Habilitar los volcados de montón de los servicios de Apache Hadoop en HDInsight basado en Linux
Los volcados de montón contienen una instantánea de la memoria de la aplicación, incluidos los valores de variables en el momento en el que se creó el volcado de memoria. Por lo tanto, son útiles para diagnosticar los problemas que se producen en tiempo de ejecución.
Servicios
Puede habilitar los volcados de montón en los siguientes servicios:
- Apache HCatalog: tempelton
- Apache Hive: hiveserver2, metastore, derbyserver
- mapreduce - jobhistoryserver
- Apache Yarn: resourcemanager, nodemanager, timelineserver
- Apache HDFS: datanode, secondarynamenode, namenode
También puede habilitar los volcados de montón para los procesos de asignación y ejecución que ejecuta HDInsight.
Información de la configuración del volcado de montón
Son las opciones de paso (también conocidas como opciones o parámetros) las que habilitan los volcados de montón en JVM cuando se inicia un servicio. En la mayoría de los servicios de Apache Hadoop, puede modificar el script de shell empleado para iniciar el servicio para pasar estas opciones.
En cada script, hay una exportación para *_OPTS, que contiene las opciones que se pasan a JVM. Por ejemplo, en el script hadoop env.sh, la línea que comienza con export HADOOP_NAMENODE_OPTS= contiene las opciones del servicio NameNode.
La asignación y reducción de procesos son tareas ligeramente diferentes, ya que se tratan de procesos secundarios del servicio MapReduce. Cada proceso de asignación o reducción se ejecuta en un contenedor secundario y existen dos entradas que contienen las opciones de JVM. Ambos están en mapred-site.xml:
- mapreduce.admin.map.child.java.opts
- mapreduce.admin.reduce.child.java.opts
Nota
Se recomienda usar Apache Ambari para modificar los scripts y la configuración de mapred-site.xml, puesto que Ambari controla la replicación de los cambios en los nodos del clúster. Consulte la sección Uso de Apache Ambari para obtener los pasos específicos que debe dar.
Habilitar los volcados de montón
La siguiente opción habilita los volcados del montón cuando se produce un OutOfMemoryError:
-XX:+HeapDumpOnOutOfMemoryError
El símbolo + indica que esta opción está habilitada, ya que está deshabilitada de forma predeterminada.
Advertencia
Los volcados de montón no están habilitados para los servicios Hadoop en HDInsight, ya que el tamaño de los archivos de volcado puede ser grande. Si los habilita para solucionar problemas, no olvide deshabilitarlos una vez haya reproducido el problema y recopilado los archivos de volcado.
Ubicación de volcado
La ubicación predeterminada del archivo de volcado es el directorio en el cual está trabajando. Puede decidir dónde guardar el archivo con la siguiente opción:
-XX:HeapDumpPath=/path
Por ejemplo, al usar -XX:HeapDumpPath=/tmp, los volcados se almacenarán en el directorio /tmp.
Scripts
También puede desencadenar un script cuando se produzca un error OutOfMemoryError . Por ejemplo, puede desencadenar una notificación que le avise de que el error se ha producido. Utilice la siguiente opción para desencadenar un script en un error OutOfMemoryError:
-XX:OnOutOfMemoryError=/path/to/script
Nota
Puesto que Apache Hadoop es un sistema distribuido, debe colocar cualquier script que use en todos los nodos del clúster que ejecute el servicio.
Asimismo, el script debe estar en una ubicación que sea accesible para la cuenta con la cual se ejecuta el servicio y deberá proporcionar permisos de ejecución. A modo de ejemplo, es posible que desee almacenar los scripts en /usr/local/bin y usar chmod go+rx /usr/local/bin/filename.sh para conceder permisos de ejecución y lectura.
Uso de Apache Ambari
Para modificar la configuración de un servicio, siga estos pasos:
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net, dondeCLUSTERNAMEes el nombre del clúster.En la lista de la izquierda, seleccione el área de servicio que desea modificar. Por ejemplo, HDFS. En el área central, seleccione la ficha Configuraciones .

Mediante la entrada Filtrar..., escriba opciones. Solo se muestran los elementos que contienen este texto.
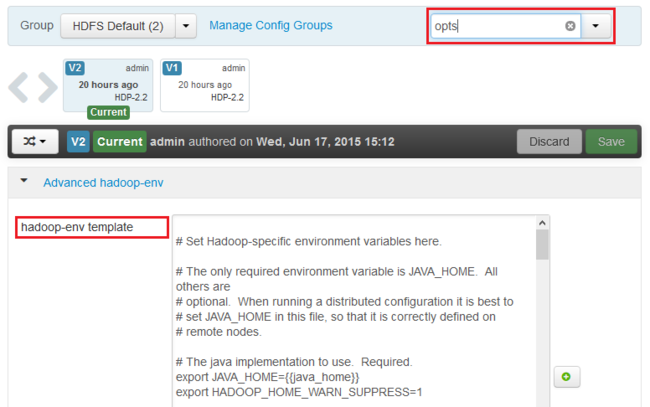
Busque la entrada *_OPTS del servicio en el cual desea habilitar los volcados de montón y agregue las opciones que desee habilitar. En la siguiente imagen, he agregado
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/a la entrada HADOOP_NAMENODE_OPTS: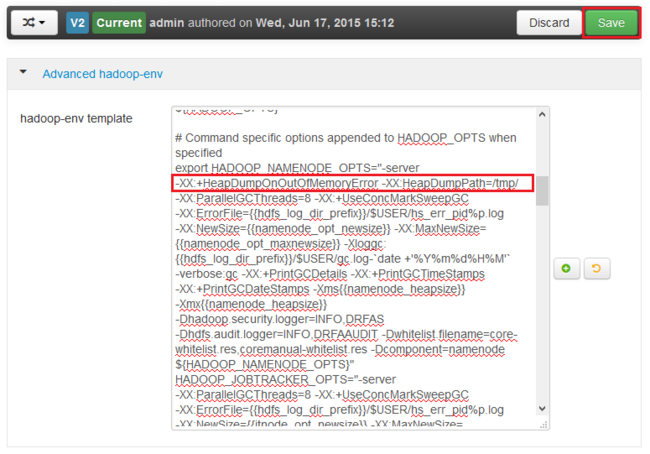
Nota:
Al habilitar los volcados de montón para el proceso secundario de asignación o reducción, busque los campos con los nombres mapreduce.admin.map.child.java.opts y mapreduce.admin.reduce.child.java.opts.
Presione el botón Guardar para guardar los cambios. Puede elaborar una nota breve en la que se describan los cambios.
Una vez que se hayan aplicado los cambios, aparecerá el icono Es necesario reiniciar junto a uno o más servicios.
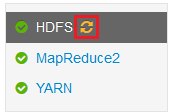
Seleccione cada uno de los servicios que necesite reiniciar y pulse el botón Acciones de servicio para seleccionar la opción Activar modo de mantenimiento. El modo de mantenimiento evita que se generen alertas desde el servicio al reiniciarlo.
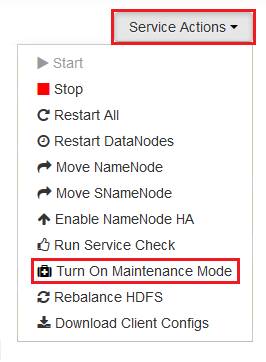
Una vez habilitado el modo de mantenimiento, pulse el botón Reiniciar para que el servicio pueda Reiniciar todos los afectados
Nota:
Es posible que las entradas del botón Reiniciar sean diferentes en otros servicios.
Una vez haya reiniciado los servicios, pulse el botón Acciones de servicio para Desactivar el modo de mantenimiento. Esto hará que Ambari reanude la supervisión de alertas para el servicio.