Kit de procesamiento por lotes para contenedores de voz
Use el kit de procesamiento por lotes para complementar y escalar horizontalmente las cargas de trabajo en los contenedores de voz. Disponible como contenedor, esta utilidad de código abierto ayuda a facilitar la transcripción por lotes de grandes cantidades de archivos de audio, en cualquier número de puntos de conexión de contenedor de voz locales y basados en la nube.
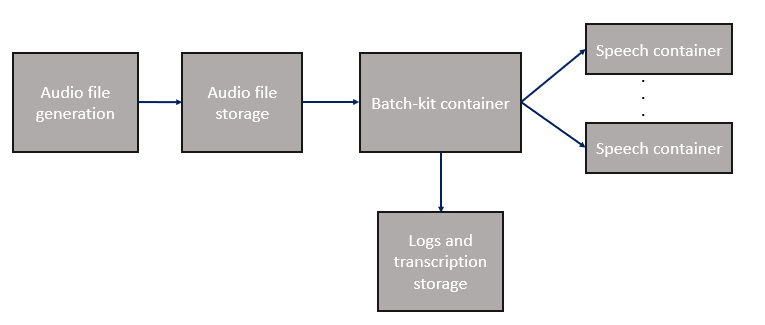
El kit por lote para contenedor está disponible de forma gratuita en GitHub y Docker Hub. Solo se le facturarán los contenedores de Voz que utilice.
| Característica | Descripción |
|---|---|
| Distribución de archivos de audio por lotes | Envíe automáticamente un gran número de archivos a los puntos de conexión de contenedor de voz locales o basados en la nube. Los archivos pueden estar en cualquier volumen compatible con POSIX, incluidos los sistemas de archivos de red. |
| Integración de SDK de voz | Pase las marcas comunes al SDK de voz, incluidos los siguientes supuestos, diarización, lenguaje, enmascaramiento de blasfemias. |
| Modos de ejecución | Ejecute el lote del cliente una vez, continuamente en segundo plano, o cree puntos de conexión HTTP para los archivos de audio. |
| Tolerancia a errores | Reintentar y continuar automáticamente la transcripción sin perder el progreso y diferenciar entre los errores que se pueden y no se pueden repetir. |
| Detección de disponibilidad de punto de conexión | Si un punto de conexión deja de estar disponible, el cliente del lote continúa la transcripción, con otros puntos de conexión del contenedor. Cuando el cliente está disponible, comienza automáticamente a usar el punto de conexión. |
| Intercambio frecuente del punto de conexión | Agregar, quitar o editar los puntos de conexión del contenedor de voz durante el tiempo de ejecución sin interrumpir el progreso del lote. Las actualizaciones son inmediatas. |
| Registro en tiempo real | Registro en tiempo real de los intentos de solicitud, las marcas de tiempo y los motivos de error, con archivos de registro del SDK de voz para cada archivo de audio. |
Obtención de la imagen del contenedor con docker pull
Use el comando docker pull para descargar el contenedor del kit de lote más reciente.
Nota
En el ejemplo siguiente se extrae una imagen de contenedor público de Docker Hub. Se recomienda autenticarse primero con la cuenta de Docker Hub (docker login) en lugar de realizar una solicitud de extracción anónima. Para mejorar la confiabilidad al usar contenido público, importe y administre la imagen en un registro de contenedor privado de Azure. Más información sobre cómo trabajar con imágenes públicas.
docker pull docker.io/batchkit/speech-batch-kit:latest
Configuración de punto de conexión
El cliente del lote toma un archivo de configuración YAML que especifica los puntos de conexión del contenedor local. El ejemplo siguiente se puede escribir en /mnt/my_nfs/config.yaml, que se usa en los ejemplos siguientes.
MyContainer1:
concurrency: 5
host: 192.168.0.100
port: 5000
rtf: 3
MyContainer2:
concurrency: 5
host: BatchVM0.corp.redmond.microsoft.com
port: 5000
rtf: 2
MyContainer3:
concurrency: 10
host: localhost
port: 6001
rtf: 4
Este ejemplo de YAML especifica tres contenedores de voz en tres hosts. El primer host está especificado por una dirección IPv4, el segundo se ejecuta en la misma VM que el lote del cliente y el tercer contenedor está especificado por el nombre de host DNS de otra VM. El valor concurrency especifica el número máximo de transcripciones de archivos simultáneas que se pueden ejecutar en el mismo contenedor. El valor rtf (factor en tiempo real) es opcional y se puede usar para optimizar el rendimiento.
El lote del cliente puede detectar dinámicamente si un punto de conexión deja de estar disponible (por ejemplo, debido a un reinicio del contenedor o un problema de red) y cuando vuelve a estar disponible. Las solicitudes de transcripción no se enviarán a los contenedores que no estén disponibles y el cliente sigue usando otros contenedores disponibles. Puede agregar, quitar o editar los puntos de conexión en cualquier momento sin interrumpir el progreso del lote.
Ejecutar el contenedor de procesamiento por lotes
Nota
- Este ejemplo utiliza el mismo directorio (
/my_nfs) para el archivo de configuración y los directorios de entradas, salidas y registros. Puede usar directorios hospedados o NFS montados para estas carpetas. - Al ejecutar el cliente con la marca
–h, se enumeran los parámetros de la línea de comandos disponibles y sus valores predeterminados. - El contenedor de procesamiento por lotes solo se admite en Linux.
Utilice el comando run de Docker para iniciar el contenedor. Esta comando inicia un shell interactivo dentro del contenedor.
docker run --network host --rm -ti -v /mnt/my_nfs:/my_nfs --entrypoint /bin/bash /mnt/my_nfs:/my_nfs docker.io/batchkit/speech-batch-kit:latest
Para ejecutar el lote cliente:
run-batch-client -config /my_nfs/config.yaml -input_folder /my_nfs/audio_files -output_folder /my_nfs/transcriptions -log_folder /my_nfs/logs -file_log_level DEBUG -nbest 1 -m ONESHOT -diarization None -language en-US -strict_config
Para ejecutar el lote cliente y el contenedor en un solo comando:
docker run --network host --rm -ti -v /mnt/my_nfs:/my_nfs docker.io/batchkit/speech-batch-kit:latest -config /my_nfs/config.yaml -input_folder /my_nfs/audio_files -output_folder /my_nfs/transcriptions -log_folder /my_nfs/logs
El cliente comienza a ejecutarse. Si ya se transformó un archivo de audio en una ejecución anterior, el cliente omite automáticamente el archivo. Los archivos se envían con un reintento automático si se producen errores transitorios y puede diferenciar entre los errores en los que desea que el cliente vuelva a intentarlo. En un error de transcripción, el cliente sigue la transcripción y puede volver a intentarlo sin perder el progreso.
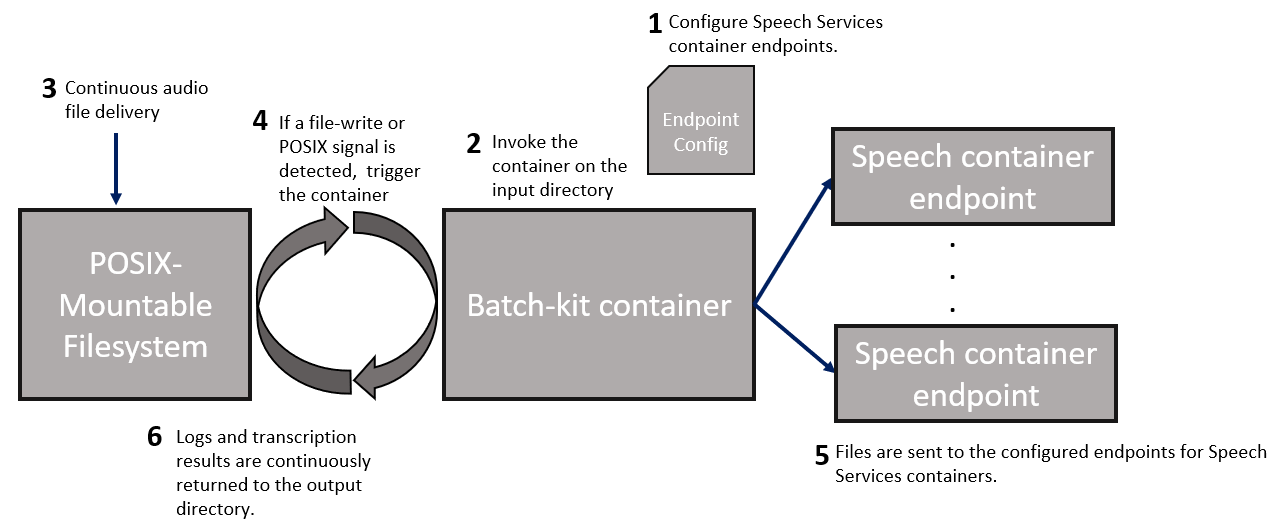
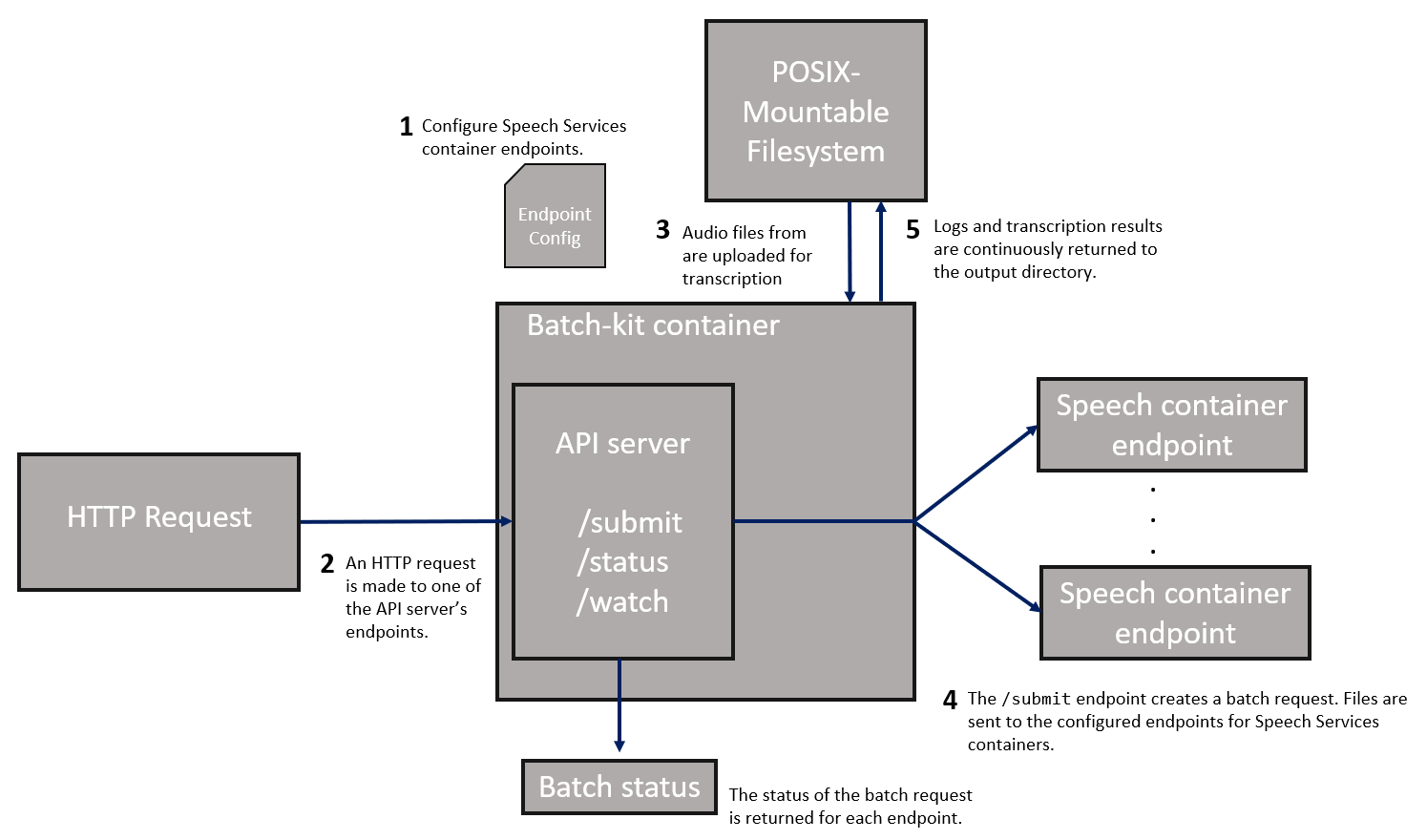
Modos de ejecución
El kit de procesamiento por lotes ofrece tres modos, mediante el parámetro --run-mode.
El modo ONESHOT transcribe un solo lote de archivos de audio (de un directorio de entrada y una lista de archivos opcional) a una carpeta de salida.
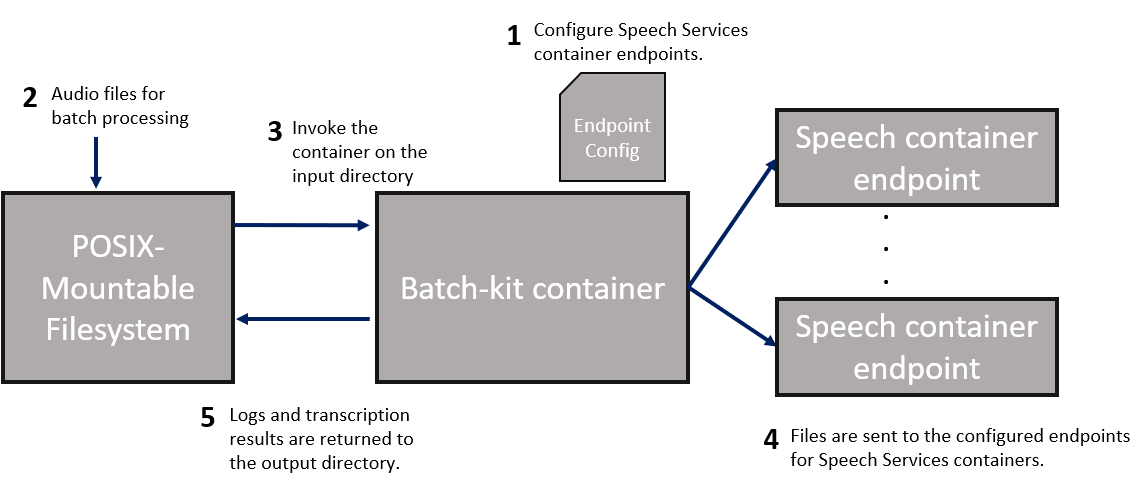
- Defina los puntos de conexión del contenedor de Voz que el cliente de lote usa en el archivo
config.yaml. - Coloque los archivos de audio para la transcripción en un directorio de entrada.
- Invoque el contenedor en el directorio para iniciar el procesamiento de los archivos. Si el archivo de audio ya ha sido transcrito en una ejecución anterior con el mismo directorio de salida (mismo nombre de archivo y suma de comprobación), el cliente omite el archivo.
- Los archivos se envían a los puntos de conexión del contenedor del paso 1.
- Los registros y la salida del contenedor de voz se devuelven al directorio de salida especificado.
Registro
Nota
El cliente de lote puede sobrescribir el archivo run.log periódicamente si es demasiado grande.
El cliente crea un archivo run.log en el directorio especificado por el argumento -log_folder en el comando run de Docker. Los registros se capturan en el nivel de depuración de forma predeterminada. Los mismos registros se envían al stdout/stderr y se filtran según los argumentos -file_log_level o console_log_level. Este registro solo es necesario para la depuración o si necesita enviar un seguimiento para la compatibilidad. La carpeta de registro también contiene los registros del SDK de voz para cada archivo de audio.
El directorio de salida especificado por -output_folder contiene un archivo run_summary.json, que se reescribe periódicamente cada 30 segundos o cada vez que se terminan nuevas transcripciones. Puede usar este archivo para comprobar el progreso a medida que el lote continúa. También contiene las estadísticas de ejecución finales y el estado final de todos los archivos cuando se completa el lote. El lote se completa cuando el proceso tiene una salida limpia.