Guía de Azure Functions para desarrolladores de Python
Esta guía es una introducción al desarrollo de Azure Functions mediante Python. En este artículo se supone que ya ha leído la guía para desarrolladores de Azure Functions.
Importante
En este artículo se admite el modelo de programación v1 y v2 para Python en Azure Functions. Aunque el modelo Python v1 usa un archivo functions.json para definir funciones, el nuevo modelo v2 le permite usar en su lugar un enfoque basado en decorador. Este nuevo enfoque da como resultado una estructura de archivos más sencilla y está más centrado en el código. Elija el selector v2 en la parte superior del artículo para obtener información sobre este nuevo modelo de programación.
Como desarrollador de Python, puede que también le interese uno de los siguientes artículos:
| Introducción | Conceptos | Escenarios y ejemplos |
|---|---|---|
| Introducción | Conceptos | Ejemplos |
|---|---|---|
Opciones de desarrollo
Ambos modelos de programación de Functions en Python admiten el desarrollo local en uno de los siguientes entornos:
Modelo de programación de Python v2:
Tenga en cuenta que el modelo de programación de Python v2 solo se admite en el entorno de ejecución de funciones 4.x. Para más información, consulte Selección de un destino para versiones de runtime de Azure Functions.
Modelo de programación de Python v1:
También puede crear funciones de Python v1 en Azure Portal.
Sugerencia
Aunque puede desarrollar su instancia de Azure Functions basada en Python localmente en Windows, Python solo se admite en un plan de hospedaje basado en Linux cuando se ejecuta en Azure. Para obtener más información, consulte la lista de combinaciones admitidas de sistema operativo y tiempo de ejecución.
Modelo de programación
Azure Functions espera que una función sea un método sin estado de un script de Python que procese entradas y genere salidas. De manera predeterminada, el runtime espera que el modelo se implemente como un método global denominado main() en el archivo __init__.py. También puede especificar un punto de entrada alternativo.
Se enlazan los datos a la función desde los desencadenadores y enlaces a través de los atributos del método que usan la propiedad name definida en el archivo function.json. Por ejemplo, en el archivo function.json siguiente se describe una función simple desencadenada mediante una solicitud HTTP denominada req:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Según esta definición, el archivo __init__.py que contiene el código de la función puede ser similar al siguiente ejemplo:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
También puede declarar de forma explícita los tipos de parámetros y el tipo de valor devuelto de la función mediante las anotaciones de tipos de Python. Esta acción le ayuda a usar las características IntelliSense y Autocompletar proporcionadas por muchos editores de código de Python.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Utilice las anotaciones de Python incluidas en el paquete azure.functions.* para enlazar las entradas y las salidas a los métodos.
Azure Functions espera que una función sea un método sin estado de un script de Python que procese entradas y genere salidas. De forma predeterminada, el runtime espera que el método se implemente como un método global en el archivo function_app.py.
Los desencadenadores y enlaces se pueden declarar y usar en una función en un enfoque basado en decorador. Se definen en el mismo archivo, function_app.py, que las funciones. Por ejemplo, el siguiente archivo function_app.py representa un desencadenador de función mediante una solicitud HTTP.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
También puede declarar de forma explícita los tipos de parámetros y el tipo de valor devuelto de la función mediante las anotaciones de tipos de Python. Esto le ayuda a usar las características de IntelliSense y Autocompletar proporcionadas por muchos editores de código de Python.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
Para obtener información sobre las limitaciones conocidas con el modelo v2 y sus soluciones alternativas, consulte Solución de problemas de errores de Python en Azure Functions.
Punto de entrada alternativo
Puede cambiar el comportamiento predeterminado de una función si especifica opcionalmente las propiedades scriptFile y entryPoint en el archivo function.json. Por ejemplo, el function.json siguiente indica al runtime que use el método customentry() del archivo main.py, como punto de entrada para la función de Azure.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
El punto de entrada solo está en el archivo function_app.py. Sin embargo, se puede hacer referencia a las funciones del proyecto en ffunction_app.py mediante planos técnicos o mediante la importación.
Estructura de carpetas
La estructura de carpetas recomendada para un proyecto de funciones de Python tiene este aspecto:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
La carpeta de proyecto principal, <project_root>, puede contener los siguientes archivos:
- local.settings.json: se usa para almacenar la configuración y las cadenas de conexión de la aplicación cuando se ejecuta localmente. Este archivo no se publica en Azure. Para más información, consulte local.settings.file.
- requirements.txt: contiene la lista de paquetes de Python que se instalan al publicar en Azure.
- host.json: contiene las opciones de configuración global que afectan a todas las funciones de una instancia de aplicación de funciones. Este archivo se publica en Azure. No todas las opciones se admiten cuando se ejecuta localmente. Para más información, consulte host.json.
- .vscode/: (Opcional) Contiene la configuración almacenada de Visual Studio Code. Para más información, consulte Configuración de Visual Studio Code.
- .venv/ : (Opcional) Contiene un entorno virtual de Python usado para el desarrollo local.
- Dockerfile: (Opcional) se usa al publicar el proyecto en un contenedor personalizado.
- tests/ : (Opcional) Contiene los casos de prueba de la aplicación de funciones.
- .funcignore: (Opcional) declara los archivos que no deben publicarse en Azure. Normalmente, este archivo contiene .vscode/ para omitir la configuración del editor, .venv/ para omitir el entorno virtual de Python local, tests/ para omitir los casos de prueba y local.settings.json para evitar la publicación de la configuración de la aplicación local.
Cada función tiene su propio archivo de código y archivo de configuración de enlace (function.json).
La estructura de carpetas recomendada para un proyecto de funciones de Python tiene este aspecto:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
La carpeta de proyecto principal, <project_root>, puede contener los siguientes archivos:
- .venv/: (opcional) contiene un entorno virtual de Python que usa el desarrollo local.
- .vscode/: (Opcional) Contiene la configuración almacenada de Visual Studio Code. Para más información, consulte Configuración de Visual Studio Code.
- function_app.py: la ubicación predeterminada para todas las funciones y sus desencadenadores y enlaces relacionados.
- additional_functions.py: (opcional) cualquier otro archivo de Python que contenga funciones (normalmente para la agrupación lógica) a los que se hace referencia a function_app.py a través de planos técnicos.
- tests/ : (Opcional) Contiene los casos de prueba de la aplicación de funciones.
- .funcignore: (Opcional) declara los archivos que no deben publicarse en Azure. Normalmente, este archivo contiene .vscode/ para omitir la configuración del editor, .venv/ para omitir el entorno virtual de Python local, tests/ para omitir los casos de prueba y local.settings.json para evitar la publicación de la configuración de la aplicación local.
- host.json: contiene las opciones de configuración global que afectan a todas las funciones de una instancia de aplicación de funciones. Este archivo se publica en Azure. No todas las opciones se admiten cuando se ejecuta localmente. Para más información, consulte host.json.
- local.settings.json: se usa para almacenar las cadenas de conexión y la configuración de la aplicación cuando la ejecución se realiza a nivel local. Este archivo no se publica en Azure. Para más información, consulte local.settings.file.
- requirements.txt: contiene la lista de paquetes de Python que se instalan al publicar en Azure.
- Dockerfile: (Opcional) se usa al publicar el proyecto en un contenedor personalizado.
Al implementar el proyecto en una aplicación de funciones de Azure, debe incluirse en el paquete todo el contenido de la carpeta principal del proyecto (<project_root>), pero no la propia carpeta, lo que significa que host.json debe estar en la raíz del paquete. Se recomienda mantener las pruebas en una carpeta junto con otras funciones (en este ejemplo, tests/). Para más información, consulte Prueba unitaria.
Conectar con una base de datos
Azure Functions se integra correctamente con Azure Cosmos DB para muchos casos de uso, como IoT, comercio electrónico, juegos, etc.
Por ejemplo, para el aprovisionamiento de eventos, los dos servicios se integran en arquitecturas controladas por eventos mediante la funcionalidad de fuente de cambios de Azure Cosmos DB. La fuente de cambios proporciona a los microservicios de nivel inferior la capacidad de leer de forma confiable e incremental las inserciones y actualizaciones (por ejemplo, los eventos desordenados). Esta funcionalidad se puede aprovechar para proporcionar un almacén de eventos persistente como un agente de mensajes para los eventos de cambio de estado y dirigir el orden del flujo de trabajo de procesamiento entre muchos microservicios (lo que se puede implementar como funciones de Azure sin servidor).
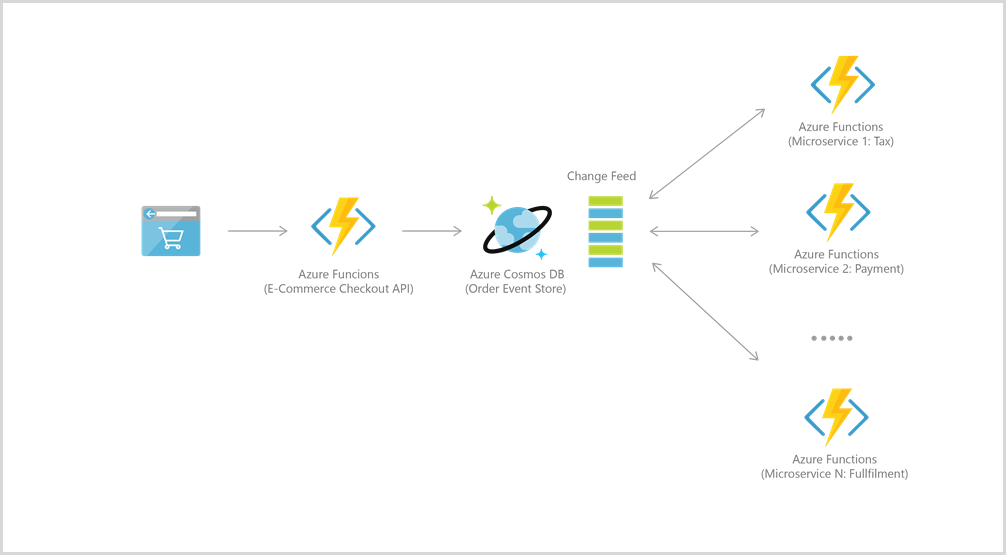
Para conectarse a Cosmos DB, primero cree una cuenta, una base de datos y un contenedor. A continuación, puede conectar Functions a Cosmos DB mediante desencadenadores y enlaces, como en este ejemplo.
Para implementar lógica de aplicaciones más complejas, también puede usar la biblioteca de Python para Cosmos DB. Una implementación de E/S asíncrona tiene este aspecto:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Blueprints
El modelo de programación Python v2 presenta el concepto de planos técnicos. Un plano técnico es una nueva clase en la que se crean instancias para registrar funciones fuera de la aplicación de función principal. Las funciones registradas en instancias de plano técnico no se indexan directamente mediante el tiempo de ejecución de la función. Para indexar estas funciones de plano técnico, la aplicación de funciones debe registrar las funciones de las instancias del plano técnico.
Usar planos técnicos brinda las ventajas siguientes:
- Permite dividir la aplicación de funciones en componentes modulares, lo que le permite definir funciones en varios archivos de Python y dividirlas en distintos componentes por archivo.
- Proporciona interfaces de aplicación de funciones públicas extensibles para compilar y reutilizar sus propias API.
El siguiente ejemplo muestra cómo usar los planos:
En primer lugar, en un archivo http_blueprint.py se define la función activada por HTTP y se agrega a un objeto de plano técnico.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
A continuación, en el archivo function_app.py, se importa el objeto de plano técnico y sus funciones se registran en la aplicación de funciones.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Nota
Durable Functions también admite planos técnicos. Para crear planos técnicos para aplicaciones Durable Functions, registre los desencadenadores de orquestación, actividad y entidad y los enlaces de cliente mediante la clase azure-functions-durableBlueprint, como se muestra aquí. A continuación, el plano técnico resultante se puede registrar como normal. Consulte nuestra muestra para obtener un ejemplo.
Comportamiento de la importación
Puede importar módulos en el código de la función mediante referencias absolutas y relativas. En el caso de la estructura de carpetas descrita anteriormente, las siguientes operaciones de importación trabajan desde el archivo de función <project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Nota
La carpeta shared_code/ debe contener un archivo __init__.py para marcarlo como un paquete de Python al usar la sintaxis de la importación absoluta.
La siguiente importación de __app__ y las importaciones relativas de nivel superior están en desuso, ya que no son compatibles con el comprobador de tipos estático y no son compatibles con los marcos de pruebas de Python:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Desencadenadores y entradas
Las entradas se dividen en dos categorías dentro de Azure Functions: entradas del desencadenador y otras entradas. Aunque son diferentes en el archivo function.json, se usan igual en el código de Python. Las cadenas de conexión o los secretos de los orígenes de entrada y el desencadenador se asignan a valores en el archivo ocal.settings.json al ejecutarse localmente y se asignan a la configuración de la aplicación al ejecutarse en Azure.
Por ejemplo, el siguiente código muestra la diferencia entre las dos entradas:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Cuando se invoca la función, la solicitud HTTP se pasa a la función como req. Se recuperará una entrada de la cuenta de Azure Blob Storage según el identificador de la dirección URL de la ruta y estará disponible como obj en el cuerpo de la función. En este caso, la cuenta de almacenamiento especificada es la cadena de conexión que se encuentra en el valor de aplicación CONNECTION_STRING.
Las entradas se dividen en dos categorías dentro de Azure Functions: entradas del desencadenador y otras entradas. Aunque se definen mediante diferentes decoradores, el uso es similar en el código de Python. Las cadenas de conexión o los secretos de los orígenes de entrada y el desencadenador se asignan a valores en el archivo ocal.settings.json al ejecutarse localmente y se asignan a la configuración de la aplicación al ejecutarse en Azure.
Por ejemplo, el código siguiente muestra cómo definir un enlace de entrada de Blob Storage:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>",
"AzureWebJobsFeatureFlags": "EnableWorkerIndexing"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.read_blob(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Cuando se invoca la función, la solicitud HTTP se pasa a la función como req. Se recuperará una entrada de la cuenta de Azure Blob Storage según el identificador de la dirección URL de la ruta y estará disponible como obj en el cuerpo de la función. En este caso, la cuenta de almacenamiento especificada es la cadena de conexión que se encuentra en el valor de aplicación STORAGE_CONNECTION_STRING.
En el caso de las operaciones de enlace con un uso intensivo de datos, es posible que le interese usar una cuenta de almacenamiento independiente. Para obtener más información, consulte Guía de la cuenta de almacenamiento.
Salidas
Las salidas se pueden expresar como valores devueltos y como parámetros de salida. Si hay una única salida, se recomienda usar el valor devuelto. Para varias salidas, deberá utilizar parámetros de salida.
Para usar el valor devuelto de una función como valor de un enlace de salida, la propiedad name del enlace debe establecerse como $return en el archivo function.json.
Si desea generar varias salidas, utilice el método set() que la interfaz azure.functions.Out ofrece para asignar un valor al enlace. Por ejemplo, la siguiente función puede insertar un mensaje en una cola y también devolver una respuesta HTTP.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Las salidas se pueden expresar como valores devueltos y como parámetros de salida. Si hay una única salida, se recomienda usar el valor devuelto. Para varias salidas, deberá utilizar parámetros de salida.
Si desea generar varias salidas, utilice el método set() que la interfaz azure.functions.Out ofrece para asignar un valor al enlace. Por ejemplo, la siguiente función puede insertar un mensaje en una cola y también devolver una respuesta HTTP.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Registro
El acceso al registrador del entorno de ejecución de Azure Functions está disponible a través de un controlador logging raíz en la aplicación de función. Este registrador está asociado a Application Insights y permite marcar las advertencias y los errores que se produjeron durante la ejecución de la función.
En el ejemplo siguiente se registra un mensaje de información cuando la función se invoca con un desencadenador HTTP.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
Hay más métodos de registro disponibles que permiten escribir en la consola en otros niveles de seguimiento:
| Método | Descripción |
|---|---|
critical(_message_) |
Escribe un mensaje con el nivel CRÍTICO en el registrador de raíz. |
error(_message_) |
Escribe un mensaje con el nivel ERROR en el registrador de raíz. |
warning(_message_) |
Escribe un mensaje con el nivel ADVERTENCIA en el registrador de raíz. |
info(_message_) |
Escribe un mensaje con el nivel INFO en el registrador de raíz. |
debug(_message_) |
Escribe un mensaje con el nivel DEBUG en el registrador de raíz. |
Para más información sobre el registro, consulte Supervisión de Azure Functions.
Registro a partir de subprocesos creados
Para ver los registros procedentes de los subprocesos creados, incluya el argumento context en la signatura de función. Este argumento contiene un atributo thread_local_storage que almacena un objeto local invocation_id. Esto se puede establecer en el actual invocation_id de la función para asegurarse que se cambia el contexto.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Registro de la telemetría personalizada
De forma predeterminada, el entorno de ejecución de Functions recopila registros y otros datos de telemetría generados por las funciones. Esta telemetría termina con seguimientos en Application Insights. La telemetría de solicitudes y dependencias para determinados servicios de Azure también se recopila de forma predeterminada por medio de desencadenadores y enlaces.
Para recopilar datos de telemetría personalizados de dependencias y solicitudes sin enlaces, puede usar las extensiones de Python de OpenCensus. Esta extensión envía datos de telemetría personalizados a la instancia de Application Insights. Puede encontrar una lista de extensiones admitidas en el repositorio de OpenCensus.
Nota
Para usar las extensiones de Python para OpenCensus, debe habilitar las extensiones de trabajo de Python en la aplicación de funciones si establece PYTHON_ENABLE_WORKER_EXTENSIONS en 1. También debe cambiar al uso de la cadena de conexión de Application Insights agregando el ajuste APPLICATIONINSIGHTS_CONNECTION_STRING a la configuración de la aplicación, si aún no está ahí.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
Desencadenador HTTP
El desencadenador HTTP se define en el archivo function.json. El valor de name del enlace debe coincidir con el parámetro con nombre de la función.
En los ejemplos anteriores, se usa un nombre de enlace req. Este parámetro es un objeto HttpRequest y se devuelve un objeto HttpResponse.
Desde el objeto HttpRequest, puede obtener encabezados de solicitud, parámetros de consulta, parámetros de ruta y el cuerpo del mensaje.
El ejemplo siguiente es de la plantilla de desencadenador HTTP para Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
En esta función, obtiene el valor del parámetro de consulta name del parámetro params del objeto HttpRequest. El cuerpo del mensaje con codificación JSON se lee mediante el método get_json.
Del mismo modo, puede establecer status_code y headers para el mensaje de respuesta en el objeto HttpResponse devuelto.
El desencadenador HTTP se define como un método que toma un parámetro de enlace con nombre, que es un objeto HttpRequest y devuelve un objeto HttpResponse. El decorador function_name se aplica al método para definir el nombre de la función, mientras que el punto de conexión HTTP se establece aplicando el decorador route.
Este ejemplo procede de la plantilla de desencadenador HTTP para el modelo de programación de Python v2, donde el nombre del parámetro de enlace es req. Es el código de ejemplo que se proporciona al crear una función mediante Azure Functions Core Tools o Visual Studio Code.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
Desde el objeto HttpRequest, puede obtener encabezados de solicitud, parámetros de consulta, parámetros de ruta y el cuerpo del mensaje. En esta función, obtiene el valor del parámetro de consulta name del parámetro params del objeto HttpRequest. El cuerpo del mensaje con codificación JSON se lee mediante el método get_json.
Del mismo modo, puede establecer status_code y headers para el mensaje de respuesta en el objeto HttpResponse devuelto.
Para pasar un nombre en este ejemplo, pegue la dirección URL proporcionada al ejecutar la función y anexe con "?name={name}".
Marcos web
Puede usar marcos compatibles con la Interfaz de puerta de enlace de servidor web (WSGI) y asincrónica (ASGI), como Flask y FastAPI, con las funciones de Python desencadenadas por HTTP. En esta sección se muestra cómo modificar las funciones para admitir estos marcos.
En primer lugar, el archivo function.json debe actualizarse para incluir un route en el desencadenador HTTP, como se muestra en el ejemplo siguiente:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
El archivo host.json también debe actualizarse para incluir un routePrefix HTTP, como se muestra en el ejemplo siguiente:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[3.*, 4.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Actualice el archivo de código de Python init.py, en función de la interfaz usada por el marco. En el ejemplo siguiente se muestra un enfoque de controlador ASGI o un enfoque de contenedor WSGI para Flask:
Puede usar marcos compatibles con la Interfaz de puerta de enlace de servidor asincrónica (ASGI) y web (WSGI), como Flask y FastAPI, con las funciones de Python desencadenadas por HTTP. Primero debe actualizar el archivo host.json para incluir un routePrefix HTTP, como se muestra en el ejemplo siguiente:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[2.*, 3.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
El código de marco es similar al ejemplo siguiente:
AsgiFunctionApp es la clase de aplicación de funciones de nivel superior para construir funciones HTTP de ASGI.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Escalado y rendimiento
Para los procedimientos recomendados de escalado y rendimiento para las aplicaciones de funciones de Python, consulte el artículo sobre el escalado y el rendimiento de Python.
Context
Para obtener el contexto de invocación de una función durante la ejecución, incluya el argumento context en su firma.
Por ejemplo:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
La clase Context tiene los atributos de cadena siguientes:
| Atributo | Descripción |
|---|---|
function_directory |
El directorio en que se ejecuta la función. |
function_name |
El nombre de la función. |
invocation_id |
El identificador de la invocación de la función actual. |
thread_local_storage |
Almacenamiento local para el subproceso de la función. Contiene un elemento local invocation_id para el registro a partir de los subprocesos creados. |
trace_context |
Contexto para el seguimiento distribuido. Para obtener más información, vea Trace Context. |
retry_context |
El contexto para los reintentos de la función. Para obtener más información, vea retry-policies. |
Variables globales
No se garantiza la conservación del estado de la aplicación para las ejecuciones futuras. Sin embargo, Azure Functions Runtime suele reutilizar el mismo proceso para varias ejecuciones de la misma aplicación. Para almacenar en caché los resultados de un cálculo costoso, debe declararse como variable global.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Variables de entorno
En Azure Functions, la configuración de la aplicación, como las cadenas de conexión del servicio, se exponen como variables de entorno durante la ejecución. Hay dos maneras principales de acceder a esta configuración en el código.
| Método | Descripción |
|---|---|
os.environ["myAppSetting"] |
Intenta obtener la configuración de la aplicación por nombre de clave. Genera un error cuando el proceso no se completa correctamente. |
os.getenv("myAppSetting") |
Intenta obtener la configuración de la aplicación por nombre de clave. Devuelve null cuando el proceso no se completa correctamente. |
Ambos métodos requieren que declare import os.
En el ejemplo siguiente se usa os.environ["myAppSetting"] para obtener la configuración de la aplicación, con la clave denominada myAppSetting:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Para el desarrollo local, la configuración de la aplicación se mantiene en el archivo local.settings.json.
En Azure Functions, la configuración de la aplicación, como las cadenas de conexión del servicio, se exponen como variables de entorno durante la ejecución. Hay dos maneras principales de acceder a esta configuración en el código.
| Método | Descripción |
|---|---|
os.environ["myAppSetting"] |
Intenta obtener la configuración de la aplicación por nombre de clave. Genera un error cuando el proceso no se completa correctamente. |
os.getenv("myAppSetting") |
Intenta obtener la configuración de la aplicación por nombre de clave. Devuelve null cuando el proceso no se completa correctamente. |
Ambos métodos requieren que declare import os.
En el ejemplo siguiente se usa os.environ["myAppSetting"] para obtener la configuración de la aplicación, con la clave denominada myAppSetting:
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Para el desarrollo local, la configuración de la aplicación se mantiene en el archivo local.settings.json.
Cuando use el nuevo modelo de programación, habilite la siguiente configuración de aplicación en el archivo local.settings.json, como se muestra aquí:
"AzureWebJobsFeatureFlags": "EnableWorkerIndexing"
Al implementar la función, esta configuración no se crea automáticamente. Debe crear explícitamente esta configuración en la aplicación de funciones de Azure para que se ejecute mediante el modelo v2.
Versión de Python
Azure Functions admite las siguientes versiones de Python:
| Versión de Functions | Versiones de Python* |
|---|---|
| 4.x | 3,11 3.10 3.9 3.8 3.7 |
| 3.x | 3.9 3.8 3.7 |
* Distribuciones oficiales de Python
Para solicitar una versión específica de Python al crear la aplicación de funciones en Azure, use la opción --runtime-version del comando az functionapp create. La versión de tiempo de ejecución de Functions se establece mediante la opción --functions-version. La versión de Python se establece cuando se crea la aplicación de funciones y no se puede cambiar para las aplicaciones que se ejecutan en un plan de Consumo.
El entorno de ejecución usa la versión de Python disponible cuando se ejecuta localmente.
Cambio de la versión de Python
Para establecer una aplicación de funciones de Python en una versión de lenguaje específica, debe especificar el lenguaje y la versión del lenguaje en el campo LinuxFxVersion de la configuración del sitio. Por ejemplo, para cambiar la aplicación de Python para usar Python 3.8, establezca linuxFxVersion en python|3.8.
Para obtener información sobre cómo ver y cambiar la configuración del sitio linuxFxVersion, consulte Cómo establecer como destino Azure Functions versiones en runtime.
Para más información general, consulte la directiva de compatibilidad con tiempo de ejecución de Azure Functions y los idiomas admitidos en Azure Functions.
Administración de paquetes
Al desarrollar de manera local con Core Tools o Visual Studio Code, agregue los nombres y las versiones de los paquetes necesarios al archivo requirements.txt e instálelos mediante pip.
Por ejemplo, puede usar el archivo requirements.txtsiguiente y el comando pip para instalar el paquete requests desde PyPI.
requests==2.19.1
pip install -r requirements.txt
Al ejecutar las funciones en un plan de App Service, las dependencias que defina en requirements.txt tienen prioridad sobre los módulos integrados de Python, como logging. Esta precedencia puede provocar conflictos cuando los módulos integrados tienen los mismos nombres que los directorios del código. Cuando se ejecuta en un plan de consumo o un plan de Elastic Premium, es menos probable que los conflictos se deban a que las dependencias no tienen prioridad de forma predeterminada.
Para evitar problemas de ejecución en un plan de App Service, no asigne nombres a los directorios iguales que los módulos nativos de Python y no incluya bibliotecas nativas de Python en el archivo requirements.txt del proyecto.
Publicación en Azure
Cuando esté preparado para la publicación, asegúrese de que todas las dependencias disponibles públicamente están incluidas en el archivo requirements.txt. Puede encontrar este archivo en la raíz del directorio del proyecto.
Puede encontrar los archivos y carpetas del proyecto que se excluyen de la publicación, incluida la carpeta del entorno virtual, en el directorio raíz del proyecto.
Se admiten tres acciones de compilación para publicar el proyecto de Python en Azure: compilación remota, compilación local y compilaciones mediante dependencias personalizadas.
También puede usar Azure Pipelines para compilar las dependencias y publicarlas mediante la entrega continua (CD). Para más información, consulte Entrega continua con Azure Pipelines.
Compilación remota
Cuando se usa la compilación remota, las dependencias restauradas en el servidor y las dependencias nativas coinciden con el entorno de producción. Esto da como resultado un paquete de implementación más pequeño para cargar. Use una compilación remota para desarrollar aplicaciones de Python en Windows. Si el proyecto tiene dependencias personalizadas, puede usar la compilación remota con la dirección URL de índice adicional.
Las dependencias se obtienen de forma remota en función del contenido del archivo requirements.txt. La compilación remota es el método de compilación recomendado. De forma predeterminada, Core Tools solicita una compilación remota cuando se usa el siguiente comando func azure functionapp publish para publicar el proyecto de Python en Azure.
func azure functionapp publish <APP_NAME>
Reemplace <APP_NAME> por el nombre de la aplicación de función de Azure.
La extensión de Azure Functions para Visual Studio Code también solicita de forma predeterminada una compilación remota.
Compilación local
Las dependencias se obtienen de forma local en función del contenido del archivo requirements.txt. Puede impedir que se lleve a cabo una compilación remota mediante el siguiente comando func azure functionapp publish para publicar con una compilación local:
func azure functionapp publish <APP_NAME> --build local
Reemplace <APP_NAME> por el nombre de la aplicación de función de Azure.
Cuando se usa la opción --build local, las dependencias del proyecto se leen del archivo requirements.txt y los paquetes dependientes se descargan e instalan localmente. Los archivos de proyecto y las dependencias se implementan desde el equipo local en Azure. Esto hace que se cargue un paquete de implementación más grande en Azure. Si por algún motivo no puede obtener el archivo requirements.txt con Core Tools, debe usar la opción de dependencias personalizadas para la publicación.
No se recomienda usar compilaciones locales para desarrollar de manera local en Windows.
Dependencias personalizadas
Cuando el proyecto tiene dependencias que no se encuentran en el Índice de paquetes de Python, hay dos maneras de compilar el proyecto. La primera, el método de compilación, depende de cómo se compile el proyecto.
Compilación remota con dirección URL de índice adicional
Cuando los paquetes estén disponibles desde un índice de paquetes personalizado accesible, use una compilación remota. Antes de publicar, asegúrese de crear una configuración de aplicación denominada PIP_EXTRA_INDEX_URL. El valor de esta configuración es la dirección URL del índice de paquetes personalizado. El uso de esta configuración indica a la compilación remota que ejecute pip install mediante la opción --extra-index-url. Para más información, consulte la documentación de pip install de Python.
También puede utilizar las credenciales de autenticación básica con las direcciones URL del índice de paquetes adicional. Para más información, vea Credenciales de autenticación básica en la documentación de Python.
Instalación de paquetes locales
Si el proyecto usa paquetes que no están disponibles públicamente para nuestras herramientas, puede ponerlos a disposición de la aplicación colocándolos en el directorio __app__/.python_packages. Antes de la publicación, ejecute el siguiente comando para instalar las dependencias localmente:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
Al usar dependencias personalizadas, use la siguiente opción de publicación --no-build, porque ya ha instalado las dependencias en la carpeta del proyecto.
func azure functionapp publish <APP_NAME> --no-build
Reemplace <APP_NAME> por el nombre de la aplicación de función de Azure.
Pruebas unitarias
Las funciones escritas en Python se pueden probar como otro código de Python mediante marcos de pruebas. Para la mayoría de los enlaces, es posible crear un objeto de entrada ficticio creando una instancia de una clase adecuada a partir del paquete azure.functions. Como el paquete azure.functions no está disponible inmediatamente, asegúrese de instalarlo a través del archivo requirements.txt, tal como se describe en la sección Administración de paquetes anterior.
Si tomamos my_second_function como ejemplo, a continuación se muestra una prueba ficticia de una función desencadenada por HTTP:
En primer lugar, debemos crear el archivo <project_root>/my_second_function/function.json y definir esta función como un desencadenador HTTP.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
A continuación, puede implementar my_second_function y shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Puede empezar a escribir casos de prueba para el desencadenador HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
Dentro de la carpeta del entorno virtual de Python, .venv, instale el marco de pruebas de Python que prefiera (por ejemplo, pip install pytest). Después, ejecute pytest tests para comprobar el resultado de la prueba.
En primer lugar, cree el archivo <project_root>/function_app.py e implemente la función my_second_function como desencadenador HTTP y shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Puede empezar a escribir casos de prueba para el desencadenador HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
Dentro de la carpeta del entorno virtual de Python, .venv, instale el marco de pruebas de Python que prefiera (por ejemplo, pip install pytest). Después, ejecute pytest tests para comprobar el resultado de la prueba.
Archivos temporales
El método tempfile.gettempdir() devuelve una carpeta temporal, que en Linux es /tmp. La aplicación puede usar este directorio para almacenar los archivos temporales generados y usados por las funciones durante la ejecución.
Importante
No se garantiza que los archivos escritos en el directorio temporal persistan entre invocaciones. Durante el escalado horizontal, los archivos temporales no se comparten entre instancias.
En el ejemplo siguiente se crea un archivo temporal con nombre en el directorio temporal (/tmp):
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
Se recomienda mantener las pruebas en una carpeta independiente de la carpeta del proyecto. Esta acción evita que se implemente código de prueba con la aplicación.
Bibliotecas preinstaladas
Algunas bibliotecas incluyen el entorno de ejecución de funciones de Python.
La biblioteca estándar de Python
La biblioteca estándar de Python contiene una lista de módulos de Python integrados que se incluyen con cada distribución de Python. La mayoría de estas bibliotecas le ayudan a acceder a la funcionalidad del sistema, como la entrada/salida de archivos (E/S). En los sistemas Windows, estas bibliotecas se instalan con Python. En los sistemas basados en Unix, las proporcionan las colecciones de paquetes.
Para ver la biblioteca de la versión de Python, vaya a:
- Biblioteca estándar de Python 3.8
- Biblioteca estándar de Python 3.9
- Biblioteca estándar de Python 3.10
- Biblioteca estándar de Python 3.11
Dependencias de trabajo de Python en Azure Functions
El trabajo de Python en Azure Functions requiere un conjunto específico de bibliotecas. También puede usar estas bibliotecas en sus funciones, pero no forman parte del estándar de Python. Si las funciones se basan en cualquiera de estas bibliotecas, puede que no estén disponibles para el código cuando se ejecutan fuera de Azure Functions. Puede encontrar una lista detallada de las dependencias en la sección "install_requires" del archivo setup.py.
Nota:
Si el archivo requirements.txt de la aplicación de funciones contiene una entrada azure-functions-worker, quítela. El trabajo de funciones se administra automáticamente mediante la plataforma de Azure Functions y se actualiza periódicamente con nuevas características y correcciones de errores. La instalación manual de una versión anterior del trabajo en el archivo requirements.txt puede producir problemas inesperados.
Nota
Si el paquete contiene determinadas bibliotecas que quizás entran en conflicto con las dependencias del trabajo (por ejemplo, Protobuf, TensorFlow, grpcio), configure PYTHON_ISOLATE_WORKER_DEPENDENCIES como 1 en la configuración de la aplicación para evitar que la aplicación haga referencia a las dependencias del trabajo.
Biblioteca de Python para Azure Functions
Cada actualización de trabajado de Python incluye una nueva versión de la biblioteca de Python para Azure Functions (azure.functions). Este enfoque facilita la actualización continua de las aplicaciones de funciones de Python, ya que cada actualización es compatible con versiones anteriores. Puede encontrar una lista de las versiones de esta biblioteca en azure-functions PyPi.
La versión de la biblioteca en tiempo de ejecución la determina Azure y no se puede reemplazar por requirements.txt. La entrada azure-functions en requirements.txt es solo para linting y reconocimiento de clientes.
Use el código siguiente para realizar un seguimiento de la versión real de la biblioteca de funciones de Python en tiempo de ejecución:
getattr(azure.functions, '__version__', '< 1.2.1')
Bibliotecas de sistema en tiempo de ejecución
Para obtener una lista de las bibliotecas de sistema preinstaladas en las imágenes de Docker de trabajo de Python, consulte lo siguiente:
| Sistema en tiempo de ejecución de Functions | Versión de Debian | Versiones de Python |
|---|---|---|
| Versión 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Extensiones de trabajo de Python
El proceso de trabajo de Python que se ejecuta en Azure Functions permite integrar bibliotecas de terceros en la aplicación de funciones. Estas bibliotecas de extensiones actúan como middleware que puede insertar operaciones específicas durante el ciclo de vida de la ejecución de la función.
Las extensiones se importan en el código de función de forma muy parecida a un módulo de biblioteca estándar de Python. Las extensiones se ejecutan en función de los ámbitos siguientes:
| Ámbito | Descripción |
|---|---|
| En el nivel de la aplicación | Cuando se importa en cualquier desencadenador de función, la extensión se aplica a cada ejecución de la función en la aplicación. |
| Nivel de función | La ejecución se limita solo al desencadenador de función específico en el que se importa. |
Revise la información de cada extensión para más información sobre el ámbito en el que se ejecuta la extensión.
Las extensiones implementan una interfaz de extensión de trabajo de Python. Esta acción permite que el proceso de trabajo de Python llame al código de la extensión durante el ciclo de vida de ejecución de la función. Para más información, consulte Creación de extensiones.
Uso de extensiones
Puede usar una biblioteca de extensiones de trabajo de Python en las funciones de Python mediante estos pasos:
- Agregue el paquete de extensión en el archivo requirements.txt del proyecto.
- Instale la biblioteca en la aplicación.
- Agregue la siguiente configuración de la aplicación:
- .Localmente: agregue
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"en la secciónValuesdel archivo local.settings.json. - Azure: escriba
PYTHON_ENABLE_WORKER_EXTENSIONS=1en la configuración de la aplicación.
- .Localmente: agregue
- Importe el módulo de extensión en el desencadenador de función.
- Configure la instancia de la extensión, si es necesario. Los requisitos de configuración deben indicarse en la documentación de la extensión.
Importante
Microsoft no admite ni garantiza las bibliotecas de extensiones de trabajo de Python de terceros. Debe asegurarse de que las extensiones que use en la aplicación de funciones sean de confianza y asumir todo el riesgo que supone usar una extensión malintencionada o mal escrita.
Los terceros deben proporcionar documentación específica sobre cómo instalar y usar sus extensiones en la aplicación de funciones. Para obtener un ejemplo básico de cómo usar una extensión, consulte Uso de la extensión.
Estos son ejemplos de uso de extensiones en una aplicación de funciones, por ámbito:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Creación de extensiones
Las extensiones las crean desarrolladores de bibliotecas de terceros que han creado funcionalidades que se pueden integrar en Azure Functions. Un desarrollador de extensiones diseña, implementa y publica paquetes de Python que contienen lógica personalizada diseñada específicamente para ejecutarse en el contexto de la ejecución de funciones. Estas extensiones se pueden publicar en el registro de PyPI o en repositorios de GitHub.
Para aprender a crear, empaquetar, publicar y usar un paquete de extensión de trabajo de Python, consulte Desarrollo de extensiones de trabajo de Python para Azure Functions.
Extensiones en el nivel de aplicación
Una extensión heredada de AppExtensionBase se ejecuta en un ámbito de aplicación.
AppExtensionBase expone los siguientes métodos de clase abstracta para que los implemente:
| Método | Descripción |
|---|---|
init |
Se le llama después de importar la extensión. |
configure |
Se le llama desde el código de función cuando se necesita para configurar la extensión. |
post_function_load_app_level |
Se le llama justo después de cargar la función. El nombre y el directorio de la función se pasan a la extensión. Tenga en cuenta que el directorio de la función es de solo lectura y cualquier intento de escribir en el archivo local de este directorio provocará un error. |
pre_invocation_app_level |
Se le llama justo antes de que se desencadene la función. El contexto y los argumentos de invocación de la función se pasan a la extensión. Normalmente puede pasar otros atributos en el objeto de contexto para que el código de la función los utilice. |
post_invocation_app_level |
Se le llama justo después de que se finalice la ejecución de la función. El contexto de la función, los argumentos de invocación de la función y el objeto devuelto por la invocación se pasan a la extensión. Esta implementación es un buen lugar para validar si la ejecución de los enlaces del ciclo de vida se ha ejecutado correctamente. |
Extensiones en el nivel de función
Una extensión que se hereda de FuncExtensionBase se ejecuta en un desencadenador de función específico.
FuncExtensionBase expone los siguientes métodos de clase abstracta para que los implemente:
| Método | Descripción |
|---|---|
__init__ |
Constructor de la extensión. Se le llama cuando se inicializa una instancia de extensión en una función específica. Al implementar este método abstracto, quizás quiera aceptar un parámetro filename y pasarlo al método del elemento primario super().__init__(filename) para el registro adecuado de la extensión. |
post_function_load |
Se le llama justo después de cargar la función. El nombre y el directorio de la función se pasan a la extensión. Tenga en cuenta que el directorio de la función es de solo lectura y cualquier intento de escribir en el archivo local de este directorio provocará un error. |
pre_invocation |
Se le llama justo antes de que se desencadene la función. El contexto y los argumentos de invocación de la función se pasan a la extensión. Normalmente puede pasar otros atributos en el objeto de contexto para que el código de la función los utilice. |
post_invocation |
Se le llama justo después de que se finalice la ejecución de la función. El contexto de la función, los argumentos de invocación de la función y el objeto devuelto por la invocación se pasan a la extensión. Esta implementación es un buen lugar para validar si la ejecución de los enlaces del ciclo de vida se ha ejecutado correctamente. |
Uso compartido de recursos entre orígenes
Azure Functions admite el uso compartido de recursos entre orígenes (CORS). CORS se configura en el portal y mediante la CLI de Azure. La lista de orígenes permitidos de CORS se aplica en el nivel de la aplicación de función. Con CORS habilitado, las respuestas incluyen el encabezado Access-Control-Allow-Origin. Para obtener más información, consulte Uso compartido de recursos entre orígenes.
El uso compartido de recursos entre orígenes (CORS) es totalmente compatible con las aplicaciones de funciones de Python.
Async
De manera predeterminada, una instancia de host para Python solo puede procesar una invocación de función a la vez. Esto se debe a que Python es un entorno de ejecución de un solo subproceso. Para una aplicación de funciones que procesa un gran número de eventos de E/S o está enlazada a E/S, puede mejorar significativamente el rendimiento mediante la ejecución asincrónica de funciones. Para más información, consulte Mejora del rendimiento de las aplicaciones de Python en Azure Functions.
Memoria compartida (versión preliminar)
Para mejorar el rendimiento, Azure Functions permite que el trabajador del lenguaje Python fuera de proceso comparta memoria con el proceso de host de Functions. Cuando se producen cuellos de botella en la aplicación de funciones, puede agregar una configuración de la aplicación denominada FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED con un valor de 1 para habilitar la memoria compartida. Con la memoria compartida habilitada, puede usar la configuración DOCKER_SHM_SIZE para establecer la memoria compartida en algo similar a 268435456, que es equivalente a 256 MB.
Por ejemplo, puede habilitar la memoria compartida para reducir los cuellos de botella al usar enlaces de Blob Storage para transferir cargas de más de 1 MB.
Esta funcionalidad solo está disponible para las aplicaciones de funciones que se ejecutan en los planes Premium y Dedicado (Azure App Service). Para obtener más información, consulte Memoria compartida.
Problemas conocidos y preguntas más frecuentes
Estas son dos guías de solución de problemas comunes:
Estas son dos guías de solución de problemas para problemas conocidos con el modelo de programación v2:
- No se pudo cargar el archivo o ensamblado
- No se puede resolver la conexión de Azure Storage denominada Storage
Todos los problemas conocidos y las solicitudes de características se siguen mediante la lista de problemas de GitHub. Si le surge algún problema y no lo encuentra en GitHub, abra un nuevo problema e incluya una descripción detallada del mismo.
Pasos siguientes
Para obtener más información, consulte los siguientes recursos:
- Documentación de la API del paquete de Azure Functions
- Procedimientos recomendados para Azure Functions
- Enlaces y desencadenadores de Azure Functions
- Enlaces de Blob Storage
- Enlaces HTTP y de webhook
- Enlaces de Queue Storage
- Desencadenadores de temporizador
¿Tiene problemas con el uso de Python? Díganos lo que está sucediendo.