Procedimiento: Incorporación de datos de métricas a Metrics Advisor
Importante
A partir del 20 de septiembre de 2023, no podrá crear nuevos recursos de Metrics Advisor. El servicio Metrics Advisor se va a retirar el 1 de octubre de 2026.
Consulte este artículo para saber cómo incorporar datos a Metrics Advisor.
Configuración y requisitos del esquema de datos
Metrics Advisor de Azure AI es un servicio de detección, diagnóstico y análisis de anomalías de serie temporal. Como servicio basado en IA, utiliza los datos para entrenar el modelo usado. El servicio acepta tablas de datos agregados con las columnas siguientes:
- Medida (obligatorio): una medida es un término fundamental o específico de unidad y un valor cuantificable de la métrica. Significa que una o varias columnas contienen valores numéricos.
- Timestamp (Marca de tiempo) (opcional): cero o una columna del tipo
DateTimeoString. Cuando esta columna no está establecida, la marca de tiempo se establece como la hora de inicio de cada período de ingesta. Formatee la marca de tiempo de la siguiente manera:yyyy-MM-ddTHH:mm:ssZ. - Dimensión (opcional): una dimensión es uno o más valores de categorías. La combinación de esos valores identifica una serie temporal univariante concreta (por ejemplo, país/región, idioma e inquilino). Las columnas de dimensión pueden ser de cualquier tipo de datos. Tenga cuidado al trabajar con grandes volúmenes de columnas y valores si desea evitar que se procese un número excesivo de dimensiones.
Si usa orígenes de datos como Azure Data Lake Storage o Azure Blob Storage, puede agregar los datos para alinearlos con el esquema de métricas previsible. Esto se debe a que estos orígenes de datos usan un archivo como entrada de métricas.
Si usa orígenes de datos como Azure SQL o Azure Data Explorer, puede usar funciones de agregación para agregar datos al esquema previsible. Esto se debe a que estos orígenes de datos admiten la ejecución de una consulta para obtener datos de métricas de los orígenes.
Si no está seguro del significado de algunos de los términos, consulte este glosario.
Evitar la carga de datos parciales
Los datos parciales se deben a incoherencias entre los datos almacenados en Metrics Advisor y el origen de datos. Esto puede ocurrir cuando se actualiza el origen de datos después de que Metrics Advisor haya terminado de extraer datos. Metrics Advisor solo extrae datos de un origen de datos determinado una vez.
Por ejemplo, si se ha incorporado una métrica a Metrics Advisor con fines de supervisión. Metrics Advisor obtiene correctamente los datos de métricas en la marca de tiempo A y realiza la detección de anomalías en ellos. Sin embargo, si los datos de métricas de la marca de tiempo A concreta se han actualizado después de la ingesta de los datos, no se recuperará el nuevo valor de los datos.
Puede intentar reponer los datos históricos (descritos más adelante) para mitigar las incoherencias, pero esto no desencadenará nuevas alertas de anomalías si ya se han desencadenado alertas para esas marcas de tiempo. Este proceso puede agregar más carga de trabajo al sistema; además, no es automático.
Para evitar que se carguen datos parciales, se recomiendan dos enfoques.
Generar datos en una transacción.
Asegúrese de que los valores de métricas de todas las combinaciones de dimensiones en la misma marca de tiempo se almacenen en el origen de datos, en una sola transacción. En el ejemplo anterior, espere hasta que estén listos los datos de todos los orígenes de datos y, a continuación, cárguelos en Metrics Advisor en una transacción. Metrics Advisor puede sondear la fuente de distribución de datos periódicamente hasta que los datos se recuperen por completo (o parcialmente).
Retrasar la ingesta de datos estableciendo un valor adecuado para el parámetro Ingestion time offset (Desfase en hora de ingesta).
Establezca el parámetro Ingestion time offset (Desfase en hora de ingesta) de la fuente de distribución de datos para retrasar la ingesta hasta que los datos estén totalmente preparados. Esto puede ser útil para algunos orígenes de datos que no admiten transacciones, como Azure Table Storage. Consulte Configuración avanzada para obtener más información.
Para empezar, agregue una fuente de distribución de datos
Después de iniciar sesión en el portal de Metrics Advisor y elegir el área de trabajo, haga clic en Get started (Comenzar). A continuación, en la página principal del área de trabajo, haga clic en Add data feed (Agregar fuente de distribución de datos), en el menú de la izquierda.
Adición de la configuración de conexión
1. Configuración básica
A continuación, deberá especificar un conjunto de parámetros para conectar el origen de datos de series temporales.
- Source Type (Tipo de origen): El tipo de origen de datos donde se almacenan los datos de series temporales.
- Granularity (Granularidad): El intervalo entre los puntos de datos consecutivos de los datos de series temporales. Actualmente, Metrics Advisor admite los siguientes: Yearly (Anual), Monthly (Mensual), Weekly (Semanal), Daily (Diario), Hourly (Cada hora), per minute (por minuto) y Custom (Personalizado). El intervalo más bajo que admite la opción de personalización es de 60 segundos.
- Seconds (Segundos): El número de segundos durante los que granularityName se establece en Customize (Personalizar).
- Ingest data since (UTC) (Ingesta de datos desde [UTC]): La hora de inicio de la línea de base para la ingesta de datos.
startOffsetInSecondsse usa a menudo para agregar un desfase que ayude a que los datos sean coherentes.
2. Especificación de una cadena de conexión
Después, deberá especificar la información de conexión para el origen de datos. Para obtener más información sobre los demás campos y la conexión de distintos tipos de orígenes de datos, consulte Conexión con distintos orígenes de datos.
3. Especificación de una consulta para una sola marca de tiempo
Para más información de los distintos tipos de orígenes de datos, consulte Conexión con distintos orígenes de datos.
Cargar datos
Después de especificar la cadena de conexión y la cadena de consulta, seleccione Cargar datos. En esta operación, Metrics Advisor comprobará la conexión y el permiso para cargar datos, los parámetros necesarios (@IntervalStart and @IntervalEnd) que deben usarse en la consulta y el nombre de columna del origen de datos.
Si se produce un error en este paso:
- En primer lugar, compruebe si la cadena de conexión es válida.
- Luego, compruebe si hay permisos suficientes y que se concede acceso a la dirección IP del trabajo de ingesta.
- Después, compruebe si se usan los parámetros necesarios (@IntervalStart and @IntervalEnd) en la consulta.
Configuración del esquema
Una vez cargado el esquema de datos, seleccione los campos correspondientes.
Si se omite la marca de tiempo de un punto de datos, Metrics Advisor usará la marca de tiempo cuando se ingiera el punto de datos. Para cada fuente de distribución de datos, puede especificar como máximo una columna como una marca de tiempo. Si recibe un mensaje que indica que no se puede especificar una columna como marca de tiempo, compruebe la consulta o el origen de datos, independientemente de que haya varias marcas de tiempo en el resultado de la consulta, no solo en la vista previa de los datos. Al realizar la ingesta de datos, Metrics Advisor solo puede consumir un fragmento (por ejemplo, un día o una hora, según la granularidad) de los datos de series temporales del origen determinado cada vez.
| Número de selección | Descripción | Notas |
|---|---|---|
| Nombre para mostrar | El nombre que se mostrará en el área de trabajo en lugar del nombre de la columna original. | Opcional. |
| Timestamp | La marca de tiempo de un punto de datos. Si se omite, Metrics Advisor usará la marca de tiempo cuando se ingiera el punto de datos. Para cada fuente de distribución de datos, puede especificar como máximo una columna como una marca de tiempo. | Opcional. Debe especificarse con una columna como máximo. Si obtiene un error column cannot be specified as Timestamp (La columna no se puede especificar como marca de tiempo), compruebe la consulta o el origen de datos para ver si hay marcas de tiempo duplicadas. |
| Measure (Medida) | Los valores numéricos de la fuente de distribución de datos. Para cada fuente de distribución de datos, puede especificar varias medidas, pero debe seleccionar al menos una columna como medida. | Debe especificarse con al menos una columna. |
| Dimensión | Los valores de las categorías. Una combinación de valores diferentes identifica una serie temporal de una única dimensión determinada; por ejemplo: Country/region (País/región), Language (Idioma) y Tenant (Inquilino). Puede seleccionar cero o más columnas como dimensiones. Nota: Tenga cuidado al seleccionar una columna que no sea de cadena como dimensión. | Opcional. |
| Omitir | Omite la columna seleccionada. | Opcional. Para que los orígenes de datos admitan el uso de una consulta para obtener datos, no hay ninguna opción "Omitir". |
Si desea omitir las columnas, se recomienda actualizar la consulta o el origen de datos para excluir esas columnas. También puede omitir las columnas seleccionando Ignore columns (Omitir columnas) y, después, Ignore (Omitir) en las columnas específicas. Si una columna debe ser una dimensión y se establece erróneamente como Ignored (Omitida), Metrics Advisor puede acabar ingiriendo datos parciales. Por ejemplo, supongamos que los datos de la consulta son los siguientes:
| Identificador de fila | Timestamp | País/región | Lenguaje | Income |
|---|---|---|---|---|
| 1 | 2019/11/10 | China | ZH-CN | 10000 |
| 2 | 2019/11/10 | China | EN-US | 1000 |
| 3 | 2019/11/10 | US | ZH-CN | 12000 |
| 4 | 2019/11/11 | US | EN-US | 23000 |
| … | … | … | … | … |
Si Country (País) es una dimensión y en Language (Idioma) se selecciona Ignored (Omitido), la primera y la segunda fila tendrán las mismas dimensiones en una marca de tiempo. Metrics Advisor usará arbitrariamente un valor de las dos filas. En este caso, Metrics Advisor no agregará las filas.
Después de configurar el esquema, seleccione Verify schema (Comprobar esquema). En esta operación, Metrics Advisor realizará las siguientes comprobaciones:
- Si la marca de tiempo de los datos consultados está en un solo intervalo.
- Si se han devuelto valores duplicados para la misma combinación de dimensiones dentro de un solo intervalo de métricas.
Configuración de la acumulación automática
Importante
Si desea habilitar el análisis de la causa principal y otras funcionalidades de diagnóstico, es necesario configurar los valores de acumulación automática. Una vez habilitado, no se puede cambiar la configuración de la acumulación automática.
Metrics Advisor puede realizar automáticamente la agregación (por ejemplo, SUM, MAX y MIN) en cada dimensión durante la ingesta y, a continuación, crear una jerarquía que se usará en el análisis de la causa principal y en otras características de diagnóstico.
Considere los siguientes escenarios:
"No necesito incluir el análisis de acumulación en mis datos."
No necesita usar la característica de acumulación de Metrics Advisor.
"Mis datos ya se han acumulado y el valor de dimensión se representa mediante NULL o Empty (NULL o vacío), que es el valor predeterminado, NULL only (Solo NULL) y Others (Otros)."
Esta opción significa que Metrics Advisor no necesita acumular los datos porque las filas ya se han sumado. Por ejemplo, si selecciona NULL only (Solo NULL), la segunda fila de datos del ejemplo siguiente se verá como una agregación de todos los países y del idioma EN-US; la cuarta fila de datos que tiene un valor vacío para Country (País) se considerará, sin embargo, una fila normal que podría indicar datos incompletos.
País/región Lenguaje Income China ZH-CN 10000 (NULL) EN-US 999999 US EN-US 12000 EN-US 5000 "Necesito que Metrics Advisor acumule los datos mediante el cálculo de Sum, Max, Min, Avg y Count, y que los represente mediante {alguna cadena}."
Algunos orígenes de datos, como Azure Cosmos DB o Azure Blob Storage, no admiten ciertos cálculos como agrupar por o cubo. Metrics Advisor proporciona la opción de acumulación para generar automáticamente un cubo de datos durante la ingesta. Esta opción significa que necesita Metrics Advisor para calcular la acumulación mediante el algoritmo que ha seleccionado y usar la cadena especificada para representar la acumulación en Metrics Advisor. Esto no cambiará ningún dato en el origen de datos. Por ejemplo, supongamos que tiene un conjunto de series temporales que representa las métricas Sales con la dimensión (Country, Region) (País, Región). Para una marca de tiempo determinada, podría ser similar a lo siguiente:
Country (País) Region Sales Canadá Alberta 100 Canadá Columbia Británica 500 Estados Unidos Montana 100 Después de habilitar la acumulación automática con SUM, Metrics Advisor calculará las combinaciones de dimensiones y sumará las métricas durante la ingesta de datos. El resultado podría ser el siguiente:
Country (País) Region Sales Canadá Alberta 100 NULL Alberta 100 Canadá Columbia Británica 500 NULL Columbia Británica 500 Estados Unidos Montana 100 NULL Montana 100 NULL NULL 700 Canadá NULL 600 Estados Unidos NULL 100 (Country=Canada, Region=NULL, Sales=600)significa que la suma de Sales (Ventas) en Canadá (todas las regiones) es 600.Lo siguiente es la transformación en lenguaje SQL.
SELECT dimension_1, dimension_2, ... dimension_n, sum (metrics_1) AS metrics_1, sum (metrics_2) AS metrics_2, ... sum (metrics_n) AS metrics_n FROM each_timestamp_data GROUP BY CUBE (dimension_1, dimension_2, ..., dimension_n);Tenga en cuenta lo siguiente antes de usar la característica de acumulación automática.
- Si desea usar SUM para agregar los datos, asegúrese de que las métricas se suman en cada dimensión. Estos son algunos ejemplos de métricas no aditivas.
- Métricas basadas en fracciones. Se incluyen la proporción, el porcentaje, etc. Por ejemplo, en EE. UU., no debe agregar la tasa de desempleo de cada estado para calcular la tasa de desempleo de todo el país/región.
- Superposición en una dimensión. Por ejemplo, no debe agregar el número de personas de cada deporte para calcular el número de personas a las que les gusta el deporte, ya que hay una superposición entre ellas: a una persona le pueden gustar varios deportes.
- Para garantizar el buen estado de todo el sistema, el tamaño del cubo es limitado. Actualmente, el límite es 100 000. Si los datos superan ese límite, se producirá un error en la ingesta en esa marca de tiempo.
- Si desea usar SUM para agregar los datos, asegúrese de que las métricas se suman en cada dimensión. Estos son algunos ejemplos de métricas no aditivas.
Configuración avanzada
Hay varios valores de configuración avanzada para habilitar la ingesta de datos de forma personalizada; por ejemplo, especificando el desfase en la ingesta o la simultaneidad. Para obtener más información, consulte la sección Configuración avanzada del artículo sobre la administración de fuentes de distribución de datos.
Especificación de un nombre para la fuente de distribución de datos y comprobación del progreso de la ingesta
Proporcione un nombre personalizado a la fuente de distribución de datos, que se mostrará en el área de trabajo. Después, seleccione Enviar. En la página de detalles de la fuente de distribución de datos, puede usar la barra de progreso de la ingesta para ver la información del estado.

Para comprobar los detalles del error de la ingesta:
- Seleccione Mostrar detalles.
- Haga clic en Estado y seleccione Fallida o Error.
- Mantenga el mouse sobre una ingesta fallida y vea el mensaje de detalles que aparece.
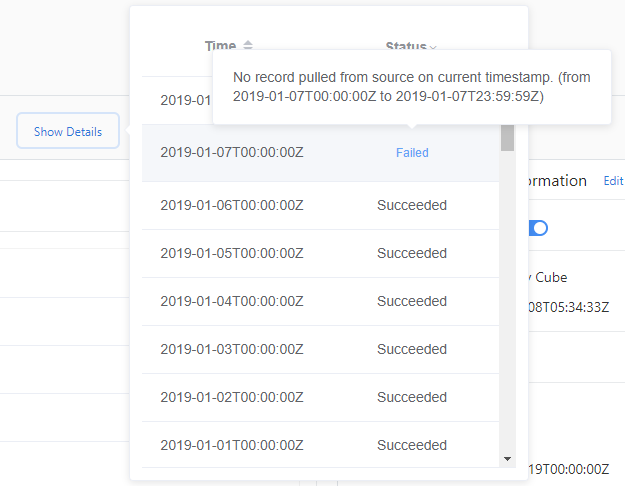
Un estado Failed (Fallida) indica que la ingesta de este origen de datos se volverá a intentar más tarde. Un estado Error indica que Metrics Advisor no volverá a intentarlo en el origen de datos. Para recargar los datos, debe desencadenar manualmente un proceso de reposición o recarga.
También puede recargar el progreso de una ingesta haciendo clic en Refresh Progress (Actualizar progreso). Tras completar la ingesta de datos, puede hacer clic en las métricas y comprobar los resultados de la detección de anomalías.