Indexadores de Azure AI Search
Un indexador de Azure AI Search es un rastreador que extrae datos textuales de orígenes de datos en la nube y rellena un índice de búsqueda mediante asignaciones de campo a campo entre los datos de origen y un índice de búsqueda. Este enfoque se denomina a veces "modelo de extracción", porque el servicio de búsqueda extrae datos sin que sea preciso escribir código que agregue datos en un índice.
Los indexadores también impulsan la ejecución del conjunto de aptitudes y el enriquecimiento con IA, donde puede configurar aptitudes para integrar el procesamiento adicional del contenido enrutado a un índice. Algunos ejemplos son OCR sobre archivos de imagen, aptitud de división de texto para fragmentación de datos, traducción de texto para varios idiomas.
Los indexadores tienen como destino orígenes de datos admitidos. Una configuración del indexador especifica un origen de datos (origen) y un índice de búsqueda (destino). Varios orígenes de datos, como Azure Blob Storage, tienen propiedades de configuración adicionales específicas de ese tipo de contenido.
Puede ejecutar los indexadores a petición o con una programación de actualización periódica de datos que se ejecuta con una frecuencia de incluso cada cinco minutos. Actualizaciones más frecuentes requieren un modelo de inserción que actualiza simultáneamente los datos en Azure AI Search y su origen de datos externo.
Un servicio de búsqueda ejecuta un trabajo de indexador por unidad de búsqueda. Si necesita procesamiento simultáneo, asegúrese de que tiene suficientes réplicas. Los indexadores no se ejecutan en segundo plano, por lo que es posible que detecte más limitación de consultas de lo habitual si el servicio está bajo presión.
Escenarios de indizador y casos de uso
Puede usar un indexador como único medio para la ingesta de datos o combinándolo con otras técnicas. En la tabla siguiente se resumen los principales escenarios.
| Escenario | Estrategia |
|---|---|
| Origen de datos único | Este patrón es el más simple: un origen de datos es el único proveedor de contenido de un índice de búsqueda. La mayoría de los orígenes de datos admitidos proporcionan algún tipo de detección de cambios para que las ejecuciones posteriores del indexador resalten la diferencia cuando se agregue o actualice contenido en el origen. |
| Varios orígenes de datos | Una especificación de indexador solo puede tener un origen de datos, pero el propio índice de búsqueda puede aceptar contenido de varios orígenes, donde cada ejecución del indexador aporta contenido nuevo de un proveedor de datos diferente. Cada origen puede aportar su parte de documentos completos o rellenar los campos seleccionados en cada documento. Para ver más de cerca este escenario, consulte Tutorial: Indexación de varios orígenes de datos. |
| Varios indexadores | Normalmente se emparejan varios orígenes de datos con varios indexadores si necesita variar los parámetros de tiempo de ejecución, la programación o las asignaciones de campos. Otro escenario es el de escalabilidad horizontal entre regiones de Azure AI Search. Es posible que tenga copias del mismo índice de búsqueda en diferentes regiones. Para sincronizar el contenido del índice de búsqueda, puede tener varios indexadores que extraigan datos del mismo origen, donde cada indexador tiene como destino un índice de búsqueda diferente en cada región. La indexación en paralelo de conjuntos de datos de gran tamaño también requiere una estrategia de varios indexadores, donde cada indexador se dirige a un subconjunto de los datos. |
| Transformación de contenido | Los indexadores impulsan la ejecución del conjunto de aptitudes y el enriquecimiento con IA. Las transformaciones de contenido se definen en un conjunto de aptitudes que se asocia al indexador. Puede usar aptitudes para incorporar la fragmentación de datos y la vectorización. |
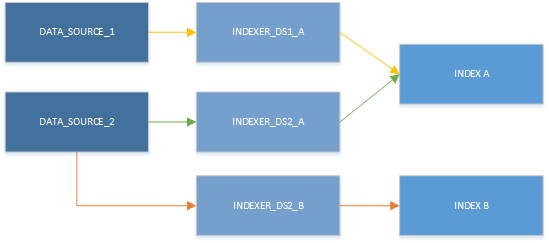
Debe planear la creación de un indizador para cada combinación de origen de datos e índice de destino. Puede hacer que varios indexadores escriban en el mismo índice, y puede reutilizar el mismo origen de datos para varios indexadores. Sin embargo, un indexador solo puede usar un origen de datos de cada vez y solo puede escribir en un índice único. Como se ilustra en el siguiente gráfico, un origen de datos proporciona información a un indexador, el cual luego llena un solo índice:

Aunque solo puede usar un indexador cada vez, los recursos se pueden utilizar en diferentes combinaciones. En la siguiente ilustración debemos observar principalmente que un origen de datos se puede emparejar con más de un indexador y varios indexadores pueden escribir en el mismo índice.
Orígenes de datos compatibles
Los indexadores rastrean los almacenes de datos en Azure y fuera de Azure.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure Table Storage
- Instancia administrada de Azure SQL
- SQL Server en Azure Virtual Machines
- Azure Files (en versión preliminar)
- Azure MySQL (en versión preliminar)
- SharePoint en Microsoft 365 (versión preliminar)
- Azure Cosmos DB for MongoDB (en versión preliminar)
- Azure Cosmos DB for Apache Gremlin (en versión preliminar)
No se admite Azure Cosmos DB para Cassandra.
Los indexadores aceptan conjuntos de filas planas, como una tabla o vista, o elementos de un contenedor o carpeta. En la mayoría de los casos, crea un documento de búsqueda por fila, registro o elemento.
Las conexiones del indexador a orígenes de datos remotos se pueden realizar mediante conexiones de Internet estándar (públicas) o conexiones privadas cifradas cuando se usa un vínculo privado compartido. También puede configurar conexiones para autenticarse mediante una identidad administrada. Para obtener más información sobre conexiones seguras, consulte Acceso del indexador al contenido que protegen las características de seguridad de red de Azure y Conectarse a un origen de datos mediante una identidad administrada.
Fases de la indexación
En una ejecución inicial, cuando el índice está vacío, un indexador lee todos los datos proporcionados en la tabla o el contenedor. En las ejecuciones posteriores, el indexador normalmente puede detectar y recuperar solo los datos que han cambiado. En el caso de los datos de blob, la detección de cambios es automática. En otros orígenes de datos, como Azure SQL o Azure Cosmos DB, la detección de cambios se debe habilitar.
En todos los documentos que recibe, un indexador implementa o coordina varios pasos, desde la recuperación del documento hasta una "entrega" final del motor de búsqueda para la indexación. Opcionalmente, un indexador también impulsa la ejecución y los resultados del conjunto de aptitudes, siempre y cuando se haya definido uno.

Fase 1: Descifrado de documentos
El descifrado de documentos es el proceso de abrir archivos y extraer contenido. El contenido basado en texto se puede extraer de los archivos de un servicio, de las filas de una tabla o de los elementos de un contenedor o una colección. Si agrega un conjunto de aptitudes y aptitudes de imagen, el descifrado de documentos también puede extraer imágenes y ponerlas en cola para su procesamiento de imágenes.
Según el origen de datos, el indizador intenta realizar diferentes operaciones para extraer contenido que posiblemente se pueda indexar:
Cuando el documento es un archivo con imágenes insertadas, como un PDF, el indexador extrae texto, imágenes y metadatos. Los indexadores pueden abrir archivos desde Azure Blob Storage, Azure Data Lake Storage Gen2 y SharePoint.
Si el documento es un registro de Azure SQL, el indizador extrae contenido no binario de cada campo de cada registro.
Si el documento es un registro de Azure Cosmos DB, el indexador extrae contenido no binario de los campos y subcampos del documento de Azure Cosmos DB.
Fase 2: Asignaciones de campos
Un indexador extrae texto de un campo de origen y lo envía a un campo de destino de un índice o un almacén de conocimiento. Si los nombres de los campos y los tipos de datos coinciden, la ruta de acceso está clara. Pero es posible que quiera nombres o tipos diferentes en el resultado, en cuyo caso debe indicar al indexador cómo asignar el campo.
Para especificar asignaciones de campos, escriba los campos de origen y destino en la definición del indexador.
La asignación de campos se produce después del descifrado de documentos, pero antes de las transformaciones, cuando el indexador lee los documentos de origen. Al definir una asignación de campos, el valor del campo de origen se envía tal cual al campo de destino, sin modificaciones.
Fase 3: Ejecución del conjunto de aptitudes
La ejecución del conjunto de aptitudes es un paso opcional que invoca al procesamiento de IA integrado o personalizado. Los conjuntos de aptitudes pueden agregar reconocimiento óptico de caracteres (OCR) u otras formas de análisis de imágenes si el contenido es binario. Los conjuntos de aptitudes también pueden agregar procesamiento de lenguaje natural. Por ejemplo, puede agregar traducción de texto o extracción de frases clave.
Sea cual sea la transformación, la ejecución del conjunto de aptitudes es donde se produce el enriquecimiento. Si un indexador es una canalización, puede imaginarse un conjunto de aptitudes como una "canalización dentro de la canalización".
Fase 4: Asignaciones de campos de salida
Si incluye un conjunto de aptitudes, deberá especificar asignaciones de campos de salida en la definición del indexador. La salida de un conjunto de aptitudes se manifiesta internamente como una estructura de árbol denominada documento enriquecido. Las asignaciones de campos de salida permiten seleccionar qué partes de este árbol se asignan a campos del índice.
A pesar de la similitud en los nombres, las asignaciones de campos de salida y las asignaciones de campos crean asociaciones de orígenes diferentes. Las asignaciones de campos asocian el contenido del campo de origen a un campo de destino en un índice de búsqueda. Las asignaciones de campos de salida asocian el contenido de un documento enriquecido interno (salidas de aptitud) a los campos de destino del índice. A diferencia de las asignaciones de campos, que se consideran opcionales, es necesario definir la asignación de campos de salida para cualquier contenido transformado que deba residir en el índice.
En la siguiente imagen se muestra una representación de sesión de depuración de un indexador de ejemplo de las fases del indexador: descifrado de documentos, asignaciones de campos, ejecución del conjunto de aptitudes y asignaciones de campos de salida.

Flujo de trabajo básico de
Los indexadores pueden ofrecer características que son exclusivas del origen de datos. En este sentido, algunos aspectos de la configuración de orígenes de datos o indexadores varían según el tipo de indexador. No obstante, todos los indexadores comparten composición básica y requisitos. Más adelante, se explican los pasos que son comunes a todos los indexadores.
Paso 1: Creación de un origen de datos
Los indexadores requieren un objeto origen de datos que proporcione una cadena de conexión y, posiblemente, credenciales. Los orígenes de datos son objetos independientes. Es posible que varios indexadores puedan usar el mismo objeto de origen de datos para cargar más de un índice a la vez.
Puede crear un origen de datos mediante cualquiera de estos enfoques:
- Con Azure Portal, en la pestaña Orígenes de datos de las páginas del servicio de búsqueda, seleccione Agregar origen de datos para especificar la definición del origen de datos.
- Con Azure Portal, el Asistente para importar datos genera un origen de datos.
- Con las API de REST, llame a Crear origen de datos.
- Con el SDK de Azure para .NET, llame a la clase SearchIndexerDataSourceConnection
Paso 2: Creación de un índice
Un indexador automatizará algunas tareas relacionadas con la ingesta de datos, pero la creación de un índice no suele ser una de ellas. Como requisito previo, debe tener un índice predefinido que contenga los campos de destino correspondientes para los campos de origen del origen de datos externo. Los campos deben coincidir por nombre y tipo de datos. Si no es así, puede definir asignaciones de campos para establecer la asociación.
Para obtener más información, consulte Creación de un índice.
Paso 3: Creación y ejecución (o programación) del indexador
Una definición de indizador consta de propiedades que identifican de forma única el indexador, especifican el origen de datos y el índice que se va a usar, y proporcionan otras opciones de configuración que influyen en los comportamientos de tiempo de ejecución, incluido si el indexador se ejecuta a petición o según una programación.
Los errores o advertencias sobre el acceso a datos o la validación de aptitudes se producirán durante la ejecución del indexador. Los objetos dependientes, como los orígenes de datos, los índices y los conjuntos de aptitudes, permanecen inactivos en el servicio de búsqueda, hasta que se inicia la ejecución del indexador.
Para obtener más información, consulte Creación de un indizador
Después de la primera ejecución del indexador, se puede volver a ejecutar a petición o definir una programación periódica.
Se puede supervisar el estado del indexador en el portal o mediante el API Get Indexer Status. También hay que ejecutar consultas en el índice para comprobar que el resultado es el esperado.
Los indexadores no tienen recursos de procesamiento dedicados. En función de esto, el estado de los indexadores puede mostrarse como inactivo antes de ejecutarse (según otros trabajos de la cola) y es posible que los tiempos de ejecución no sean predecibles. Otros factores definen también el rendimiento del indexador, como el tamaño del documento, la complejidad del documento, el análisis de imágenes, entre otros.
Pasos siguientes
Tras esta introducción a los indexadores, el siguiente paso es revisar las propiedades y los parámetros del indexador, su programación y su supervisión. Como alternativa, puede volver a la lista de orígenes de datos admitidos, donde podrá obtener más información acerca de cualquier origen concreto.