Este patrón arquitectónico muestra cómo se puede incorporar MDM en el ecosistema de Azure Data Services para mejorar la calidad de los datos que se usan para el análisis y la toma de decisiones operativas. MDM resuelve varios desafíos habituales, entre los que se incluyen:
- Identificación y administración de datos duplicados (coincidencia y combinación).
- Marcar y resolver problemas de calidad de datos.
- Estandarización y enriquecimiento de datos
- Permitir a los administradores de datos administrar y mejorar los datos de forma proactiva.
Este patrón presenta un enfoque moderno para MDM. Todas las tecnologías se pueden implementar de forma nativa en Azure, incluido Profisee, que puede implementar a través de contenedores y administrar con Azure Kubernetes Service.
Architecture

Descargue un archivo de Visio de los diagramas usados en esta arquitectura.
Flujo de datos
El siguiente flujo de trabajo corresponde al diagrama anterior:
Carga de datos de origen: los datos de origen de las aplicaciones empresariales se copian en Azure Data Lake, y se almacenan para su transformación y uso adicionales en el análisis en el flujo descendente. Normalmente, los datos de origen se dividen en una de estas tres categorías:
- Datos maestros estructurados: información que describe clientes, productos, ubicaciones, etc. Los datos maestros son de bajo volumen, alta complejidad y cambios lentos a lo largo del tiempo. A menudo, son los datos con los que las organizaciones tienen más dificultades en términos de calidad.
- Datos transaccionales estructurados: eventos del negocio que se producen en un momento específico, como un pedido, una factura o una interacción. Las transacciones incluyen métricas de esa transacción (por ejemplo, el precio de venta) y referencias a los datos maestros (por ejemplo, el producto y el cliente implicados en una compra). Los datos transaccionales suelen ser de gran volumen, baja complejidad y no cambian a lo largo del tiempo.
- Datos no estructurados: pueden incluir documentos, imágenes, vídeos, contenido de redes sociales y audio, etc. Las plataformas de análisis modernas pueden usar cada vez más datos no estructurados para recopilar nuevas conclusiones. Los datos no estructurados suelen estar asociados a datos maestros, como el cliente asociado a una cuenta de redes sociales o el producto asociado a una imagen.
Carga de datos maestros de origen: Los datos maestros de las aplicaciones empresariales de origen se cargan en la aplicación MDM "tal cual", con información de linaje completa y transformaciones mínimas.
Procesamiento automatizado de MDM: la solución MDM usa procesos automatizados para estandarizar, comprobar y enriquecer datos, como los datos de dirección. La solución también identifica problemas de calidad de datos, agrupa registros duplicados (como clientes duplicados) y genera registros maestros, también denominados "registros dorados".
Administración de datos: Según sea necesario, los administradores de datos pueden:
- Revisar y administrar grupos de registros coincidentes
- Creación y administración de relaciones de datos
- Rellenar la información que falta
- Resolver problemas de calidad de datos.
Los administradores de datos pueden administrar varios resúmenes jerárquicos alternativos según sea necesario, como las jerarquías de productos.
Carga de datos maestros administrados: Los datos maestros de alta calidad fluyen hacia las soluciones de análisis en el flujo descendente. Esta acción simplifica el proceso porque las integraciones de datos ya no requieren transformaciones de calidad de datos.
Carga de datos transaccionales y no estructurados: los datos transaccionales y no estructurados se cargan en la solución de análisis en el flujo descendente, donde se combinan con datos maestros de alta calidad.
Visualización y análisis: Los datos se modelan y se ponen a disposición de los usuarios empresariales para su análisis. Los datos maestros de alta calidad eliminan los problemas habituales de calidad de los datos y se obtienen mejores conclusiones.
Componentes
Azure Data Factory es un servicio híbrido de integración de datos que le permite crear, programar y orquestar flujos de trabajo de ETL y ELT.
Azure Data Lake proporciona almacenamiento ilimitado para los datos de análisis.
Profisee es una plataforma MDM escalable diseñada para facilitar su integración con el ecosistema de Microsoft.
Azure Synapse Analytics es un almacenamiento de datos en la nube rápido, flexible y de confianza que le permite escalar, procesar y almacenar datos de forma elástica e independiente, con una arquitectura de procesamiento en paralelo masivo.
Power BI es un conjunto de herramientas de análisis empresarial que proporciona información detallada acerca de toda la organización. Conéctese a cientos de orígenes de datos, simplifique la preparación de los datos y realice análisis improvisados. Cree informes atractivos y publíquelos en la organización para que se usen en la web y en los dispositivos móviles.
Alternativas
En ausencia de una aplicación de MDM creada con tal propósito, algunas de las funcionalidades técnicas necesarias para crear una solución de MDM se pueden encontrar en el ecosistema de Azure.
- Calidad de los datos: Puede crear calidad de los datos en los procesos de integración al cargarlos en una plataforma de análisis. Por ejemplo, aplique transformaciones de calidad de los datos en una canalización de Azure Data Factory con scripts codificados de forma rígida.
- Normalización y enriquecimiento de datos: Azure Maps ayuda a proporcionar comprobación y estandarización de datos para los datos de dirección, que se pueden usar en Azure Functions o en Azure Data Factory. La normalización de otros datos puede requerir el desarrollo de scripts codificados de forma rígida.
- Administración de datos duplicados: puede usar Azure Data Factory para desduplicar filas cuando hay suficientes identificadores disponibles para una coincidencia exacta. En este caso, la lógica para combinar los coincidentes con la supervivencia adecuada probablemente requeriría scripts codificados de forma personalizada.
- Administración de datos: use Power Apps para desarrollar rápidamente soluciones sencillas de administración de datos para administrar datos en Azure, junto con las interfaces de usuario adecuadas para la revisión, el flujo de trabajo, las alertas y las validaciones.
Detalles del escenario
Muchos programas de transformación digital usan Azure como núcleo. Pero depende de la calidad y coherencia de los datos de varios orígenes, como aplicaciones empresariales, bases de datos, fuentes de distribución de datos, etc. También ofrece valor a través de inteligencia empresarial, análisis, aprendizaje automático, etc. La solución de administración de datos maestros (MDM) de Profisee completa el patrimonio de datos de Azure con un método práctico para "alinear y combinar" los datos de varios orígenes. Para ello, aplica estándares de datos coherentes en los datos de origen, como coincidencia, combinación, estandarización, comprobación y corrección. La integración nativa con Azure Data Factory y otros servicios de Azure Data Services simplifica aún más este proceso para acelerar la entrega de las ventajas empresariales de Azure.
Un aspecto fundamental de cómo funcionan las soluciones de MDM es que combinan datos de varios orígenes para crear un "maestro de registros dorados" que contiene los datos conocidos y de confianza para cada registro. Esta estructura crea dominio a dominio según los requisitos, pero casi siempre requiere varios dominios. Los dominios habituales son cliente, producto y ubicación. Pero los dominios pueden representar cualquier cosa, desde datos de referencia hasta contratos o nombres de fármacos. En general, cuanto mejor sea la cobertura de dominios que puede crear en relación con los amplios requisitos de datos de Azure, mejor.
Canalización de integración de MDM

Descargue un archivo Visio de esta arquitectura.
En la imagen anterior se muestran los detalles de la integración con la solución de MDM de Profisee. Tenga en cuenta que Azure Data Factory y Profisee incluyen compatibilidad nativa con la integración REST, lo que proporciona una integración moderna y ligera.
Carga de los datos de origen en MDM: Azure Data Factory extrae datos del lago de datos, los transforma para que coincidan con el modelo de datos maestros y los transmite al repositorio de MDM mediante un receptor REST.
Procesamiento de MDM: La plataforma de MDM procesa los datos maestros de origen mediante una secuencia de actividades para comprobar, normalizar y enriquecer los datos, así como para ejecutar procesos de calidad de datos. Por último, MDM realiza procesos de coincidencia y supervivencia para identificar y agrupar los registros duplicados y crear registros maestros. Opcionalmente, los administradores de datos pueden realizar tareas que dan lugar a un conjunto de datos maestros para usarlos en el análisis de flujo descendente.
Carga de datos maestros para su análisis: Azure Data Factory utiliza su origen REST para transmitir los datos maestros de Profisee a Azure Synapse Analytics.
Plantillas de Azure Data Factory para Profisee
En colaboración con Microsoft, Profisee ha desarrollado un conjunto de plantillas de Azure Data Factory que facilitan y agilizan la integración de Profisee en el ecosistema de Azure Data Services. Estas plantillas usan el origen de datos y el receptor de datos REST de Azure Data Factory para leer y escribir datos de la API de puerta de enlace REST de Profisee. Se proporcionan plantillas para leer y escribir en Profisee.
Ejemplo de plantilla de Data Factory: de JSON a Profisee sobre REST
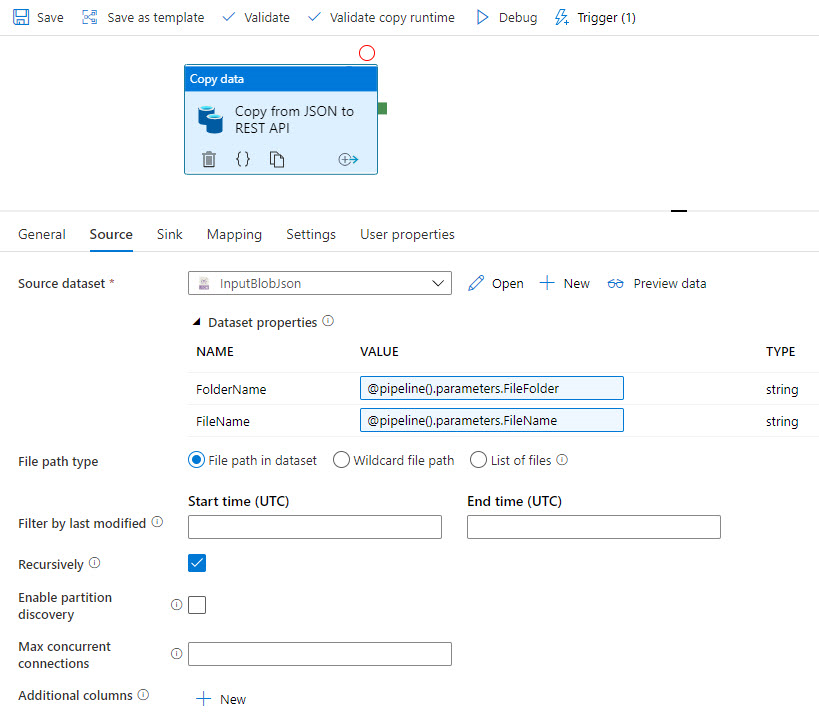
Las capturas de pantalla siguientes muestran una plantilla de Azure Data Factory que copia datos de un archivo JSON desde una instancia de Azure Data Lake a Profisee mediante REST.
La plantilla copia los datos JSON de origen:
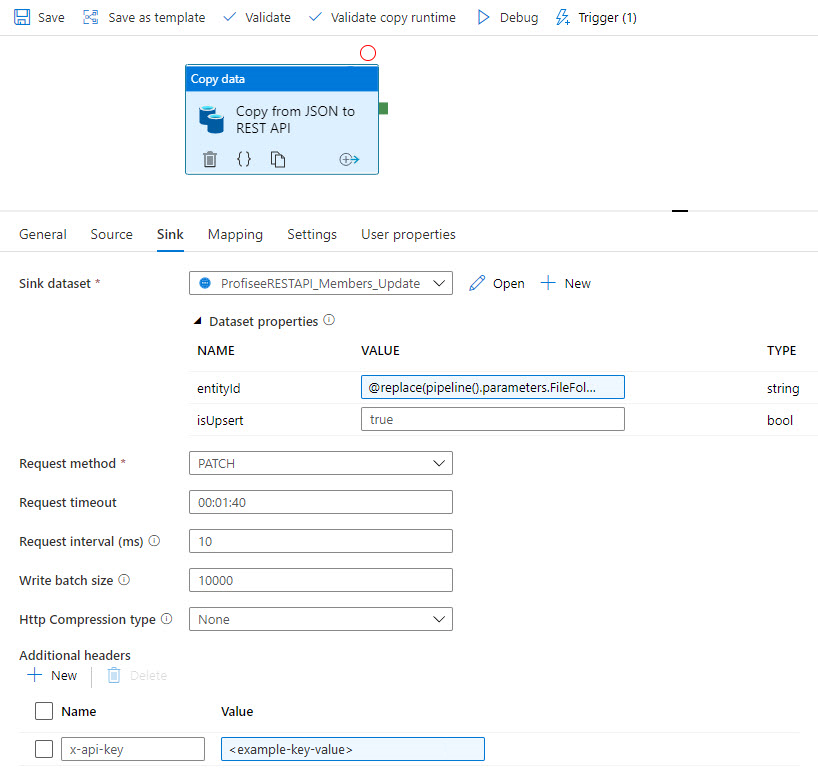
Después, los datos se sincronizan con Profisee mediante REST:
Para más información, consulte Plantillas de Azure Data Factory para Profisee.
Procesamiento de MDM
En un caso de uso analítico de MDM, los datos a menudo se procesan mediante la solución de MDM de forma automática para cargar datos para su análisis. En las secciones siguientes se muestra un proceso típico de datos de clientes en este contexto.
1. Carga de los datos de origen
Los datos de origen se cargan en la solución de MDM desde los sistemas de origen, incluida la información de linaje. En este caso, tenemos dos registros de origen, uno de la aplicación de CRM y otro de la aplicación de ERP. Tras la inspección visual, los dos registros parecen representar a la misma persona.
| Nombre de origen | Dirección de origen | Estado de origen | Teléfono de origen | Id. de origen | Dirección estándar | Estado estándar | Nombre estándar | Teléfono estándar | Similitud |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | |||||
| Bosch, Alana | 123 Main St. | Georgia | 404-854-7736 | CRM-121 | |||||
| Alana Bosch | (404) 854-7736 | ERP-988 |
2. Comprobación y normalización de los datos
Las reglas y servicios de comprobación y normalización ayudan a normalizar y comprobar la información de dirección, nombre y número de teléfono.
| Nombre de origen | Dirección de origen | Estado de origen | Teléfono de origen | Id. de origen | Dirección estándar | Estado estándar | Nombre estándar | Teléfono estándar | Similitud |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | 123 Main St. | GA | Alana Bosh | 770 843 4125 | |
| Bosch, Alana | 123 Main St. | Georgia | 404-854-7736 | CRM-121 | 123 Main St. | GA | Alana Bosch | 404 854 7736 | |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 |
3. Coincidencia
Se realiza la búsqueda de coincidencias con los datos normalizados, lo que identifica la similitud entre los registros del grupo. En este escenario, dos registros coinciden entre sí exactamente en el nombre y el teléfono, y las demás coincidencias aproximadas en el nombre y la dirección.
| Nombre de origen | Dirección de origen | Estado de origen | Teléfono de origen | Id. de origen | Dirección estándar | Estado estándar | Nombre estándar | Teléfono estándar | Similitud |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | 123 Main St. | GA | Alana Bosh | 770 843 4125 | 0.9 |
| Bosch, Alana | 123 Main St. | Georgia | 404-854-7736 | CRM-121 | 123 Main St. | GA | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 |
4. Supervivencia
Con un grupo formado, el proceso de supervivencia crea y rellena un registro maestro (también llamado "registro dorado") para representar al grupo.
| Nombre de origen | Dirección de origen | Estado de origen | Teléfono de origen | Id. de origen | Dirección estándar | Estado estándar | Nombre estándar | Teléfono estándar | Similitud |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | 123 Main St. | GA | Alana Bosh | 770 843 4125 | 0.9 |
| Bosch, Alana | 123 Main St. | Georgia | 404-854-7736 | CRM-121 | 123 Main St. | GA | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 | ||||
| Registro maestro: | 123 Main St. | GA | Alana Bosch | 404 854 7736 |
Este registro maestro, junto con los datos de origen mejorados y la información de linaje, se cargan en la solución de análisis en el flujo descendente, donde se puede enlazar a los datos transaccionales.
En este ejemplo se muestra el procesamiento de MDM automatizado básico. Las reglas de calidad de los datos también se pueden usar para calcular o actualizar automáticamente los valores, así como para marcar los valores que faltan o no son válidos para que los administradores de datos los resuelvan. Los administradores de datos ayudan a administrar los datos, incluida la administración de resúmenes jerárquicos de los datos.
Impacto de MDM en la complejidad de la integración
Como se muestra anteriormente, MDM aborda varios desafíos habituales que se encuentran al integrar los datos en una solución de análisis. Incluye la corrección de los problemas de calidad de datos, la normalización y el enriquecimiento de los datos y la racionalización de los datos duplicados. La incorporación de MDM en la arquitectura de análisis fundamentalmente cambia el flujo de datos, ya que elimina la lógica codificada de forma rígida del proceso de integración y la descarga en la solución de MDM, lo que simplifica considerablemente las integraciones. En la tabla siguiente se describen algunas diferencias habituales en el proceso de integración con y sin MDM.
| Capacidad | Sin MDM | Con MDM |
|---|---|---|
| Calidad de los datos | Los procesos de integración incluyen reglas y transformaciones de calidad para ayudar a corregir los datos a medida que se mueven. Requiere recursos técnicos para la implementación inicial y el mantenimiento continuo de estas reglas, lo que dificulta el desarrollo y el mantenimiento de los procesos de integración de datos. | La solución MDM configura y aplica reglas y lógicas de calidad de datos. Los procesos de integración no realizan transformaciones de calidad de datos, sino que mueven los datos "tal cual" a la solución de MDM. Los procesos de integración de datos son sencillos y asequibles en su desarrollo y mantenimiento. |
| Normalización y enriquecimiento de los datos | Los procesos de integración incluyen lógica para normalizar y alinear los datos maestros y los de referencia. Desarrolle integraciones con servicios de terceros para realizar la normalización de los datos de la dirección, el nombre, el correo electrónico y el teléfono. | Mediante el uso de reglas integradas e integraciones predefinidas con servicios de datos de terceros, los datos se pueden estandarizar dentro de la solución MDM, lo que simplifica la integración. |
| Administración de datos duplicados | El proceso de integración identifica y agrupa los registros duplicados que existen dentro de las aplicaciones y entre ellas en función de los identificadores únicos existentes. Este proceso comparte identificadores entre sistemas (por ejemplo, SSN o correo electrónico) y solo coincide y los agrupa cuando son idénticos. Los enfoques más sofisticados requieren grandes inversiones en ingeniería de integración. | Las funcionalidades de coincidencia con aprendizaje automático integradas identifican los registros duplicados dentro de los sistemas y entre ellos, lo que genera un registro dorado para representar al grupo. Este proceso permite que los registros tengan "coincidencia aproximada", con agrupación de los registros que son similares, con resultados que se pueden explicar. Administra grupos en aquellos escenarios en los que el motor de ML no puede formar un grupo con una confianza alta. |
| Administración de datos | Las actividades de administración de datos solo actualizan los datos de las aplicaciones de origen, como ERP o CRM. Normalmente, detectan problemas, como datos que faltan, están incompletos o son incorrectos, al realizar el análisis. Corrigen los problemas en la aplicación de origen y, a continuación, los actualizan en la solución de análisis durante la siguiente actualización. Cualquier nueva información que se vaya a administrar se agrega a las aplicaciones de origen, lo que puede llevar tiempo y ser costoso. | Las soluciones de MDM tienen funcionalidades de administración de datos integradas, lo que permite a los usuarios acceder a los datos y administrarlos. Idealmente, el sistema marca los problemas y pide a los administradores de datos que los corrijan. Configure rápidamente nueva información o jerarquías en la solución para que los administradores de datos los administren. |
Casos de uso de MDM
Aunque hay varios casos de uso para MDM, hay un pequeño número de casos de uso que cubren la mayoría de las implementaciones de MDM reales. Aunque estos casos de uso se centran en un solo dominio, no es probable que se creen solo a partir de ese dominio. En otras palabras, incluso la mayoría de estos casos de uso centrados incluyen varios dominios de datos maestros.
Customer 360
La consolidación de los datos de los clientes para su análisis es el caso de uso más común de MDM. Las organizaciones capturan los datos de los clientes desde un creciente número de aplicaciones, con lo que se crean datos de clientes duplicados dentro de las aplicaciones y entre ellas con incoherencias y discrepancias. Estos datos de cliente de mala calidad hacen que sea difícil aprovechar el valor de las soluciones de análisis moderno. Los síntomas incluyen:
- Es difícil responder a preguntas empresariales básicas como "quiénes son nuestros principales clientes" y "cuántos clientes nuevos hemos tenido", lo que requiere un esfuerzo manual significativo.
- Información del cliente que falta o no es precisa, lo que dificulta la acumulación o la obtención de detalles de los datos.
- Imposibilidad de analizar los datos de los clientes entre sistemas o unidades de negocio debido a la incapacidad de identificar de forma única a un cliente en los límites de la organización y del sistema.
- Conclusiones de baja calidad de la inteligencia artificial y el aprendizaje automático debido a datos de entrada de mala calidad.
Productos 360
A menudo, los datos de los productos se distribuyen entre varias aplicaciones empresariales, por ejemplo, ERP, PLM o comercio electrónico. El resultado es el desafío de conocer el catálogo total de productos que tienen definiciones incoherentes para propiedades como el nombre, la descripción y las características del producto. Además, las distintas definiciones de datos de referencia complican aún más esta situación. Los síntomas incluyen:
- Incapacidad de ofrecer diferentes rutas de acumulación y obtención de detalles con jerarquías alternativas para el análisis de los productos.
- En casos de productos terminados o inventario de materiales, existen dificultades para conocer exactamente qué productos tiene disponibles, los proveedores a los que se compran los productos y los productos duplicados, lo que provoca un exceso de inventario.
- Existen dificultades al racionalizar los productos debido a definiciones conflictivas, lo que conduce a la falta de información o a información inexacta en el análisis.
Datos de referencia 360
En el contexto del análisis, los datos de referencia existen como varias listas de datos que ayudan a describir otros conjuntos de datos maestros. Los datos de referencia incluyen listas de países o regiones, monedas, colores, tamaños y unidades de medida. Los datos de referencia incoherentes conducen a errores obvios en el análisis en el flujo descendente. Los síntomas incluyen:
- Varias representaciones de la mismo cosa. Por ejemplo, el estado de Georgia aparece como "GA" y "Georgia", por lo que resulta difícil agregar y profundizar en los datos de forma coherente.
- Dificultad en la agregación de datos entre aplicaciones debido a la imposibilidad de cotejar los valores de los datos de referencia entre sistemas. Por ejemplo, el color rojo se representa con "R" en el sistema de ERP y "Rojo" en el sistema de PLM.
- Dificultad en la coincidencia de cifras entre organizaciones debido a las diferencias en los valores de los datos de referencia acordados para clasificar los datos.
Finanzas 360
Las organizaciones financieras dependen en gran medida de los datos de actividades críticas como los informes mensuales, trimestrales y anuales. Las organizaciones con varios sistemas de finanzas y contabilidad suelen tener los datos financieros en varios libros generales, que consolidan para generar informes financieros. MDM puede proporcionar un lugar centralizado para asignar y administrar cuentas, centros de costos, entidades comerciales y otros conjuntos de datos financieros en una vista consolidada. Los síntomas incluyen:
- Dificultad para agregar los datos financieros entre varios sistemas en una vista consolidada.
- Falta de procesos para agregar y asignar nuevos elementos de datos en los sistemas financieros.
- Retrasos en la producción de los informes financieros de final de período.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Confiabilidad
La confiabilidad garantiza que la aplicación pueda cumplir los compromisos contraídos con los clientes. Para más información, consulte Resumen del pilar de fiabilidad.
Profisee se ejecuta de forma nativa en Azure Kubernetes Service y Azure SQL Database. Ambos servicios ofrecen funcionalidades listas para admitir la alta disponibilidad.
Eficiencia del rendimiento
La eficiencia del rendimiento es la capacidad de la carga de trabajo para escalar con el fin de satisfacer de manera eficiente las demandas que los usuarios hayan ejercido sobre ella. Para obtener más información, vea Resumen del pilar de eficiencia del rendimiento.
Profisee se ejecuta de forma nativa en Azure Kubernetes Service y Azure SQL Database. Se puede configurar Azure Kubernetes Service para escalar Profisee vertical y horizontalmente, en función de las necesidades. Puede implementar Azure SQL Database en muchas configuraciones diferentes para equilibrar el rendimiento, la escalabilidad y los costos.
Seguridad
La seguridad proporciona garantías contra ataques deliberados y el abuso de datos y sistemas valiosos. Para más información, consulte Introducción al pilar de seguridad.
Profisee autentica a los usuarios mediante OpenID Connect, que implementa un flujo de autenticación de OAuth 2.0. La mayoría de organizaciones configuran Profisee para autenticar a los usuarios en Microsoft Entra ID. Este proceso garantiza que las directivas empresariales para la autenticación se apliquen.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Los costos de ejecución constan de una licencia de software y del consumo de Azure. Para obtener más información, póngase en contacto con Profisee.
Implementación de este escenario
Para implementar este escenario:
- Implemente Profisee en Azure con una plantilla de ARM.
- Cree una instancia de Azure Data Factory.
- Configure la instancia de Azure Data Factory para conectarse a un repositorio de Git.
- Agregue las plantillas de Azure Data Factory de Profisee al repositorio de Git de Azure Data Factory.
- Cree una nueva canalización de Azure Data Factory mediante una plantilla.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Sunil Sabat | Administrador de programas principal
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- Conozca las funcionalidades del conector de copia REST en Azure Data Factory.
- Más información sobre la ejecución de Profisee de forma nativa en Azure.
- Obtenga información sobre cómo implementar Profisee en Azure con una plantilla de ARM.
- Consulte las plantillas de Azure Data Factory para Profisee.
Recursos relacionados
Guías de arquitectura
- Extracción, transformación y carga (ETL)
- Entorno de ejecución de integración en Azure Data Factory
- Elección de una tecnología de orquestación de canalizaciones de datos en Azure