¿Qué es el almacenamiento de datos en Azure Databricks?
El almacenamiento de datos hace referencia a la recopilación y el almacenamiento de datos de varios orígenes para que se pueda acceder rápidamente a ellos para obtener información empresarial e informes. Este artículo contiene conceptos clave para compilar un almacenamiento de datos en data lakehouse.
Almacenamiento de datos en lakehouse
La arquitectura lakehouse y Databricks SQL aportan funcionalidades de almacenamiento de datos en la nube a los lagos de datos. Con las estructuras de datos, las relaciones y las herramientas de administración conocidas, puede modelar un almacenamiento de datos de alto rendimiento y rentable que se ejecuta directamente en el lago de datos. Para más información, consulte ¿Qué es un almacén de lago de datos?
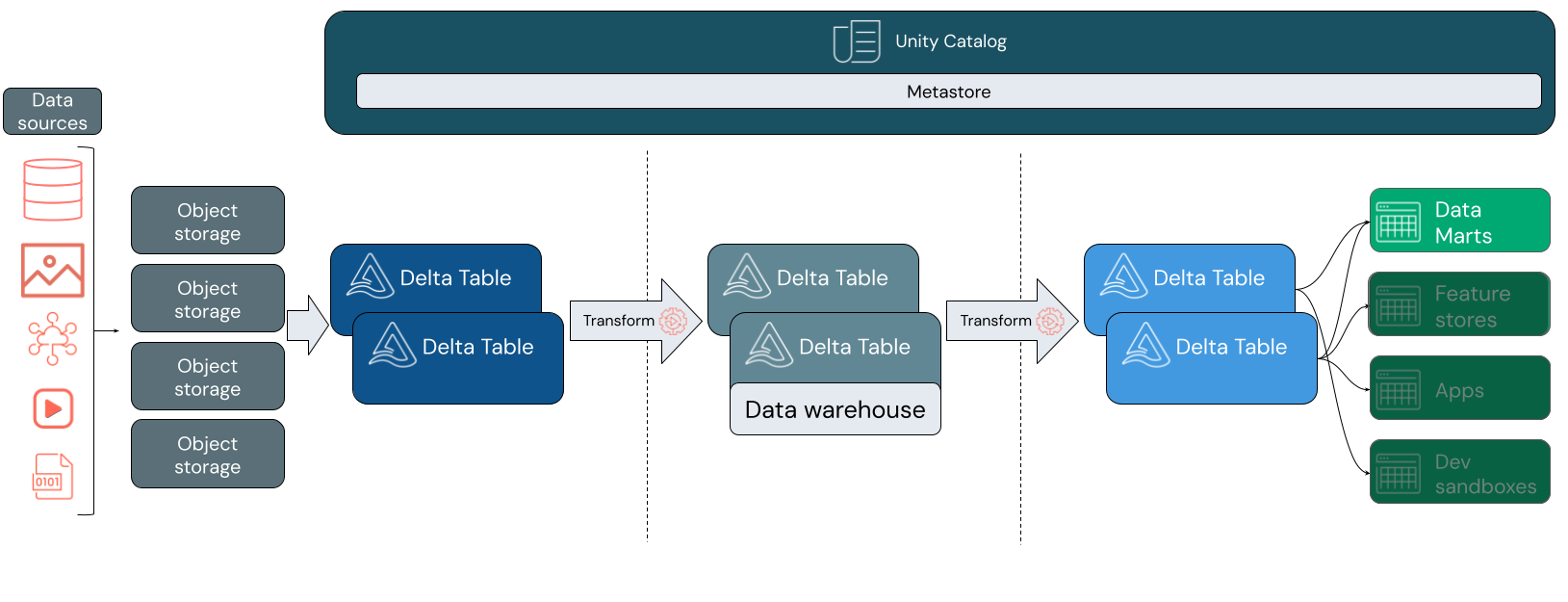
Al igual que con un almacenamiento de datos tradicional, modela los datos según los requisitos empresariales y, a continuación, los sirve a los usuarios finales para análisis e informes. A diferencia de un almacén de datos tradicional, puede evitar el aislamiento de sus datos de análisis empresarial o la creación de copias redundantes que se quedan obsoletas rápidamente.
La compilación de un almacén de datos dentro de su lakehouse le permite traer todos sus datos a un único sistema y aprovechar funciones como el catálogo de Unity y Delta Lake.
Catálogo de Unity agrega un modelo de gobernanza unificado para que pueda proteger y auditar el acceso a los datos y proporcionar información de linaje sobre las tablas de bajada. Delta Lake agrega transacciones ACID y evolución del esquema, entre otras herramientas eficaces para mantener los datos confiables, escalables y de alta calidad.
¿Qué es Databricks SQL?
Nota:
Databricks SQL sin servidor no está disponible en Azure China. Databricks SQL no está disponible en las regiones de Azure Government.
Databricks SQL es la colección de servicios que proporcionan funcionalidades de almacenamiento de datos y rendimiento a los lagos de datos existentes. Databricks SQL admite formatos abiertos y ANSI SQL estándar. Las herramientas de panel y editor de SQL en la plataforma permiten a los miembros del equipo colaborar con otros usuarios de Databricks directamente en el área de trabajo. Databricks SQL también se integra con una variedad de herramientas para que los analistas puedan crear consultas y paneles en sus entornos favoritos sin ajustar a una nueva plataforma.
Databricks SQL proporciona recursos de proceso generales que se ejecutan en las tablas de lakehouse. Databricks SQL se basa en Almacenes de SQL, lo que ofrece recursos de proceso de SQL escalables desacoplados del almacenamiento.
Consulte ¿Qué es un almacén de SQL? para obtener más información sobre los valores predeterminados y las opciones de almacenes de SQL.
Databricks SQL se integra con Unity Catalog para que pueda descubrir, auditar y controlar los activos de datos desde un único lugar. Para obtener más información, consulte ¿Qué es el catálogo de Unity?
Modelado de datos en Azure Databricks
Un lakehouse admite una variedad de estilos de modelado. En la imagen siguiente se muestra cómo se mantienen y modelan los datos a medida que se mueven a través de diferentes capas de lakehouse.
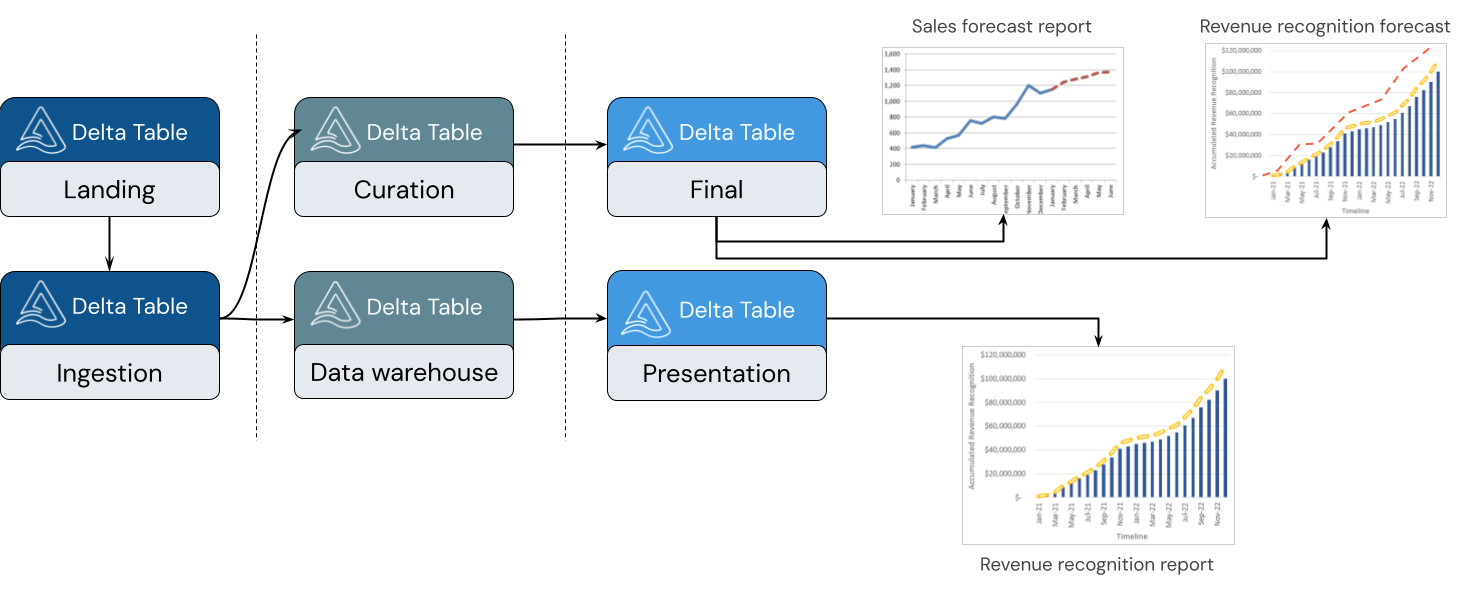
Arquitectura de Medallion
La arquitectura de medallón es un patrón de diseño de datos que describe una serie de capas de datos refinadas incrementalmente que proporcionan una estructura básica en el lakehouse. Las capas de bronce, plata y oro significan un aumento de la calidad de los datos en cada nivel, con oro que representa la más alta calidad. Para obtener más información, consulte ¿Qué es la arquitectura de medallion de almacén de lago?.
Dentro de lakehouse, cada capa puede contener una o más tablas. El almacenamiento de datos se modela en la capa de plata y alimenta data marts especializados en la capa de oro.
Capa de bronce
Los datos pueden introducir su lakehouse en cualquier formato y a través de cualquier combinación de transacciones por lotes o de vapor. La capa de bronce proporciona el espacio de aterrizaje para todos los datos sin procesar en su formato original. Esos datos se convierten en tablas Delta.
Capa de plata
La capa de plata reúne los datos de diferentes orígenes. Para la parte de la empresa que se centra en las aplicaciones de ciencia de datos y aprendizaje automático, aquí es donde empieza a seleccionar recursos de datos significativos. Este proceso suele estar marcado por un enfoque en la velocidad y la agilidad.
La capa plateada es también donde se pueden integrar cuidadosamente los datos procedentes de orígenes distintos para compilar un almacén de datos en consonancia con los procesos empresariales existentes. A menudo, estos datos siguen un tercer formulario normal (3NF) o un modelo de Data Vault. Especificar restricciones de clave principal y externa permite a los usuarios finales comprender las relaciones de tabla al usar el catálogo de Unity. El almacenamiento de datos debe servir como origen único de verdad para los data marts.
El propio almacenamiento de datos es de esquema en escritura y atómico. Está optimizado para el cambio, por lo que puede modificar rápidamente el almacenamiento de datos para que coincida con sus necesidades actuales cuando los procesos empresariales cambian o evolucionan.
Capa de oro
La capa dorada es la capa de presentación, que puede contener uno o varios data marts. Con frecuencia, los data marts son modelos dimensionales en forma de un conjunto de tablas relacionadas que capturan una perspectiva empresarial específica.
La capa de oro también alberga espacios aislados de ciencia de datos y departamento para permitir el análisis de autoservicio y la ciencia de datos en toda la empresa. Proporcionar estos espacios aislados y sus propios clústeres de proceso independientes impide que los equipos empresariales creen copias de datos fuera de lakehouse.
Paso siguiente
Para obtener más información sobre los principios y procedimientos recomendados para implantar y gestionar almacenes de lago con Databricks, consulte Introducción a la buena arquitectura de almacenes de lago de datos.