Visualización del código de entrenamiento para un modelo de ML automatizado
En este artículo, aprenderá a ver el código de entrenamiento generado desde cualquier modelo entrenado de aprendizaje automático automatizado.
La generación de código para modelos entrenados de aprendizaje automático automatizado permite ver los siguientes detalles que el aprendizaje automático automatizado usa para entrenar y compilar el modelo para una ejecución concreta.
- Preprocesamiento de datos
- Selección del algoritmo
- Caracterización
- Hiperparámetros
Puede seleccionar cualquier modelo de aprendizaje automático automatizado, con ejecución recomendada o secundaria, y ver el código de entrenamiento de Python generado que creó ese modelo concreto.
Con el código de entrenamiento del modelo generado, puede:
- Obtener información sobre el proceso de caracterización y los hiperparámetros que usa el algoritmo del modelo.
- Realizar un seguimiento, controlar la versión y realizar una auditoría de los modelos entrenados. Almacene el código con control de versiones para realizar un seguimiento de qué código de entrenamiento específico se usa con el modelo que se va a implementar en producción.
- Personalizar el código de entrenamiento mediante el cambio de hiperparámetros o la aplicación de sus aptitudes o experiencia en Machine Learning y algoritmos, y volver a entrenar un nuevo modelo con su código personalizado.
En el diagrama siguiente se muestra que puede generar el código para experimentos de aprendizaje automático automatizados con todos los tipos de tareas. En primer lugar, seleccione un modelo. El modelo seleccionado se resalta, Azure Machine Learning copia los archivos de código usados para crear el modelo y los muestra en la carpeta compartida de los cuadernos. Desde ahí, se puede ver y personalizar el código tanto como sea necesario.
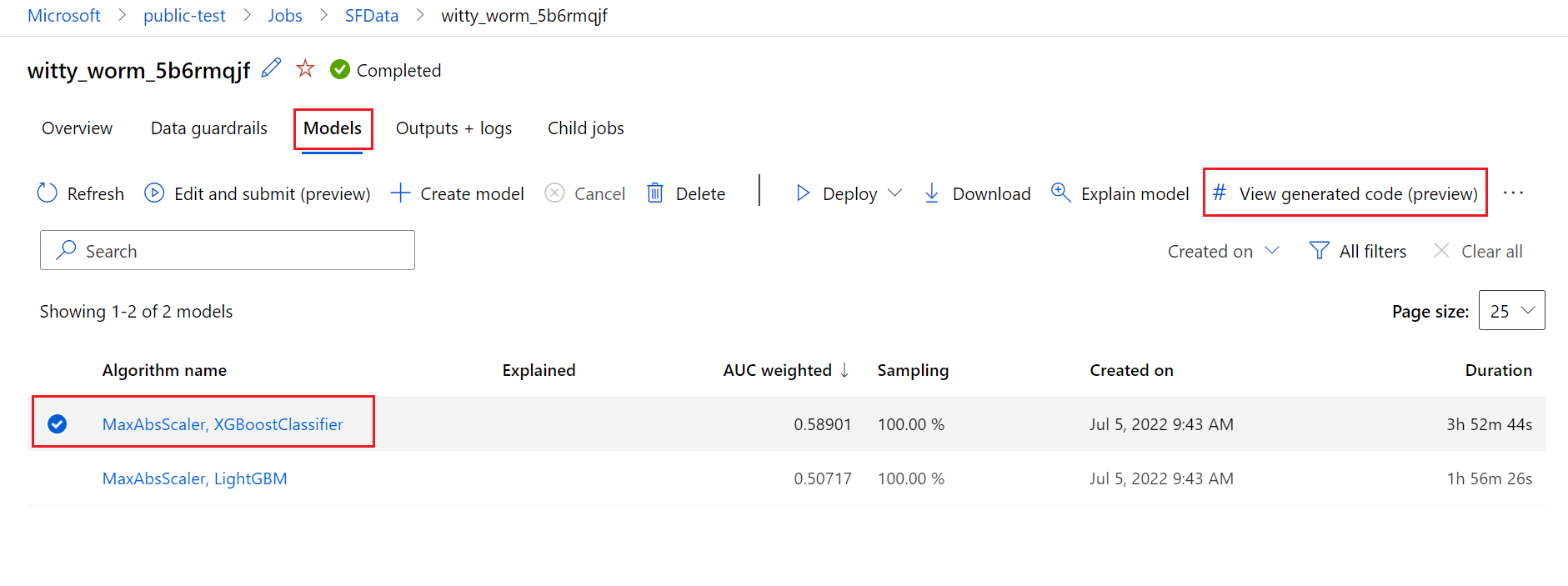
Requisitos previos
Un área de trabajo de Azure Machine Learning. Para crear el área de trabajo, consulte Creación de recursos del área de trabajo.
En este artículo se presupone una familiarización con la configuración de un experimento de aprendizaje de automático automatizado. Siga el tutorial o los procedimientos para ver los principales modelos de diseño del experimento de aprendizaje automático automatizado.
La generación de código de ML automatizado solo está disponible para los experimentos que se ejecutan en destinos de proceso remotos de Azure Machine Learning. No se admite la generación de código para las ejecuciones locales.
Todas las ejecuciones de ML automatizadas desencadenadas a través de Estudio de Azure Machine Learning, SDKv2 o CLIv2 tendrán habilitada la generación de código.
Obtención del código generado y los artefactos del modelo
De forma predeterminada, cada modelo entrenado de ML automatizado genera su código de entrenamiento cuando se completa el entrenamiento. ML automatizado guarda este código en la carpeta outputs/generated_code del experimento para ese modelo concreto. Puede verlos en la interfaz de usuario de Estudio de Azure Machine Learning en la pestaña Resultados y registros del modelo seleccionado.
script.py. Es el código de entrenamiento del modelo que probablemente quiera analizar con los pasos de caracterización, el algoritmo específico usado y los hiperparámetros.
script_run_notebook.ipynb. Cuaderno con código reutilizable para ejecutar el código de entrenamiento del modelo (script.py) en el proceso de Azure Machine Learning a través del SDKv2 de Azure Machine Learning.
Una vez completada la ejecución de entrenamiento de ML automatizado, puede acceder a los archivos script.py y script_run_notebook.ipynb a través de la UI de Estudio de Azure Machine Learning.
Para ello, vaya a la pestaña Modelos de la página de ejecución primaria del experimento de ML automatizado. Después de seleccionar uno de los modelos entrenados, puede seleccionar el botón Ver código generado. Este botón le redirige a la extensión del portal Notebooks, donde puede ver, editar y ejecutar el código generado para ese modelo concreto seleccionado.
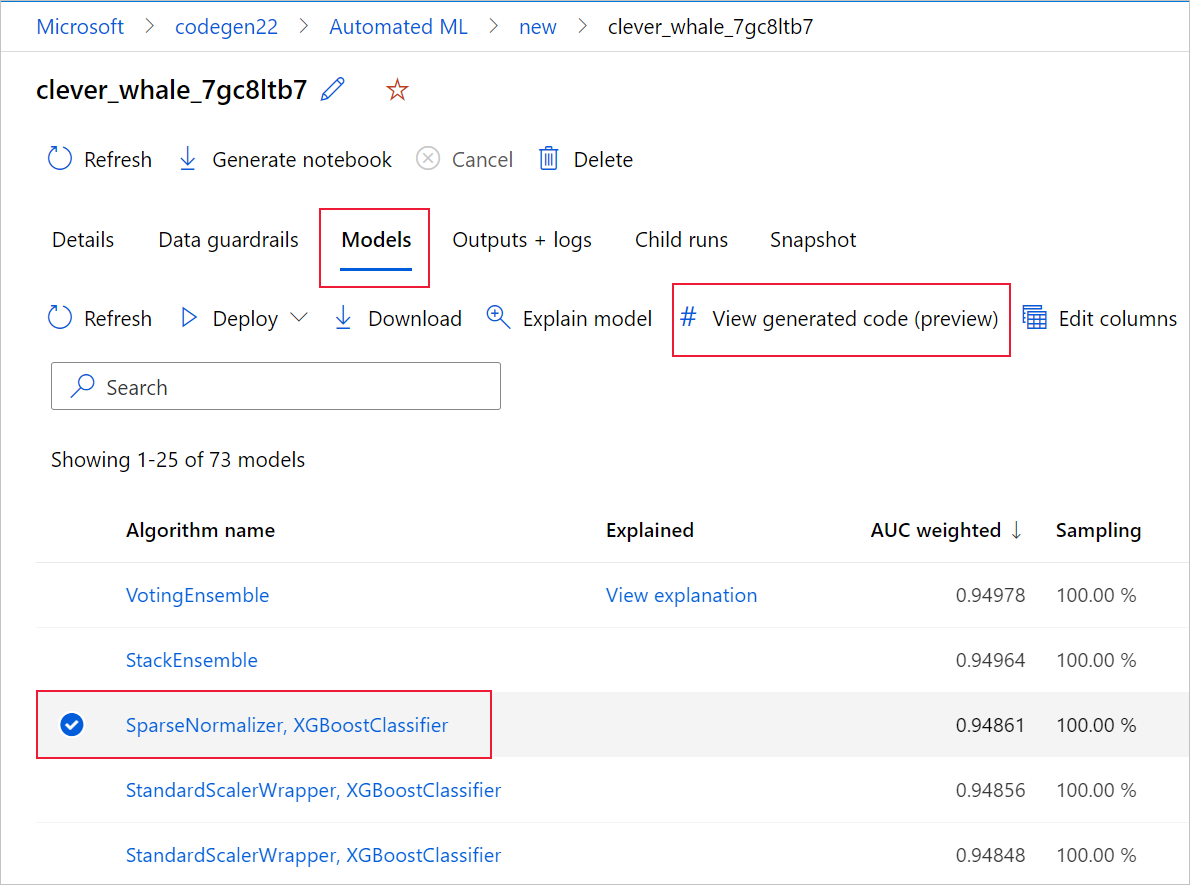
También se puede acceder al código generado del modelo desde la parte superior de la página de la ejecución secundaria una vez que se accede a la página de esa ejecución secundaria de un modelo determinado.
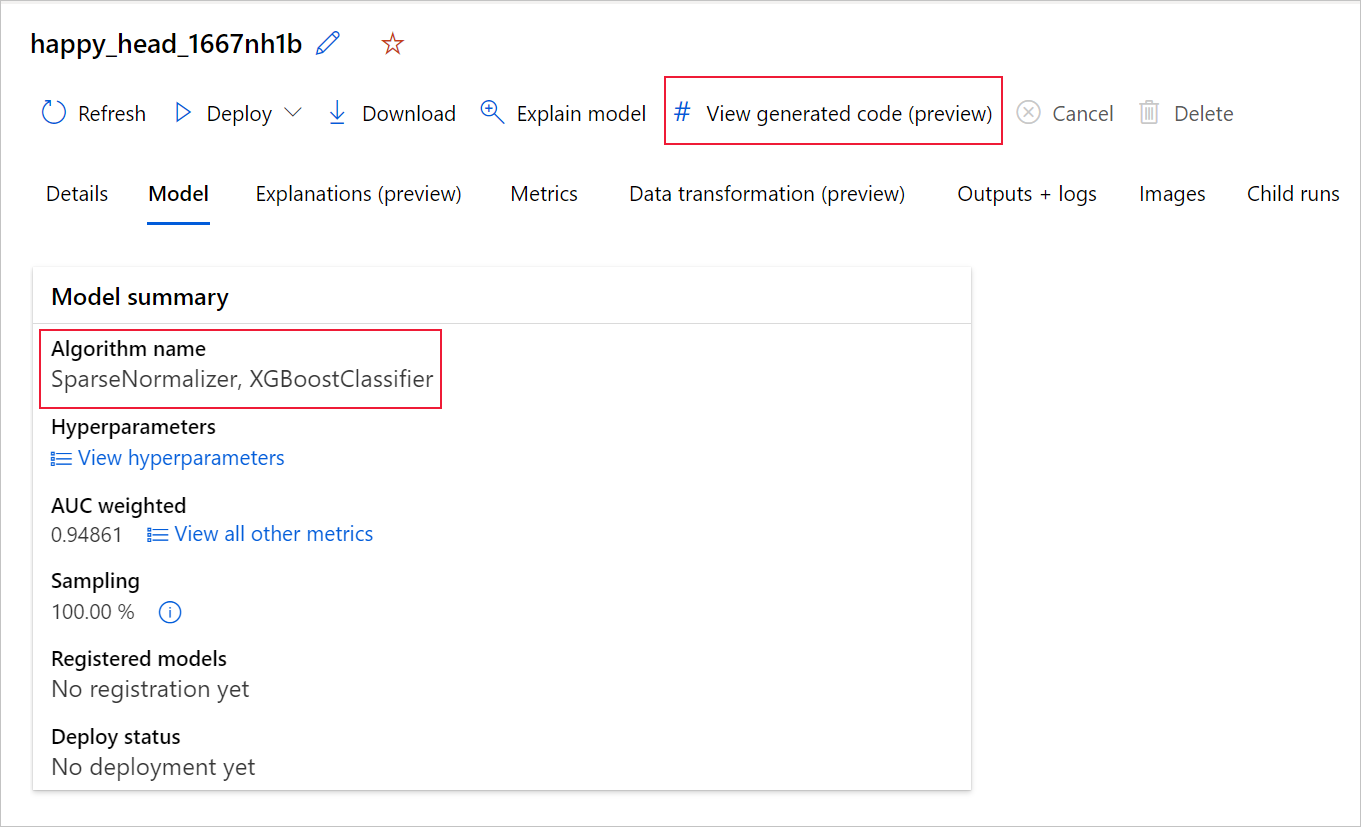
Si usa el SDKv2 de Python, también puede descargar "script.py" y "script_run_notebook.ipynb" recuperando la mejor ejecución a través de MLFlow y descargando los artefactos resultantes.
Limitaciones
Hay un problema conocido al seleccionar Ver código generado. Esta acción no se puede redirigir al portal de Notebooks cuando el almacenamiento está detrás de una red virtual. Como solución alternativa, el usuario puede descargar manualmente el script.py y los archivos script_run_notebook.ipynb. Para ello, vaya a la pestaña Salidas y registros en la carpeta outputs>generated_code. Estos archivos se pueden cargar manualmente en la carpeta de Notebooks para ejecutarlos o editarlos. Siga este vínculo para más información sobre las redes virtuales en Azure Machine Learning.
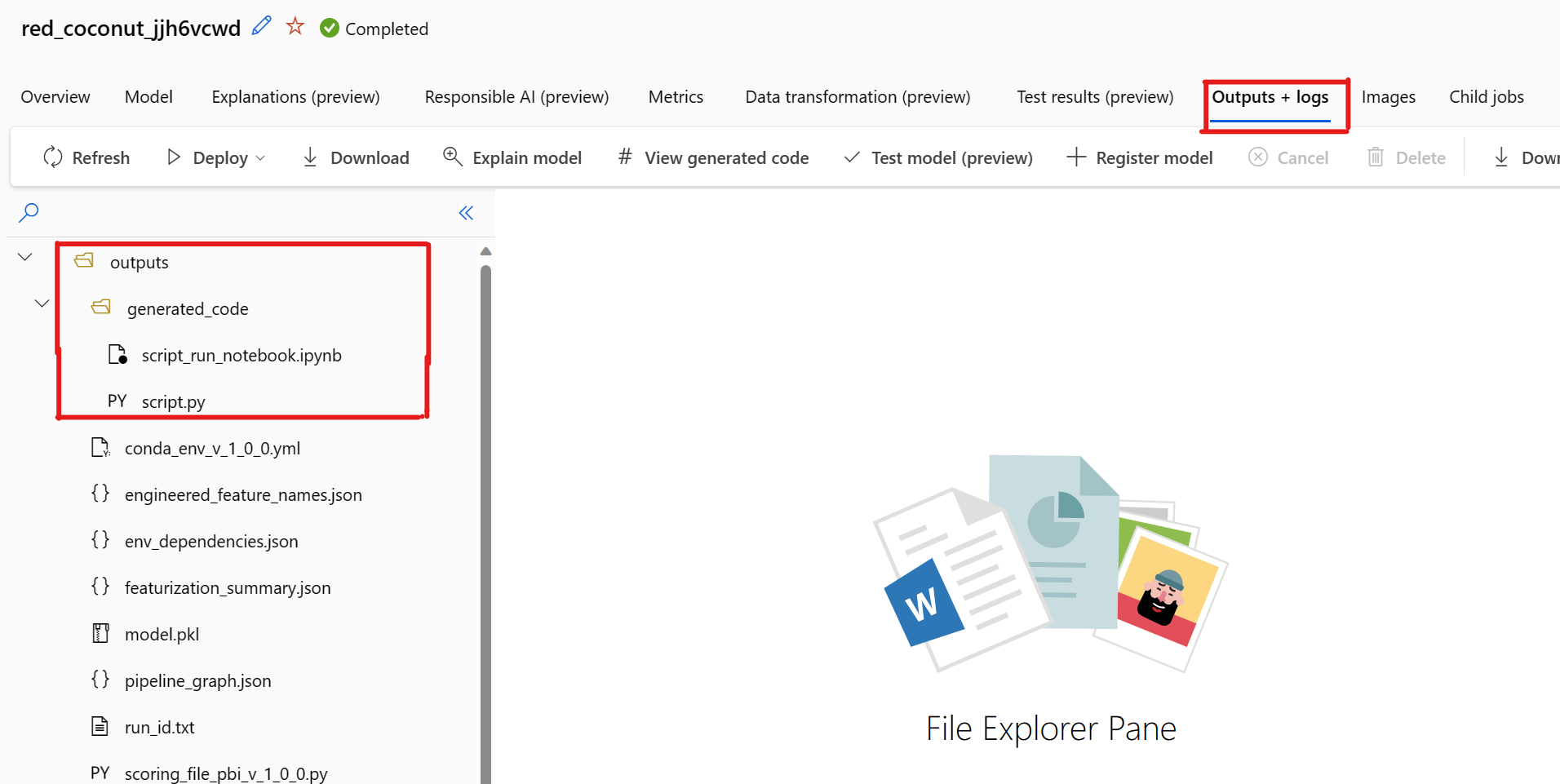
script.py
El archivo script.py contiene la lógica básica necesaria para entrenar un modelo con los hiperparámetros usados anteriormente. Aunque está previsto que se ejecute en el contexto de una ejecución de script de Azure Machine Learning, con algunas modificaciones, el código de entrenamiento del modelo también se puede ejecutar de forma independiente en su propio entorno local.
Someramente, el script se puede dividir en varias de las siguientes partes: carga de datos, preparación de datos, caracterización de datos, especificación de preprocesador o algoritmo, y entrenamiento.
Carga de datos
La función get_training_dataset() carga el conjunto de datos usado anteriormente. Se supone que el script se ejecuta en un script de Azure Machine Learning que se ejecuta en la misma área de trabajo que el experimento original.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Cuando se ejecuta como parte de una ejecución de script, Run.get_context().experiment.workspace recupera el área de trabajo correcta. Sin embargo, si este script se ejecuta dentro de un área de trabajo diferente o localmente, debe modificar el script para especificar explícitamente el área de trabajo apropiada.
Una vez que se ha recuperado el área de trabajo, su identificador recupera el conjunto de datos original. Otro conjunto de datos con exactamente la misma estructura también se puede especificar por identificador o nombre con get_by_id() o get_by_name(), respectivamente. Puede encontrar el identificador más adelante en el script, en una sección similar a la del código siguiente.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
También puede optar por reemplazar toda esta función por su propio mecanismo de carga de datos; las únicas restricciones son que el valor devuelto debe ser una trama de datos de Pandas y que los datos deben tener la misma forma que en el experimento original.
Código de preparación de datos
La función prepare_data() limpia los datos, divide las columnas de características y peso de ejemplo, y prepara los datos para usarlos en el entrenamiento.
Esta función puede variar en función del tipo de conjunto de datos y el tipo de tarea del experimento: clasificación, regresión, previsión de series temporal, imágenes o tareas de NLP.
En el ejemplo siguiente se muestra que, en general, se pasa la trama de datos del paso de carga de datos. Si se especifica originalmente, se extraen la columna de etiqueta y los pesos de ejemplo, y las filas que contienen NaN se descartan de los datos de entrada.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Si desea realizar otra preparación de datos, puede hacerlo en este paso agregando el código de preparación de datos personalizado.
Código de caracterización de datos
La función generate_data_transformation_config() especifica el paso de caracterización en la canalización de scikit-learn final. Los caracterizadores del experimento original se reproducen aquí, junto con sus parámetros.
Por ejemplo, la posible transformación de datos que puede producirse en esta función puede basarse en imputers como SimpleImputer() y CatImputer(), o en transformadores como StringCastTransformer() y LabelEncoderTransformer().
A continuación se muestra un transformador del tipo StringCastTransformer() que se puede usar para transformar un conjunto de columnas. En este caso, el conjunto lo indica column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Si tiene muchas columnas a las que hay que aplicar la misma caracterización o transformación (por ejemplo, 50 columnas en varios grupos de columnas), estas columnas se controlan mediante la agrupación en función del tipo.
En el ejemplo siguiente, observe que a cada grupo se le ha aplicado un asignador único. A continuación, este asignador se aplica a todas las columnas de ese grupo.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Este enfoque le permite tener un código más simplificado, ya que no tiene un bloque de código de transformador para cada columna, lo que puede ser especialmente complicado incluso cuando se tienen decenas o cientos de columnas en el conjunto de datos.
Con las tareas de clasificación y regresión, se usa [FeatureUnion] para los caracterizadores.
En el caso de los modelos de previsión de series temporales, se recopilan varios caracterizadores compatibles con series temporales en una canalización de scikit-learn y, después, se encapsulan en TimeSeriesTransformer.
Las caracterizaciones proporcionadas por el usuario para los modelos de previsión de series temporales se producen antes que las que proporciona el aprendizaje automático automatizado.
Código de especificación de preprocesador
La función generate_preprocessor_config(), si está presente, especifica un paso de preprocesamiento que se debe realizar después de la caracterización en la canalización de scikit-learn final.
Normalmente, este paso de preprocesamiento solo consta de estandarización o normalización de datos que se realiza con sklearn.preprocessing.
ML automatizado especifica solo un paso de preprocesamiento para los modelos de clasificación y regresión que no son de conjunto.
Este es un ejemplo de código de preprocesador generado:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Código de especificación de algoritmos e hiperparámetros
Es probable que el código de especificación de algoritmos e hiperparámetros sea lo que más interese a muchos profesionales de Machine Learning.
La función generate_algorithm_config() especifica el algoritmo y los hiperparámetros reales para entrenar el modelo como la última fase de la canalización de scikit-learn final.
En el ejemplo siguiente se usa un algoritmo XGBoostClassifier con hiperparámetros específicos.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
El código generado en la mayoría de los casos usa clases y paquetes de software de código abierto (OSS). Hay instancias en las que se usan clases contenedoras intermedias para simplificar código más complejo. Por ejemplo, se pueden aplicar el clasificador XGBoost y otras bibliotecas de uso frecuente, como los algoritmos LightGBM o Scikit-Learn.
Como profesional de Machine Learning, puede personalizar el código de configuración de ese algoritmo, para lo que debe ajustar sus hiperparámetros según sea necesario en función de sus aptitudes y experiencia para ese algoritmo y su problema de Machine Learning específico.
Para los modelos de conjunto, se definen generate_preprocessor_config_N() (si es necesario) y generate_algorithm_config_N() para cada estudiante en el modelo del conjunto, donde N representa la colocación de cada estudiante en la lista del modelo del conjunto. En el caso de los modelos del conjunto de pila, se define el metaestudiante generate_algorithm_config_meta().
Código de entrenamiento de un extremo a otro
La generación de código emite build_model_pipeline() y train_model() para definir la canalización de scikit-learn y para llamar fit() a en ella, respectivamente.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
La canalización de scikit-learn incluye el paso de caracterización, un preprocesador (si se usa) y el algoritmo o modelo.
En el caso de los modelos de previsión de series temporales, la canalización de scikit-learn se encapsula en ForecastingPipelineWrapper, que tiene la lógica adicional necesaria para controlar correctamente los datos de series temporales en función del algoritmo aplicado.
En todos los tipos de tareas usamos PipelineWithYTransformer en aquellos casos en los que es necesario codificar la columna de etiqueta.
Una vez que tenga la canalización de scikit-learn, lo único que queda por llamar es el método fit() para entrenar el modelo:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
El valor devuelto desde train_model() es el modelo ajustado o entrenado en los datos de entrada.
Este es el código principal que ejecuta todas las funciones anteriores:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Una vez que tenga el modelo entrenado, puede usarlo para realizar predicciones con el método predict(). Si el experimento es para un modelo de serie temporal, use el método forecast() para las predicciones.
y_pred = model.predict(X)
Por último, el modelo se serializa y se guarda en forma de archivo .pkl denominado "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
El cuaderno script_run_notebook.ipynb sirve como una manera fácil de ejecutar script.py en un proceso de Azure Machine Learning.
Este cuaderno es similar a los cuadernos de ejemplo de AutoML, pero hay un par de diferencias importantes, como se explica en las secciones siguientes.
Entorno
Normalmente, el SDK establece automáticamente el entorno de entrenamiento de una ejecución de ML automatizado. Sin embargo, cuando se ejecuta una ejecución de script personalizado como el código generado, ML automatizado deja de impulsar el proceso, por lo que debe especificarse el entorno para que el trabajo de comando se ejecute correctamente.
La generación de código reutiliza el entorno que se usó en el experimento de ML automatizado original, siempre que sea posible. Esto garantiza que la ejecución del script de entrenamiento no provoca un error debido a que faltan dependencias y tiene la ventaja adicional de que no necesita una recompilación de imágenes de Docker, lo que ahorra tiempo y recursos de proceso.
Si realiza cambios en script.py que requieran dependencias adicionales o desea usar su propio entorno, debe actualizar el entorno en script_run_notebook.ipynb en consecuencia.
Envío del experimento
Dado que el código generado ya no está controlado por el aprendizaje automático automatizado, en lugar de crear y enviar un trabajo de AutoML, es preciso crear Command Job y proporcionarle el código generado (script.py).
El siguiente ejemplo contiene los parámetros y las dependencias regulares necesarias para ejecutar un trabajo de comando, como proceso, entorno, etc.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
Pasos siguientes
- Obtenga más información sobre cómo y dónde implementar un modelo.
- Consulte cómo habilitar las características de interpretabilidad específicamente dentro de experimentos de ML automatizado.