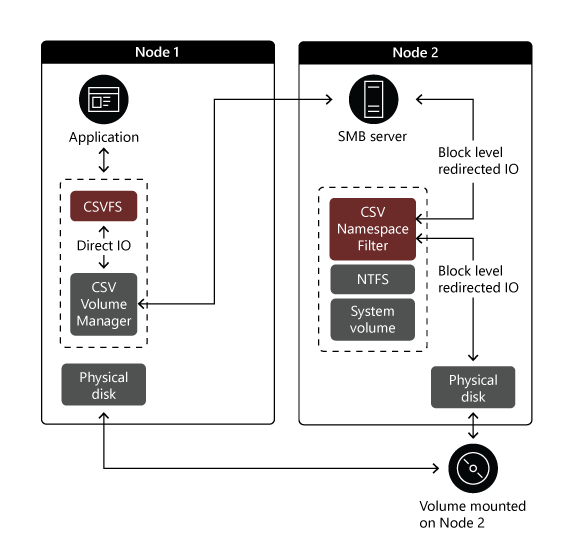
Note
You can identify the status of the CSV volume per node, including its I/O redirection mode and the reason for it by using the Get-ClusterSharedVolumeState Windows PowerShell cmdlet.
Redirected I/O traffic can travel across multiple cluster networks, benefiting from the integration of CSV with such SMB 3.x features as SMB Multichannel and SMB Direct.