Los minoristas y las marcas de consumidor se centran en garantizar que tienen los productos y servicios adecuados que los consumidores buscan para comprar en marketplace. Cuando se busca maximizar las ventas, los productos (o combinaciones de productos) son la parte principal de la experiencia de compra. La disponibilidad de ofertas (inventario) constituye un problema constante para las marcas de consumidor.
El inventario de productos, también conocido como surtido de SKU, es un problema complejo que abarca la cadena de valor de suministro y logística. En este artículo, nos centraremos específicamente en el problema de optimizar el surtido de SKU para maximizar los ingresos desde un punto de vista de los bienes de consumo.
Puede resolver el rompecabezas de la optimización del surtido de SKU desarrollando algoritmos para responder a las preguntas siguientes:
- ¿Qué SKU rinden mejor en una tienda o mercado determinado?
- ¿Qué SKU se deben asignar a un determinado mercado o tienda en función de su rendimiento?
- ¿Qué SKU tienen un rendimiento bajo y deben reemplazarse por SKU de mayor rendimiento?
- ¿Qué otra información podemos derivar sobre nuestros segmentos de mercado y consumidores?
Automatización de la toma de decisiones
Tradicionalmente, las marcas de consumo abordaban el problema la demanda de los consumidores aumentando el número de referencias en la cartera de referencias de almacén. Dado este aumento y la mayor competencia existente en la actualidad, se estima que el 90 % de los ingresos se atribuye a solo el 10 % de referencias de almacén del producto que hay en la cartera. Normalmente, el 80 por ciento de los ingresos se acumula del 20 por ciento de SKU. Y esta relación es un candidato para mejorar la rentabilidad.
Los métodos tradicionales de generación de informes estáticos usan los datos históricos, lo que limita la información. En el mejor de los casos, las decisiones aún se toman e implementan manualmente. Esto se traduce en intervención humana y tiempo de procesamiento. Con los avances de la inteligencia artificial y la informática en la nube, es posible utilizar análisis avanzado para proporcionar diversas opciones y predicciones. Este tipo de automatización mejora los resultados y la comercialización.
Optimización del surtido de SKU
Una solución de surtido de SKU debe controlar millones de SKU mediante la segmentación de datos de ventas en comparaciones significativas y detalladas. El objetivo de la solución es utilizar análisis avanzados para maximizar las ventas en cada punto de venta o tienda ajustando el surtido de productos. Un segundo objetivo es eliminar el desabastecimiento y mejorar los surtidos. El objetivo fiscal es un aumento del 5 al 10 por ciento de las ventas. Con tal objetivo, las conclusiones permiten:
- Comprender el rendimiento de la cartera de SKU y administrar las de bajo rendimiento.
- Optimizar la distribución de SKU para reducir el desabastecimiento.
- Comprender cómo las nuevas SKU admiten las estrategias a corto y largo plazo.
- Crear conclusiones repetibles, escalables y procesables a partir de los datos existentes.
Análisis descriptivo
Los modelos descriptivos agregan puntos de datos y exploran las relaciones entre los factores que pueden influir en las ventas de los productos. La información se puede ampliar con algunos puntos de datos externos, como la ubicación, el clima y los datos del censo. Las visualizaciones ayudan a las personas a obtener información mediante la interpretación de los datos. Sin embargo, al hacerlo, los conocimientos se limitan a lo qué ha ocurrido durante el ciclo de ventas anterior o, posiblemente, a lo que sucede en el actual (según la frecuencia con que se actualicen los datos).
En este caso, un enfoque de informes y almacenamiento de datos tradicional es suficiente para comprender, por ejemplo, qué SKU se han comportado mejor y peor durante un período de tiempo.
La siguiente figura muestra un informe típico de datos de ventas históricos. Ofrece varios bloques con casillas para seleccionar los criterios para filtrar los resultados. En el centro aparecen dos gráficos de barras que muestran las ventas a lo largo del tiempo. El primer gráfico muestra el promedio de ventas por semana. Por su parte, el segundo muestra las cantidades semanales.

Análisis predictivo
Los informes históricos ayudan a saber lo que ha sucedido. Pero, en último término, lo que queremos es una previsión de lo que probablemente ocurra. La información del pasado puede ser útil para tal fin. Por ejemplo, podemos identificar tendencias de temporada. Pero esto no resulta de ayuda en escenarios “hipotéticos”, por ejemplo, para modelar la introducción de un producto nuevo. Para ello, es preciso cambiar el centro de atención hacia el modelado del comportamiento del cliente, ya que ese es el factor final que determina las ventas.
Una mirada en profundidad al problema: modelos de elección
Vamos a empezar definiendo lo que estamos buscando y los datos que tenemos:
La optimización del surtido significa encontrar un subconjunto de los productos que se van a vender que maximice los ingresos esperados. Esto es lo que estamos buscando.
Los datos de transacción se recopilan de forma rutinaria con fines financieros.
Los datos de surtido pueden incluir todo lo relacionado con las referencias de almacén. Este es un ejemplo de lo que queremos:
- El número de referencias de almacén
- Descripciones de las SKU
- Cantidades asignadas
- SKU y cantidad comprada
- Marcas de tiempo de los eventos (por ejemplo, la compra)
- Precio de la SKU
- Precio de la SKU en los puntos de venta
- Nivel de existencias de todas las referencias de almacén en todo momento
Lamentablemente, tales datos no se recopilan tan confiablemente como los datos de transacción.
En este artículo, por motivos de simplicidad, solo consideraremos datos de transacciones y datos de SKU, no factores externos.
Aun así, tenga en cuenta que, dado un conjunto de n productos, hay 2n posibles surtidos. Esto hace que el problema de optimización sea un proceso muy intenso desde el punto de vista computacional. Evaluar todas las combinaciones posibles no es práctico con una gran cantidad de productos. Por lo general, los surtidos se segmentan por categoría (por ejemplo, cereales), ubicación y otros criterios para reducir el número de variables. Los modelos de optimización intentan eliminar el número de permutaciones a un subconjunto manejable.
El quid del problema se basa en el modelado del comportamiento de los consumidores eficazmente. En un mundo perfecto, los productos que se les presentan coincidirán con los que desean comprar.
A lo largo de décadas se han desarrollado modelos matemáticos para predecir las elecciones que realizan los consumidores. La elección del modelo determinará en última instancia la tecnología de implementación más adecuada. Por lo tanto, los resumiremos y ofreceremos algunas consideraciones.
Modelos paramétricos
Los modelos paramétricos aproximación el comportamiento de los clientes mediante el uso de una función con un conjunto finito de parámetros. Estimamos el conjunto de parámetros para ajustar mejor los datos a nuestra disposición. Uno de los más antiguos y conocidos es la regresión logística multinomial (también conocida como MNL, función logit de varias clases o regresión softmax). Se utiliza para calcular las probabilidades de varios resultados posibles en los problemas de clasificación. En este caso, puede usar MNL para calcular:
La probabilidad de que un consumidor (c) elija un elemento (i) en un momento determinado (t), dado un conjunto de elementos de esa categoría en un surtido (a) con una utilidad conocida para el cliente (v).
También se supone que la utilidad de un elemento puede ser una función de sus características. También se puede incluir información externa en la medida de la utilidad (por ejemplo, un paraguas es más útil cuando llueve).
A menudo usamos MNL como punto de referencia para otros modelos debido a su manejabilidad al estimar parámetros y al evaluar resultados. En otras palabras, si lo hace peor que MNL, su algoritmo no sirve de nada.
Se han derivado varios modelos de MNL, pero queda fuera del ámbito de este documento hablar sobre ellos.
Existen bibliotecas para los lenguajes de programación R y Python. Para R, puede usar glm (y derivados). Para Python, existen scikit-aprender, biogeme y larch. Estas bibliotecas ofrecen herramientas para especificar problemas de MNL y solucionadores paralelos para encontrar soluciones en diversas plataformas.
Recientemente, se ha propuesto que la implementación de modelos de MNL en GPU calcule modelos complejos con una serie de parámetros que, de lo contrario, los harían intratables.
Se han utilizado de forma eficaz redes neuronales con una capa de salida softmax en grandes problemas de varias clases. Estas redes generan un vector de salidas que representan una distribución de probabilidad a través de una serie de resultados diferentes. Resultan lentos de entrenar, en comparación con otras implementaciones, pero pueden controlar un gran número de clases y parámetros.
Modelos no paramétricos
A pesar de su popularidad, MNL coloca algunas suposiciones importantes en el comportamiento humano que pueden limitar su utilidad. En concreto, se supone que la probabilidad relativa de que alguien elija entre dos opciones es independiente de alternativas adicionales introducidas en el conjunto más adelante. En la mayoría de los casos, esto es poco práctico.
Por ejemplo, si le gustan los productos A y B de igual manera, elegirá uno, en lugar del otro, el 50 % del tiempo. Vamos a introducir el producto C en la mezcla. Puede elegir el producto A el 50 % del tiempo, pero ahora divide su preferencia un 25 % al producto B y otro 25 % al producto C. La probabilidad relativa ha cambiado.
Además, tanto MNL y los derivados no tienen una forma sencilla de explicar las sustituciones que son debidas a una variedad de surtidos o desabastecimiento (es decir, cuando no tiene una idea clara y elige un artículo al azar entre los que están en el estante).
Los modelos no paramétricos están diseñados para explicar las sustituciones e imponer menos restricciones en el comportamiento de los clientes.
Introducen el concepto de clasificación, donde los consumidores expresan una preferencia estricta por los productos de un surtido. Por consiguiente, su comportamiento de compra se puede modelar clasificando los productos en orden descendente de preferencia.
El problema de optimización del surtido se puede expresar como maximización de ingresos:
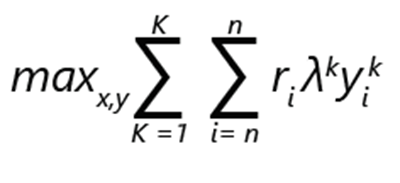
- ri denota los ingresos del producto i.
- yik es 1 si el producto i se elige en la clasificación k. De lo contrario, es 0.
- λk es la probabilidad de que el cliente realice una elección según la clasificación k.
- xi es 1 si el producto está incluido en el surtido. De lo contrario, es 0.
- K es el número de clasificaciones.
- n es el número de productos.
Nota:
sujeto a restricciones:
- puede haber exactamente una elección para cada clasificación.
- En una clasificación k, solo se puede elegir un producto i si forma parte del surtido.
- Si un producto i se incluye en el surtido, no se puede elegir ninguna de las opciones menos preferibles en la clasificación k.
- No comprar es una opción y, como tal, se puede no elegir ninguna de las opciones menos preferibles en una clasificación.
En una formulación de este tipo, el problema puede considerarse como una optimización de enteros mixtos.
Consideremos que, si hay n productos, el número máximo de clasificaciones posibles, incluida la opción de no elección, es factorial: (n + 1)!
Las restricciones de la formulación permiten una eliminación relativamente eficaz de las opciones posibles. Por ejemplo, solo se elige la opción más preferible y se establece en 1. El resto se establece en 0. Puede imaginar que la escalabilidad de la implementación será importante, dado el número de alternativas posibles.
La importancia de los datos
Hemos mencionado antes que los datos de ventas están fácilmente disponibles. Queremos usarlos para informar a nuestro modelo de optimización del surtido. En particular, queremos encontrar nuestra distribución de probabilidad λ.
Los datos de ventas obtenidos del sistema de puntos de ventas se componen de transacciones con marcas de tiempo y de un conjunto de productos que se muestran a los clientes en ese momento y ubicación. A partir de ellos, podemos crear un vector de ventas reales, cuyos elementos vi,m representan la probabilidad de vender el artículo i a un cliente dado un surtido Sm
También podemos construir una matriz:
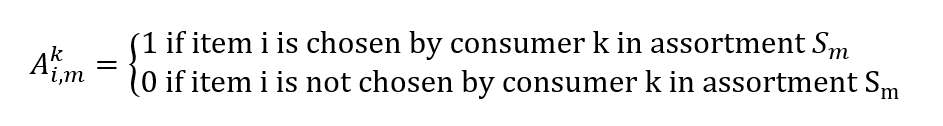
La búsqueda de nuestra distribución de probabilidad λ dados nuestros datos de ventas se convierte en otro problema de optimización. Queremos encontrar un vector λ para minimizar nuestros errores de estimación de ventas:
minλ |Λλ - v|
Tenga en cuenta que el cálculo también se puede expresar como una regresión y, por lo tanto, se pueden usar modelos como árboles de decisión multivariantes.
Detalles de la implementación
Como podemos deducir de la formulación anterior, los modelos de optimización se controlan mediante datos y hacen un uso intensivo del cálculo.
Asociados de Microsoft, como Neal Analytics, han desarrollado arquitecturas sólidas para satisfacer esas condiciones. Consulte SKU Max. Utilizaremos esas arquitecturas como ejemplo y ofreceremos algunas consideraciones.
- En primer lugar, se basan en una canalización de datos sólida y escalable para alimentar los modelos, etc. y una infraestructura de ejecución sólida y escalable para ejecutarlos.
- En segundo lugar, los planificadores pueden consumir fácilmente los resultados a través de un panel.
En la figura 2 se muestra una arquitectura de ejemplo. Incluye cuatro bloques principales: capturar, procesar, modelar y poner en marcha. Cada bloque contiene procesos importantes. Capturar incluye preprocesamiento de datos; procesar incluye la función datos de la tienda; modelar incluye la función de entrenar modelo de Machine Learning y poner en marcha incluye datos de la tienda y opciones de informe (por ejemplo, paneles).

Figura 2: arquitectura para la optimización de una referencia de almacén, cortesía de Neal Analytics
La canalización de datos
La arquitectura destaca la importancia de establecer una canalización de datos para el entrenamiento y las operaciones del modelo. Organizamos las actividades en la canalización mediante Azure Data Factory, un servicio administrado de extracción, transformación y carga (ETL) de datos que permite diseñar y ejecutar los flujos de trabajo de integración.
Azure Data Factory es un servicio administrado con componentes denominados actividades que consumen o generan conjuntos de datos.
Las actividades se pueden dividir en:
- Movimiento de datos (por ejemplo, copiar del origen al destino)
- Transformación de datos (por ejemplo, agregar con una consulta SQL o ejecutar un procedimiento almacenado)
El servicio Data Factory puede programar, supervisar y administrar los flujos de trabajo que vinculan conjuntos de actividades. El flujo de trabajo completo se denomina una canalización.
En la fase de captura, podemos usar la actividad de copia de Data Factory para transferir datos desde numerosos orígenes (tanto locales como en la nube) a Azure SQL Data Warehouse. En la documentación se proporcionan ejemplos de cómo hacerlo:
- Copia de datos con Azure SQL Data Warehouse como origen o destino mediante Azure Data Factory
- Carga de datos en Azure SQL Data Warehouse mediante Azure Data Factory
La siguiente figura muestra la definición de una canalización. Consta de tres bloques de igual tamaño seguidos. Los dos primeros son un conjunto de datos y una actividad conectados mediante flechas para indicar los flujos de datos. El tercer bloque tiene la etiqueta Canalización y apunta a los dos primeros para indicar la encapsulación.

Figura 3: Conceptos básicos de Azure Data Factory
En la página de Marketplace comercial de Microsoft puede encontrar un ejemplo del formato de datos que usa la solución de Neal Analytics. La solución incluye los conjuntos de datos siguientes:
- Datos históricos de ventas para cada combinación de tienda y SKU
- Registros de tienda y consumidor
- Códigos y descripción de SKU
- Atributos de SKU que capturan características de los productos (por ejemplo, el tamaño y el material). Se suelen utilizar en modelos paramétricos para diferenciar entre las variantes de producto.
Si los orígenes de datos no se expresan en el formato determinado, Data Factory ofrece una serie de actividades de transformación.
En la fase de proceso, SQL Data Warehouse es el motor de almacenamiento principal. Puede expresar una actividad de transformación como un procedimiento almacenado de SQL, que se puede invocar automáticamente como parte de la canalización. La documentación proporciona instrucciones detalladas:
Tenga en cuenta que Data Factory no le limita a SQL Data Warehouse y procedimientos almacenados de SQL. De hecho, se integra con diversas plataformas. Por ejemplo, puede usar Databricks y ejecutar un script de Python para la transformación. Esto es una ventaja, ya que puede usar una sola plataforma para el almacenamiento, la transformación y el entrenamiento de algoritmos de aprendizaje automático en la siguiente fase del modelo.
Entrenamiento del algoritmo de ML
Hay varias herramientas que pueden ayudarle a implementar los modelos, tanto los paramétricos como los no paramétricos. La elección depende de los requisitos de escalabilidad y rendimiento.
Azure ML Studio es una excelente herramienta para la creación de prototipos. Proporciona una manera fácil de crear y ejecutar un flujo de trabajo de entrenamiento con los módulos de código (en R o Python), o con componentes de ML predefinidos (por ejemplo, clasificadores multiclase y regresión de árbol de decisión incrementado) en un entorno gráfico. También facilita la publicación de un modelo entrenado como un servicio web para el consumo adicional, ya que genera una interfaz REST automáticamente.
Sin embargo, actualmente, el tamaño de los datos que puede controlar se limita a 10 GB y el número de núcleos disponibles para cada componente también se limita a dos.
Si necesita realizar un mayor escalado, pero desea las rápidas implementaciones de Microsoft en paralelo del algoritmo de aprendizaje automático común (por ejemplo, la regresión logística multinomial), puede plantearse usar Microsoft ML Server, si se ejecuta en Azure Data Science Virtual Machine.
Para tamaños de datos muy grandes (TB), tiene sentido elegir una plataforma donde el almacenamiento y el elemento de cálculo pueden:
- Escalar por separado, para limitar los costos cuando no se entrenan los modelos.
- Distribuir el cálculo entre varios núcleos.
- Ejecutar el cálculo cerca del almacenamiento para limitar el movimiento de datos.
Azure HDInsight y Databricks cumplen esos requisitos. Además, ambas plataformas de ejecución son compatibles con el editor de Azure Data Factory. Por consiguiente, es relativamente sencillo integrar cualquiera de ellas en un flujo de trabajo.
ML Server y sus bibliotecas se pueden implementar sobre HDInsight, pero para aprovechar al máximo las funcionalidades de la plataforma, se puede implementar el algoritmo de ML preferido mediante SparkML, las bibliotecas de Microsoft ML Spark en Python u otro solucionador de programación lineal especialista, como TFoCS, Spark-LP o SolveDF.
Iniciar el proceso de entrenamiento se convierte en una cuestión de invocar el cuaderno o el script de pySpark adecuado desde un flujo de trabajo de Data Factory. Esto se admite completamente en el editor gráfico. Para más detalles, consulte Ejecución de un cuaderno de Databricks con la actividad de cuaderno de Databricks en Azure Data Factory.
En la siguiente figura se muestra la interfaz de usuario de Data Factory, a la que se accede a través de Azure Portal. Incluye bloques para los distintos procesos del flujo de trabajo.

Figura 4: ejemplo de canalización de Data Factory con actividad de cuaderno de Databricks
Asimismo, tenga en cuenta que en nuestra solución de optimización de inventarios proponemos una implementación basada en contenedores de los solucionadores que se escala a través de Azure Batch. Las bibliotecas de optimización especializadas, como pyomo, permiten expresar un problema de optimización mediante el lenguaje de programación Python y, después, invocar solucionadores independientes, como bonmin (código abierto) o gurobi (comercial) para encontrar una solución.
La documentación de optimización de inventario se ocupa de un problema diferente (cantidades de pedidos) de la optimización del surtido, aunque la implementación de solucionadores en Azure es aplicable de forma similar.
Aunque es más compleja que las sugeridas hasta ahora, esta técnica permite una escalabilidad máxima, limitada principalmente por el número de núcleos que se puede permitir.
Ejecución del modelo (puesta en marcha)
Tras entrenar el modelo, su ejecución normalmente requiere una infraestructura diferente de la que se utilizó para la implementación. Para que sea fácil de consumir, puede implementarlo como un servicio web con una interfaz de REST. Tanto Azure ML Studio como ML Server automatizan el proceso de creación de tales servicios. En el caso de ML Server, Microsoft proporciona plantillas para la implementación de una infraestructura de soporte. Consulte la documentación correspondiente.
La siguiente ilustración muestra la arquitectura de la implementación. Incluye las representaciones de los servidores que ejecutan el lenguaje R y Python. Ambos servidores se comunican con una subsección de nodos web que realizan el cálculo. Un almacén de datos de gran tamaño se conecta al bloque de cálculo.

Figura 5: ejemplo de implementación de ML Server
Los modelos que se crean en HDInsight o Databricks dependen del entorno de Spark (bibliotecas, funcionalidades paralelas, etc.). Puede considerar la posibilidad de ejecutarlos en un clúster. Puede ver una guía aquí. Esto tiene la ventaja de que el modelo operacional se puede invocar a sí mismo a través de una actividad de canalización de Data Factory para la puntuación.
Para utilizar contenedores, puede empaquetar los modelos e implementarlos en Azure Kubernetes Service. Los prototipos requieren el uso de Azure Data Science VM. También debe instalar las herramientas de línea de comandos de Azure Machine Learning en la máquina virtual.
Salida de datos e informes
Tras su implementación, el modelo puede procesar los flujos de trabajo de transacciones financieras y las lecturas de existencias para generar predicciones de surtido óptimas. Por tanto, los datos generados se pueden almacenar en Azure SQL Data Warehouse para su posterior análisis. En concreto, es posible estudiar el rendimiento histórico de las diferentes SKU mediante la identificación de los mayores generadores de ingresos y los creadores de pérdidas. Luego, se pueden comparar con los surtidos que sugieren los modelos y evaluar el rendimiento y la necesidad de volver a entrenar.
Power BI proporciona una manera de analizar y mostrar los datos generados en el proceso.
La siguiente figura muestra un panel de Power BI típico. Incluye dos gráficos que muestran información de existencias de SKU.
Consideraciones sobre la seguridad
Una solución que se ocupa de la información confidencial contiene registros financieros, niveles de existencias e información de precios. Esta información confidencial se debe proteger. Así puede mitigar sus preocupaciones sobre la seguridad y la privacidad de los datos:
- Puede ejecutar algunas de las canalizaciones de Azure Data Factory localmente mediante Azure Integration Runtime. El runtime ejecuta las actividades de movimiento de datos que se producen tanto hacia orígenes locales como desde estos. También envía actividades para su ejecución en el entorno local.
- Puede desarrollar una actividad personalizada para anonimizar los datos que se van a transferir a Azure y ejecutarlos de forma local.
- Todos los servicios mencionados admiten el cifrado en tránsito y en reposo. Si decide almacenar los datos mediante Azure Data Lake, el cifrado se habilita de forma predeterminada. Si usa Azure SQL Data Warehouse, puede habilitar el cifrado de datos transparente (TDE).
- Todos los servicios mencionados, con la excepción del estudio de ML, admiten la integración con Microsoft Entra ID para la autenticación y autorización. Si escribe su propio código, debe crear esa integración en la aplicación.
Para más información sobre el Reglamento general de protección de datos (RGPD), un reglamento de protección de datos y privacidad de la Unión Europea, consulte nuestra página de cumplimiento.
Componentes
Las siguientes tecnologías se presentaron en este artículo:
- Azure Batch
- Microsoft Entra ID
- Azure Data Factory
- HDInsight
- Databricks
- Máquinas virtuales de ciencia de datos
- Azure Kubernetes Service
- Microsoft Power BI
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Scott Seely | Arquitecto de software
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- ¿Qué es Azure Data Factory?
- Entorno de ejecución de integración en Azure Data Factory
- ¿Qué es un grupo de SQL dedicado (anteriormente SQL DW) en Azure Synapse Analytics?
- Microsoft Machine Learning Studio (clásico)
- ¿Qué es Machine Learning Server?
- Lenguaje de modelado de optimización Pyomo
- Bonmin Solver
- Solucionador de TFoCS para Spark
Recursos relacionados
Instrucciones relacionadas con la venta al por menor:
- Soluciones para el sector minorista
- Migración de una solución de comercio electrónico a Azure
- Búsqueda visual en el comercio minorista con Azure Cosmos DB
- Implementación de una solución de detección de afluencia de público basada en IA con Azure y Azure Stack Hub
Arquitecturas relacionadas: