En este artículo se presenta un árbol de decisión y ejemplos de opciones de alta disponibilidad (HA) y recuperación ante desastres (DR) al implementar aplicaciones de infraestructura como servicio (IaaS) de varios niveles en Azure.
Architecture
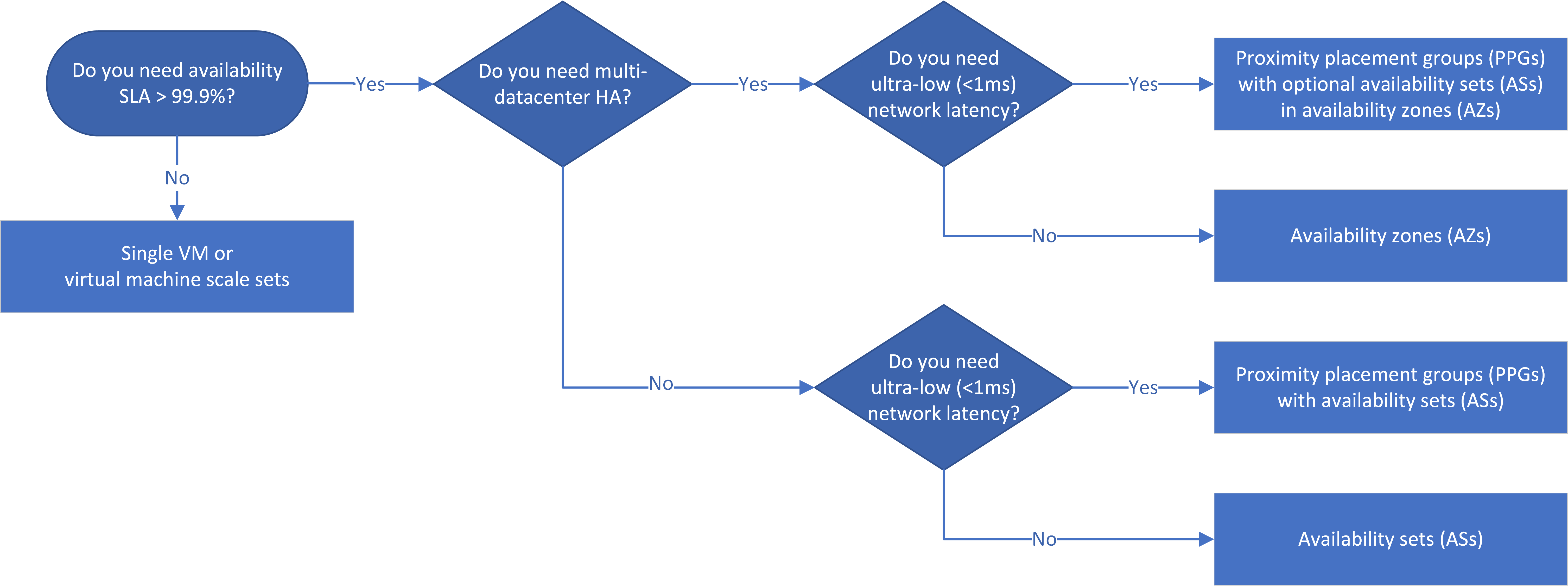
Flujo de trabajo
Los conjuntos de disponibilidad (AS) proporcionan redundancia y disponibilidad de la máquina virtual en un centro de datos mediante la distribución de las máquinas virtuales en varios nodos de hardware aislados. Un subconjunto de las máquinas virtuales se mantiene en ejecución durante el tiempo de inactividad planeado o no planeado, de modo que toda la aplicación permanece disponible y operativa.
Las zonas de disponibilidad (AZ) son ubicaciones físicas exclusivas que ocupan los centros de datos de una región de Azure. Cada zona de disponibilidad accede a uno o varios centros de datos que tienen alimentación, refrigeración y redes independientes, y cada región de Azure habilitada para zonas de disponibilidad tiene un mínimo de tres independientes. La separación física de las zonas de disponibilidad dentro de una región protege las máquinas virtuales implementadas frente a los errores del centro de datos.
En el diagrama de flujo de decisión se refleja el principio de que las aplicaciones de alta disponibilidad deben usar zonas de disponibilidad si es posible. La alta disponibilidad entre zonas y, por tanto, entre centros de datos, proporciona un Acuerdo de Nivel de Servicio superior al 99,99 % debido a la resistencia a los errores en el centro de datos.
No se garantiza que los conjuntos de disponibilidad y las zonas de disponibilidad para diferentes niveles de aplicación se encuentren dentro de los mismos centros de datos. Si la latencia de la aplicación es una preocupación principal, debe ubicar los servicios en un único centro de datos mediante grupos con ubicación por proximidad (PPG) con conjuntos de disponibilidad y zonas de disponibilidad.
Componentes
Alternativas
Como alternativa a la recuperación ante desastres regional mediante Azure Site Recovery, si la aplicación puede replicar datos de forma nativa, puede implementar la recuperación ante desastres para varias regiones mediante servidores en espera activa o pasiva, como un clúster extendido solo para la recuperación ante desastres. Esta alternativa no se detalla específicamente en los ejemplos, pero se podría agregar a cualquiera de las soluciones. Tenga en cuenta que la replicación entre regiones es asincrónica y se espera cierta pérdida de datos.
Como alternativa, si tiene una tecnología de replicación de datos propia, puede usarla para crear una zona secundaria dentro la región para la recuperación ante desastres. En función de la región de las cargas de trabajo, también podría usar Azure Site Recovery para replicar elementos en una zona alternativa; puede comprobar la disponibilidad regional y obtener más información sobre esta característica en Habilitación de la recuperación ante desastres de zona a zona para máquinas virtuales de Azure.
La alta disponibilidad de varias regiones es posible, pero requiere un equilibrador de carga global como Front Door o Traffic Manager. Para más información, consulte Ejecución de una aplicación de N niveles en varias regiones de Azure para lograr alta disponibilidad.
Detalles del escenario
Las arquitecturas de varios niveles o n niveles son habituales en las aplicaciones locales tradicionales, por lo que son una opción natural para migrar aplicaciones locales a la nube, o bien para desarrollar aplicaciones tanto en el entorno local como en la nube. Normalmente, las arquitecturas de n niveles se implementan como aplicaciones IaaS divididas en niveles lógicos y físicos, con un nivel de presentación o web superior, un nivel empresarial intermedio y un nivel de datos.
En una aplicación IaaS de n niveles, cada nivel se ejecuta en un conjunto independiente de máquinas virtuales. Los niveles web y empresarial carecen de estado, lo que significa que cualquier máquina virtual del nivel puede controlar cualquier solicitud para ese nivel. La capa de datos es una base de datos replicada, almacenamiento de objetos o almacenamiento de archivos. En cada nivel, varias máquinas virtuales proporcionan resistencia si se produce un error en una de ellas, y los equilibradores de carga distribuyen las solicitudes entre las máquinas virtuales.
Puede escalar horizontalmente los niveles si agrega más máquinas virtuales a los grupos y usar conjuntos de escalado de máquinas virtuales para escalar horizontalmente máquinas virtuales idénticas de forma automática. Como se usan equilibradores de carga, puede escalar horizontalmente los niveles sin afectar al tiempo de actividad de la aplicación.
Si el Acuerdo de Nivel de Servicio (SLA) para una aplicación IaaS requiere una disponibilidad superior al 99 %, puede colocar las máquinas virtuales en conjuntos de disponibilidad, zonas de disponibilidad y grupos con ubicación por proximidad a fin de configurar la alta disponibilidad de la aplicación. Las soluciones de alta disponibilidad y recuperación ante desastres que elija dependen del Acuerdo de Nivel de Servicio, las consideraciones de latencia y los requisitos de recuperación ante desastres regionales.
Posibles casos de uso
- Migración de una aplicación de n niveles desde un entorno local a la nube.
- Implementación de una aplicación de n niveles tanto en un entorno local como en la nube.
- Configuración de alta disponibilidad y recuperación ante desastres para una aplicación IaaS.
Esta solución se puede usar para cualquier sector, incluidos los siguientes escenarios:
- Aplicaciones del sector público
- Banca (sector financiero)
- Atención sanitaria
Consideraciones
Las zonas de disponibilidad no están disponibles en todas las regiones de Azure.
Decida qué opción de implementación quiere usar antes de compilar la solución. Aunque es posible, no es fácil cambiar de una opción a otra después de la implementación. Es un proceso implicado: tendría que eliminar las máquinas virtuales y volver a crearlas a partir de los discos administrados subyacentes.
Asegúrese de que puede asignar la aplicación a la solución seleccionada. Muchos diseños y patrones de resistencia de nivel de aplicación están fuera del ámbito de este árbol de decisión.
Hay tres escenarios que pueden provocar reinicios de las máquinas virtuales de Azure: mantenimiento de hardware no planeado, tiempo de inactividad inesperado y mantenimiento planeado. Para obtener más información sobre estos eventos y los procedimientos recomendados de alta disponibilidad para reducir su impacto, vea Descripción de las diferencias entre reinicios de máquina virtual, mantenimiento y tiempo de inactividad.
Máquinas virtuales únicas
Si una aplicación no requiere disponibilidad superior al 99,9 %, no es necesario configurarla para la alta disponibilidad y puede implementar máquinas virtuales individuales. Puede usar conjuntos de escalado de máquinas virtuales para escalar horizontalmente máquinas virtuales idénticas de forma automática. Implemente máquinas virtuales únicas sin especificar una zona, de modo que se distribuyan en toda la región. Estas aplicaciones tienen un Acuerdo de Nivel de Servicio del 99,9 % si usa discos SSD Premium de Azure.
Las máquinas virtuales únicas usan la funcionalidad de recuperación de servicio predeterminada integrada en todos los centros de datos de Azure. En el caso de los errores predecibles, esta funcionalidad suele usar la migración en vivo, pero durante los eventos imprevisibles, es posible que las máquinas virtuales se reinicien o no estén disponibles.
Alta disponibilidad
Si la aplicación requiere un Acuerdo de Nivel de Servicio superior al 99,9 %, tendrá que diseñarla para alta disponibilidad. Use zonas de disponibilidad si es posible, ya que proporcionan tolerancia a errores del centro de datos. Puede usar grupos de disponibilidad en lugar de zonas de disponibilidad, pero se reduce la disponibilidad del 99,99 % al 99,95 %, ya que los grupos de disponibilidad no pueden tolerar errores en el centro de datos.
Las zonas de disponibilidad son adecuadas para muchos escenarios de aplicaciones agrupadas, como clústeres de SQL Always On, mediante activo-activo, activo-pasivo o una combinación de los dos niveles de alta disponibilidad en cada nivel con conmutación por error rápida. La replicación sincrónica es posible entre cualquier nodo del sistema de administración de bases de datos (DBMS), debido a la baja latencia de la red entre zonas. También puede ejecutar una configuración de clúster extendido entre zonas, que tiene una latencia mayor y admite la replicación asincrónica.
Si quiere usar un árbitro de clúster basado en la máquina virtual, por ejemplo un testigo de recurso compartido de archivos, colóquelo en la tercera zona de disponibilidad para asegurarse de que el cuórum no se pierda si se produce un error en alguna de las zonas. Como alternativa, es posible que pueda usar un testigo basado en la nube en otra región.
Todas las máquinas virtuales de una zona de disponibilidad se encuentran en un único dominio de error (FD) y un dominio de actualización (UD), lo que significa que comparten una fuente de alimentación y un conmutador de red, y se pueden reiniciar al mismo tiempo. Si crea máquinas virtuales en zonas de disponibilidad distintas, se distribuyen de manera eficaz entre diferentes FD y UD, por lo que no se producirá un error en ellas ni se reiniciarán al mismo tiempo. Si quiere tener máquinas virtuales redundantes internas de la zona, así como máquinas virtuales entre zonas, debe colocar las internas en conjuntos de disponibilidad en PPG para asegurarse de que no se reinicien a la vez. Incluso en el caso de cargas de trabajo con una sola instancia de máquina virtual que no son redundantes hoy en día, todavía tiene la opción de usar conjuntos de disponibilidad en los PPG para permitir el crecimiento y la flexibilidad en el futuro.
Para implementar conjuntos de escalado de máquinas virtuales entre zonas de disponibilidad, considere la posibilidad de usar el modo de orquestación, actualmente en versión preliminar pública, que permite combinar FD y AZ.
Las zonas de disponibilidad con PPG internos de la zona permiten una de las latencias de red más bajas en Azure y un Acuerdo de Nivel de Servicio de al menos el 99,99 % debido a la resistencia de varios centros de datos. Cuando sea posible, use redes aceleradas en las máquinas virtuales.
Esta solución puede presentar un escenario en el que un servicio que se ejecuta en una máquina virtual en una zona tenga que interactuar con un servicio de otra. Por ejemplo, podría haber un nivel web activo-activo y un nivel de base de datos activo-pasivo entre zonas. Algunas solicitudes cruzarán zonas, lo que introduce latencia. Aunque la latencia entre zonas sigue siendo muy baja, si tiene que garantizar la menor latencia posible, mantenga todas las comunicaciones de red entre los niveles de aplicación dentro de una zona.
Consideraciones de latencia
La latencia de red depende, entre otros factores, de la distancia física entre las máquinas virtuales implementadas. Si una aplicación requiere una latencia muy baja entre los niveles, puede implementarla en un único centro de datos, mediante un PPG con conjuntos de disponibilidad para cada nivel. Si es posible, use redes aceleradas en las máquinas virtuales. Este escenario permite una de las latencias de red más bajas de Azure y un Acuerdo de Nivel de Servicio del 99,95 %.
Puede usar las herramientas siguientes para obtener una visión más detallada de las condiciones de latencia de diversos escenarios:
- Para probar la latencia entre las máquinas virtuales, vea Comprobación de la latencia de red de la máquina virtual.
- Para probar la latencia entre zonas, use AvZone-Latency-Test. Esta prueba puede ayudarle a determinar qué zonas lógicas tienen la latencia más baja para la suscripción.
- Para probar la latencia entre regiones de Azure, use http://www.azurespeed.com/. Esta herramienta actualizada periódicamente puede ser útil a la hora de considerar la replicación asincrónica entre regiones.
Recuperación ante desastres
Las consideraciones sobre recuperación ante desastres incluyen la disponibilidad, la capacidad de la aplicación de seguir ejecutándose en un estado correcto y la durabilidad de los datos, su conservación en caso de desastre.
La conmutación por error de alta disponibilidad debe ser rápida, sin pérdida de datos, y tener un efecto muy limitado en el servicio. Por el contrario, una conmutación por error de recuperación ante desastres tradicional puede tener asociados un objetivo de tiempo de recuperación (RTO) y un objetivo de punto de recuperación (RPO) más largos, y ser asincrónica, con posible pérdida de datos.
Puede aprovechar las ventajas de las zonas de disponibilidad para la alta disponibilidad y la recuperación ante desastres si usa otra zona de disponibilidad para la solución de recuperación ante desastres. Pero el uso de una zona de disponibilidad no garantiza que los centros de datos de cada zona estén físicamente separados.
Azure Site Recovery le permite replicar las máquinas virtuales en otra región de Azure para la recuperación ante desastres regional y la continuidad empresarial. Puede usar Azure Site Recovery para recuperar las aplicaciones en caso de que se produzcan interrupciones en la región de origen, o bien para realizar simulacros periódicos de recuperación ante desastres a fin de asegurarse de que se satisfacen los requisitos de cumplimiento.
Si la aplicación admite Azure Site Recovery, puede proporcionar una solución de recuperación ante desastres regional para aumentar la protección, si la importancia crítica de la aplicación lo exige. Pero la alta disponibilidad entre centros de datos y zonas puede ser una protección suficiente, porque si una aplicación es totalmente resistente a los errores del centro de datos, no debería haber tiempo de inactividad ni pérdida de datos.
Optimización de costos
No hay ningún coste adicional para las máquinas virtuales implementadas en zonas de disponibilidad. Es posible que haya gastos adicionales de transferencia de datos de una máquina virtual a otra entre zonas de disponibilidad. Para obtener más información, vea la página Precios de ancho de banda.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Shaun Croucher | Consultor sénior
Pasos siguientes
- Conjuntos de disponibilidad
- Zonas de disponibilidad
- Conjuntos de escalado de máquinas virtuales
- Habilitación de la recuperación ante desastres de máquinas virtuales de Azure
Recursos relacionados
- Estilo de arquitectura de n niveles
- Aplicación web de varios niveles creada para lograr alta disponibilidad y recuperación ante desastres en Azure
- Ejecución de aplicaciones web con redundancia de zona de alta disponibilidad
- Ejecución de una aplicación web en varias regiones de Azure para alta disponibilidad
- Ejecución de una aplicación de N niveles en varias regiones de Azure para lograr alta disponibilidad