Databricks Runtime 7.4 (sin soporte técnico)
Databricks publicó esta imagen en noviembre de 2020.
Las notas de la versión siguientes proporcionan información sobre Databricks Runtime 7.4, con tecnología Apache Spark 3.0.
Nuevas características
En esta sección:
- Característica y mejoras de Delta Lake
- Auto Loader ahora admite la delegación de la configuración de recursos de notificación de archivos a los administradores
- El nuevo privilegio
USAGEda a los administradores un mayor control sobre los privilegios de acceso a datos - FUSE para DBFS ahora está habilitado para clústeres habilitados para acceso directo
Característica y mejoras de Delta Lake
En esta versión se proporcionan las siguientes características y mejoras de Delta Lake:
- La nueva API permite a Delta Lake comprobar que los datos agregados a una tabla satisfacen las restricciones
- La nueva API permite revertir una tabla de Delta a una versión anterior de la tabla
- La nueva versión inicial permite devolver solo los cambios más recientes en un origen de streaming de Delta Lake
- Se mejoró la estabilidad de
OPTIMIZE
La nueva API permite a Delta Lake comprobar que los datos agregados a una tabla satisfacen las restricciones
Delta Lake ahora admite restricciones CHECK. Cuando se proporciona, Delta Lake comprueba automáticamente que los datos agregados a una tabla satisfagan la expresión especificada.
Para agregar restricciones CHECK, use el comando ALTER TABLE ADD CONSTRAINTS. Para más información, consulte Restricciones en Azure Databricks.
La nueva API permite revertir una tabla de Delta a una versión anterior de la tabla
Ahora puede revertir las tablas de Delta a versiones anteriores mediante el comando RESTORE:
SQL
RESTORE <table> TO VERSION AS OF n;
RESTORE <table> TO TIMESTAMP AS OF 'yyyy-MM-dd HH:mm:ss';
Python
from delta.tables import DeltaTable
DeltaTable.forPath(spark, path).restoreToVersion(n)
DeltaTable.forPath(spark, path).restoreToTimestamp('yyyy-MM-dd')
Scala
import io.delta.tables.DeltaTable
DeltaTable.forPath(spark, path).restoreToVersion(n)
DeltaTable.forPath(spark, path).restoreToTimestamp("yyyy-MM-dd")
RESTORE crea una nueva confirmación que revierte todos los cambios realizados en la tabla desde la versión que desea restaurar. Se restauran todos los datos y metadatos existentes, lo que incluye el esquema, las restricciones, los identificadores de transacción de streaming, los metadatos de COPY INTO y la versión del protocolo de tabla. Para más información, consulte Restauración de una tabla de Delta.
La nueva versión inicial permite devolver solo los cambios más recientes en un origen de streaming de Delta Lake
Para devolver solo los cambios más recientes, especifique startingVersion como latest. Para obtener más información, consulte Especificación de la posición inicial.
Se mejoró la estabilidad de OPTIMIZE
OPTIMIZE (sin predicados de partición) se puede escalar para ejecutarse en tablas con decenas de millones de archivos pequeños. Anteriormente, el controlador de Apache Spark se podía quedar sin memoria y OPTIMIZE no se completaba.Ahora, OPTIMIZE controla tablas muy grandes con decenas de millones de archivos.
Auto Loader ahora admite la delegación de la configuración de recursos de notificación de archivos a los administradores
Una nueva API de Scala permite a los administradores configurar recursos de notificación de archivos para Auto Loader. Los ingenieros de datos ahora pueden operar sus flujos de Auto Loader con menos permisos al delegar la configuración inicial de los recursos a sus administradores. Vea Configuración o administración manual de recursos de notificación de archivos.
El nuevo privilegio USAGE da a los administradores un mayor control sobre los privilegios de acceso a datos
Para realizar una acción en un objeto de una base de datos, ahora se le debe conceder el privilegio USAGE en esa base de datos, además de los privilegios necesarios para realizar la acción. El privilegio USAGE se concede para una base de datos o un catálogo. Con la introducción del privilegio USAGE, el propietario de una tabla ya no puede decidir compartirla con otro usuario; el usuario también debe tener el privilegio USAGE en la base de datos que contiene la tabla.
En las áreas de trabajo que tienen habilitado el control de acceso a tablas, el users grupo tiene automáticamente el privilegio USAGE para la raíz CATALOG.
Para más información, consulte Privilegio USAGE.
FUSE para DBFS ahora está habilitado para clústeres habilitados para acceso directo
Ahora puede leer y escribir desde DBFS mediante el montaje de FUSE en /dbfs/ cuando se usa un clúster de alta simultaneidad habilitado para el acceso directo a credenciales. Se admiten los montajes normales. No se admiten los montajes que requieren credenciales de acceso directo.
Mejoras
Spark SQL admite IFF y CHARINDEX como sinónimos de IF y POSITION
En Databricks Runtime, IF() es un sinónimo de CASE WHEN <cond> THEN <expr1> ELSE <expr2> END.
Databricks Runtime ahora admite IFF() como sinónimo de IF().
SELECT IFF(c1 = 1, 'Hello', 'World'), c1 FROM (VALUES (1), (2)) AS T(c1)
=> (Hello, 1)
(World, 2)
CHARINDEX es un nombre alternativo para la función POSITION. CHARINDEX busca la posición de la primera aparición de una cadena dentro de otra cadena con un índice de inicio opcional.
VALUES(CHARINDEX('he', 'hello from hell', 2))
=> 12
Varias salidas por celda habilitadas para cuadernos de Python de manera predeterminada
Databricks Runtime 7.1 introdujo compatibilidad con varias salidas por celda en cuadernos de Python (y celdas de %python dentro de cuadernos que no son de Python), pero era necesario habilitar la característica para el cuaderno. Esta característica está habilitada de manera predeterminada en Databricks Runtime 7.4. Consulte Visualización de varias salidas por celda.
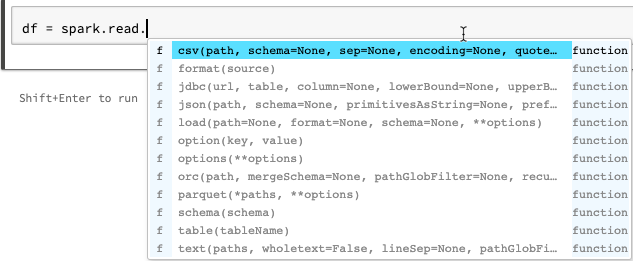
Mejoras de la característica de autocompletar para cuadernos de Python
Autocompletar para Python muestra información de tipos adicional generada a partir del análisis estático del código mediante la biblioteca de Jedi. Puede presionar la tecla Tab para ver una lista de opciones.
Se ha mejorado display de los vectores de Spark ML en la versión preliminar de DataFrame de Spark
El formato display ahora muestra etiquetas para el tipo de vector (disperso o denso), la longitud, los índices (para los vectores dispersos) y los valores.
Otras correcciones
- Se ha corregido un problema de selección con
collections.namedtupleen los cuadernos. - Se ha corregido un problema de selección con clases y métodos definidos de manear interactiva.
- Se ha corregido un error que provocaba un error de
mlflow.start_run()en las llamadas en el acceso directo o en los clústeres habilitados para el control de acceso a tablas.
Actualizaciones de bibliotecas
- Bibliotecas de Python actualizadas:
- jedi se actualizó de 0.14.1 a 0.17.2.
- koalas se actualizó de 1.2.0 a 1.3.0.
- parso se actualizó de 0.5.2 a 0.7.0.
- Se han actualizado varias bibliotecas de R instaladas. Consulte Bibliotecas de R instaladas.
Apache Spark
Databricks Runtime 7.4 incluye Apache Spark 3.0.1. Esta versión incluye todas las correcciones y mejoras de Spark incluidas en Databricks Runtime 7.3 LTS (sin soporte técnico), así como las siguientes correcciones de errores y mejoras adicionales realizadas en Spark:
- [SPARK-33170] [SQL] Adición de la configuración de SQL para controlar el comportamiento de respuesta rápida a errores en FileFormatWriter
- [SPARK-33136] [SQL] Corrección del parámetro intercambiado por error en V2WriteCommand.outputResolved
- [SPARK-33134] [SQL] Devolución de resultados parciales solo para objetos JSON raíz
- [SPARK-33038] [SQL] Combinación de AQE inicial y plan actual…
- [SPARK-33118] [SQL] CREATE TEMPORARY TABLE produce un error con la ubicación
- [SPARK-33101] [ML] Hacer que el formato LibSVM propague la configuración de Hadoop desde las opciones de DS hasta el sistema de archivos HDFS subyacente
- [SPARK-33035] [SQL] Actualiza las entradas obsoletas de asignación de atributos en QueryPlan#transformUpWithNewOutput
- [SPARK-33091] [SQL] Evitar el uso de map en lugar de foreach para evitar posibles efectos secundarios en los autores de llamada de OrcUtilsreadCatalystSchema
- [SPARK-33073] [PYTHON] Mejora del control de errores en de conversión de Pandas a Arrow
- [SPARK-33043] [ML] Control de spark.driver.maxResultSize=0 en el cálculo heurístico de RowMatrix
- [SPARK-29358] [SQL] Hacer que unionByName rellene opcionalmente las columnas que faltan con valores NULL
- [SPARK-32996] [WEB-UI] Control de ExecutorMetrics vacío en ExecutorMetricsJsonSerializer
- [SPARK-32585] [SQL] Compatibilidad con la enumeración de Scala en ScalaReflection
- [SPARK-33019] [CORE] Uso de spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=1 de manera predeterminada
- [SPARK-33018] [SQL] Corrección del problema de estimación de estadísticas si el elemento secundario tiene 0 bytes
- [SPARK-32901] [CORE] No asignar memoria mientras se desborda UnsafeExternalSorter
- [SPARK-33015] [SQL] Uso de millisToDays() en la regla ComputeCurrentTime
- [SPARK-33015] [SQL] Cálculo de la fecha actual solo una vez
- [SPARK-32999] [SQL] Uso de Utils.getSimpleName para evitar alcanzar el nombre de clase con formato incorrecto en TreeNode
- [SPARK-32659] [SQL] Difusión de Array en lugar de Set en InSubqueryExec
- [SPARK-32718] [SQL] Eliminación de palabras clave innecesarias para las unidades de intervalo
- [SPARK-32886] [WEBUI] Corrección del vínculo "undefined" en la vista de escala de tiempo de eventos
- [SPARK-32898] [CORE] Corrección de un executorRunTime incorrecto cuando la tarea termina antes del inicio real
- [SPARK-32635] [SQL] Adición de un nuevo caso de prueba en el módulo de Catalyst
- [SPARK-32930] [CORE] Reemplazo de los métodos isFile/isDirectory en desuso
- [SPARK-32906] [SQL] Los nombres de campo de estructura no deben cambiar después de normalizar los valores float
- [SPARK-24994] [SQL] Adición de un optimizador UnwrapCastInBinaryComparison para simplificar el literal entero
- [SPARK-32635] [SQL] Corrección de la propagación plegable
- [SPARK-32738] [CORE] Debe reducir el número de subprocesos activos si se produce un error grave en
Inbox.process - [SPARK-32900] [CORE] Permitir un desbordamiento de UnsafeExternalSorter cuando hay valores NULL
- [SPARK-32897] [PYTHON] No mostrar una advertencia de desuso en SparkSession.builder.getOrCreate
- [SPARK-32715] [CORE] Corrección de la fuga de memoria cuando no se pudieron almacenar fragmentos de difusión
- [SPARK-32715] [CORE] Corrección de la fuga de memoria cuando no se pudieron almacenar fragmentos de difusión
- [SPARK-32872] [CORE] Impedir que BytesToBytesMap en MAX_CAPACITY supere el umbral de crecimiento
- [SPARK-32876] [SQL] Cambio de las versiones de reserva predeterminadas a 3.0.1 y 2.4.7 en HiveExternalCatalogVersionsSuite
- [SPARK-32840] [SQL] Puede ocurrir que el valor de intervalo no válido esté simplemente adherido a la unidad
- [SPARK-32819] [SQL] El parámetro ignoreNullability debe ser eficaz de forma recursiva
- [SPARK-32832] [SS] Uso de CaseInsensitiveMap para las opciones DataStreamReader/Writer
- [SPARK-32794] [SS] Corrección de un error de caso patológico poco frecuente en el motor de microlotes con algunas consultas con estado + lotes sin datos + orígenes V1
- [SPARK-32813] [SQL] Obtención de la configuración predeterminada del lector vectorizado ParquetSource si no hay ninguna SparkSession activa
- [SPARK-32823] [INTERFAZ DE USUARIO WEB] Corrección de los informes de recursos de la interfaz de usuario maestra
- [SPARK-32824] [CORE] Mejora del mensaje de error cuando el usuario olvida .amount en una configuración de recursos
- [SPARK-32614] [SQL] No aplicar el procesamiento de comentarios si "comment" se ha anulado para CSV
- [SPARK-32638] [SQL] Corrige las referencias al agregar alias en WidenSetOperationTypes
- [SPARK-32810] [SQL] Los orígenes de datos CSV/JSON deben evitar las rutas comodín g al inferir el esquema
- [SPARK-32815] [ML] Corrección del error de carga del origen de datos LibSVM en rutas de acceso de archivo con metacaracteres glob
- [SPARK-32753] [SQL] Solo copiar etiquetas en el nodo sin etiquetas
- [SPARK-32785] [SQL] El intervalo con elementos pendientes no debe dar como resultado NULL
- [SPARK-32764] [SQL] -0.0 debe ser igual a 0.0
- [SPARK-32810] [SQL] Los orígenes de datos CSV/JSON deben evitar las rutas comodín g al inferir el esquema
- [SPARK-32779] [SQL] Evitar el uso de la API sincronizada de SessionCatalog en el flujo withClient, lo que conduce a DeadLock
- [SPARK-32791] [SQL] La métrica de tablas sin particiones no debe tener tiempo de recorte dinámico de particiones
- [SPARK-32767] [SQL] La combinación de cubos debe funcionar si spark.sql.shuffle.partitions es mayor que el número de cubos
- [SPARK-32788] [SQL] El recorrido de tablas sin particiones no debe tener un filtro de partición
- [SPARK-32776] [SS] PropagateEmptyRelation no debe optimizar el límite de streaming
- [SPARK-32624] [SQL] Corrección de la regresión en CodegenContext.addReferenceObj en tipos de Scala anidados
- [SPARK-32659] [SQL] Mejora de la prueba para la poda de DPP en un tipo no atómico
- [SPARK-31511] [SQL] Hacer que los iteradores de BytesToBytesMap sean seguros para subprocesos
- [SPARK-32693] [SQL] Comparación de dos dataframes con el mismo esquema, excepto la propiedad que acepta valores NULL
- [SPARK-28612] [SQL] Documento de método correcto de DataFrameWriterV2.replace()
Actualizaciones de mantenimiento
Consulte Actualizaciones de mantenimiento de Databricks Runtime 7.4.
Entorno del sistema
- Sistema operativo: Ubuntu 18.04.5 LTS
- Java: Zulu 8.48.0.53-CA-linux64 (compilación 1.8.0_265-b11)
- Scala: 2.12.10
- Python: 3.7.5
- R: Versión R 3.6.3 (29-02-2020)
- Delta Lake 0.7.0
Bibliotecas de Python instaladas
| Biblioteca | Versión | Biblioteca | Versión | Biblioteca | Versión |
|---|---|---|---|---|---|
| asn1crypto | 1.3.0 | backcall | 0.1.0 | boto3 | 1.12.0 |
| botocore | 1.15.0 | certifi | 2020.6.20 | cffi | 1.14.0 |
| chardet | 3.0.4 | criptografía | 2.8 | cycler | 0.10.0 |
| Cython | 0.29.15 | decorator | 4.4.1 | docutils | 0.15.2 |
| entrypoints | 0,3 | idna | 2.8 | ipykernel | 5.1.4 |
| ipython | 7.12.0 | ipython-genutils | 0.2.0 | jedi | 0.17.2 |
| jmespath | 0.10.0 | joblib | 0.14.1 | jupyter-client | 5.3.4 |
| jupyter-core | 4.6.1 | kiwisolver | 1.1.0 | koalas | 1.3.0 |
| matplotlib | 3.1.3 | numpy | 1.18.1 | pandas | 1.0.1 |
| parso | 0.7.0 | patsy | 0.5.1 | pexpect | 4.8.0 |
| pickleshare | 0.7.5 | pip | 20.0.2 | prompt-toolkit | 3.0.3 |
| psycopg2 | 2.8.4 | ptyprocess | 0.6.0 | pyarrow | 1.0.1 |
| pycparser | 2.19 | Pygments | 2.5.2 | PyGObject | 3.26.1 |
| pyOpenSSL | 19.1.0 | pyparsing | 2.4.6 | PySocks | 1.7.1 |
| python-apt | 1.6.5+ubuntu0.3 | Python-dateutil | 2.8.1 | pytz | 2019.3 |
| pyzmq | 18.1.1 | Solicitudes | 2.22.0 | s3transfer | 0.3.3 |
| scikit-learn | 0.22.1 | scipy | 1.4.1 | seaborn | 0.10.0 |
| setuptools | 45.2.0 | six (seis) | 1.14.0 | ssh-import-id | 5.7 |
| statsmodels | 0.11.0 | tornado | 6.0.3 | traitlets | 4.3.3 |
| unattended-upgrades | 0,1 | urllib3 | 1.25.8 | virtualenv | 16.7.10 |
| wcwidth | 0.1.8 | wheel | 0.34.2 |
Bibliotecas de R instaladas
Las bibliotecas de R se instalan desde la instantánea de Microsoft CRAN del XX-XX-XXXX.
| Biblioteca | Versión | Biblioteca | Versión | Biblioteca | Versión |
|---|---|---|---|---|---|
| askpass | 1.1 | assertthat | 0.2.1 | backports | 1.1.8 |
| base | 3.6.3 | base64enc | 0.1-3 | BH | 1.72.0-3 |
| bit | 1.1-15.2 | bit64 | 0.9-7 | blob | 1.2.1 |
| boot | 1.3-25 | brew | 1.0-6 | broom | 0.7.0 |
| callr | 3.4.3 | caret | 6.0-86 | cellranger | 1.1.0 |
| chron | 2.3-55 | clase | 7.3-17 | cli | 2.0.2 |
| clipr | 0.7.0 | cluster | 2.1.0 | codetools | 0.2-16 |
| colorspace | 1.4-1 | commonmark | 1.7 | compiler | 3.6.3 |
| config | 0,3 | covr | 3.5.0 | crayon | 1.3.4 |
| diafonía | 1.1.0.1 | curl | 4.3 | data.table | 1.12.8 |
| conjuntos de datos | 3.6.3 | DBI | 1.1.0 | dbplyr | 1.4.4 |
| desc | 1.2.0 | devtools | 2.3.0 | digest | 0.6.25 |
| dplyr | 0.8.5 | DT | 0.14 | ellipsis | 0.3.1 |
| evaluate | 0.14 | fansi | 0.4.1 | farver | 2.0.3 |
| fastmap | 1.0.1 | forcats | 0.5.0 | foreach | 1.5.0 |
| foreign | 0.8-76 | forge | 0.2.0 | fs | 1.4.2 |
| generics | 0.0.2 | ggplot2 | 3.3.2 | gh | 1.1.0 |
| git2r | 0.27.1 | glmnet | 3.0-2 | globals | 0.12.5 |
| glue | 1.4.1 | gower | 0.2.2 | elementos gráficos | 3.6.3 |
| grDevices | 3.6.3 | grid | 3.6.3 | gridExtra | 2.3 |
| gsubfn | 0.7 | gtable | 0.3.0 | haven | 2.3.1 |
| highr | 0.8 | hms | 0.5.3 | htmltools | 0.5.0 |
| htmlwidgets | 1.5.1 | httpuv | 1.5.4 | httr | 1.4.1 |
| hwriter | 1.3.2 | hwriterPlus | 1.0-3 | ini | 0.3.1 |
| ipred | 0.9-9 | isoband | 0.2.2 | iterators | 1.0.12 |
| jsonlite | 1.7.0 | KernSmooth | 2.23-17 | knitr | 1.29 |
| labeling | 0,3 | later | 1.1.0.1 | lattice | 0.20-41 |
| lava | 1.6.7 | lazyeval | 0.2.2 | ciclo de vida | 0.2.0 |
| lubridate | 1.7.9 | magrittr | 1.5 | markdown | 1.1 |
| MASS | 7.3-53 | Matriz | 1.2-18 | memoise | 1.1.0 |
| methods | 3.6.3 | mgcv | 1.8-33 | mime | 0.9 |
| ModelMetrics | 1.2.2.2 | modelr | 0.1.8 | munsell | 0.5.0 |
| nlme | 3.1-149 | nnet | 7.3-14 | numDeriv | 2016.8-1.1 |
| openssl | 1.4.2 | parallel | 3.6.3 | pillar | 1.4.6 |
| pkgbuild | 1.1.0 | pkgconfig | 2.0.3 | pkgload | 1.1.0 |
| plogr | 0.2.0 | plyr | 1.8.6 | praise | 1.0.0 |
| prettyunits | 1.1.1 | pROC | 1.16.2 | processx | 3.4.3 |
| prodlim | 2019.11.13 | progreso | 1.2.2 | promises | 1.1.1 |
| proto | 1.0.0 | ps | 1.3.3 | purrr | 0.3.4 |
| r2d3 | 0.2.3 | R6 | 2.4.1 | randomForest | 4.6-14 |
| rappdirs | 0.3.1 | rcmdcheck | 1.3.3 | RColorBrewer | 1.1-2 |
| Rcpp | 1.0.5 | readr | 1.3.1 | readxl | 1.3.1 |
| recipes | 0.1.13 | rematch | 1.0.1 | rematch2 | 2.1.2 |
| remotes | 2.1.1 | reprex | 0.3.0 | reshape2 | 1.4.4 |
| rex | 1.2.0 | rjson | 0.2.20 | rlang | 0.4.7 |
| rmarkdown | 2.3 | RODBC | 1.3-16 | roxygen2 | 7.1.1 |
| rpart | 4.1-15 | rprojroot | 1.3-2 | Rserve | 1.8-7 |
| RSQLite | 2.2.0 | rstudioapi | 0,11 | rversions | 2.0.2 |
| rvest | 0.3.5 | scales | 1.1.1 | selectr | 0.4-2 |
| sessioninfo | 1.1.1 | shape | 1.4.4 | shiny | 1.5.0 |
| sourcetools | 0.1.7 | sparklyr | 1.3.1 | SparkR | 3.0.0 |
| spatial | 7.3-11 | splines | 3.6.3 | sqldf | 0.4-11 |
| SQUAREM | 2020.3 | stats | 3.6.3 | stats4 | 3.6.3 |
| stringi | 1.4.6 | stringr | 1.4.0 | survival | 3.2-7 |
| sys | 3.3 | tcltk | 3.6.3 | TeachingDemos | 2,10 |
| testthat | 2.3.2 | tibble | 3.0.3 | tidyr | 1.1.0 |
| tidyselect | 1.1.0 | tidyverse | 1.3.0 | timeDate | 3043.102 |
| tinytex | 0,24 | tools | 3.6.3 | usethis | 1.6.1 |
| utf8 | 1.1.4 | utils | 3.6.3 | uuid | 0.1-4 |
| vctrs | 0.3.1 | viridisLite | 0.3.0 | whisker | 0,4 |
| withr | 2.2.0 | xfun | 0,15 | xml2 | 1.3.2 |
| xopen | 1.0.0 | xtable | 1.8-4 | yaml | 2.2.1 |
Bibliotecas de Java y Scala instaladas (versión de clúster de Scala 2.12)
| Identificador de grupo | Identificador de artefacto | Versión |
|---|---|---|
| antlr | antlr | 2.7.7 |
| com.amazonaws | amazon-kinesis-client | 1.12.0 |
| com.amazonaws | aws-java-sdk-autoscaling | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudformation | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudfront | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudhsm | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudsearch | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudtrail | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudwatch | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudwatchmetrics | 1.11.655 |
| com.amazonaws | aws-java-sdk-codedeploy | 1.11.655 |
| com.amazonaws | aws-java-sdk-cognitoidentity | 1.11.655 |
| com.amazonaws | aws-java-sdk-cognitosync | 1.11.655 |
| com.amazonaws | aws-java-sdk-config | 1.11.655 |
| com.amazonaws | aws-java-sdk-core | 1.11.655 |
| com.amazonaws | aws-java-sdk-datapipeline | 1.11.655 |
| com.amazonaws | aws-java-sdk-directconnect | 1.11.655 |
| com.amazonaws | aws-java-sdk-directory | 1.11.655 |
| com.amazonaws | aws-java-sdk-dynamodb | 1.11.655 |
| com.amazonaws | aws-java-sdk-ec2 | 1.11.655 |
| com.amazonaws | aws-java-sdk-ecs | 1.11.655 |
| com.amazonaws | aws-java-sdk-efs | 1.11.655 |
| com.amazonaws | aws-java-sdk-elasticache | 1.11.655 |
| com.amazonaws | aws-java-sdk-elasticbeanstalk | 1.11.655 |
| com.amazonaws | aws-java-sdk-elasticloadbalancing | 1.11.655 |
| com.amazonaws | aws-java-sdk-elastictranscoder | 1.11.655 |
| com.amazonaws | aws-java-sdk-emr | 1.11.655 |
| com.amazonaws | aws-java-sdk-glacier | 1.11.655 |
| com.amazonaws | aws-java-sdk-iam | 1.11.655 |
| com.amazonaws | aws-java-sdk-importexport | 1.11.655 |
| com.amazonaws | aws-java-sdk-kinesis | 1.11.655 |
| com.amazonaws | aws-java-sdk-kms | 1.11.655 |
| com.amazonaws | aws-java-sdk-lambda | 1.11.655 |
| com.amazonaws | aws-java-sdk-logs | 1.11.655 |
| com.amazonaws | aws-java-sdk-machinelearning | 1.11.655 |
| com.amazonaws | aws-java-sdk-opsworks | 1.11.655 |
| com.amazonaws | aws-java-sdk-rds | 1.11.655 |
| com.amazonaws | aws-java-sdk-redshift | 1.11.655 |
| com.amazonaws | aws-java-sdk-route53 | 1.11.655 |
| com.amazonaws | aws-java-sdk-s3 | 1.11.655 |
| com.amazonaws | aws-java-sdk-ses | 1.11.655 |
| com.amazonaws | aws-java-sdk-simpledb | 1.11.655 |
| com.amazonaws | aws-java-sdk-simpleworkflow | 1.11.655 |
| com.amazonaws | aws-java-sdk-sns | 1.11.655 |
| com.amazonaws | aws-java-sdk-sqs | 1.11.655 |
| com.amazonaws | aws-java-sdk-ssm | 1.11.655 |
| com.amazonaws | aws-java-sdk-storagegateway | 1.11.655 |
| com.amazonaws | aws-java-sdk-sts | 1.11.655 |
| com.amazonaws | aws-java-sdk-support | 1.11.655 |
| com.amazonaws | aws-java-sdk-swf-libraries | 1.11.22 |
| com.amazonaws | aws-java-sdk-workspaces | 1.11.655 |
| com.amazonaws | jmespath-java | 1.11.655 |
| com.chuusai | shapeless_2.12 | 2.3.3 |
| com.clearspring.analytics | flujo | 2.9.6 |
| com.databricks | Rserve | 1.8-3 |
| com.databricks | jets3t | 0.7.1-0 |
| com.databricks.scalapb | compilerplugin_2.12 | 0.4.15-10 |
| com.databricks.scalapb | scalapb-runtime_2.12 | 0.4.15-10 |
| com.esotericsoftware | kryo-shaded | 4.0.2 |
| com.esotericsoftware | minlog | 1.3.0 |
| com.fasterxml | classmate | 1.3.4 |
| com.fasterxml.jackson.core | jackson-annotations | 2.10.0 |
| com.fasterxml.jackson.core | jackson-core | 2.10.0 |
| com.fasterxml.jackson.core | jackson-databind | 2.10.0 |
| com.fasterxml.jackson.dataformat | jackson-dataformat-cbor | 2.10.0 |
| com.fasterxml.jackson.datatype | jackson-datatype-joda | 2.10.0 |
| com.fasterxml.jackson.module | jackson-module-paranamer | 2.10.0 |
| com.fasterxml.jackson.module | jackson-module-scala_2.12 | 2.10.0 |
| com.github.ben-manes.caffeine | caffeine | 2.3.4 |
| com.github.fommil | jniloader | 1.1 |
| com.github.fommil.netlib | core | 1.1.2 |
| com.github.fommil.netlib | native_ref-java | 1.1 |
| com.github.fommil.netlib | native_ref-java-natives | 1.1 |
| com.github.fommil.netlib | native_system-java | 1.1 |
| com.github.fommil.netlib | native_system-java-natives | 1.1 |
| com.github.fommil.netlib | netlib-native_ref-linux-x86_64-natives | 1.1 |
| com.github.fommil.netlib | netlib-native_system-linux-x86_64-natives | 1.1 |
| com.github.joshelser | dropwizard-metrics-hadoop-metrics2-reporter | 0.1.2 |
| com.github.luben | zstd-jni | 1.4.4-3 |
| com.github.wendykierp | JTransforms | 3.1 |
| com.google.code.findbugs | jsr305 | 3.0.0 |
| com.google.code.gson | gson | 2.2.4 |
| com.google.flatbuffers | flatbuffers-java | 1.9.0 |
| com.google.guava | guava | 15.0 |
| com.google.protobuf | protobuf-java | 2.6.1 |
| com.h2database | h2 | 1.4.195 |
| com.helger | profiler | 1.1.1 |
| com.jcraft | jsch | 0.1.50 |
| com.jolbox | bonecp | 0.8.0.RELEASE |
| com.lihaoyi | sourcecode_2.12 | 0.1.9 |
| com.microsoft.azure | azure-data-lake-store-sdk | 2.2.8 |
| com.microsoft.sqlserver | mssql-jdbc | 8.2.1.jre8 |
| com.ning | compress-lzf | 1.0.3 |
| com.sun.mail | javax.mail | 1.5.2 |
| com.tdunning | json | 1.8 |
| com.thoughtworks.paranamer | paranamer | 2.8 |
| com.trueaccord.lenses | lenses_2.12 | 0.4.12 |
| com.twitter | chill-java | 0.9.5 |
| com.twitter | chill_2.12 | 0.9.5 |
| com.twitter | util-app_2.12 | 7.1.0 |
| com.twitter | util-core_2.12 | 7.1.0 |
| com.twitter | util-function_2.12 | 7.1.0 |
| com.twitter | util-jvm_2.12 | 7.1.0 |
| com.twitter | util-lint_2.12 | 7.1.0 |
| com.twitter | util-registry_2.12 | 7.1.0 |
| com.twitter | util-stats_2.12 | 7.1.0 |
| com.typesafe | config | 1.2.1 |
| com.typesafe.scala-logging | scala-logging_2.12 | 3.7.2 |
| com.univocity | univocity-parsers | 2.9.0 |
| com.zaxxer | HikariCP | 3.1.0 |
| commons-beanutils | commons-beanutils | 1.9.4 |
| commons-cli | commons-cli | 1.2 |
| commons-codec | commons-codec | 1.10 |
| commons-collections | commons-collections | 3.2.2 |
| commons-configuration | commons-configuration | 1.6 |
| commons-dbcp | commons-dbcp | 1.4 |
| commons-digester | commons-digester | 1.8 |
| commons-fileupload | commons-fileupload | 1.3.3 |
| commons-httpclient | commons-httpclient | 3.1 |
| commons-io | commons-io | 2.4 |
| commons-lang | commons-lang | 2.6 |
| commons-logging | commons-logging | 1.1.3 |
| commons-net | commons-net | 3.1 |
| commons-pool | commons-pool | 1.5.4 |
| info.ganglia.gmetric4j | gmetric4j | 1.0.10 |
| io.airlift | aircompressor | 0,10 |
| io.dropwizard.metrics | metrics-core | 4.1.1 |
| io.dropwizard.metrics | metrics-graphite | 4.1.1 |
| io.dropwizard.metrics | metrics-healthchecks | 4.1.1 |
| io.dropwizard.metrics | metrics-jetty9 | 4.1.1 |
| io.dropwizard.metrics | metrics-jmx | 4.1.1 |
| io.dropwizard.metrics | metrics-json | 4.1.1 |
| io.dropwizard.metrics | metrics-jvm | 4.1.1 |
| io.dropwizard.metrics | metrics-servlets | 4.1.1 |
| io.netty | netty-all | 4.1.47.Final |
| jakarta.annotation | jakarta.annotation-api | 1.3.5 |
| jakarta.validation | jakarta.validation-api | 2.0.2 |
| jakarta.ws.rs | jakarta.ws.rs-api | 2.1.6 |
| javax.activation | activation | 1.1.1 |
| javax.el | javax.el-api | 2.2.4 |
| javax.jdo | jdo-api | 3.0.1 |
| javax.servlet | javax.servlet-api | 3.1.0 |
| javax.servlet.jsp | jsp-api | 2.1 |
| javax.transaction | jta | 1.1 |
| javax.transaction | transaction-api | 1.1 |
| javax.xml.bind | jaxb-api | 2.2.2 |
| javax.xml.stream | stax-api | 1.0-2 |
| javolution | javolution | 5.5.1 |
| jline | jline | 2.14.6 |
| joda-time | joda-time | 2.10.5 |
| log4j | apache-log4j-extras | 1.2.17 |
| log4j | log4j | 1.2.17 |
| net.razorvine | pyrolite | 4.30 |
| net.sf.jpam | jpam | 1.1 |
| net.sf.opencsv | opencsv | 2.3 |
| net.sf.supercsv | super-csv | 2.2.0 |
| net.snowflake | snowflake-ingest-sdk | 0.9.6 |
| net.snowflake | snowflake-jdbc | 3.12.8 |
| net.snowflake | spark-snowflake_2.12 | 2.8.1-spark_3.0 |
| net.sourceforge.f2j | arpack_combined_all | 0,1 |
| org.acplt.remotetea | remotetea-oncrpc | 1.1.2 |
| org.antlr | ST4 | 4.0.4 |
| org.antlr | antlr-runtime | 3.5.2 |
| org.antlr | antlr4-runtime | 4.7.1 |
| org.antlr | stringtemplate | 3.2.1 |
| org.apache.ant | ant | 1.9.2 |
| org.apache.ant | ant-jsch | 1.9.2 |
| org.apache.ant | ant-launcher | 1.9.2 |
| org.apache.arrow | arrow-format | 0.15.1 |
| org.apache.arrow | arrow-memory | 0.15.1 |
| org.apache.arrow | arrow-vector | 0.15.1 |
| org.apache.avro | avro | 1.8.2 |
| org.apache.avro | avro-ipc | 1.8.2 |
| org.apache.avro | avro-mapred-hadoop2 | 1.8.2 |
| org.apache.commons | commons-compress | 1.8.1 |
| org.apache.commons | commons-crypto | 1.0.0 |
| org.apache.commons | commons-lang3 | 3.9 |
| org.apache.commons | commons-math3 | 3.4.1 |
| org.apache.commons | commons-text | 1.6 |
| org.apache.curator | curator-client | 2.7.1 |
| org.apache.curator | curator-framework | 2.7.1 |
| org.apache.curator | curator-recipes | 2.7.1 |
| org.apache.derby | derby | 10.12.1.1 |
| org.apache.directory.api | api-asn1-api | 1.0.0-M20 |
| org.apache.directory.api | api-util | 1.0.0-M20 |
| org.apache.directory.server | apacheds-i18n | 2.0.0-M15 |
| org.apache.directory.server | apacheds-kerberos-codec | 2.0.0-M15 |
| org.apache.hadoop | hadoop-annotations | 2.7.4 |
| org.apache.hadoop | hadoop-auth | 2.7.4 |
| org.apache.hadoop | hadoop-client | 2.7.4 |
| org.apache.hadoop | hadoop-common | 2.7.4 |
| org.apache.hadoop | hadoop-hdfs | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-app | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-common | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-core | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-jobclient | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-shuffle | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-api | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-client | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-common | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-server-common | 2.7.4 |
| org.apache.hive | hive-beeline | 2.3.7 |
| org.apache.hive | hive-cli | 2.3.7 |
| org.apache.hive | hive-common | 2.3.7 |
| org.apache.hive | hive-exec-core | 2.3.7 |
| org.apache.hive | hive-jdbc | 2.3.7 |
| org.apache.hive | hive-llap-client | 2.3.7 |
| org.apache.hive | hive-llap-common | 2.3.7 |
| org.apache.hive | hive-metastore | 2.3.7 |
| org.apache.hive | hive-serde | 2.3.7 |
| org.apache.hive | hive-shims | 2.3.7 |
| org.apache.hive | hive-storage-api | 2.7.1 |
| org.apache.hive | hive-vector-code-gen | 2.3.7 |
| org.apache.hive.shims | hive-shims-0.23 | 2.3.7 |
| org.apache.hive.shims | hive-shims-common | 2.3.7 |
| org.apache.hive.shims | hive-shims-scheduler | 2.3.7 |
| org.apache.htrace | htrace-core | 3.1.0-incubating |
| org.apache.httpcomponents | httpclient | 4.5.6 |
| org.apache.httpcomponents | httpcore | 4.4.12 |
| org.apache.ivy | ivy | 2.4.0 |
| org.apache.orc | orc-core | 1.5.10 |
| org.apache.orc | orc-mapreduce | 1.5.10 |
| org.apache.orc | orc-shims | 1.5.10 |
| org.apache.parquet | parquet-column | 1.10.1-databricks6 |
| org.apache.parquet | parquet-common | 1.10.1-databricks6 |
| org.apache.parquet | parquet-encoding | 1.10.1-databricks6 |
| org.apache.parquet | parquet-format | 2.4.0 |
| org.apache.parquet | parquet-hadoop | 1.10.1-databricks6 |
| org.apache.parquet | parquet-jackson | 1.10.1-databricks6 |
| org.apache.thrift | libfb303 | 0.9.3 |
| org.apache.thrift | libthrift | 0.12.0 |
| org.apache.velocity | velocity | 1.5 |
| org.apache.xbean | xbean-asm7-shaded | 4.15 |
| org.apache.yetus | audience-annotations | 0.5.0 |
| org.apache.zookeeper | zookeeper | 3.4.14 |
| org.codehaus.jackson | jackson-core-asl | 1.9.13 |
| org.codehaus.jackson | jackson-jaxrs | 1.9.13 |
| org.codehaus.jackson | jackson-mapper-asl | 1.9.13 |
| org.codehaus.jackson | jackson-xc | 1.9.13 |
| org.codehaus.janino | commons-compiler | 3.0.16 |
| org.codehaus.janino | janino | 3.0.16 |
| org.datanucleus | datanucleus-api-jdo | 4.2.4 |
| org.datanucleus | datanucleus-core | 4.1.17 |
| org.datanucleus | datanucleus-rdbms | 4.1.19 |
| org.datanucleus | javax.jdo | 3.2.0-m3 |
| org.eclipse.jetty | jetty-client | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-continuation | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-http | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-io | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-jndi | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-plus | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-proxy | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-security | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-server | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-servlet | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-servlets | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-util | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-webapp | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-xml | 9.4.18.v20190429 |
| org.fusesource.leveldbjni | leveldbjni-all | 1.8 |
| org.glassfish.hk2 | hk2-api | 2.6.1 |
| org.glassfish.hk2 | hk2-locator | 2.6.1 |
| org.glassfish.hk2 | hk2-utils | 2.6.1 |
| org.glassfish.hk2 | osgi-resource-locator | 1.0.3 |
| org.glassfish.hk2.external | aopalliance-repackaged | 2.6.1 |
| org.glassfish.hk2.external | jakarta.inject | 2.6.1 |
| org.glassfish.jersey.containers | jersey-container-servlet | 2,30 |
| org.glassfish.jersey.containers | jersey-container-servlet-core | 2,30 |
| org.glassfish.jersey.core | jersey-client | 2,30 |
| org.glassfish.jersey.core | jersey-common | 2,30 |
| org.glassfish.jersey.core | jersey-server | 2,30 |
| org.glassfish.jersey.inject | jersey-hk2 | 2,30 |
| org.glassfish.jersey.media | jersey-media-jaxb | 2,30 |
| org.hibernate.validator | hibernate-validator | 6.1.0.Final |
| org.javassist | javassist | 3.25.0-GA |
| org.jboss.logging | jboss-logging | 3.3.2.Final |
| org.jdbi | jdbi | 2.63.1 |
| org.joda | joda-convert | 1.7 |
| org.jodd | jodd-core | 3.5.2 |
| org.json4s | json4s-ast_2.12 | 3.6.6 |
| org.json4s | json4s-core_2.12 | 3.6.6 |
| org.json4s | json4s-jackson_2.12 | 3.6.6 |
| org.json4s | json4s-scalap_2.12 | 3.6.6 |
| org.lz4 | lz4-java | 1.7.1 |
| org.mariadb.jdbc | mariadb-java-client | 2.1.2 |
| org.objenesis | objenesis | 2.5.1 |
| org.postgresql | postgresql | 42.1.4 |
| org.roaringbitmap | RoaringBitmap | 0.7.45 |
| org.roaringbitmap | shims | 0.7.45 |
| org.rocksdb | rocksdbjni | 6.2.2 |
| org.rosuda.REngine | REngine | 2.1.0 |
| org.scala-lang | scala-compiler_2.12 | 2.12.10 |
| org.scala-lang | scala-library_2.12 | 2.12.10 |
| org.scala-lang | scala-reflect_2.12 | 2.12.10 |
| org.scala-lang.modules | scala-collection-compat_2.12 | 2.1.1 |
| org.scala-lang.modules | scala-parser-combinators_2.12 | 1.1.2 |
| org.scala-lang.modules | scala-xml_2.12 | 1.2.0 |
| org.scala-sbt | test-interface | 1,0 |
| org.scalacheck | scalacheck_2.12 | 1.14.2 |
| org.scalactic | scalactic_2.12 | 3.0.8 |
| org.scalanlp | breeze-macros_2.12 | 1,0 |
| org.scalanlp | breeze_2.12 | 1,0 |
| org.scalatest | scalatest_2.12 | 3.0.8 |
| org.slf4j | jcl-over-slf4j | 1.7.30 |
| org.slf4j | jul-to-slf4j | 1.7.30 |
| org.slf4j | slf4j-api | 1.7.30 |
| org.slf4j | slf4j-log4j12 | 1.7.30 |
| org.spark-project.spark | unused | 1.0.0 |
| org.springframework | spring-core | 4.1.4.RELEASE |
| org.springframework | spring-test | 4.1.4.RELEASE |
| org.threeten | threeten-extra | 1.5.0 |
| org.tukaani | xz | 1.5 |
| org.typelevel | algebra_2.12 | 2.0.0-M2 |
| org.typelevel | cats-kernel_2.12 | 2.0.0-M4 |
| org.typelevel | machinist_2.12 | 0.6.8 |
| org.typelevel | macro-compat_2.12 | 1.1.1 |
| org.typelevel | spire-macros_2.12 | 0.17.0-M1 |
| org.typelevel | spire-platform_2.12 | 0.17.0-M1 |
| org.typelevel | spire-util_2.12 | 0.17.0-M1 |
| org.typelevel | spire_2.12 | 0.17.0-M1 |
| org.xerial | sqlite-jdbc | 3.8.11.2 |
| org.xerial.snappy | snappy-java | 1.1.7.5 |
| org.yaml | snakeyaml | 1.24 |
| oro | oro | 2.0.8 |
| pl.edu.icm | JLargeArrays | 1.5 |
| software.amazon.ion | ion-java | 1.0.2 |
| stax | stax-api | 1.0.1 |
| xmlenc | xmlenc | 0,52 |