Eventos
31 mar, 23 - 2 abr, 23
Evento de aprendizaje de Fabric, Power BI y SQL más grande. 31 de marzo – 2 de abril. Use el código FABINSIDER para ahorrar $400.
Regístrate hoyEste explorador ya no se admite.
Actualice a Microsoft Edge para aprovechar las características y actualizaciones de seguridad más recientes, y disponer de soporte técnico.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Este artículo se aplica a los conectores siguientes: Amazon S3, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP y SFTP.
Importante
El servicio ha presentado el nuevo modelo de conjuntos de datos basado en formato. Consulte el artículo sobre formato correspondiente con los detalles:
-
Formato Avro
-
Formato binario
-
Formato de texto delimitado
-
Formato JSON
-
Formato ORC
-
Formato Parquet
Todavía se admiten el resto de configuraciones mencionadas en este artículo tal y como están por motivos de compatibilidad con versiones anteriores. Se sugiere usar el nuevo modelo de aquí en adelante.
Nota
Obtenga información sobre el nuevo modelo en el artículo Formato de texto delimitado. Todavía se admiten las siguientes configuraciones en el conjunto de datos basado en archivo, porque cuentan con compatibilidad con versiones anteriores. Se sugiere usar el nuevo modelo de aquí en adelante.
Si quiere leer un archivo de texto o escribir en él, establezca la propiedad type de la sección format del conjunto de datos en TextFormat. También puede especificar las siguientes propiedades opcionales en la sección format. Consulte la sección Ejemplo de TextFormat sobre cómo realizar la configuración.
| Propiedad | Descripción | Valores permitidos | Obligatorio |
|---|---|---|---|
| columnDelimiter | El carácter utilizado para separar las columnas en un archivo. Puede considerar el uso de un carácter imprimible poco frecuente que es probable que no exista en sus datos. Por ejemplo, especifique "\u0001", que representa el inicio de encabezado (SOH). | Solo se permite un carácter. El valor predeterminado es coma (",") . Para usar un carácter Unicode, consulte la lista de caracteres Unicode para obtener el código correspondiente. |
No |
| rowDelimiter | carácter utilizado para separar filas en un archivo. | Solo se permite un carácter. El valor predeterminado es cualquiera de los siguientes en lectura: ["\r\n", "\r", "\n"] y "\r\n" en escritura. | No |
| escapeChar | carácter especial utilizado para aplicar una secuencia de escape a un delimitador de columna en el contenido de un archivo de entrada. No puede especificar ambos valores escapeChar y quoteChar para una tabla. |
Solo se permite un carácter. Ningún valor predeterminado. Ejemplo: si usa la coma (",") como delimitador de columna, pero quiere tener el carácter de coma en el texto (ejemplo: "Hello, world"), puede definir "$" como carácter de escape y usar la cadena "Hello$, world" en el origen. |
No |
| quoteChar | carácter utilizado para citar el valor de una cadena. Los delimitadores de columna y fila de dentro de las comillas se tratan como parte del valor de la cadena. Esta propiedad es aplicable tanto al conjunto de datos de entrada como al de salida. No puede especificar ambos valores escapeChar y quoteChar para una tabla. |
Solo se permite un carácter. Ningún valor predeterminado. Por ejemplo, si tiene la coma (",") como delimitador de columna, pero quiere tener el carácter de coma en el texto (por ejemplo: <Hello, world>), puede definir " (comillas dobles) como comillas y usar la cadena "Hello, world" en el origen. |
No |
| nullValue | uno o varios caracteres empleados para representar un valor nulo. | Uno o más caracteres. Los valores predeterminados son "\N" y "NULL" en lectura y "\N" en escritura. | No |
| encodingName | permite especificar el nombre de la codificación. | Un nombre de codificación válido. Consulte la propiedad Encoding.EncodingName. Por ejemplo: windows-1250 o shift_jis. El valor predeterminado es UTF-8. | No |
| firstRowAsHeader | Especifica si se tendrá en cuenta la primera fila como encabezado. Para un conjunto de datos de entrada, el servicio lee la primera fila como encabezado. Para un conjunto de datos de salida, el servicio escribe la primera fila como encabezado. Consulte Escenarios de uso firstRowAsHeader y skipLineCount para ver ejemplos de escenarios. |
True False (valor predeterminado) |
No |
| skipLineCount | Indica el número de filas no vacías que se omitirán al leer datos de archivos de entrada. Si se especifican ambos valores skipLineCount y firstRowAsHeader, las líneas se omiten primero y, luego, la información del encabezado se lee a partir del archivo de entrada. Consulte Escenarios de uso firstRowAsHeader y skipLineCount para ver ejemplos de escenarios. |
Entero | No |
| treatEmptyAsNull | permite especificar si hay que tratar una cadena nula o vacía como un valor nulo al leer datos de un archivo de entrada. |
True (predeterminado) False |
No |
En la siguiente definición JSON de un conjunto de datos, se especifican algunas propiedades opcionales.
"typeProperties":
{
"folderPath": "mycontainer/myfolder",
"fileName": "myblobname",
"format":
{
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": ";",
"quoteChar": "\"",
"NullValue": "NaN",
"firstRowAsHeader": true,
"skipLineCount": 0,
"treatEmptyAsNull": true
}
},
Para usar un escapeChar en lugar de quoteChar, reemplace la línea con quoteChar por el siguiente escapeChar:
"escapeChar": "$",
firstRowAsHeader como true en el conjunto de datos de salida de este escenario.firstRowAsHeader como true en el conjunto de datos de entrada.skipLineCount para indicar el número de líneas que se omitirá. Si el resto del archivo contiene una línea de encabezado, también puede especificar firstRowAsHeader. Si se especifican skipLineCount y firstRowAsHeader, las líneas se omiten primero y luego la información del encabezado se lee del archivo de entrada.Nota
Obtenga información sobre el nuevo modelo en el artículo Formato JSON. Todavía se admiten las siguientes configuraciones en el conjunto de datos basado en archivo, porque cuentan con compatibilidad con versiones anteriores. Se sugiere usar el nuevo modelo de aquí en adelante.
Para importar o exportar un archivo JSON como está en Azure Cosmos DB, consulte la sección sobre la importación o exportación de documentos JSON en el artículo Move data to/from Azure Cosmos DB (Movimiento de datos a y desde Azure Cosmos DB).
Si quiere analizar los archivos JSON o escribir los datos en formato JSON, establezca la propiedad typeformat en JsonFormat. También puede especificar las siguientes propiedades opcionales en la sección format. Consulte la sección Ejemplo de JsonFormat sobre cómo realizar la configuración.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| filePattern | Indica el patrón de los datos almacenados en cada archivo JSON. Estos son los valores permitidos: setOfObjects y arrayOfObjects. El valor predeterminado es setOfObjects. Consulte la sección patrones de archivo JSON para obtener más información acerca de estos patrones. | No |
| jsonNodeReference | Si desea iterar y extraer datos de los objetos dentro de un campo de matriz con el mismo patrón, especifique la ruta de acceso JSON de esa matriz. Esta propiedad se admite solo cuando se copian datos desde los archivos JSON. | No |
| jsonPathDefinition | Especifique la expresión de ruta de acceso JSON para cada asignación de columna con un nombre de columna personalizado (que empiece con minúscula). Esta propiedad se admite solo cuando se copian datos desde archivos JSON y puede extraer datos del objeto o matriz. Para los campos en el objeto raíz, comience por root $; para los campos dentro de la matriz elegida mediante la propiedad jsonNodeReference, empiece desde el elemento de matriz. Consulte la sección Ejemplo de JsonFormat sobre cómo realizar la configuración. |
No |
| encodingName | permite especificar el nombre de la codificación. Para obtener la lista de nombres de codificación válidos, consulte la propiedad Encoding.EncodingName. Por ejemplo: windows-1250 o shift_jis. El valor predeterminado es: UTF-8. | No |
| nestingSeparator | Carácter que se usa para separar los niveles de anidamiento. El valor predeterminado es '.' (punto). | No |
Nota
En caso de la aplicación cruzada de los datos en la matriz en varias filas (caso 1 -> ejemplo 2 en los ejemplos de JsonFormat), solo puede elegir expandir la matriz con la propiedad jsonNodeReference.
La actividad de copia puede analizar los siguientes patrones de archivos JSON:
Tipo I: setOfObjects
Cada archivo contiene un único objeto o bien varios objetos concatenados/delimitados por líneas. Si se elige esta opción en un conjunto de datos de salida, la actividad de copia genera un único archivo JSON con cada objeto por línea (delimitado por líneas).
ejemplo de JSON de objeto único
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
}
ejemplo de JSON delimitado por líneas
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
ejemplo de JSON concatenado
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
}
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
}
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
Tipo II: arrayOfObjects
Cada archivo contiene una matriz de objetos.
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Caso 1: Copia de datos desde archivos JSON
Ejemplo 1: extracción de datos de objeto y matriz
En esta ejemplo, se espera un objeto JSON de raíz que se asigna al registro individual en resultado tabulares. Si tiene un archivo JSON con el siguiente contenido:
{
"id": "ed0e4960-d9c5-11e6-85dc-d7996816aad3",
"context": {
"device": {
"type": "PC"
},
"custom": {
"dimensions": [
{
"TargetResourceType": "Microsoft.Compute/virtualMachines"
},
{
"ResourceManagementProcessRunId": "827f8aaa-ab72-437c-ba48-d8917a7336a3"
},
{
"OccurrenceTime": "1/13/2017 11:24:37 AM"
}
]
}
}
}
y quiere copiarlo en una tabla de SQL de Azure con el formato siguiente extrayendo datos tanto de los objetos como de la matriz:
| ID | deviceType | targetResourceType | resourceManagementProcessRunId | occurrenceTime |
|---|---|---|---|---|
| ed0e4960-d9c5-11e6-85dc-d7996816aad3 | PC | Microsoft.Compute/virtualMachines | 827f8aaa-ab72-437c-ba48-d8917a7336a3 | 1/13/2017 11:24:37 AM |
El conjunto de datos de entrada con el tipo JsonFormat se define de la siguiente manera: (definición parcial en la que solo se ilustran las secciones relevantes). Más concretamente:
structure permite definir los nombres personalizados de columna y el tipo de datos correspondiente mientras los convierte a datos tabulares. Esta sección es opcional a menos que necesite realizar una asignación de columnas. Consulte la sección Asignación de columnas de conjunto de datos de origen a columnas del conjunto de datos de destino para más información.jsonPathDefinition especifica la ruta de acceso JSON para cada columna que indica de dónde se deben extraer los datos. Para copiar datos de la matriz, puede usar array[x].property para extraer el valor de la propiedad dada del objeto xth, o puede usar array[*].property para buscar el valor de cualquier objeto que contenga dicha propiedad."properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "deviceType",
"type": "String"
},
{
"name": "targetResourceType",
"type": "String"
},
{
"name": "resourceManagementProcessRunId",
"type": "String"
},
{
"name": "occurrenceTime",
"type": "DateTime"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonPathDefinition": {"id": "$.id", "deviceType": "$.context.device.type", "targetResourceType": "$.context.custom.dimensions[0].TargetResourceType", "resourceManagementProcessRunId": "$.context.custom.dimensions[1].ResourceManagementProcessRunId", "occurrenceTime": " $.context.custom.dimensions[2].OccurrenceTime"}
}
}
}
Ejemplo 2: aplicación cruzada en varios objetos del mismo patrón de matriz
En este ejemplo, se espera transformar un objeto JSON de raíz en varios registros en resultado tabular. Si tiene un archivo JSON con el siguiente contenido:
{
"ordernumber": "01",
"orderdate": "20170122",
"orderlines": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "sanmateo": "No 1" } ]
}
y desea copiarlo en una tabla de Azure SQL del formato siguiente, puede hacerlo mediante el acoplamiento de los datos dentro de la matriz y la combinación cruzada con la información de la raíz habitual:
ordernumber |
orderdate |
order_pd |
order_price |
city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P2 | 13 | [{"sanmateo":"No 1"}] |
| 01 | 20170122 | P3 | 231 | [{"sanmateo":"No 1"}] |
El conjunto de datos de entrada con el tipo JsonFormat se define de la siguiente manera: (definición parcial en la que solo se ilustran las secciones relevantes). Más concretamente:
structure permite definir los nombres personalizados de columna y el tipo de datos correspondiente mientras los convierte a datos tabulares. Esta sección es opcional a menos que necesite realizar una asignación de columnas. Consulte la sección Asignación de columnas de conjunto de datos de origen a columnas del conjunto de datos de destino para más información.jsonNodeReference indica la iteración y extracción de datos de los objetos con el mismo patrón en la matrizorderlines.jsonPathDefinition especifica la ruta de acceso JSON para cada columna que indica de dónde se deben extraer los datos. En este ejemplo, ordernumber, orderdate y city están bajo el objeto raíz con la ruta de acceso JSON que empieza por $., mientras que order_pd y order_price se definen con la ruta de acceso que se obtiene del elemento de matriz sin $.."properties": {
"structure": [
{
"name": "ordernumber",
"type": "String"
},
{
"name": "orderdate",
"type": "String"
},
{
"name": "order_pd",
"type": "String"
},
{
"name": "order_price",
"type": "Int64"
},
{
"name": "city",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat",
"filePattern": "setOfObjects",
"jsonNodeReference": "$.orderlines",
"jsonPathDefinition": {"ordernumber": "$.ordernumber", "orderdate": "$.orderdate", "order_pd": "prod", "order_price": "price", "city": " $.city"}
}
}
}
Tenga en cuenta los siguientes puntos:
structure y jsonPathDefinition en el conjunto de datos, la actividad de copia detecta el esquema del primer objeto y acopla el objeto en su conjunto.jsonNodeReference o jsonPathDefinition, u omitir la extracción no especificándolo en jsonPathDefinition.Caso 2: Escritura de datos en el archivo JSON
Si tiene la siguiente tabla en SQL Database:
| ID | order_date | order_price | order_by |
|---|---|---|---|
| 1 | 20170119 | 2000 | David |
| 2 | 20170120 | 3500 | Patrick |
| 3 | 20170121 | 4000 | Jason |
y para cada registro, espera escribir en un objeto JSON con el formato siguiente:
{
"id": "1",
"order": {
"date": "20170119",
"price": 2000,
"customer": "David"
}
}
El conjunto de datos de salida con el tipo JsonFormat se define de la siguiente manera: (definición parcial en la que solo se ilustran las secciones relevantes). Más concretamente, la sección structure permite definir los nombres de propiedad personalizados en el archivo de destino y nestingSeparator (el valor predeterminado es ".") se usa para identificar el nivel de anidamiento del nombre. Esta sección es opcional a menos que desee cambiar el nombre de la propiedad comparándolo con el nombre de la columna de origen, o anidar algunas de las propiedades.
"properties": {
"structure": [
{
"name": "id",
"type": "String"
},
{
"name": "order.date",
"type": "String"
},
{
"name": "order.price",
"type": "Int64"
},
{
"name": "order.customer",
"type": "String"
}
],
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"format": {
"type": "JsonFormat"
}
}
}
Nota
Obtenga información sobre el nuevo modelo en el artículo Formato Parquet. Todavía se admiten las siguientes configuraciones en el conjunto de datos basado en archivo, porque cuentan con compatibilidad con versiones anteriores. Se sugiere usar el nuevo modelo de aquí en adelante.
Si quiere analizar los archivos Parquet o escribir los datos en formato Parquet, establezca la propiedad formattype en ParquetFormat. No es preciso especificar propiedades en la sección Format de la sección typeProperties. Ejemplo:
"format":
{
"type": "ParquetFormat"
}
Tenga en cuenta los siguientes puntos:
Importante
En el caso de las copias autorizadas por el entorno de ejecución de integración (IR) autohospedado (por ejemplo, entre almacenes de datos locales y almacenes de datos en la nube), si no va a copiar archivos Parquet tal y como están, tendrá que instalar JRE (Java Runtime Environment) 8 de 64 bits u OpenJDK en la máquina de IR. Consulte el párrafo siguiente para más información.
En el caso de las copias que se ejecutan en el IR autohospedado con la serialización o deserialización de archivos Parquet, para buscar el entorno de ejecución de Java, el servicio consulta primero el Registro (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) en busca de JRE; si no lo encuentra, comprueba la variable del sistema JAVA_HOME de OpenJDK.
Sugerencia
Si copia datos desde o hacia Parquet mediante Integration Runtime autohospedado y recibe un error que indica que "Se produjo un error al invocar Java, mensaje: Espacio en el montón java.lang.OutOfMemoryError:Java", puede agregar una variable de entorno _JAVA_OPTIONS en la máquina que hospeda IR autohospedado para ajustar el tamaño del montón mínimo y máximo para JVM a fin de facilitar dicha copia y, a continuación, volver a ejecutar la canalización.
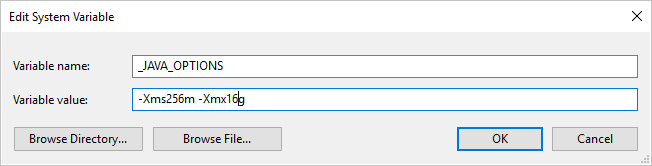
Ejemplo: establecimiento de la variable _JAVA_OPTIONS con el valor -Xms256m -Xmx16g. La marca Xms especifica el grupo de asignación de memoria inicial para una máquina virtual Java (JVM), mientras que Xmx especifica el grupo de asignación de memoria máxima. Esto significa que JVM se iniciará con la cantidad de memoria Xms y podrá utilizar Xmx como máximo. De manera predeterminada, el servicio usa un mínimo de 64 MB y un máximo de 1 G.
| Tipo de datos de servicio provisional | Tipo primitivo PARQUET | Tipo original PARQUET (deserializar) | Tipo original PARQUET (serializar) |
|---|---|---|---|
| Boolean | Boolean | N/D | N/D |
| SByte | Int32 | Int8 | Int8 |
| Byte | Int32 | UInt8 | Int16 |
| Int16 | Int32 | Int16 | Int16 |
| UInt16 | Int32 | UInt16 | Int32 |
| Int32 | Int32 | Int32 | Int32 |
| UInt32 | Int64 | UInt32 | Int64 |
| Int64 | Int64 | Int64 | Int64 |
| UInt64 | Int64/binario | UInt64 | Decimal |
| Single | Float | N/D | N/D |
| Double | Double | N/D | N/D |
| Decimal | Binary | Decimal | Decimal |
| String | Binary | Utf8 | Utf8 |
| DateTime | Int96 | N/D | N/D |
| TimeSpan | Int96 | N/D | N/D |
| DateTimeOffset | Int96 | N/D | N/D |
| ByteArray | Binary | N/D | N/D |
| Guid | Binary | Utf8 | Utf8 |
| Char | Binary | Utf8 | Utf8 |
| CharArray | No compatible | N/D | N/D |
Nota
Obtenga información sobre el nuevo modelo en el artículo Formato ORC. Todavía se admiten las siguientes configuraciones en el conjunto de datos basado en archivo, porque cuentan con compatibilidad con versiones anteriores. Se sugiere usar el nuevo modelo de aquí en adelante.
Si quiere analizar los archivos ORC o escribir los datos en formato ORC, establezca la propiedad formattype en OrcFormat. No es preciso especificar propiedades en la sección Format de la sección typeProperties. Ejemplo:
"format":
{
"type": "OrcFormat"
}
Tenga en cuenta los siguientes puntos:
Importante
En el caso de las copias autorizadas por el entorno de ejecución de integración (IR) autohospedado (por ejemplo, entre almacenes de datos locales y almacenes de datos en la nube), si no va a copiar archivos ORC tal y como están, tendrá que instalar JRE (Java Runtime Environment) 8 de 64 bits u OpenJDK en la máquina de IR. Consulte el párrafo siguiente para más información.
En el caso de las copias que se ejecutan en el IR autohospedado con la serialización o deserialización de archivos ORC, para buscar el entorno de ejecución de Java, el servicio consulta primero el Registro (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) en busca de JRE; si no lo encuentra, comprueba la variable del sistema JAVA_HOME de OpenJDK.
| Tipo de datos de servicio provisional | Tipos ORC |
|---|---|
| Boolean | Boolean |
| SByte | Byte |
| Byte | Short |
| Int16 | Short |
| UInt16 | Int |
| Int32 | Int |
| UInt32 | long |
| Int64 | long |
| UInt64 | String |
| Single | Float |
| Double | Double |
| Decimal | Decimal |
| String | String |
| DateTime | Timestamp |
| DateTimeOffset | Timestamp |
| TimeSpan | Timestamp |
| ByteArray | Binary |
| Guid | String |
| Char | Char(1) |
Nota
Obtenga información sobre el nuevo modelo en el artículo Formato Avro. Todavía se admiten las siguientes configuraciones en el conjunto de datos basado en archivo, porque cuentan con compatibilidad con versiones anteriores. Se sugiere usar el nuevo modelo de aquí en adelante.
Si quiere analizar los archivos Avro o escribir los datos en formato Avro, establezca la propiedad formattype en AvroFormat. No es preciso especificar propiedades en la sección Format de la sección typeProperties. Ejemplo:
"format":
{
"type": "AvroFormat",
}
Para usar el formato Avro en una tabla de Hive, puede consultar Tutorial de Apache Hive.
Tenga en cuenta los siguientes puntos:
El servicio admite la compresión y descompresión de datos durante la copia. Cuando se especifica la propiedad compression en un conjunto de datos de entrada, la actividad de copia lee los datos comprimidos del origen y los descomprime; y cuando se especifica la propiedad en un conjunto de datos de salida, la actividad de copia comprime los datos y luego los escribe en el receptor. Estos son algunos escenarios de ejemplo:
compressiontype como GZIP.compressiontype como GZIP.compressiontype como ZipDeflate.compressiontype establecido en GZIP y el conjunto de datos de salida con compressiontype establecido en BZIP2.Para especificar la compresión para un conjunto de datos, use la propiedad compression del conjunto de datos JSON como en el ejemplo siguiente:
{
"name": "AzureBlobDataSet",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "StorageLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"fileName": "pagecounts.csv.gz",
"folderPath": "compression/file/",
"format": {
"type": "TextFormat"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
La sección compression tiene dos propiedades:
Type: el códec de compresión, que puede ser GZIP, Deflate o BZIP2 o ZipDeflate. Tenga en cuenta que cuando utilice la actividad de copia para descomprimir archivos ZipDeflate y escribir en el almacén de datos de receptores basado en archivos, los archivos se extraerán a la carpeta <path specified in dataset>/<folder named as source zip file>/.
Level: la relación de compresión, que puede ser Optimal o Fastest.
Fastest: la operación de compresión debe completarse tan pronto como sea posible, incluso si el archivo resultante no se comprime de forma óptima.
Optimal: la operación de compresión se debe comprimir óptimamente, incluso si tarda más tiempo en completarse.
Para más información, consulte el tema Nivel de compresión .
Nota
La configuración de la compresión no se admite para los datos con los formatos AvroFormat, OrcFormat o ParquetFormat. Al leer archivos en estos formatos, el servicio detecta y usa el códec de compresión en los metadatos. Pero, al escribir en archivos en estos formatos, el servicio elige el códec de compresión predeterminado para ese formato. Por ejemplo, ZLIB en el caso de OrcFormat y SNAPPY en el caso de ParquetFormat.
Puede usar las características de extensibilidad para transformar los archivos que no son compatibles. Las dos opciones incluyen Azure Functions y las tareas personalizadas con Azure Batch.
Puede ver un ejemplo que usa una función de Azure para extraer el contenido de un archivo tar. Para más información, consulte la actividad de Azure Functions.
También puede crear esta funcionalidad a través de una actividad de DotNet personalizada. Aquí hay disponible más información
Obtenga información sobre los formatos de archivo y las compresiones admitidos más recientes en Compresiones y formatos de archivo compatibles.
Eventos
31 mar, 23 - 2 abr, 23
Evento de aprendizaje de Fabric, Power BI y SQL más grande. 31 de marzo – 2 de abril. Use el código FABINSIDER para ahorrar $400.
Regístrate hoyCursos
Módulo
Transformación a escala sin código con Azure Data Factory - Training
Realización de transformaciones sin código a escala con Azure Data Factory o una canalización de Azure Synapse
Documentación
En este tema se describen los formatos de archivo y los códigos de compresión que admite las actividad de copia en Azure Data Factory y Azure Synapse Analytics.
Actividad de copia - Azure Data Factory & Azure Synapse
Obtenga información sobre la actividad de copia de Azure Data Factory y Azure Synapse Analytics. Puede usarla para copiar datos de un almacén de datos de origen admitido a un almacén de datos receptor compatible.
Formato de texto delimitado en Azure Data Factory - Azure Data Factory & Azure Synapse
En este tema se describe cómo tratar el formato de texto delimitado en Azure Data Factory y Azure Synapse Analytics.