¿Qué es el almacenamiento definido por software de Windows Server?
El almacenamiento definido por software es una de las bases esenciales de Azure Stack HCl. Sin embargo, a diferencia de Hyper-V o de los clústeres de conmutación por error, el almacenamiento definido por software no es un rol del servidor individual ni una característica. Al contrario, consta de diferentes tecnologías que se complementan. Estas tecnologías pueden combinarse para implementar varios escenarios de virtualización de almacenamiento, como clúster invitado o HCl. Algunas de ellas son Espacios de almacenamiento, Volúmenes compartidos de clúster (CSV), Bloque de mensajes del servidor (SMB), SMB multicanal, SMB directo, Servidor de archivos de escalabilidad horizontal (SOFS), Espacios de almacenamiento directo (S2D) y Réplica de almacenamiento. Para usar Azure Stack HCl en el entorno de prueba de concepto, se basará en la mayoría de estas tecnologías.
Nota:
Esta no es una lista completa, pero es suficiente para conocer la funcionalidad básica de almacenamiento definida por software de Azure Stack HCl.
¿Qué es el almacenamiento definido por software?
El almacenamiento definido por software emplea la virtualización de almacenamiento para separar la administración y la presentación del almacenamiento del hardware físico subyacente. Una de las principales ventajas de este enfoque es que simplifica el aprovisionamiento y el acceso a los recursos de almacenamiento.
Motivos para usar el almacenamiento definido por software
Con el almacenamiento definido por software, para implementar cargas de trabajo virtualizadas ya no es necesario configurar números de unidad lógica (LUN) y conmutadores de redes de área de almacenamiento (SAN), de acuerdo con las especificaciones de otros proveedores. En cambio, puede administrar el almacenamiento de la misma manera coherente, independientemente de su hardware subyacente. Además, tiene la opción de reemplazar las tecnologías propias y costosas por soluciones flexibles y económicas basadas en hardware. En lugar de confiar en redes SAN dedicadas para un almacenamiento de gran rendimiento y alta disponibilidad, puede usar discos locales y valerse de las mejoras en los protocolos de uso compartido de archivos remotos y redes de ancho de banda alto y latencia baja.
Los espacios de almacenamiento son el ejemplo más sencillo de almacenamiento definido por software en escenarios no basados en clúster.
Espacios de almacenamiento
Un espacio de almacenamiento es una funcionalidad de virtualización de almacenamiento que Microsoft ha integrado en Azure Stack HCl, Windows Server y Windows 10. La característica de espacios de almacenamiento consta de dos componentes:
- Los grupos de almacenamiento son una colección de discos físicos agregados a un disco lógico que puede administrarse como una sola entidad. Un grupo de almacenamiento puede contener discos físicos de cualquier tipo y tamaño.
- Los espacios de almacenamiento son discos virtuales que puede crear a partir de espacio libre en un grupo de almacenamiento. Los discos virtuales son equivalentes a los LUN de una SAN.
Motivos para usar espacios de almacenamiento
Entre los motivos más comunes para usar espacios de almacenamiento se incluyen:
- Aumento de los niveles de resistencia de almacenamiento, como la creación de reflejo y la paridad. La resistencia de los discos virtuales es similar a las tecnologías de matriz redundante de discos independientes (RAID).
- Mejora del rendimiento del almacenamiento mediante el uso de capas de almacenamiento. Las capas de almacenamiento permiten optimizar el uso de diferentes tipos de disco en un espacio de almacenamiento. Por ejemplo, podría usar unidades de estado sólido (SSD) rápidas pero de pequeña capacidad con discos duros más lentos pero de gran capacidad. Al usar esta combinación de discos, los espacios de almacenamiento mueven automáticamente aquellos datos a los que se tiene un acceso frecuente a los discos más rápidos. A continuación, mueven los datos a los que se tiene un acceso menos frecuente a los discos más lentos.
- Mejora del rendimiento del almacenamiento mediante el almacenamiento en caché con reescritura. El propósito del almacenamiento en caché con reescritura es optimizar la escritura de datos en los discos de un espacio de almacenamiento. El almacenamiento en caché con reescritura funciona con capas de almacenamiento. Si el servidor que ejecuta el espacio de almacenamiento detecta un pico en la actividad de escritura en disco, inicia automáticamente la escritura de datos en los discos más rápidos.
- Aumento de la eficiencia de almacenamiento mediante el aprovisionamiento fino. El aprovisionamiento fino permite que el almacenamiento se asigne fácilmente según sea necesario. En un método de asignación de almacenamiento fijo tradicional, se preasignan grandes partes de la capacidad de almacenamiento, pero podrían permanecer sin usar. El aprovisionamiento fino optimiza cualquier almacenamiento disponible reclamando el almacenamiento que ya no es necesario con un proceso conocido como reducción.
El ejemplo más simple de almacenamiento definido por software en escenarios en clúster son volúmenes compartidos de clúster (CSV).
Volúmenes compartidos en clúster
CSV es un sistema de archivos en clúster que permite a varios nodos de un clúster de conmutación por error leer y escribir simultáneamente en el mismo conjunto de volúmenes de almacenamiento. Los volúmenes CSV se asignan a subdirectorios dentro de C:\ClusterStorage\directory en cada nodo de clúster. Esta asignación permite a los nodos de clúster acceder al mismo contenido a través de la misma ruta de acceso del sistema de archivos. Aunque cada nodo puede leer y escribir en archivos individuales de un volumen determinado de forma independiente, un solo nodo de clúster tiene una función especial del propietario de CSV (o bien, del coordinador) de ese volumen. Tiene la opción de asignar un volumen individual a un propietario específico. Sin embargo, un clúster de conmutación por error distribuye automáticamente la propiedad de CSV entre los nodos de clúster.
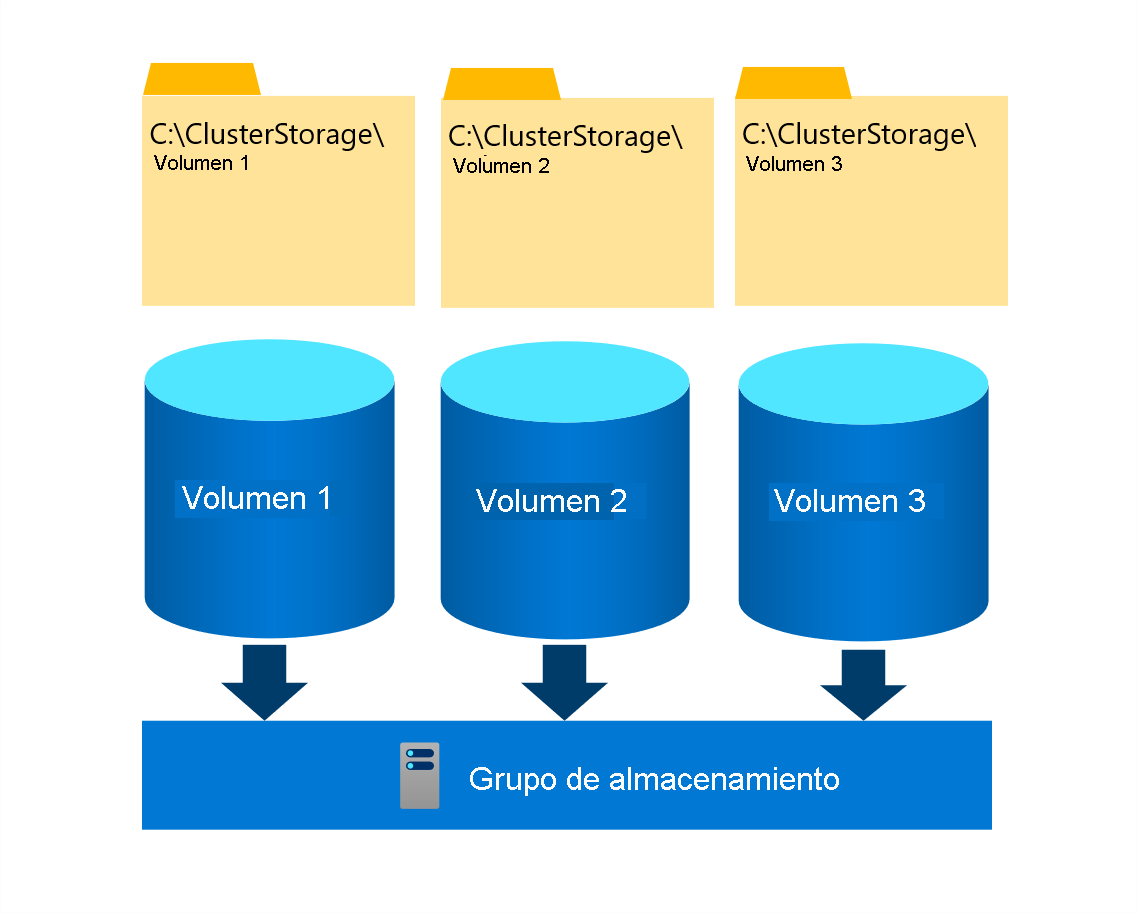
Cuando los cambios en los metadatos del sistema de archivos tienen lugar en un volumen CSV, el propietario es responsable de implementarlos, administrar su orquestación y sincronizarlos en todos los nodos de clúster con acceso a ese volumen. Entre estos cambios se incluyen la creación o la eliminación de un archivo. Sin embargo, las operaciones de escritura y lectura estándar para abrir archivos en un volumen CSV no afectan a los metadatos. Cada nodo de clúster con conectividad directa al almacenamiento subyacente puede realizarlos de forma independiente, sin depender del propietario de CSV de ese volumen.
Motivos para usar CSV
Entre los usos más comunes de CSV se incluyen:
- Máquinas virtuales de Hyper-V en clúster.
- Recursos compartidos de archivos de escalabilidad horizontal que hospedan datos de aplicación accesibles a través de SMB 3.x.
Bloque de mensajes del servidor 3.x
El protocolo SMB es un protocolo de uso compartido de archivos de red que proporciona acceso a los archivos a través de una red Ethernet tradicional a través del protocolo de transporte TCP/IP. SMB sirve como uno de los componentes principales de las tecnologías de almacenamiento definido por software. Microsoft presentó SMB versión 3.0 en Windows Server 2012 y lo ha mejorado de forma incremental en las versiones posteriores.
Motivos para usar SMB
Entre los usos de SMB más habituales se incluyen:
- Almacenamiento de archivos de disco de la máquina virtual (Hyper-V en SMB). Hyper-V puede almacenar archivos de máquina virtual, como la configuración, los archivos de disco de la máquina virtual y los puntos de control en recursos compartidos de archivos a través del protocolo SMB 3.x. Puede usar estos archivos de la máquina virtual tanto para los servidores de archivos independientes como para los servidores de archivos en clúster que utilicen Hyper-V junto con el almacenamiento de archivos compartidos para el clúster.
- Microsoft SQL Server a través de SMB. En SQL Server se pueden almacenar archivos de base de datos de usuarios en recursos compartidos de archivos SMB.
- Almacenamiento tradicional para datos de usuario final. El protocolo SMB 3.x admite las cargas de trabajo del trabajador de la información tradicionales.
SMB 3.x proporciona compatibilidad con SMB multicanal y SMB directo.
SMB multicanal
SMB multicanal forma parte de la implementación del protocolo SMB 3.x, que mejora significativamente el rendimiento de la red y la disponibilidad de los dispositivos que ejecutan nodos de clúster de Azure Stack HCI o Windows Server que funcionan como servidores de archivos. SMB multicanal permite a estos servidores aprovechar las ventajas de varias conexiones de red para proporcionar las siguientes funcionalidades:
- Aumento del rendimiento. El servidor de archivos puede transmitir simultáneamente más datos mediante varias conexiones. SMB multicanal resulta beneficioso cuando se usan servidores con varios adaptadores de red de alta velocidad.
- Configuración automática. SMB multicanal detecta automáticamente varias rutas de acceso de red disponibles y agrega dinámicamente conexiones según sea necesario.
- Tolerancia a errores de la red. Si una conexión existente finaliza debido a una incidencia en una de las rutas de acceso de red a un servidor SMB 3.x, los clientes SMB 3.x tienen una capacidad integrada para conmutar por error automáticamente a otra.
SMB directo
SMB directo optimiza el uso de adaptadores de red de acceso directo a memoria remota (RDMA) para el tráfico de SMB, lo que les permite funcionar a toda velocidad con baja latencia y un uso reducido de la CPU. Esto hace que SMB directo sea adecuado para escenarios en los que cargas de trabajo, como Hyper-V o Microsoft SQL Server se basan en servidores de archivos SMB 3.x remotos para emular el almacenamiento local. SMB directo está disponible y habilitado de forma predeterminada en todas las versiones actualmente compatibles de Windows Server y Azure Stack HCl.
SMB multicanal es responsable de detectar las funcionalidades RDMA de los adaptadores de red necesarios para habilitar SMB directo. Crea automáticamente dos conexiones RDMA por interfaz. Los clientes SMB detectan y utilizan automáticamente varias conexiones de red si no se identifica una configuración apropiada.
Las tecnologías SMB 3.x y CSV sirven como base para SOFS.
Servidores de archivos de escalabilidad horizontal
SOFS es una característica de clústeres de conmutación por error basada en CSV. Al configurar el rol del servidor de servicios de archivo como un rol de clúster, puede configurarlo como servidor de archivos para uso general o como servidor de archivos de escalabilidad horizontal para datos de aplicación. La opción anterior implementa carpetas compartidas de alta disponibilidad accesibles a través de uno de los nodos de clúster. Si se produce un error en ese nodo, otro nodo toma propiedad del rol y sus recursos, manteniendo la disponibilidad de las carpetas compartidas. Sin embargo, los clientes siempre tienen acceso a ellas a través de un solo nodo. SOFS implementa un enfoque diferente, en el que las carpetas compartidas residen en un volumen basado en CSV.
Motivos para usar SOFS
SOFS ofrece las siguientes ventajas:
- Escalado mejorado. Dado que los clientes tienen acceso a las carpetas compartidas a través de varios nodos, si el volumen de solicitudes de acceso aumenta, puede agregar oro nodo a SOFS.
- Uso de carga equilibrada. Todos los nodos de clúster de conmutación por error pueden aceptar y procesar solicitudes de lectura y escritura de los clientes destinadas a uno o varios SOFS. Al combinar la potencia del procesador y el ancho de banda, puede alcanzar tasas más altas de uso que con cualquier nodo único. Un solo nodo de clúster ya no es un posible cuello de botella, ya que SOFS puede admitir tantos clientes como puedan facilitar colectivamente todos los nodos de clúster.
- Mantenimiento, actualizaciones y errores de nodo sin interrupciones. La corrección de problemas de disco dañado, la realización de tareas de mantenimiento, la actualización o el reinicio de un nodo de clúster de conmutación por error no afecta a la disponibilidad de un SOFS. SOFS también proporciona una conmutación por error transparente desencadenada por un error de nodo.
También puede usar SOFS para implementar la agrupación en clúster de invitado.
Agrupación en clúster de invitado
Los clústeres de conmutación por error de invitado se configuran de forma similar a los clústeres de conmutación por error de servidor físico, salvo que los nodos de clúster son máquinas virtuales. En este escenario, creará dos o más máquinas virtuales e implementará los clústeres de conmutación por error en los sistemas operativos invitados. A continuación, la aplicación o el servicio pueden aprovechar la alta disponibilidad entre las máquinas virtuales. Aunque puede colocar las máquinas virtuales en un solo host, en escenarios de producción, debe usar equipos host con Hyper-V habilitados para clústeres de conmutación por error independientes. Después de implementar los clústeres de conmutación por error tanto en el nivel de host como en el de VM, puede reiniciar el recurso independientemente de si se produce un error en una VM o en un nodo de host.
Las máquinas virtuales de Hyper-V pueden usar el almacenamiento compartido al que se puede conectar mediante Canal de fibra o SCSI de Internet (iSCSI) desde las máquinas virtuales en clúster. Como alternativa, puede configurar el almacenamiento compartido en los hosts de Hyper-V en clúster mediante la característica de disco duro virtual compartido y, a continuación, conectar los discos compartidos a las máquinas virtuales en clúster.
Puede usar un disco duro virtual compartido en los escenarios siguientes:
- CSV en el clúster de hosts de Hyper-V. En este escenario, todos los archivos de máquina virtual, incluidos los archivos de disco duro virtual compartido, se almacenan en un CSV que está configurado como almacenamiento compartido para las máquinas virtuales en clúster.
- SOFS en un clúster de almacenamiento independiente. En este escenario se usa el almacenamiento basado en archivos SMB como ubicación de los archivos de disco duro virtual compartido.
En ambos escenarios, puede implementar el almacenamiento mediante Espacios de almacenamiento directo.
Espacios de almacenamiento directo
Espacios de almacenamiento directo representa la evolución de los espacios de almacenamiento. Aplica los espacios de almacenamiento, los clústeres de conmutación por error, los CSV y SMB 3.x para implementar el almacenamiento en clúster virtualizado y de alta disponibilidad mediante el uso de discos locales en cada uno de los nodos de clúster de Espacios de almacenamiento directo. Es adecuado para hospedar cargas de trabajo de alta disponibilidad, incluidas las VM y las bases de datos de SQL Server. Espacios de almacenamiento directo elimina la necesidad de conectar dispositivos de almacenamiento a varios nodos de clúster en escenarios de clústeres de conmutación por error.
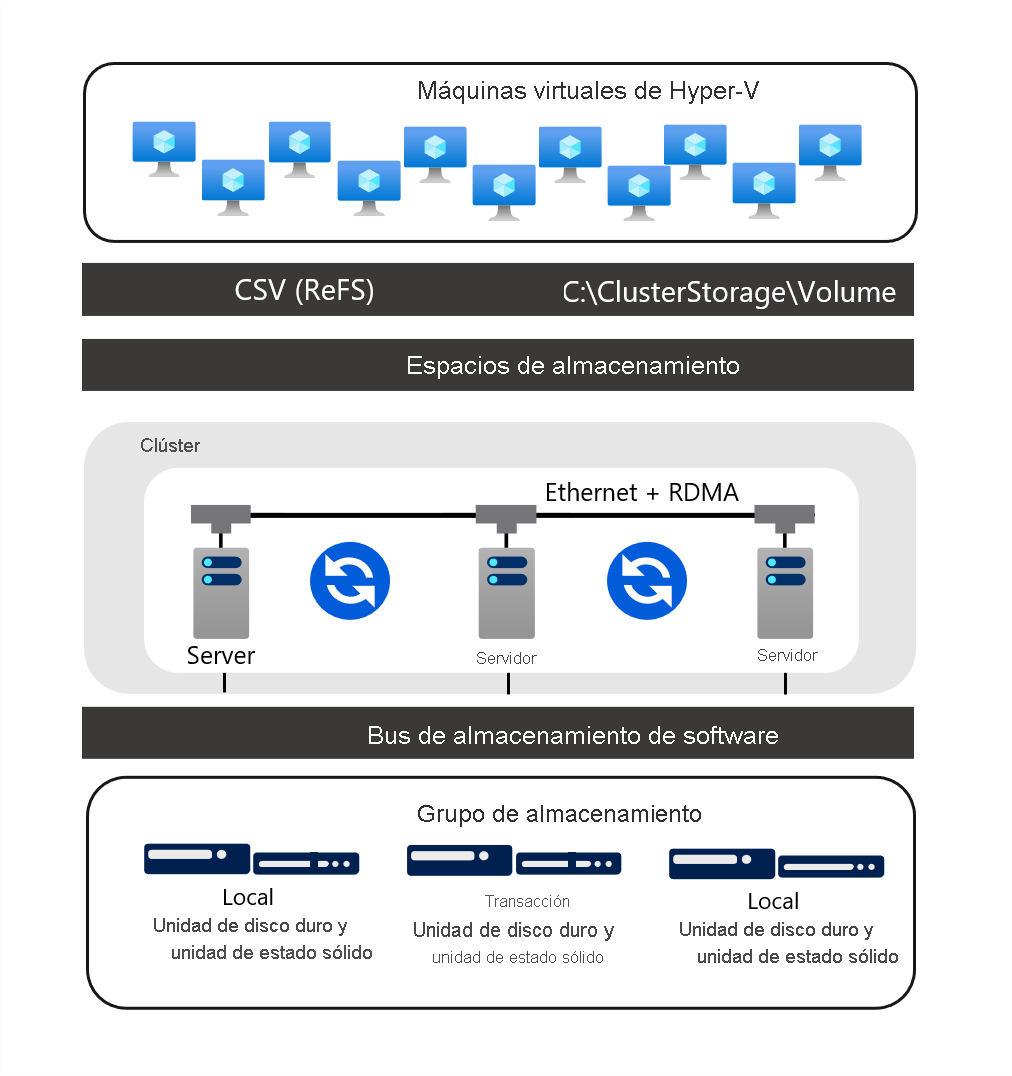
Esta forma de usar los discos de almacenamiento requiere una red de baja latencia y alto ancho de banda entre los nodos. Para satisfacer este requisito, debe implementar conexiones de red redundantes en combinación con los adaptadores de red RDMA de gama alta. Esta arquitectura permite beneficiarse de tecnologías como SMB 3.x, SMB directo y SMB multicanal para ofrecer acceso a almacenamiento de alta velocidad, de baja latencia y con un uso eficiente de la CPU.
Modelos de carga de trabajo de Hyper-V de Espacios de almacenamiento directo
Hay dos modelos de implementación de cargas de trabajo de Hyper-V que usan Espacios de almacenamiento directo:
- Desagregado. En el modelo desagregado, los hosts de Hyper-V (proceso) están en un clúster aparte de los hosts de Espacios de almacenamiento directo (almacenamiento). Las VM de Hyper-V se configuran para almacenar los archivos en el clúster de almacenamiento basándose en SOFS, lo que le permite escalar el clúster de Hyper-V (proceso) y el clúster basado en S2D (almacenamiento) de forma independiente.
- Hiperconvergido. En el modelo hiperconvergido, los nodos de clúster funcionan como hosts de Hyper-V (proceso) y hosts de Espacios de almacenamiento directo (almacenamiento). Este modelo de implementación tiene los procesos y el almacenamiento colocados en el mismo conjunto de nodos de clúster. Para escalar verticalmente el clúster, debe aumentar el número de sus nodos.
Nota:
Azure Stack HCl es un ejemplo del modelo hiperconvergido, que no usa SOFS.
Para proporcionar resistencia adicional para las cargas de trabajo de Hyper-V, puede usar la réplica de almacenamiento.
Réplica de almacenamiento
La réplica de almacenamiento permite la replicación asincrónica, sincrónica, de nivel de bloque o independiente del almacenamiento entre servidores o clústeres en diferentes ubicaciones físicas.
Motivos para usar la réplica de almacenamiento
Puede usar la réplica de almacenamiento para crear clústeres de conmutación por error extendidos que abarquen dos sitios físicos distintos, con todos los nodos sincronizados. La replicación sincrónica replica volúmenes entre sitios que tienen una proximidad relativa entre sí. La replicación es coherente frente a bloqueos, lo que ayuda a garantizar que no se produzca ninguna pérdida de datos en el sistema de archivos durante una conmutación por error. La replicación asincrónica permite la replicación en distancias más largas en los casos en los que la latencia de ida y vuelta de red supera los 5 milisegundos (ms), pero se pueden producir pérdidas de datos. El alcance de la pérdida de datos depende del retraso de la replicación entre los volúmenes de origen y de destino.
Nota:
Los clústeres extendidos de Azure Stack HCI usan la réplica de almacenamiento.