Eventos
31 mar, 23 - 2 abr, 23
Evento de aprendizaje de Fabric, Power BI y SQL más grande. 31 de marzo – 2 de abril. Use el código FABINSIDER para ahorrar $400.
Regístrate hoyEste explorador ya no se admite.
Actualice a Microsoft Edge para aprovechar las características y actualizaciones de seguridad más recientes, y disponer de soporte técnico.
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, creará una factoría de datos mediante la interfaz de usuario (UI) de Azure Data Factory. La canalización de esta factoría de datos copia los datos desde Azure Blob Storage hasta una base de datos de Azure SQL Database. El patrón de configuración de este tutorial se aplica a la copia de un almacén de datos basado en archivos a un almacén de datos relacional. Para obtener una lista de los almacenes de datos que se admiten como orígenes y receptores, consulte la tabla de almacenes de datos admitidos.
Nota
Si no está familiarizado con Data Factory, consulte Introducción a Azure Data Factory.
En este tutorial, realizará los siguientes pasos:
Ahora, prepare su almacenamiento de blobs y su base de datos SQL para el tutorial mediante los pasos siguientes:
Inicie el Bloc de notas. Copie el texto siguiente y guárdelo como un archivo emp.txt en el disco:
FirstName,LastName
John,Doe
Jane,Doe
Cree un contenedor denominado adftutorial en su instancia de Blob Storage. Cree una carpeta denominada input en este contenedor. A continuación, cargue el archivo emp.txt en la carpeta input. Use Azure Portal o herramientas como Explorador de Azure Storage para realizar estas tareas.
Use el siguiente script de SQL para crear la tabla dbo.emp en la base de datos:
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Permita que los servicios de Azure accedan a SQL Server. Asegúrese de que Permitir el acceso a servicios de Azure esté Activado para SQL Server de forma que Data Factory pueda escribir datos en su instancia de SQL Server. Para comprobar y activar esta configuración, vaya al servidor SQL lógico > Información general > > Establecer el firewall del servidor > y establezca la opción Permitir el acceso a servicios de Azure en Activada.
En este paso, creará una factoría de datos e iniciará la interfaz de usuario de Data Factory para crear una canalización en la factoría de datos.
Abra Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory.
En la página Create Data Factory (Crear factoría de datos), en la pestaña Aspectos básicos, seleccione la suscripción de Azure en la que desea crear la factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
a. Seleccione un grupo de recursos existente de la lista desplegable.
b. Seleccione Crear nuevo y escriba el nombre de un nuevo grupo de recursos.
Para más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
En Región, seleccione una ubicación para la factoría de datos. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) que usa la factoría de datos pueden estar en otras regiones.
En Nombre, escriba ADFTutorialDataFactory.
El nombre de la instancia de Azure Data Factory debe ser único de forma global. Si recibe un mensaje de error sobre el valor de nombre, escriba un nombre diferente para la factoría de datos. (Por ejemplo, utilice SuNombreADFTutorialDataFactory). Para conocer las reglas de nomenclatura de los artefactos de Data Factory, consulte Azure Data Factory: reglas de nomenclatura.
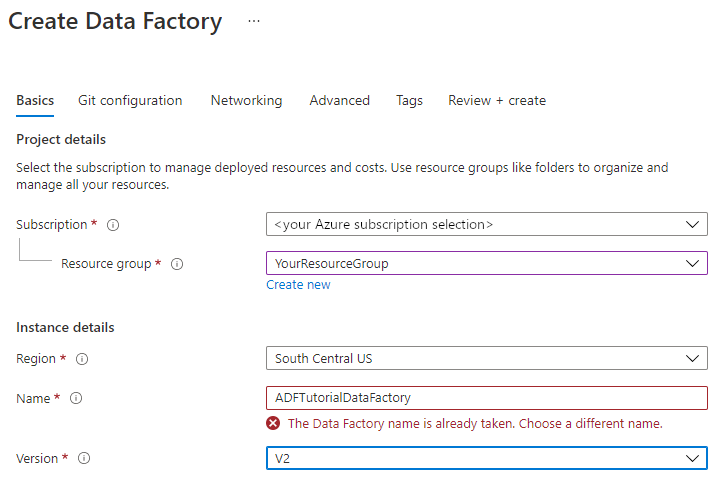
En Versión, seleccione V2.
Seleccione la pestaña Git configuration (Configuración de Git) arriba y active la casilla Configure Git later (Configurar Git más tarde).
Seleccione Revisar y crear y elija Crear una vez superada la validación.
Una vez finalizada la creación, verá el aviso en el centro de notificaciones. Seleccione Ir al recurso para ir a la página de Data Factory.
Seleccione Abrir en el icono Abrir Azure Data Factory Studio para iniciar la interfaz de usuario de Azure Data Factory en una pestaña independiente.
En este paso, creará una canalización con una actividad de copia en la factoría de datos. La actividad de copia realiza la copia de los datos de Blob Storage a SQL Database. En el tutorial de inicio rápido,creó una canalización mediante estos pasos:
En este tutorial, comenzará a crear la canalización. A continuación, creará servicios vinculados y conjuntos de datos cuando los necesite para configurar la canalización.
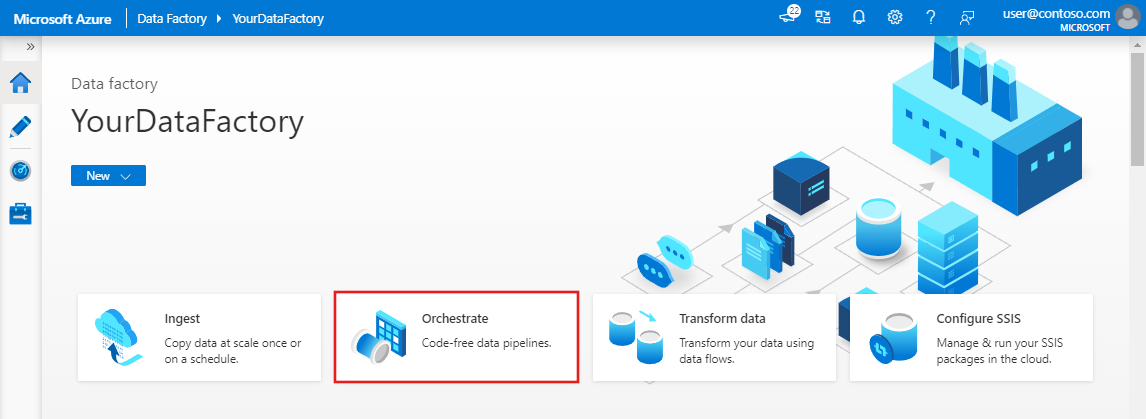
En la página principal, seleccione Orchestrate (Organizar).
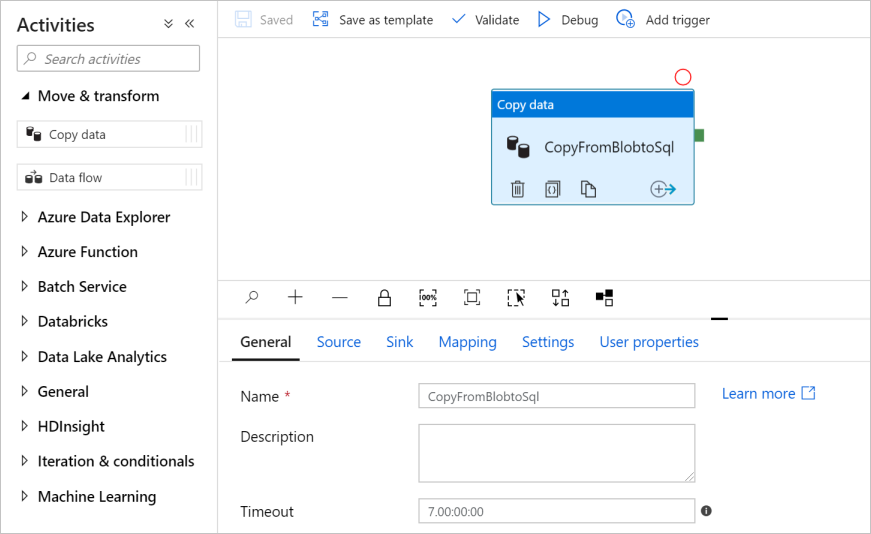
En el panel General, en Propiedades, especifique CopyPipeline en Nombre. A continuación, contraiga el panel; para ello, haga clic en el icono Propiedades en la esquina superior derecha.
En el cuadro de herramientas Activities (Actividades), expanda la categoría Move and Transform (Mover y transformar) y arrastre y suelte la actividad Copy Data (Copiar datos) desde el cuadro de herramientas hasta la superficie de diseño de la canalización. Especifique CopyFromBlobToSql en Name (Nombre).
Sugerencia
En este tutorial, usará Clave de cuenta como el tipo de autenticación para el almacén de datos de origen, pero puede elegir otros métodos de autenticación compatibles: identificador URI de SAS, entidad de servicio e identidad administrada, si es necesario. Consulte las secciones correspondientes en este artículo para más información. Para almacenar los secretos de los almacenes de datos de forma segura, también se recomienda usar Azure Key Vault. Consulte este artículo para obtener instrucciones detalladas.
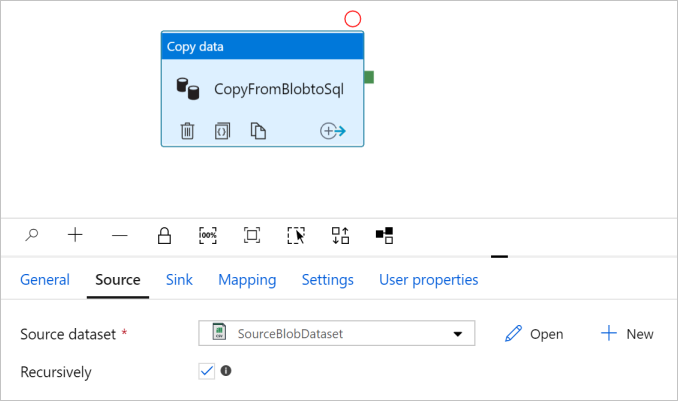
Vaya a la pestaña Source (Origen). Haga clic en + New (+ Nuevo) para crear un conjunto de datos de origen.
En el cuadro de diálogo New Dataset (Nuevo conjunto de datos), seleccione Azure Blob Storage y, después, seleccione Continue (Continuar). Los datos de origen están en Blob Storage, así que seleccionará Azure Blob Storage como conjunto de datos de origen.
En el cuadro de diálogo Select Format (Seleccionar formato), elija el tipo de formato de los datos y, después, seleccione Continue (Continuar).
En el cuadro de diálogo Set Properties (Establecer propiedades), escriba SourceBlobDataset como nombre. Active la casilla First row as header (Primera fila como encabezado). En el cuadro de texto Linked service (Servicio vinculado), seleccione + New (+ Nuevo).
En la ventana New Linked Service (Azure Blob Storage) [Nuevo servicio vinculado (Azure Blob Storage)], escriba AzureStorageLinkedService como nombre y seleccione la cuenta de almacenamiento en la lista Nombre de la cuenta de almacenamiento. Pruebe la conexión y, a continuación, seleccione Create (Crear) para implementar el servicio vinculado.
Una vez creado el servicio vinculado, se vuelve a ir a la página Set Properties (Establecer propiedades). Junto a File path (Ruta de acceso del archivo), seleccione Browse (Examinar).
Vaya a la carpeta adftutorial/input, seleccione el archivo emp.txt y, luego, OK (Aceptar).
Seleccione Aceptar. Va automáticamente a la página de canalización. En la pestaña Source (Origen), confirme que se selecciona SourceBlobDataset. Para obtener una vista previa de los datos de esta página, seleccione Preview data (Vista previa de los datos).
Sugerencia
En este tutorial, usará Autenticación de SQL como el tipo de autenticación para el almacén de datos receptor, pero puede elegir otros métodos de autenticación compatibles: entidad de servicio e identidad administrada, si es necesario. Consulte las secciones correspondientes en este artículo para más información. Para almacenar los secretos de los almacenes de datos de forma segura, también se recomienda usar Azure Key Vault. Consulte este artículo para obtener instrucciones detalladas.
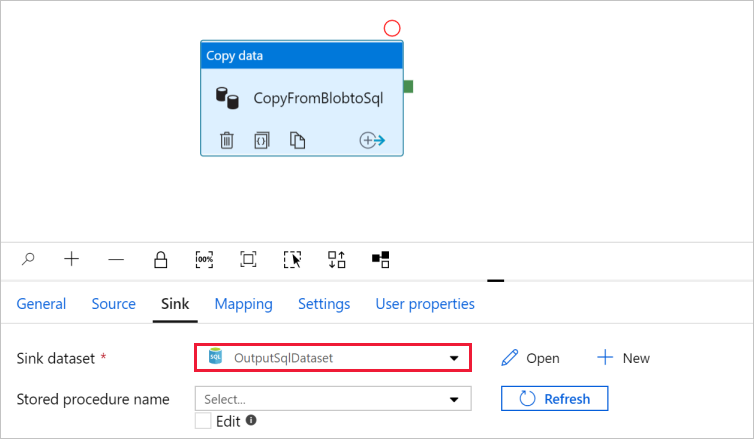
Vaya a la pestaña Sink (Receptor) y seleccione + New (+Nuevo) para crear un conjunto de datos del receptor.
En el cuadro de diálogo New Datase (Nuevo conjunto de datos), escriba "SQL" en el cuadro de búsqueda para filtrar los conectores, seleccione Azure SQL Database y, después, seleccione Continue (Continuar). En este tutorial, copiará los datos en una base de datos SQL.
En el cuadro de diálogo Set Properties (Establecer propiedades), escriba OutputSqlDataset como nombre. En la lista desplegable Linked service (Servicio vinculado), seleccione + New (+ Nuevo). Un conjunto de datos debe estar asociado con un servicio vinculado. El servicio vinculado tiene la cadena de conexión que usa Data Factory para conectarse a SQL Database en tiempo de ejecución. El conjunto de datos especifica el contenedor, la carpeta y el archivo (opcional) donde se copian los datos.
En el cuadro de diálogo New Linked Service (Azure SQL Database) [Nuevo servicio vinculado (Azure SQL Database)], realice los siguientes pasos:
a. En Name (Nombre), escriba AzureSqlDatabaseLinkedService.
b. En Server name (Nombre del servidor), seleccione su instancia de SQL Server.
c. En Database name (Nombre de base de datos), seleccione la base de datos.
d. En User name (Nombre de usuario), escriba el nombre del usuario.
e. En Password (Contraseña), escriba la contraseña del usuario.
f. Seleccione Test connection (Prueba de conexión) para probar la conexión.
g. Seleccione Create (Crear) para implementar el servicio vinculado.
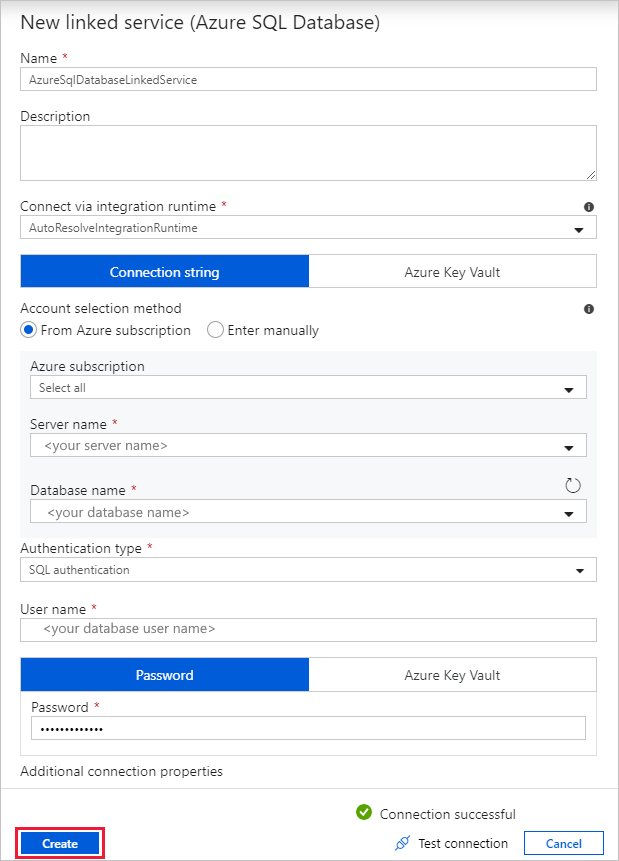
Va automáticamente al cuadro de diálogo Set Properties (Establecer propiedades). En Table (Tabla), seleccione [dbo].[emp] . Después, seleccione Aceptar.
Vaya a la pestaña con la canalización y, en Sink Dataset (Conjunto de datos del receptor), confirme que se ha seleccionado OutputSqlDataset.
Opcionalmente, puede asignar el esquema del origen al correspondiente esquema de destino. Para ello, siga las instrucciones de Asignación de esquemas en la actividad de copia.
Para validar la canalización, seleccione Validar en la barra de herramientas.
Puede ver el código JSON asociado a la canalización. Para ello, haga clic en Code (Código) en la parte superior derecha.
Puede depurar una canalización antes de publicar artefactos (servicios vinculados, conjuntos de datos y canalizaciones) en Data Factory o en su propio repositorio Git de Azure Repos.
Para depurar la canalización, seleccione Depurar en la barra de herramientas. Verá el estado de ejecución de la canalización en la pestaña Output (Salida) en la parte inferior de la ventana.
Una vez que la canalización se puede ejecutar correctamente, en la barra de herramientas superior, seleccione Publish all (Publicar todo). Esta acción publica las entidades (conjuntos de datos y canalizaciones) que creó para Data Factory.
Espere a que aparezca el mensaje Successfully published (Publicado correctamente). Para ver los mensajes de notificación, haga clic en Show Notifications (Mostrar notificaciones) en la parte superior derecha (botón de campana).
En este paso, desencadenará manualmente la canalización que publicó en el paso anterior.
Seleccione Trigger (Desencadenar) en la barra de herramientas y, después, seleccione Trigger Now (Desencadenar ahora). En la página Pipeline Run (Ejecución de la canalización), seleccione OK (Aceptar).
Vaya a la pestaña Monitor (Supervisar) de la izquierda. Verá una ejecución de canalización que se desencadena de forma manual. Puede usar los vínculos de la columna PIPELINE NAME (Nombre de la canalización) para ver los detalles de la actividad y volver a ejecutar la canalización.

Para ver las ejecuciones de actividad asociadas a la ejecución de la canalización, seleccione el vínculo CopyPipeline (Copiar canalización) en la columna PIPELINE NAME (Nombre de la canalización). En este ejemplo, solo hay una actividad, así que solo verá una entrada en la lista. Para obtener más información sobre la operación de copia, seleccione el vínculo Detalles (icono de gafas) en la columna ACTIVITY NAME. Para volver a la vista Ejecuciones de canalización, seleccione All pipeline runs (Todas las ejecuciones de canalización) en la parte superior. Para actualizar la vista, seleccione Refresh (Actualizar).

Compruebe que se agregan dos filas más a la tabla emp de la base de datos.
En esta programación, creará un desencadenador de programación para la canalización. El desencadenador ejecuta la canalización de acuerdo con la programación especificada, como diariamente o cada hora. Aquí establece el desencadenador para que se ejecute cada minuto hasta la fecha y hora de finalización especificadas.
Vaya a la pestaña Author (Creador) a la izquierda, por encima de la pestaña Monitor (Supervisar).
Vaya a la canalización, haga clic en Desencadenar en la barra de herramientas y seleccione New/Edit (Nuevo/Editar).
En el cuadro de diálogo Add Triggers (Agregar desencadenadores), seleccione + New (+ Nuevo) para el área Choose trigger (Elegir desencadenador).
En la ventana New Trigger (Nuevo desencadenador), lleve a cabo los siguientes pasos:
a. En Name (Nombre), escriba RunEveryMinute.
b. Actualice Start date (Fecha de inicio) del desencadenador. Si la fecha es anterior a la fecha y hora actuales, el desencadenador comenzará a surtir efecto una vez publicado el cambio.
c. En Time zone (Zona horaria), seleccione la lista desplegable.
d. En Recurrence (Periodicidad), seleccione Every 1 Minute(s) (Cada minuto).
e. Active la casilla Specify an end date (Especifica una fecha de finalización) y actualice la sección End On (Finaliza el) para que sea unos minutos después de la fecha y hora actuales. El desencadenador se activa únicamente después de publicar los cambios. Si lo establece solo en un par de minutos de diferencia y no lo publica para entonces, no verá una ejecución de desencadenador.
f. En la opción Activated (Activado), seleccione Yes (Sí).
g. Seleccione Aceptar.
Importante
Con cada ejecución de canalización se asocia un costo, así que establezca la fecha de finalización correctamente.
En la página Edit trigger (Editar desencadenador), revise la advertencia y, a continuación, seleccione Save (Guardar). La canalización de este ejemplo no toma ningún parámetro.
Haga clic en Publish all (Publicar todo) para publicar el cambio.
Vaya a la pestaña Monitor (Supervisión) de la izquierda para ver las ejecuciones de canalización desencadenadas.

Para cambiar de la vista Pipeline Runs (Ejecuciones de canalización) a la vista Trigger Runs (Ejecuciones de desencadenador), seleccione Trigger Runs (Ejecuciones de desencadenador) en la parte izquierda de la ventana.
Verá las ejecuciones de desencadenador en una lista.
Compruebe que se insertan dos filas por minuto (para cada ejecución de canalización) en la tabla emp hasta la hora de finalización especificada.
La canalización de este ejemplo copia los datos de una ubicación a otra de Blob Storage. Ha aprendido a:
Para aprender a copiar datos desde el entorno local a la nube, avance al tutorial siguiente:
Eventos
31 mar, 23 - 2 abr, 23
Evento de aprendizaje de Fabric, Power BI y SQL más grande. 31 de marzo – 2 de abril. Use el código FABINSIDER para ahorrar $400.
Regístrate hoyCursos
Módulo
Uso de canalizaciones de Data Factory en Microsoft Fabric - Training
Uso de canalizaciones de Data Factory en Microsoft Fabric
Certificación
Microsoft Certified: Azure Data Engineer Associate - Certifications
Demostrar la comprensión de las tareas comunes de ingeniería de datos para implementar y administrar cargas de trabajo de ingeniería de datos en Microsoft Azure mediante una serie de servicios de Azure.
Documentación
Tutoriales de Azure Data Factory - Azure Data Factory
Lista de tutoriales que muestran los conceptos de Azure Data Factory
Copia de datos locales con la herramienta Copiar datos de Azure - Azure Data Factory
Creación de una instancia de Azure Data Factory y uso de la herramienta Copiar datos para copiar datos de una base de datos de SQL Server a una instancia de Azure Blob Storage.
Copia de datos de Azure Blob Storage a SQL con la herramienta Copiar datos - Azure Data Factory
Creación de una instancia de Azure Data Factory y uso de la herramienta Copiar datos para copiar datos de Azure Blob Storage a una instancia de SQL Database.