Optimización del rendimiento de Azure Data Lake Storage Gen1
Data Lake Storage Gen1 permite un alto rendimiento en el movimiento de datos y el análisis con uso intensivo de operaciones de E/S. En Data Lake Storage Gen1, usar toda la capacidad de proceso disponible (la cantidad de datos que se pueden leer o escribir por segundo) es importante para obtener el mejor rendimiento. Se consigue realizando tantas lecturas y escrituras en paralelo como sea posible.
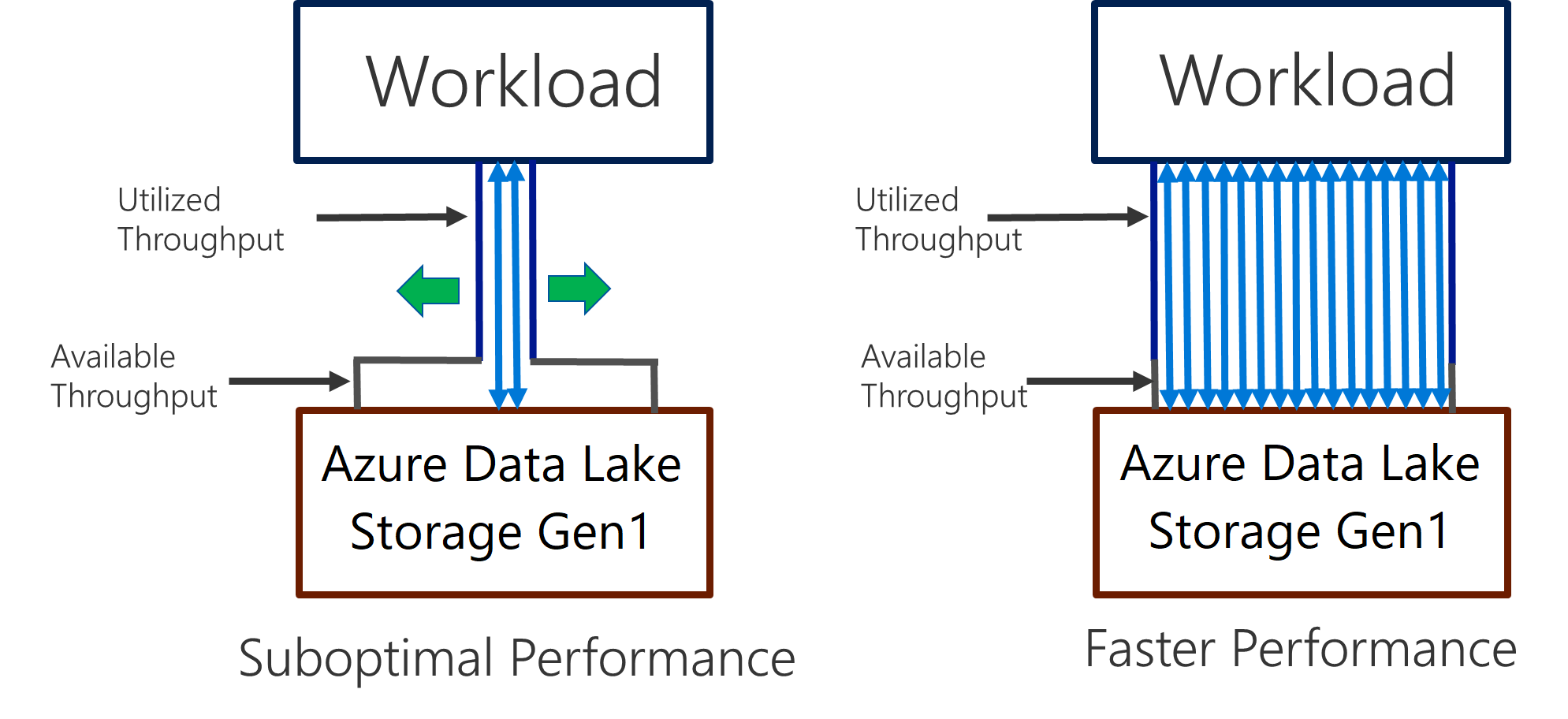
Data Lake Storage Gen1 puede escalar para ofrecer la capacidad de proceso necesaria para todos los escenarios de análisis. De forma predeterminada, una cuenta Data Lake Storage Gen1 proporciona automáticamente la capacidad suficiente para satisfacer las necesidades de una amplia variedad de casos de uso. Cuando los clientes llegan al límite predeterminado, la cuenta Data Lake Storage Gen1 se puede configurar para proporcionar más rendimiento, si se ponen en contacto con el soporte técnico de Microsoft.
Ingesta de datos
Cuando se ingieren datos de un sistema de origen para Data Lake Storage Gen1, es importante tener en cuenta que el hardware de origen, el hardware de red de origen y la conectividad de red con Data Lake Storage Gen1 pueden constituir un cuello de botella.
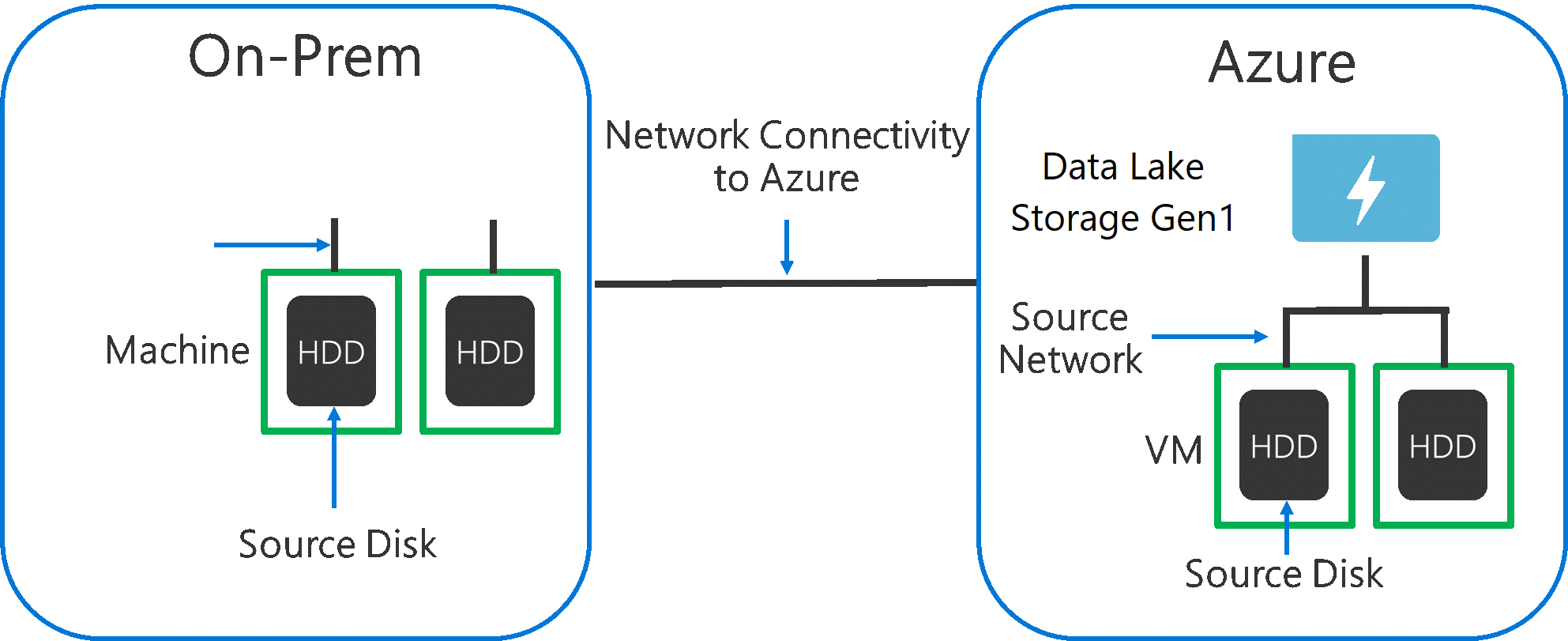
Es importante asegurarse de que el movimiento de datos no se ve afectado por estos factores.
Hardware de origen
Si usa máquinas locales o máquinas virtuales en Azure, debe seleccionar cuidadosamente el hardware apropiado. Como hardware del disco de origen, elija SSD antes que HDD y seleccione el hardware de disco con los ejes más rápidos. Como hardware de la red de origen, use los NIC más rápidos que sea posible. En Azure, se recomienda el uso de máquinas virtuales de Azure D14 que tengan el hardware de red y de disco con la capacidad apropiada.
Conectividad de red para Data Lake Storage Gen1
La conectividad de red entre los datos de origen y Data Lake Storage Gen1 a veces puede constituir un cuello de botella. Cuando los datos de origen están en local, considere el uso de un vínculo dedicado con Azure ExpressRoute. Si los datos de origen están en Azure, el rendimiento será el mejor cuando los datos se encuentren en la misma región de Azure que Data Lake Storage Gen1.
Configuración de herramientas de ingesta de datos para lograr una paralelización máxima
Cuando haya solucionado los cuellos de botella de la conectividad de la red y del hardware de origen, estará listo para configurar las herramientas de ingesta. En la tabla siguiente se resume la configuración básica de varias herramientas de ingesta populares y se ofrecen artículos detallados sobre la optimización del rendimiento relacionados con ellas. Para más información sobre la herramienta adecuada para su escenario, consulte este artículo.
| Herramienta | Configuración | Más detalles |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Vínculo |
| AdlCopy | Unidades de Azure Data Lake Analytics | Vínculo |
| DistCp | -m (mapper) | Vínculo |
| Azure Data Factory | parallelCopies | Vínculo |
| Sqoop | fs.azure.block.size, -m (mapper) | Vínculo |
Estructuración del conjunto de datos
Cuando los datos se almacenan en Data Lake Storage Gen1, el tamaño de los archivos, su número y la estructura de carpetas afectan al rendimiento. En la siguiente sección se describen los procedimientos recomendados en estas áreas.
Tamaño de archivo
Normalmente, los motores de análisis como HDInsight y Azure Data Lake Analytics tienen una sobrecarga por cada archivo. Si los datos se almacenan en muchos archivos pequeños, puede afectar desfavorablemente al rendimiento.
En general, organice los datos en archivos de un tamaño mayor para mejorar el rendimiento. Como regla general, organice los conjuntos de datos en archivos de 256 MB o más. En algunos casos, como para las imágenes y datos binarios, no es posible procesarlos en paralelo. En estos casos, se recomienda mantener los archivos individuales por debajo de 2 GB.
A veces, las canalizaciones de datos ejercen un control limitado sobre los datos sin procesar que tienen gran cantidad de archivos pequeños. Se recomienda disponer de un proceso de "cocinado" que genere archivos de mayor tamaño para usarlos en las aplicaciones de bajada.
Organización de los datos de serie temporal en carpetas
En las cargas de trabajo de Hive y ADLA, la eliminación de las particiones de los datos de serie temporal puede contribuir a que algunas consultas lean solo un subconjunto de los datos, lo que mejora el rendimiento.
Aquellas canalizaciones que ingieren datos de serie temporal suelen ubicar sus archivos con una nomenclatura estructurada para los archivos y las carpetas. A continuación se muestra un ejemplo común de datos estructurados por fecha: \DataSet\AAAA\MM\DD\datafile_AAAA_MM_DD.tsv.
Observe que la información de fecha y hora aparece tanto en las carpetas como en el nombre de archivo.
Para la fecha y la hora, el siguiente es un patrón común: \DataSet\AAAA\MM\DD\HH\mm\datafile_AAAA_MM_DD_HH_mm.tsv.
De nuevo, su elección de organización de los archivos y carpetas debería ser la que consiga un tamaño de archivo mayor y un número razonable de archivos en cada carpeta.
Optimización de trabajos con uso intensivo de operaciones de E/S en las cargas de trabajo de Hadoop y Spark en HDInsight
Los trabajos se dividen en una de las siguientes tres categorías:
- Gran uso de CPU. Estos trabajos tienen tiempos de cálculo largos con tiempos de E/S mínimos. Algunos ejemplos son los trabajos de procesamiento del lenguaje natural y el aprendizaje automático.
- Gran uso de memoria. Estos trabajos usan una gran cantidad de memoria. Algunos ejemplos son los trabajos de análisis en tiempo real y PageRank.
- Gran uso de operaciones de E/S. Estos trabajos dedican la mayor parte de su tiempo a realizar operaciones de E/S. Un ejemplo común es un trabajo de copia que solo realice operaciones de lectura y escritura. Otros ejemplos son los trabajos de preparación de datos que leen una gran cantidad de datos, realizan alguna transformación en ellos y luego los escriben de nuevo en el almacén.
Las siguientes instrucciones solo se pueden aplicar a los trabajos que usan mucho las operaciones de E/S.
Consideraciones generales para un clúster de HDInsight
- Versiones de HDInsight. Para obtener el mejor rendimiento, utilice la versión más reciente de HDInsight.
- Regiones. Coloque la cuenta de Data Lake Storage Gen1 en la misma región que el clúster de HDInsight.
Un clúster de HDInsight se compone de dos nodos principales y algunos nodos de trabajo. Cada nodo de trabajo proporciona una cantidad específica de núcleos y de memoria, lo que se determina según el tipo de máquina virtual. Cuando se ejecuta un trabajo, YARN es el negociador de recursos que asigna la memoria disponible y los núcleos para crear los contenedores. Cada contenedor ejecuta las tareas necesarias para completar el trabajo. Los contenedores se ejecutan en paralelo para procesar las tareas rápidamente. Por lo tanto, el rendimiento se mejora ejecutando tantos contenedores en paralelo como sea posible.
Hay tres niveles dentro de un clúster de HDInsight que se pueden optimizar para aumentar el número de contenedores y usar toda la capacidad de proceso disponible.
- Nivel físico
- Nivel de YARN
- Nivel de carga de trabajo
Nivel físico
Ejecute el clúster con más nodos o máquinas virtuales de un tamaño mayor. Un clúster mayor le permitirá ejecutar más contenedores de YARN, tal como se muestra en la ilustración siguiente.

Use máquinas virtuales con más ancho de banda de red. La cantidad de ancho de banda de red puede ser un cuello de botella, si hay menos de lo que necesita la capacidad de proceso de Data Lake Storage Gen1. Diferentes máquinas virtuales tendrán varios tamaños de ancho de banda de red. Elija un tipo de máquina virtual que tenga el mayor ancho de banda de red posible.
Nivel de YARN
Use contenedores de YARN menores. Reduzca el tamaño de cada contenedor de YARN para crear más contenedores con la misma cantidad de recursos.
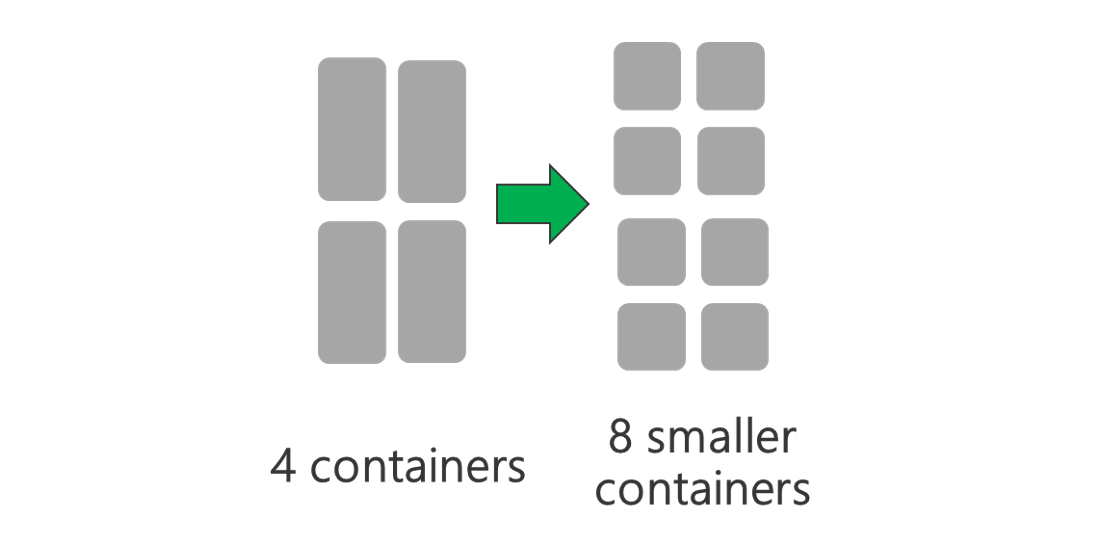
En función de la carga de trabajo, siempre habrá un tamaño de contenedor de YARN mínimo que se necesite. Si elige un contenedor demasiado pequeño, los trabajos no tendrán memoria suficiente. Normalmente, los contenedores de YARN no deben ser de menos de 1 GB. Es habitual ver contenedores de YARN de 3 GB. Para algunas cargas de trabajo, puede que necesite contenedores de YARN mayores.
Aumente los núcleos para cada contenedor de YARN. Aumente el número de núcleos asignados a cada contenedor para incrementar las tareas en paralelo que se ejecutan en cada uno. Funciona en aplicaciones como Spark que ejecutan varias tareas por contenedor. En aplicaciones como Hive que ejecutan un único subproceso en cada contenedor, es mejor tener varios contenedores en lugar de más núcleos por contenedor.
Nivel de carga de trabajo
Use todos los contenedores disponibles. Establezca el número de tareas para que sea igual o mayor que el número de contenedores disponibles de modo que se usen todos los recursos.
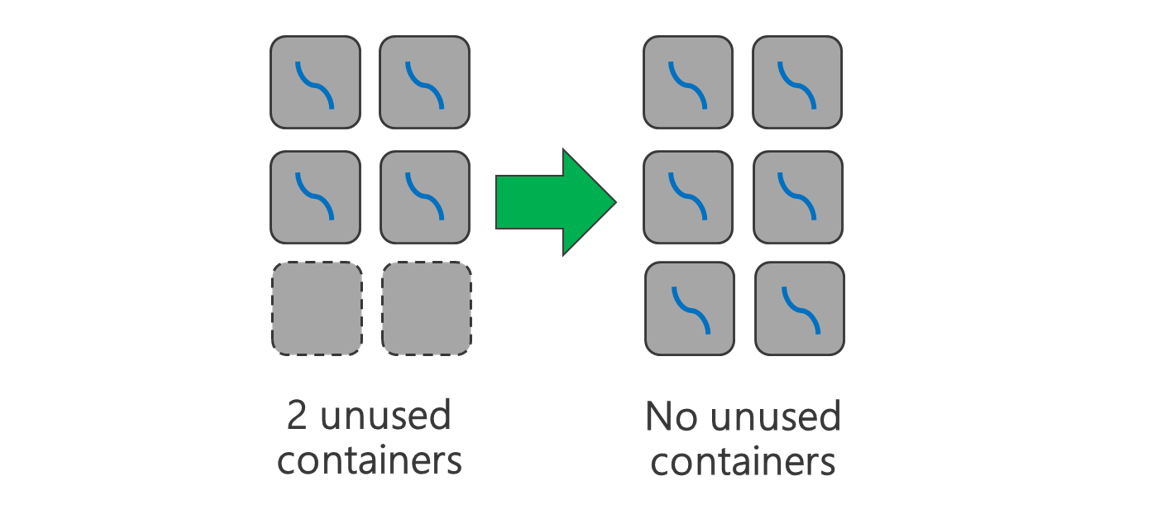
Los errores de las tareas son costosos. Si cada tarea tiene una gran cantidad de datos que se van a procesar, el error de una tarea provoca un reintento que resulta caro. Por lo tanto, es mejor que cree más tareas y que cada una procese una pequeña cantidad de datos.
Además de las directrices generales anteriores, cada aplicación tiene diferentes parámetros disponibles que pueden optimizarse para ella en concreto. En la tabla siguiente se enumeran algunos de los parámetros y los vínculos para empezar a optimizar el rendimiento de cada aplicación.
| Carga de trabajo | Parámetro para establecer tareas |
|---|---|
| Spark en HDInsight |
|
| Hive en HDInsight |
|
| MapReduce en HDInsight |
|
| Storm en HDInsight |
|