Habilitación de Azure Machine Learning Studio en una Azure Virtual Network
Sugerencia
Microsoft recomienda utilizar las redes virtuales administradas de Azure Machine Learning en lugar de los pasos de este artículo. Con una red virtual administrada, Azure Machine Learning se hace cargo del trabajo de aislamiento de red para el área de trabajo y los procesos administrados. También puede agregar puntos de conexión privados para los recursos necesarios para el área de trabajo, como la cuenta de Azure Storage. Para más información, consulte Aislamiento de red gestionada del área de trabajo.
En este artículo se explica cómo usar Azure Machine Learning Studio en una red virtual. Studio incluye características como AutoML, el diseñador y el etiquetado de datos.
Algunas de las características de Studio están deshabilitadas de forma predeterminada en una red virtual. Para volver a habilitarlas, debe habilitar la identidad administrada para las cuentas de almacenamiento que desea usar en Studio.
Las siguientes operaciones están deshabilitadas de forma predeterminada en una red virtual:
- Vista previa de los datos en Studio.
- Visualización de los datos en el diseñador.
- Implementación de un modelo en el diseñador.
- Envío de un experimento de AutoML.
- Inicio de un proyecto de etiquetado.
Studio admite la lectura de datos de los siguientes tipos de almacén de datos en una red virtual:
- Cuenta de Azure Storage (blob y archivo)
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure SQL Database
En este artículo aprenderá a:
- Proporcionar a Studio acceso a los datos almacenados dentro de una red virtual.
- Obtener acceso a Studio desde un recurso dentro de una red virtual.
- Comprender cómo Studio afecta a la seguridad del almacenamiento.
Requisitos previos
Lea el artículo Introducción a la seguridad de red para comprender la arquitectura y los escenarios comunes de redes virtuales.
Una red virtual y una subred preexistentes que se usarán.
- Para aprender cómo crear un área de trabajo seguro, consulte Tutorial: Creación de un área de trabajo seguro o Tutorial: Creación de un área de trabajo seguro mediante una plantilla.
Limitaciones
Cuenta de Azure Storage
Cuando la cuenta de almacenamiento está en la red virtual, hay requisitos de validación adicionales para usar Studio:
- Si la cuenta de almacenamiento usa un punto de conexión de servicio, el punto de conexión privado del área de trabajo y el punto de conexión de servicio de almacenamiento deben estar en la misma subred de la red virtual.
- Si la cuenta de almacenamiento usa un punto de conexión privado, el punto de conexión privado del área de trabajo y el punto de conexión privado del almacenamiento deben estar en la misma red virtual. En este caso, pueden estar en subredes diferentes.
Canalización de ejemplo del diseñador
Hay un problema conocido por el que los usuarios no pueden ejecutar una canalización de ejemplo en la página principal del diseñador. Este problema se produce porque el conjunto de datos de ejemplo usado en la canalización de ejemplo es un conjunto de datos globales de Azure. No se puede acceder desde un entorno de red virtual.
Para resolver este problema, use un área de trabajo pública para ejecutar la canalización de ejemplo. O bien, reemplace el conjunto de datos de ejemplo por su propio conjunto de datos en el área de trabajo dentro de una red virtual.
Almacén datos: cuenta de Azure Storage
Siga estos pasos para habilitar el acceso a los datos almacenados en Azure Blob Storage y File Storage:
Sugerencia
El primer paso no es necesario para la cuenta de almacenamiento predeterminada del área de trabajo. Los restantes pasos son necesarios para todas las cuentas de almacenamiento que se encuentren detrás de la red virtual y que el área de trabajo usa, incluida la cuenta de almacenamiento predeterminada.
Si la cuenta de almacenamiento es el almacenamiento predeterminado de su área de trabajo, omita este paso . Si no es el valor predeterminado, conceda a la identidad administrada del área de trabajo el rol de Lector de datos de Storage Blob para la cuenta de Azure Storage para que pueda leer datos de Blob Storage.
Para más información, consulte el rol integrado Lector de datos de blob.
Conceda a su identidad de usuario de Azure el rol Lector de datos de Storage Blob para la cuenta de Azure Storage. Studio usa la identidad para acceder a los datos a Blob Storage, incluso si la identidad administrada del área de trabajo tiene el rol Lector.
Para más información, consulte el rol integrado Lector de datos de blob.
Conceda a la identidad administrada del área de trabajo el rol Lector para los puntos de conexión privados de almacenamiento. Si el servicio de almacenamiento usa un punto de conexión privado, conceda a la identidad administrada del área de trabajo acceso de Lector al punto de conexión privado. La identidad administrada del área de trabajo de Microsoft Entra ID se llama igual que el área de trabajo de Azure Machine Learning. Se necesita un punto de conexión privado para tipos de almacenamiento de blobs y archivos.
Sugerencia
La cuenta de almacenamiento puede tener varios puntos de conexión privados. Por ejemplo, una cuenta de almacenamiento puede tener un punto de conexión privado independiente para blobs, archivos e instancias de DFS (Azure Data Lake Storage Gen2). Agregue la identidad administrada a todos estos puntos de conexión.
Para más información, consulte el rol integrado Lector.
Habilite la autenticación de la identidad administrada en las cuentas de almacenamiento predeterminadas. Cada área de trabajo de Azure Machine Learning tiene dos cuentas de almacenamiento, una cuenta de almacenamiento de blobs y una cuenta de almacenamiento de archivos predeterminadas. Ambos se definen al crear el área de trabajo. También puede establecer nuevos valores predeterminados en la página de administración del almacén de datos.
En la tabla siguiente se describe el motivo por el que se usa la autenticación de identidad administrada para las cuentas de almacenamiento predeterminadas del área de trabajo.
Cuenta de almacenamiento Notas Almacenamiento de blobs predeterminado del área de trabajo Almacena recursos del modelo desde el diseñador. Habilite la autenticación de identidad administrada en esta cuenta de almacenamiento para implementar modelos en el diseñador. Si la autenticación de identidad administrada está deshabilitada, la identidad del usuario se usa para acceder a los datos almacenados en el blob.
Puede visualizar y ejecutar una canalización del diseñador si usa un almacén de datos no predeterminado que se ha configurado para utilizar una identidad administrada. Sin embargo, si intenta implementar un modelo entrenado sin la identidad administrada habilitada en el almacén de datos predeterminado, se produce un error en la implementación independientemente de que se usen otros almacenes de datos.Almacén de archivos predeterminado del área de trabajo Almacena los recursos de experimentos de AutoML. Habilite la autenticación de identidad administrada en esta cuenta de almacenamiento para enviar experimentos de AutoML. Configuración de almacenes de datos para usar la autenticación de la identidad administrada. Después de agregar una cuenta de Azure Storage a la red virtual con un punto de conexión de servicio o un punto de conexión privado, debe configurar el almacén de datos para usar la autenticación de identidad administrada. Esto permite que Studio tenga acceso a los datos de la cuenta de almacenamiento.
Azure Machine Learning usa almacenes de datos para conectarse a las cuentas de almacenamiento. Al crear un almacén de datos, siga estos pasos para configurar un almacén de datos para usar la autenticación de la identidad administrada:
En Studio, seleccione Almacenes de datos.
Para crear un nuevo almacén de datos, seleccione + Crear.
En la configuración del almacén de datos, active el modificador para Usar la identidad administrada del área de trabajo para la vista previa de datos y la generación de perfiles en Azure Machine Learning Studio.
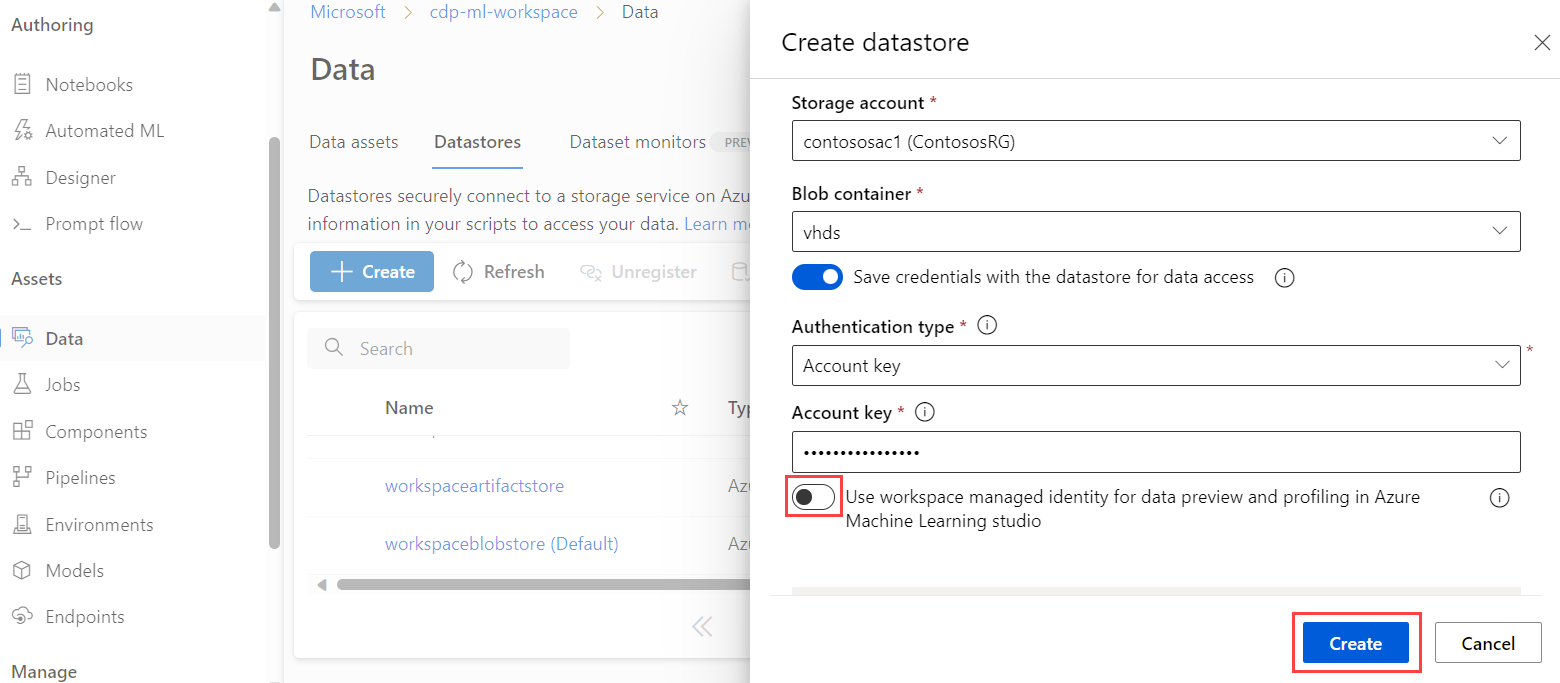
En la configuración de redes para la cuenta de Azure Storage, agregue el
Microsoft.MachineLearningService/workspacestipo de recurso y establezca el nombre de instancia en el área de trabajo.
En estos pasos se agrega la identidad administrada del área de trabajo como Lector al nuevo servicio de almacenamiento mediante el control de acceso basado en roles de Azure (RBAC). El acceso de Lector permite al área de trabajo ver el recurso, pero no realizar cambios.


Almacén de datos: Azure Data Lake Storage Gen1
Si usa Azure Data Lake Storage Gen1 como almacén de datos, solo puede utilizar listas de control de acceso de estilo POSIX. Puede asignar el acceso de la identidad administrada del área de trabajo a los recursos como cualquier otra entidad de seguridad. Para obtener más información, vea Control de acceso en Azure Data Lake Storage Gen1.
Almacén de datos: Azure Data Lake Storage Gen2
Si usa Azure Data Lake Storage Gen2, como almacén de datos, puede usar listas de control de acceso de Azure RBAC y de estilo POSIX para controlar el acceso a los datos dentro de una red virtual.
Para usar Azure RBAC, siga los pasos de la sección Almacén de datos: cuenta de Azure Storage de este artículo. Data Lake Storage Gen2 se basa en Azure Storage, por lo que se aplican los mismos pasos al usar Azure RBAC.
Para usar las listas de control de acceso, el acceso de la identidad administrada del área de trabajo se puede asignar como cualquier otra entidad de seguridad. Para obtener más información, vea Listas de control de acceso en archivos y directorios.
Almacén de datos: Azure SQL Database
Para acceder a los datos almacenados en una base de datos de Azure SQL Database con una identidad administrada, debe crear un usuario independiente de SQL que se asigne a la identidad administrada. Para obtener más información sobre cómo crear un usuario desde un proveedor externo, consulte Creación de usuarios independientes asignados a identidades de Microsoft Entra.
Después de crear un usuario independiente de SQL, utilice el comando GRANT de T-SQL para concederle permisos.
Salida de componente intermedio
Cuando se usa la salida de componente intermedio del diseñador de Azure Machine Learning, se puede especificar la ubicación de salida de cualquier componente del diseñador. Use esta salida para almacenar conjuntos de datos intermedios en una ubicación independiente para la seguridad, el registro o la auditoría. Para especificar la salida, siga estos pasos:
- Seleccione el componente cuya salida quiere especificar.
- En el panel de configuración del componente, seleccione Configuración de salida.
- Especifique el almacén de datos que quiere usar para cada salida de componente.
Asegúrese de que tiene acceso a las cuentas de almacenamiento intermedias en la red virtual. De lo contrario, se produce un error en la canalización.
Habilite la autenticación de identidad administrada para las cuentas de almacenamiento intermedias para visualizar los datos de salida.
Acceso a Studio desde un recurso dentro de una red virtual
Si accede a Studio desde un recurso dentro de una red virtual (por ejemplo, una instancia de proceso o una máquina virtual), tendrá que permitir el tráfico de salida desde la red virtual a Studio.
Por ejemplo, si usa grupos de seguridad de red (NSG) para restringir el tráfico de salida, agregue una regla a un destino de etiqueta de servicio de AzureFrontDoor.Frontend.
Configuración de firewall
La configuración del firewall de algunos servicios de almacenamiento, como las cuentas de almacenamiento de Azure, se aplica al punto de conexión público para esa instancia del servicio específica. Normalmente, con esta configuración puede permitir o impedir el acceso desde direcciones IP concretas de la red pública de Internet. Esto no se admite cuando se usa Estudio de Azure Machine Learning, pero sí cuando se usa la CLI o el SDK de Azure Machine Learning.
Sugerencia
Estudio de Azure Machine Learning se admite cuando se usa el servicio Azure Firewall. Para obtener más información, consulte Configuración del tráfico de red de entrada y salida.
Contenido relacionado
Este artículo forma parte de una serie sobre la protección de un flujo de trabajo de Azure Machine Learning. Consulte los demás artículos de esta serie: