Configuración de un grupo de conmutación por error para una SQL Managed Instance
Se aplica a:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
En este tema se muestra cómo configurar un grupo de conmutación por error para Azure SQL Managed Instance mediante el portal de Azure y Azure PowerShell.
Para que un script de PowerShell de un extremo a otro cree ambas instancias dentro de un grupo de conmutación por error, revisa Agregar instancia a un grupo de conmutación por error.
Requisitos previos
Tenga en cuenta los siguientes requisitos previos:
- La instancia administrada secundaria debe estar vacía, es decir, no puede contener bases de datos de usuario.
- Las dos instancias de Instancia administrada de SQL deben ser del mismo nivel de servicio y tener el mismo tamaño de almacenamiento. Aunque no es necesario, se recomienda que dos instancias tengan un tamaño de proceso igual, para asegurarse de que la instancia secundaria pueda procesar de forma sostenible los cambios que se replican desde la instancia principal, incluidos los períodos de actividad máxima.
- El intervalo de direcciones IP de la red virtual de la instancia principal no debe superponerse con el intervalo de direcciones de la red virtual de la instancia administrada secundaria, ni con cualquier otra red virtual emparejada con la red virtual principal o secundaria.
- Al crear la instancia administrada secundaria, debes especificar el identificador de zona DNS de la instancia principal como el valor del parámetro
DnsZonePartner. Si no se especifica un valor paraDnsZonePartner, el Id. de zona se genera como una cadena aleatoria cuando se crea la primera instancia en cada red virtual, y este mismo Id. se asigna a todas las demás instancias de la misma subred. Una vez que se ha asignado, no se puede modificar la zona DNS. - Las reglas de grupos de seguridad de red (NSG) en la instancia de hospedaje de subred deben tener abiertas la entrada y salida del puerto 5022 (TCP) y del intervalo de puertos 11000-11999 (TCP) para las conexiones desde y hacia la subred que hospeda la otra instancia administrada. Esto se aplica a ambas subredes que hospedan las instancias principal y secundaria.
- La intercalación y zona horaria de la instancia administrada secundaria deben coincidir con las de la instancia administrada principal.
- Las instancias administradas se deben implementar en regiones emparejadas por motivos de rendimiento. Las instancias administradas que residen en regiones emparejadas geográficamente se benefician de una velocidad de replicación geográfica significativamente mayor en comparación con las regiones no emparejadas.
Intervalo del espacio de direcciones
Para comprobar el espacio de direcciones de la instancia principal, ve al recurso de red virtual de la instancia principal y selecciona Espacio de direcciones en Configuración. Comprueba el intervalo en Intervalo de direcciones:
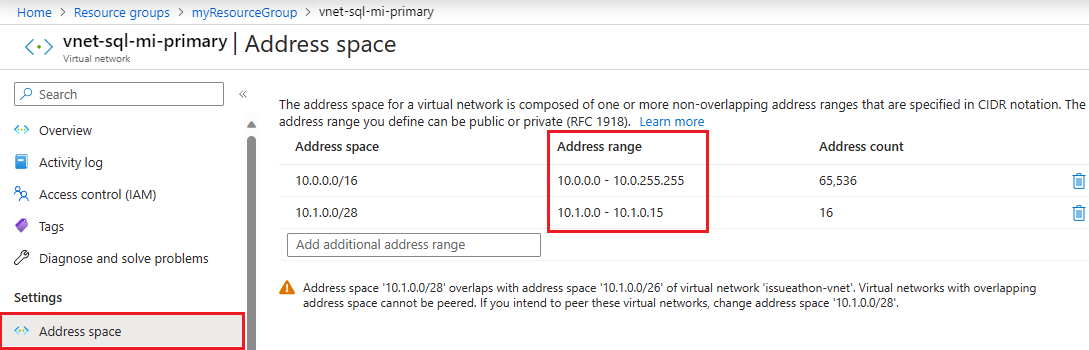
Especificar el Id. de zona de la instancia principal
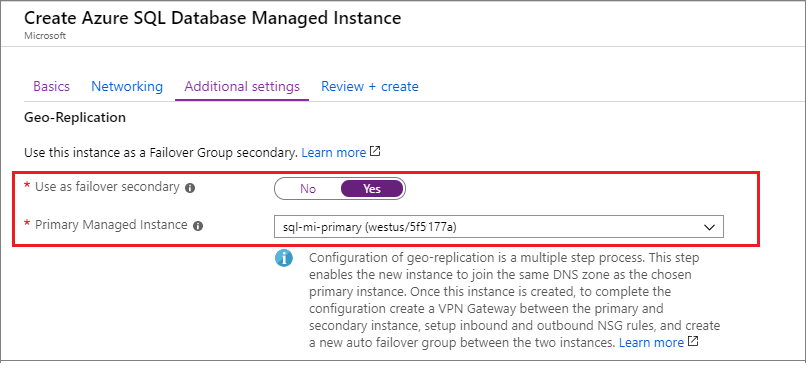
Al crear la instancia administrada secundaria, debes especificar el Id. de zona de la instancia principal como el valor de DnsZonePartner.
Si vas a crear la instancia secundaria en Azure Portal, en la pestaña Configuración adicional, en Replicación geográfica, elige Sí para Usar como secundaria de conmutación por error y, a continuación, selecciona la instancia principal en la lista desplegable:
Habilitación de la conectividad entre las instancias
Se debe establecer la conectividad entre las subredes de red virtual que hospedan las instancias principal y secundaria para el flujo de tráfico de replicación geográfica ininterrumpido. Hay varias maneras de establecer la conectividad entre instancias administradas en diferentes regiones de Azure, entre las que se incluyen:
- Emparejamiento global de redes virtuales
- Información técnica de ExpressRoute
- Puertas de enlace de VPN
El emparejamiento de red virtual global se recomienda como la manera más eficaz y sólida de establecer la conectividad entre las instancias y un grupo de conmutación por error. El emparejamiento de red virtual global proporciona una conexión privada de ancho de banda alto y baja latencia entre las redes virtuales emparejadas mediante la infraestructura troncal de Microsoft. No se requiere ninguna red pública de Internet, puertas de enlace ni cifrado adicional en la comunicación entre las redes virtuales emparejadas.
Importante
Las formas alternativas de conectar instancias que implican dispositivos de red adicionales podrían complicar la solución de problemas de conectividad o velocidad de replicación, lo que podría requerir la participación activa de los administradores de red y, posiblemente, prolongar significativamente el tiempo de resolución.
Independientemente del mecanismo de conectividad, hay requisitos que deben cumplirse para que fluya el tráfico de replicación geográfica:
- Los grupos de seguridad de red y la tabla de rutas asignados a subredes de instancia administrada no se comparten entre las dos redes virtuales emparejadas.
- Las reglas del grupo de seguridad de red en la subred que hospeda la instancia principal permiten lo siguiente:
- Tráfico de entrada en el puerto 5022 y en el intervalo de puertos 11000-11999 desde la subred que hospeda la instancia secundaria.
- Tráfico de salida en el puerto 5022 y en el intervalo de puertos 11000-11999 a la subred que hospeda la instancia secundaria.
- Las reglas del grupo de seguridad de red (NSG) en la subred que hospeda la instancia secundaria permiten lo siguiente:
- Tráfico de entrada en el puerto 5022 y en el intervalo de puertos 11000-11999 desde la subred que hospeda la instancia principal.
- Tráfico de salida en el puerto 5022 y en el intervalo de puertos 11000-11999 a la subred que hospeda la instancia principal.
- Los intervalos de direcciones IP de las redes virtuales que hospedan la instancia principal y secundaria no deben superponerse.
- No hay superposición indirecta de intervalos de direcciones IP entre las redes virtuales que hospedan las instancias principal y secundaria u otra red virtual con la que se emparejan mediante el emparejamiento de red virtual local u otros medios.
Además, si usa otros mecanismos para proporcionar conectividad entre las instancias aparte del emparejamiento global de redes virtuales recomendado, debe asegurarse de lo siguiente:
- Ningún dispositivo de red usado, como firewalls o aplicaciones virtuales de red (NVA), bloquea el tráfico descrito anteriormente.
- El enrutamiento está configurado correctamente y se evita el enrutamiento asimétrico.
- Si implementas grupos de conmutación por error en una topología en estrella tipo hub-and-spoke entre regiones, el tráfico de replicación debe ir directamente entre las dos subredes de instancia administrada en lugar de dirigirse a través de las redes del centro. Te permite evitar problemas de velocidad de conectividad y replicación.
- En el portal de Azure, vaya al recurso Red virtual para la instancia administrada principal.
- Seleccione Emparejamientos en el menú Configuración y, después, seleccione + Agregar.
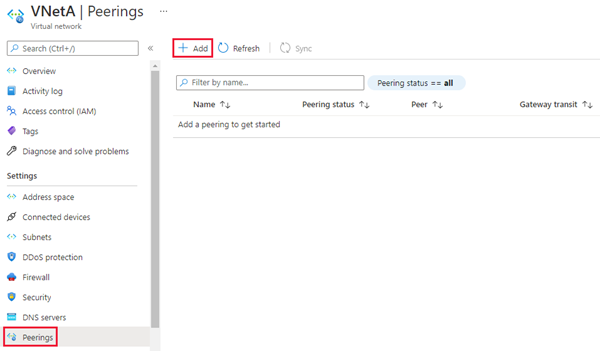
Escriba o seleccione valores para la siguiente configuración:
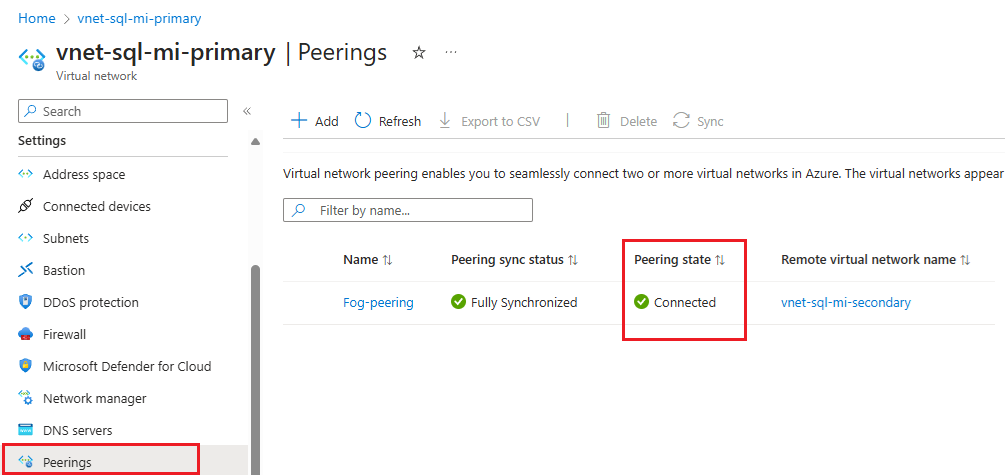
Configuración Descripción Esta red virtual Nombre del vínculo de emparejamiento el nombre del emparejamiento debe ser único dentro de la red virtual. Tráfico hacia la red virtual remota Seleccione Permitir (valor predeterminado) para habilitar la comunicación entre las dos redes virtuales a través del flujo VirtualNetworkpredeterminado. Al permitir la comunicación entre redes virtuales, los recursos conectados a cualquier red virtual se pueden comunicar entre sí, con el mismo ancho de banda y latencia que si estuvieran conectados a la misma red virtual. Todas las comunicaciones entre los recursos de las dos redes virtuales se realizan a través de la red privada de Azure.Tráfico reenviado desde la red virtual remota Las opciones Permitido (valor predeterminado) y Bloquear funcionarán para este tutorial. Para obtener más información, consulte Creación de un emparejamiento. Servidor de rutas o puerta de enlace de la red virtual Seleccione Ninguno. Para obtener más información sobre las otras opciones disponibles, consulte Creación de un emparejamiento. Red virtual remota Nombre del vínculo de emparejamiento El nombre del mismo emparejamiento que se va a usar en la red virtual que hospeda la instancia secundaria. Modelo de implementación de red virtual Seleccione Administrador de recursos. Conozco mi Id. de recurso Deje desactivada esta casilla. Subscription Seleccione la suscripción de Azure de la red virtual que hospeda la instancia secundaria con la que desea emparejarse. Virtual network Seleccione la red virtual que hospeda la instancia secundaria con la que desea emparejarse. Si una red virtual aparece en gris en la lista, puede deberse a que el espacio de direcciones de la red virtual se superpone con el espacio de direcciones de esta red virtual. Si los espacios de direcciones de las redes virtuales se superponen, no se pueden emparejar. Tráfico hacia la red virtual remota Seleccione Permitir (valor predeterminado). Tráfico reenviado desde la red virtual remota Las opciones Permitido (valor predeterminado) y Bloquear funcionarán para este tutorial. Para obtener más información, consulte Creación de un emparejamiento. Servidor de rutas o puerta de enlace de la red virtual Seleccione Ninguno. Para obtener más información sobre las otras opciones disponibles, consulte Creación de un emparejamiento. Seleccione Agregar para configurar el emparejamiento con la red virtual que ha elegido. Después de unos segundos, seleccione el botón Actualizar y el estado de emparejamiento cambiará de Actualizando a Conectado.
Creación del grupo de conmutación por error
Cree el grupo de conmutación por error para sus instancias administradas mediante Azure Portal o PowerShell.
Cree el grupo de conmutación por error para sus Instancias administradas de SQL mediante Azure Portal.
Seleccione Azure SQL en el menú izquierdo de Azure Portal. Si Azure SQL no está en la lista, seleccione Todos los servicios y escriba Azure SQL en el cuadro de búsqueda. (Opcional) Seleccione la estrella junto a Azure SQL para agregarlo como elemento favorito al panel de navegación izquierdo.
Seleccione la instancia administrada principal que desea agregar al grupo de conmutación por error.
En Configuración, navegue a Grupos de conmutación por error de instancias y, después, elija Agregar grupo para abrir la página de creación de grupo de conmutación por error de instancias.
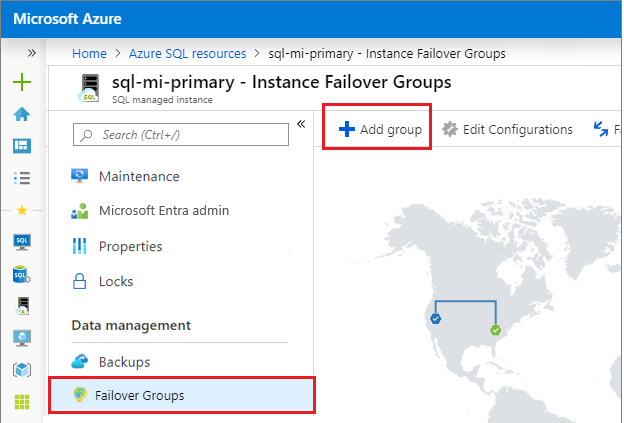
En la página Grupo de conmutación por error de instancias, escriba el nombre del grupo de conmutación por error y después elija la instancia administrada secundaria en la lista desplegable. Seleccione Crear para crear el grupo de conmutación por error.
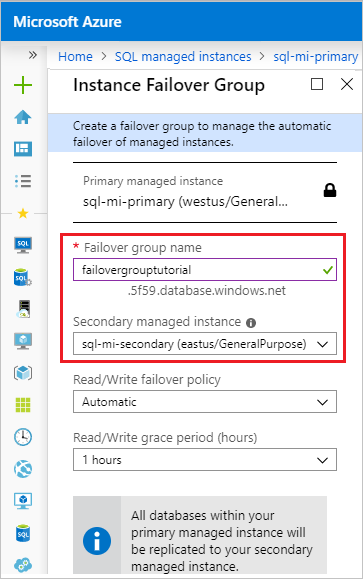
Una vez completada la implementación del grupo de conmutación por error, vuelve a mostrarse la página Grupo de conmutación por error.
Conmutación por error de prueba
Pruebe la conmutación por error de su grupo de conmutación por error mediante Azure Portal o PowerShell.
Pruebe la conmutación por error de su grupo de conmutación por error mediante Azure Portal.
Vaya a la instancia administrada secundaria en Azure Portal y seleccione Grupos de conmutación por error de instancias en las opciones de configuración.
Observe las instancias administradas en los roles principal y secundario.
Seleccione Conmutación por error y, a continuación, seleccione Sí en la advertencia acerca de la desconexión de las sesiones TDS.
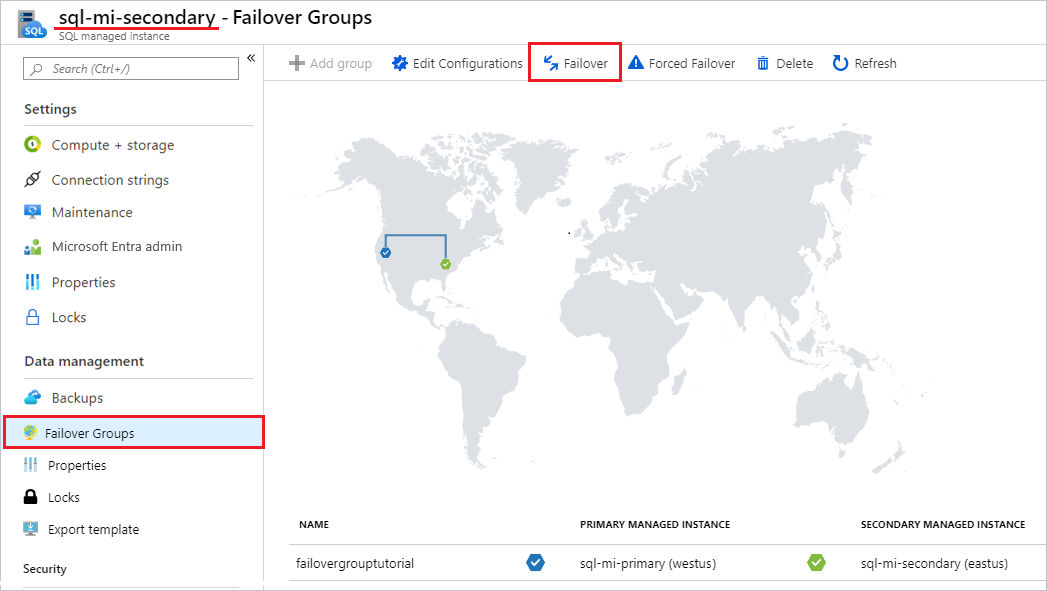
Observe las instancias administradas en los roles principal y secundario. Si la conmutación por error se realiza correctamente, las dos instancias deben tener los roles cambiados.

Importante
Si los roles no han cambiado, compruebe la conectividad entre las instancias y las reglas de firewall y NSG relacionadas. Continúe con el paso siguiente solo después de cambiar los roles.
- Vaya a la nueva instancia administrada secundaria y seleccione Conmutación por error para que la instancia principal vuelva a tener el rol principal.
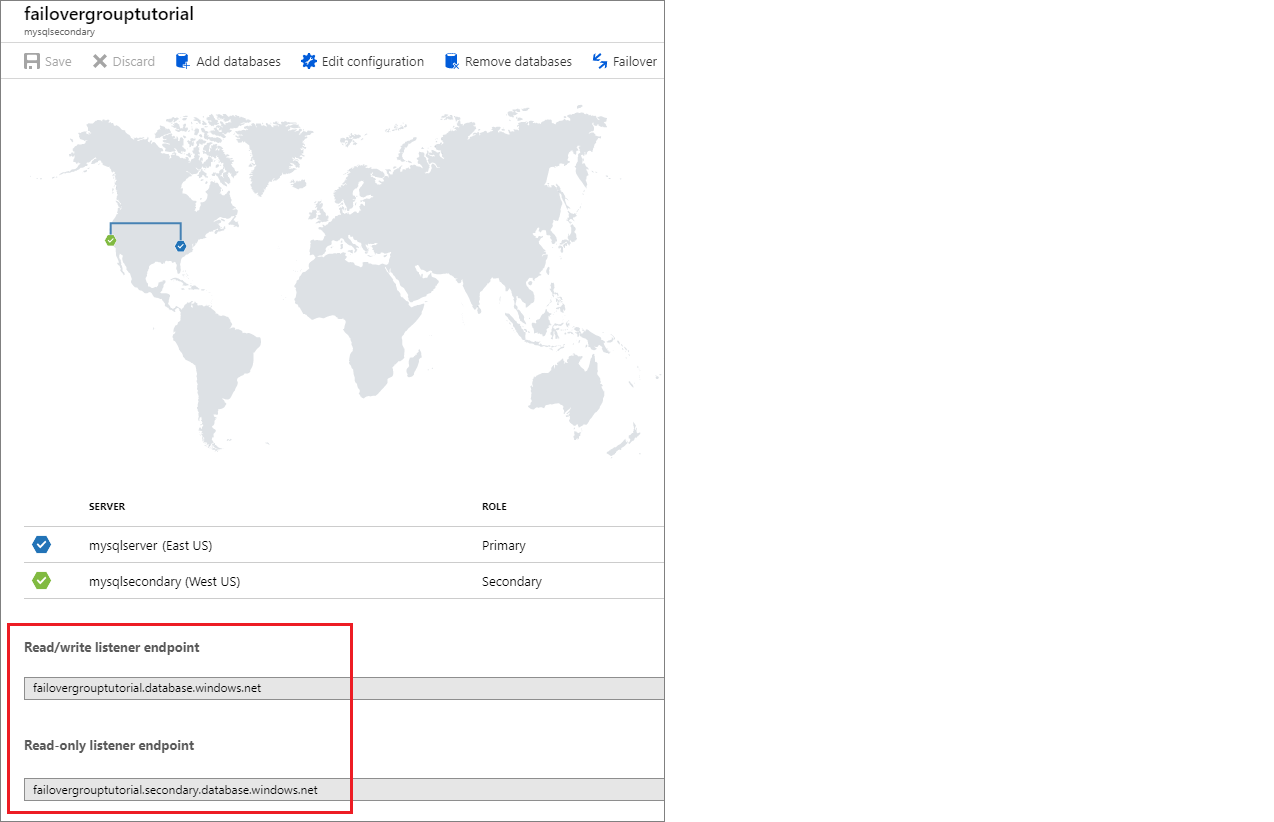
Búsqueda del punto de conexión del cliente de escucha
Una vez que se configure su grupo de conmutación por error, actualice la cadena de conexión para su aplicación al punto de conexión del cliente de escucha. Esto mantiene tu aplicación conectada al cliente de escucha del grupo de conmutación por error, en lugar de la base de datos principal, el grupo elástico o la base de datos de instancia. De esa forma, no tendrá que actualizar manualmente la cadena de conexión cada vez que su entidad de base de datos conmute por error y el tráfico se enrute a la entidad que actualmente sea la principal.
El punto de conexión del cliente de escucha tiene el formato fog-name.database.windows.net y es visible en Azure Portal, al ver el grupo de conmutación por error:
Creación de un grupo entre instancias en distintas suscripciones
Puede crear un grupo de conmutación por error entre instancias de SQL Managed Instance en dos suscripciones diferentes, siempre que estén asociadas al mismo inquilino de Microsoft Entra.
- Al usar la API de PowerShell, puede hacerlo especificando el parámetro
PartnerSubscriptionIdde la instancia secundaria de SQL Managed Instance. - Al usar la API REST, cada identificador de instancia incluido en el parámetro
properties.managedInstancePairspuede tener su propio id. de suscripción. - Azure Portal no admite la creación de grupos de conmutación por error en distintas suscripciones.
Importante
Azure Portal no admite la creación de grupos de conmutación por error en distintas suscripciones. Para los grupos de conmutación por error en distintas suscripciones y/o grupos de recursos, no se puede iniciar manualmente la conmutación por error mediante el portal de Azure desde la instancia administrada principal de SQL. En su lugar, se inicia desde la instancia de la base de datos geográfica secundaria.
Evitación la pérdida de datos críticos
Debido a la elevada latencia de las redes de área extensa, la replicación geográfica usa un mecanismo de replicación asincrónica. La replicación asincrónica hace que la posibilidad de perder datos sea inevitable si se produce un error en la principal. Para proteger las transacciones críticas contra la pérdida de datos, un desarrollador de aplicaciones puede llamar al procedimiento almacenado sp_wait_for_database_copy_sync inmediatamente después de confirmar la transacción. La llamada a sp_wait_for_database_copy_sync bloquea el subproceso de llamada hasta que se transmite y protege la última transacción confirmada en el registro de transacciones de la base de datos secundaria. Pero no espera a que las transacciones transmitidas se reproduzcan (vuelvan a hacerse) en la secundaria. sp_wait_for_database_copy_sync está limitado a un vínculo de replicación geográfica específico. Cualquier usuario con derechos de conexión para la base de datos principal puede llamar a este procedimiento.
Nota:
sp_wait_for_database_copy_sync evita la pérdida de datos después de la conmutación por error geográfica para transacciones específicas, pero no garantiza la sincronización completa para el acceso de lectura. El retraso provocado por una llamada al procedimiento sp_wait_for_database_copy_sync puede ser considerable y depende del tamaño del registro de transacciones que todavía no se transmiten en la principal en el momento de la llamada.
Cambio de la región secundaria
Supongamos que la instancia A es la principal, la B es la instancia secundaria existente y la C es la nueva instancia secundaria de la tercera región. Para realizar la transición, siga estos pasos:
- Cree la instancia C con el mismo tamaño que la instancia A y en la misma zona DNS.
- Elimina el grupo de conmutación por error entre las instancias A y B. En este momento, se produce un error en los intentos de inicios de sesión porque se han eliminado los alias de SQL de los clientes de escucha del grupo de conmutación por error y la puerta de enlace no reconocerá el nombre del grupo de conmutación por error. Las bases de datos secundarias se desconectan de las principales y se convierten en bases de datos de lectura y escritura.
- Crea un grupo de conmutación por error con el mismo nombre entre las instancias A y C. Sigue las instrucciones de la guía para congigurar grupos de conmutación por error. Se trata de una operación de tamaño de datos, que se completa cuando todas las bases de datos de la instancia A se inicialicen y se sincronicen.
- Si no es necesario, elimine la instancia B para evitar cargos innecesarios.
Nota:
Después del paso 2 y hasta que se complete el paso 3, las bases de datos de la instancia A permanecerán desprotegidas frente a un error catastrófico en la instancia A.
Cambio de la región primaria
Supongamos que la instancia A es la principal, la B es la instancia secundaria existente y la C es la nueva instancia principal de la tercera región. Para realizar la transición, siga estos pasos:
- Cree la instancia C con el mismo tamaño que la instancia B y en la misma zona DNS.
- Conéctate a la instancia B y conmuta por error manualmente para cambiar la instancia principal a B. La instancia A se convertirá en la nueva instancia secundaria automáticamente.
- Elimina el grupo de conmutación por error entre las instancias A y B. En este momento, se produce un error en los intentos de inicio de sesión mediante el uso de los puntos de conexión del grupo de conmutación por error. Las bases de datos secundarias en A se desconectan de las principales y se convierten en bases de datos de lectura y escritura.
- Crea un grupo de conmutación por error con el mismo nombre entre las instancias B y C. Sigue las instrucciones de la guía sobre grupos de conmutación por error. Se trata de una operación de tamaño de datos, que se completa cuando todas las bases de datos de la instancia A se inicialicen y se sincronicen. En este momento, se dejan de producir errores en los intentos de inicio de sesión.
- Realiza una conmutación por error manual para cambiar la instancia C al rol principal. La instancia B se convierte automáticamente en la nueva instancia secundaria.
- Si no es necesario, elimine la instancia A para evitar cargos innecesarios.
Precaución
Después del paso 3 y hasta que se complete el paso 4, las bases de datos de la instancia A permanecerán desprotegidas frente a un error catastrófico en la instancia A.
Importante
Cuando se elimina el grupo de conmutación por error, también se eliminan los registros de DNS de los puntos de conexión del agente de escucha. En ese momento, existe una probabilidad distinta de cero de que otra persona cree un grupo de conmutación por error con el mismo nombre. Dado que los nombres de grupo de conmutación por error deben ser únicos globalmente, esto impedirá que vuelva a usar el mismo nombre. Para minimizar este riesgo, no utilice nombres de grupo de conmutación por error genéricos.
Habilitación de escenarios que dependen de objetos de las bases de datos del sistema
Las bases de datos del sistema no se replican en la instancia secundaria de un grupo de conmutación por error. Para habilitar escenarios que dependen de los objetos de las bases de datos del sistema, asegúrese de crear los mismos objetos en la instancia secundaria y mantenerlos sincronizados con la instancia principal.
Por ejemplo, si tiene previsto utilizar los mismos inicios de sesión en la instancia secundaria, asegúrese de crearlos con el SID idéntico.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Para más información, consulte el artículo sobre la replicación de inicios de sesión y trabajos de agente.
Sincronización de las propiedades de instancia y las instancias de directivas de retención
Las instancias de un grupo de conmutación por error siguen siendo recursos de Azure independientes y ningún cambio que se haga en la configuración de la instancia principal se replicará automáticamente en la instancia secundaria. Por ello, asegúrese de realizar todos los cambios relevantes tanto en la instancia principal como en la secundaria. Por ejemplo, si cambia la redundancia del almacenamiento de copia de seguridad o la directiva de retención de copias de seguridad a largo plazo en la instancia principal, asegúrese de cambiarla también en la instancia secundaria.
Escalado de instancias
Puede escalar verticalmente o reducir verticalmente la instancia principal o secundaria a un tamaño de proceso diferente en el mismo nivel de servicio. Cuando se escala verticalmente dentro del mismo nivel de servicio, se recomienda escalar verticalmente primero la secundaria geográfica y, después, escalar verticalmente la principal. Al reducir verticalmente dentro del mismo nivel de servicio, invierta el orden: primero escale verticalmente la principal y, a continuación, escale verticalmente la secundaria. Cuando se escala la instancia a un nivel de servicio diferente, se aplica esta recomendación.
La secuencia se recomienda específicamente para evitar que la base de datos secundaria geográfica de una SKU inferior se sobrecargue y deba reinicializarse durante un proceso de actualización o degradación.
Permisos
Los permisos para un grupo de conmutación por error se administran a través del control de acceso basado en rol de Azure (Azure RBAC).
El acceso de escritura de RBAC de Azure es necesario para crear y administrar grupos de conmutación por error. El rol Colaborador de SQL Managed Instance tiene todos los permisos necesarios para administrar grupos de conmutación por error.
En la tabla siguiente se enumeran los ámbitos de permiso específicos para Azure SQL Managed Instance:
| Acción | Permiso | Ámbito |
|---|---|---|
| Creación de un grupo de conmutación por error | Acceso de escritura de RBAC de Azure | Instancia administrada principal Instancia administrada secundaria |
| Actualización de grupo de conmutación por error | Acceso de escritura de RBAC de Azure | Grupo de conmutación por error Todas las bases de datos dentro de la instancia administrada |
| Conmutación por error de un grupo de conmutación por error | Acceso de escritura de RBAC de Azure | Grupo de conmutación por error en la nueva instancia administrada principal |
Limitaciones
Tenga en cuenta las siguientes limitaciones:
- No se pueden crear grupos de conmutación por error entre dos instancias en la misma región de Azure.
- No se puede cambiar el nombre de los grupos de conmutación por error. Tendrá que eliminar el grupo y volver a crearlo con otro nombre.
- Un grupo de conmutación por error contiene exactamente dos instancias administradas. No se admite la incorporación de instancias adicionales al grupo de conmutación por error.
- Una instancia puede participar en solo un grupo de conmutación por error en cualquier momento.
- No se puede crear un grupo de conmutación por error entre dos instancias que pertenezcan a distintos inquilinos de Azure.
- No se puede crear un grupo de conmutación por error entre dos instancias que pertenezcan a distintas suscripciones de Azure mediante Azure Portal o la CLI de Azure. Use Azure PowerShell o la API REST para crear este grupo de conmutación por error. Una vez creado, el grupo de conmutación por error entre suscripciones es visible regularmente en Azure Portal y todas las operaciones posteriores, incluidas las conmutaciones por error, se pueden iniciar desde Azure Portal o la CLI de Azure.
- No se admiten los cambios de nombre de la base de datos para las bases de datos del grupo de conmutación por error. Tendrás que eliminar temporalmente el grupo de conmutación por error para poder cambiar el nombre a una base de datos.
- Las bases de datos del sistema no se replican en la instancia secundaria de un grupo de conmutación por error. Por lo tanto, los escenarios que dependen de objetos de las bases de datos del sistema, como los inicios de sesión del servidor o los trabajos del agente, necesitan que los objetos se creen manualmente en las instancias secundarias y también que se mantengan sincronizados manualmente después de los cambios realizados en la instancia principal. La única excepción es la clave maestra de servicio (SMK) de SQL Managed Instance, que se replica automáticamente en la instancia secundaria durante la creación del grupo de conmutación por error. Sin embargo, los cambios posteriores de SMK en la instancia principal no se replicarán en la instancia secundaria. Para obtener más información, consulte Habilitación de escenarios que dependen de objetos de las bases de datos del sistema.
- No se pueden crear grupos de conmutación por error entre instancias si alguna de ellas se encuentra en un grupo de instancias.
Administración mediante programación de grupos de conmutación por error
Los grupos de conmutación por error también se pueden administrar mediante programación con Azure PowerShell, la CLI de Azure y la API de REST. En las tablas siguientes se describe el conjunto de comandos disponibles. Los grupos de conmutación por error incluyen un conjunto de API de Azure Resource Manager para la administración, en el que se incluyen la API de REST de Azure SQL Database y los cmdlets de Azure PowerShell. Estas API requieren que se usen grupos de recursos y admiten el control de acceso basado en rol de Azure (Azure RBAC). Para más información sobre cómo implementar los roles de acceso, consulte Control de acceso basado en roles de Azure (Azure RBAC).
| Cmdlet | Descripción |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | Este comando crea un grupo de conmutación por error y lo registra en las instancias principal y secundaria. |
| Set-AzSqlDatabaseInstanceFailoverGroup | Modifica la configuración de un grupo de conmutación por error. |
| Get-AzSqlDatabaseInstanceFailoverGroup | Recupera la configuración de un grupo de conmutación por error. |
| Switch-AzSqlDatabaseInstanceFailoverGroup | Desencadena la conmutación por error de un grupo de conmutación por error en la instancia secundaria. |
| Remove-AzSqlDatabaseInstanceFailoverGroup | Quita un grupo de conmutación por error. |
Pasos siguientes
Si deseas conocer los pasos necesarios para configurar un grupo de conmutación por error, consulta el tutorial Adición de una instancia administrada a un grupo de conmutación por error.
Para obtener información general sobre la característica, consulta Grupos de conmutación por error. Para obtener información sobre cómo ahorrar en los costos de licencias, consulte Configuración de la réplica en espera sin licencia para Azure SQL Managed Instance (versión preliminar).
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de