En este artículo, aprenderá a usar Open Neural Network Exchange (ONNX) para hacer predicciones en modelos de Computer Vision generados con el aprendizaje automático automatizado (AutoML) en Azure Machine Learning.
Para usar ONNX para las predicciones, debe hacer lo siguiente:
Descargue los archivos del modelo de ONNX de una ejecución de entrenamiento de AutoML.
Comprenda las entradas y las salidas de un modelo de ONNX.
Preprocese los datos para que estén en el formato necesario para las imágenes de entrada.
Haga la inferencia con ONNX Runtime for Python.
Visualice las predicciones para las tareas de detección de objeto visual y segmentación de instancias.
ONNX es un estándar abierto para los modelos de aprendizaje automático y aprendizaje profundo. Permite la importación y exportación los de modelos (interoperabilidad) en los marcos de IA populares. Para obtener más información, explore el proyecto GitHub ONNX.
ONNX Runtime es un proyecto de código abierto que admite la inferencia multiplataforma. ONNX Runtime proporciona las API en lenguajes de programación (incluidos Python, C++, C#, C, Java y JavaScript). Puede usar estas API para hacer inferencias en imágenes de entrada. Una vez que tenga el modelo que se exportó al formato ONNX, puede usar estas API en cualquier lenguaje de programación que necesite el proyecto.
En esta guía, aprenderá a usar las API de Python para ONNX Runtime para hacer las predicciones en las imágenes para las tareas de visión populares. Puede usar estos modelos exportados de ONNX entre lenguajes.
Instale el paquete onnxruntime. Los métodos de este artículo se han probado con las versiones 1.3.0 a 1.8.0.
Descarga de archivos del modelo de ONNX
Puede descargar archivos del modelo de ONNX de las ejecuciones de AutoML mediante la UI de Estudio de Azure Machine Learning o el SDK de Python de Azure Machine Learning. Se recomienda descargar mediante el SDK con el nombre del experimento y el identificador de ejecución primario.
Azure Machine Learning Studio
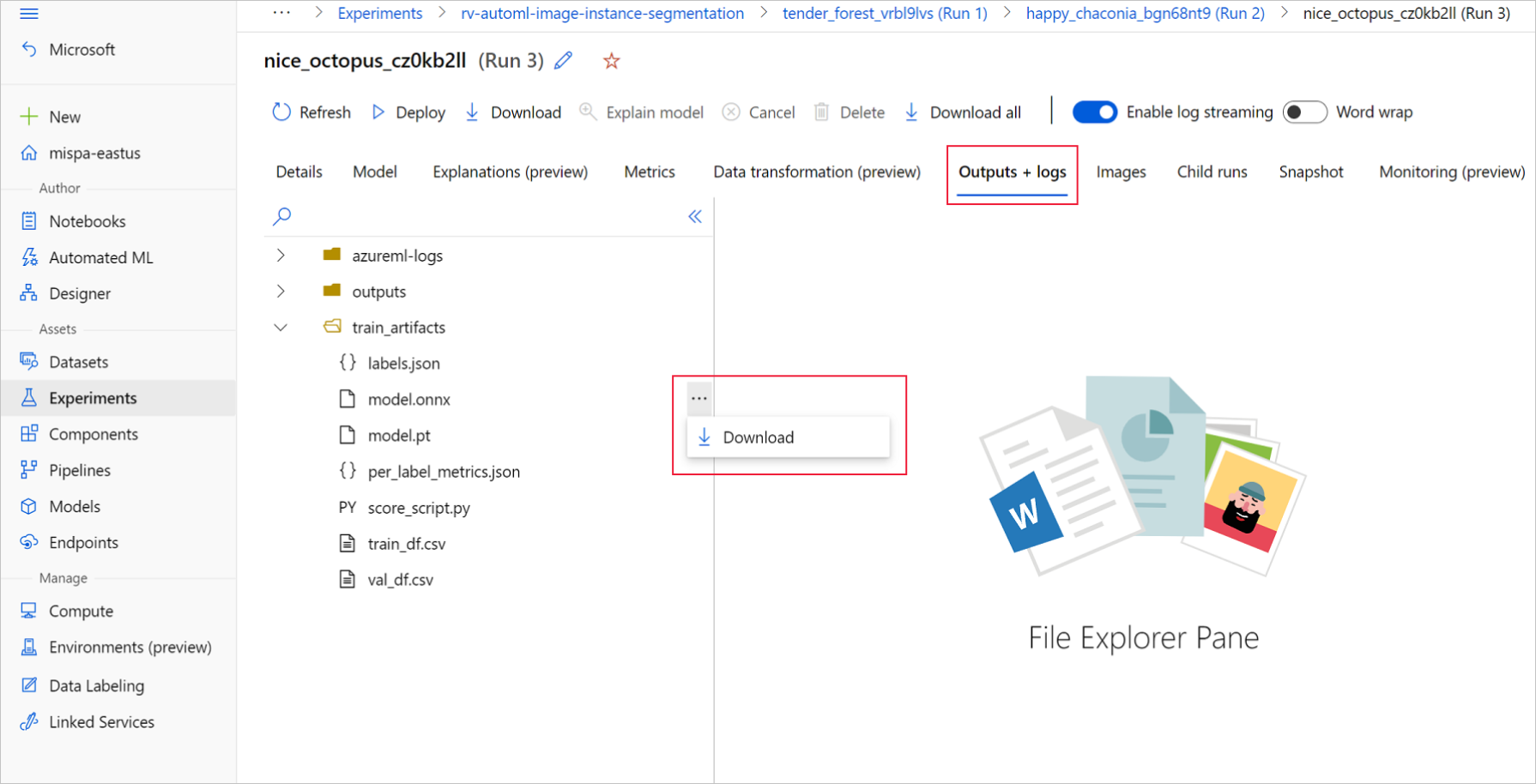
En Estudio de Azure Machine Learning, vaya al experimento mediante el hipervínculo al experimento generado en el cuaderno de entrenamiento o mediante la selección del nombre del experimento en la pestaña Experiments (Experimentos) en Assets (Recursos). A continuación, seleccione la mejor ejecución secundaria.
En la mejor ejecución secundaria, vaya a Outputs+logs>train_artifacts. Use el botón Download para descargar manualmente los siguientes archivos:
labels.json: archivo que contiene todas las clases o etiquetas del conjunto de datos de entrenamiento.
model.onnx: modelo en formato ONNX.
Guarde los archivos descargados del modelo en un directorio. En el ejemplo de este artículo se usa el directorio ./automl_models.
SDK de Python de Azure Machine Learning
Con el SDK, puede seleccionar la mejor ejecución secundaria (por métrica principal) con el nombre del experimento y el id. de ejecución primario. A continuación, puede descargar los archivos labels.json y model.onnx.
El código siguiente devuelve la mejor ejecución secundaria en función de la métrica principal pertinente.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Descargue el archivo labels.json que contiene todas las clases y etiquetas del conjunto de datos de entrenamiento.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
En el caso de la inferencia por lotes para la detección de objetos y la segmentación de instancias mediante modelos ONNX, consulte la sección sobre la generación de modelos para la puntuación por lotes.
Generación de modelos para la puntuación por lotes
De manera predeterminada, AutoML para imágenes admite la puntuación por lotes para la clasificación. Pero los modelos ONNX de detección de objetos y segmentación de instancias no admiten la inferencia por lotes. En el caso de la inferencia por lotes para la detección de objetos y la segmentación de instancias, use el siguiente procedimiento para generar un modelo ONNX para el tamaño de lote necesario. Los modelos generados para un tamaño de lote específico no funcionan para otros tamaños de lote.
Descargue el archivo de entorno de Conda y cree un objeto de entorno que se usará con el trabajo de comando.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Para obtener los valores de argumento necesarios para crear el modelo de puntuación por lotes, consulte los scripts de puntuación generados en la carpeta outputs de las ejecuciones de entrenamiento de AutoML. Use los valores de hiperparámetro disponibles en la variable de configuración del modelo dentro del archivo de puntuación para la mejor ejecución secundaria.
Para la clasificación de imágenes de varias clases, el modelo ONNX generado para la mejor ejecución secundaria admite la puntuación por lotes de manera predeterminada. Por lo tanto, no se necesitan argumentos específicos del modelo para este tipo de tarea y puede ir directamente a la sección Carga de las etiquetas y los archivos del modelo ONNX.
Para la clasificación de imágenes con varias etiquetas, el modelo ONNX generado para la mejor ejecución secundaria admite la puntuación por lotes de manera predeterminada. Por lo tanto, no se necesitan argumentos específicos del modelo para este tipo de tarea y puede ir directamente a la sección Carga de las etiquetas y los archivos del modelo ONNX.
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Descargue y mantenga el archivo ONNX_batch_model_generator_automl_for_images.py en el directorio actual para enviar el script. Use el siguiente comando de trabajo para enviar el script ONNX_batch_model_generator_automl_for_images.py disponible en el repositorio de GitHub azureml-examples para generar un modelo ONNX de un tamaño de lote específico. En el código siguiente, el entorno del modelo entrenado se usa para enviar este script para generar y guardar el modelo ONNX en el directorio outputs.
Para la clasificación de imágenes de varias clases, el modelo ONNX generado para la mejor ejecución secundaria admite la puntuación por lotes de manera predeterminada. Por lo tanto, no se necesitan argumentos específicos del modelo para este tipo de tarea y puede ir directamente a la sección Carga de las etiquetas y los archivos del modelo ONNX.
Para la clasificación de imágenes con varias etiquetas, el modelo ONNX generado para la mejor ejecución secundaria admite la puntuación por lotes de manera predeterminada. Por lo tanto, no se necesitan argumentos específicos del modelo para este tipo de tarea y puede ir directamente a la sección Carga de las etiquetas y los archivos del modelo ONNX.
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
Una vez generado el modelo por lotes, descárguelo de Salidas y registros>Salidas manualmente mediante la UI o use el método siguiente:
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
Después del paso de descarga del modelo, use el paquete de Python de ONNX Runtime para hacer la inferencia mediante el archivo model.onnx. Con fines de demostración, en este artículo se usan los conjuntos de datos de Preparación de conjuntos de datos de imagen para cada tarea de visión.
Hemos entrenado los modelos para todas las tareas de visión con sus respectivos conjuntos de datos para demostrar la inferencia de los modelos de ONNX.
Carga de las etiquetas y los archivos del modelo de ONNX
El siguiente fragmento de código carga labels.json, en el que se ordenan los nombres de clase. Es decir, si el modelo de ONNX predice un id. de etiqueta como 2, corresponde al nombre de etiqueta especificado en el tercer índice del archivo labels.json.
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Obtención de los detalles de entrada y salida esperados para un modelo de ONNX
Cuando tenga el modelo, es importante conocer algunos detalles específicos del modelo y específicos de la tarea. Estos detalles incluyen el número de entradas y el número de salidas, la forma o el formato de entrada esperados para preprocesar la imagen y la forma de salida para que conozca las salidas específicas del modelo o específicas de la tarea.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Formatos de entrada y salida esperados para el modelo de ONNX
Cada modelo de ONNX tiene un conjunto predefinido de formatos de entrada y salida.
En este ejemplo se aplica el modelo entrenado en el conjunto de datos fridgeObjects con 134 imágenes y 4 clases o etiquetas para explicar la inferencia del modelo de ONNX. Para obtener más información sobre cómo entrenar una tarea de clasificación de imágenes, consulte el cuaderno de clasificación de imágenes de varias clases.
Formato de entrada
La entrada es una imagen preprocesada.
Nombre de entrada
Forma de entrada
Tipo de entrada
Descripción
input1
(batch_size, num_channels, height, width)
ndarray(float)
La entrada es una imagen preprocesada, con la forma (1, 3, 224, 224) para un tamaño de lote de 1 y un alto y ancho de 224. Estos números corresponden a los valores usados para crop_size del ejemplo de entrenamiento.
Formato de salida
La salida es una matriz de logits para todas las clases o etiquetas.
Nombre de salida
Forma de salida
Tipo de salida
Descripción
output1
(batch_size, num_classes)
ndarray(float)
El modelo devuelve logits (sin softmax). Por ejemplo, para las clases de tamaño de lote 1 y 4, devuelve (1, 4).
La entrada es una imagen preprocesada, con la forma (1, 3, 224, 224) para un tamaño de lote de 1 y un alto y ancho de 224. Estos números corresponden a los valores usados para crop_size del ejemplo de entrenamiento.
Formato de salida
La salida es una matriz de logits para todas las clases o etiquetas.
Nombre de salida
Forma de salida
Tipo de salida
Descripción
output1
(batch_size, num_classes)
ndarray(float)
El modelo devuelve logits (sin sigmoid). Por ejemplo, para las clases de tamaño de lote 1 y 4, devuelve (1, 4).
En este ejemplo de detección de objetos se aplica el modelo entrenado en el conjunto de datos de detección fridgeObjects de 128 imágenes y 4 clases o etiquetas para explicar la inferencia del modelo de ONNX. En este ejemplo se entrenan modelos de Faster R-CNN para mostrar los pasos de la inferencia. Para obtener más información sobre los modelos de detección de objetos de entrenamiento, vea el cuaderno de detección de objetos.
Formato de entrada
La entrada es una imagen preprocesada.
Nombre de entrada
Forma de entrada
Tipo de entrada
Descripción
Entrada
(batch_size, num_channels, height, width)
ndarray(float)
La entrada es una imagen preprocesada, con la forma (1, 3, 600, 800) para un tamaño de lote de 1 y un alto de 600 y un ancho de 800.
Formato de salida
La salida es una tupla de output_names y predicciones. En este caso, output_names y predictions son listas con una longitud de 3*batch_size cada una. Para Faster R-CNN, el orden de las salidas es cuadros, etiquetas y puntuaciones, mientras que para las salidas de RetinaNet son cuadros, puntuaciones y etiquetas.
Nombre de salida
Forma de salida
Tipo de salida
Descripción
output_names
(3*batch_size)
Lista de claves
Para un tamaño de lote de 2, output_names es ['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1'].
predictions
(3*batch_size)
Lista de ndarray(float)
Para un tamaño de lote de 2, predictions toma la forma [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. En este caso, los valores de cada índice corresponden al mismo índice de output_names.
En la tabla siguiente, se describen los cuadros, las etiquetas y las puntuaciones devueltos para cada muestra del lote de imágenes.
Nombre
Forma
Tipo
Descripción
Cuadros
(n_boxes, 4), donde cada rectángulo tiene x_min, y_min, x_max, y_max
ndarray(float)
El modelo devuelve n rectángulos con sus coordenadas superior izquierda e inferior derecha.
Etiquetas
(n_boxes)
ndarray(float)
Id. de la etiqueta o de la clase de un objeto en cada rectángulo.
Puntuaciones
(n_boxes)
ndarray(float)
Puntuación de confianza de un objeto en cada rectángulo.
En este ejemplo de detección de objetos se aplica el modelo entrenado en el conjunto de datos de detección fridgeObjects de 128 imágenes y 4 clases o etiquetas para explicar la inferencia del modelo de ONNX. En este ejemplo se entrenan modelos de YOLO para mostrar los pasos de la inferencia. Para obtener más información sobre los modelos de detección de objetos de entrenamiento, vea el cuaderno de detección de objetos.
Formato de entrada
La entrada es una imagen preprocesada, con la forma (1, 3, 640, 640) para un tamaño de lote de 1 y un alto y ancho de 640. Estos números corresponden a los valores usados en el ejemplo de entrenamiento.
Nombre de entrada
Forma de entrada
Tipo de entrada
Descripción
Entrada
(batch_size, num_channels, height, width)
ndarray(float)
La entrada es una imagen preprocesada, con la forma (1, 3, 640, 640) para un tamaño de lote de 1 y un alto de 640 y un ancho de 640.
Formato de salida
Las predicciones del modelo ONNX contienen varias salidas. La primera salida es necesaria para realizar la supresión no máxima para las detecciones. Para facilitar el uso, ML automatizado muestra el formato de salida después del paso de postprocesamiento de NMS. La salida después de NMS es una lista de cuadros, etiquetas y puntuaciones para cada muestra del lote.
Nombre de salida
Forma de salida
Tipo de salida
Descripción
Output
(batch_size)
Lista de ndarray(float)
El modelo devuelve detecciones de cuadro para cada ejemplo del lote.
Cada celda de la lista indica detecciones de cuadro de una muestra con la forma (n_boxes, 6), donde cada cuadro tiene x_min, y_min, x_max, y_max, confidence_score, class_id.
En este ejemplo de la segmentación de instancias, se usa el modelo Mask R-CNN que se ha entrenado en el conjunto de datos fridgeObjects con 128 imágenes y 4 clases o etiquetas para explicar la inferencia del modelo de ONNX. Para obtener más información sobre el entrenamiento del modelo de la segmentación de instancias, consulte el cuaderno de segmentación de instancias.
Importante
La red Mask R-CNN es la única que se admite para las tareas de segmentación de instancias. Los formatos de entrada y salida se basan solo en Mask R-CNN.
Formato de entrada
La entrada es una imagen preprocesada. El modelo de ONNX para Mask R-CNN se ha exportado para trabajar con imágenes de diferentes formas. Se recomienda cambiar su tamaño a un tamaño fijo coherente con los tamaños de las imágenes de entrenamiento, para mejorar el rendimiento.
Nombre de entrada
Forma de entrada
Tipo de entrada
Descripción
Entrada
(batch_size, num_channels, height, width)
ndarray(float)
La entrada es una imagen preprocesada, con la forma (1, 3, input_image_height, input_image_width) para un tamaño de lote de 1 y un alto y ancho similares a los de una imagen de entrada.
Formato de salida
La salida es una tupla de output_names y predicciones. En este caso, output_names y predictions son listas con una longitud de 4*batch_size cada una.
Nombre de salida
Forma de salida
Tipo de salida
Descripción
output_names
(4*batch_size)
Lista de claves
Para un tamaño de lote de 2, output_names es ['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1'].
predictions
(4*batch_size)
Lista de ndarray(float)
Para un tamaño de lote de 2, predictions toma la forma [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. En este caso, los valores de cada índice corresponden al mismo índice de output_names.
Nombre
Forma
Tipo
Descripción
Cuadros
(n_boxes, 4), donde cada rectángulo tiene x_min, y_min, x_max, y_max
ndarray(float)
El modelo devuelve n rectángulos con sus coordenadas superior izquierda e inferior derecha.
Etiquetas
(n_boxes)
ndarray(float)
Id. de la etiqueta o de la clase de un objeto en cada rectángulo.
Puntuaciones
(n_boxes)
ndarray(float)
Puntuación de confianza de un objeto en cada rectángulo.
Máscaras
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Máscaras (polígonos) de objetos detectados con el alto y el ancho de la forma de una imagen de entrada.
Siga los siguientes pasos de preprocesamiento para la inferencia del modelo de ONNX:
Convierta la imagen a RGB.
Cambie el tamaño de la imagen a los valores valid_resize_size y valid_resize_size correspondientes a los valores usados en la transformación del conjunto de datos de validación durante el entrenamiento. El valor predeterminado para valid_resize_size es 256.
Recorte en el centro la imagen a height_onnx_crop_size y width_onnx_crop_size. Esto corresponde a valid_crop_size con el valor predeterminado de 224.
Cambio de HxWxC a CxHxW.
Convierta al tipo float.
Normalice con mean = [0.485, 0.456, 0.406] y std = [0.229, 0.224, 0.225] de ImageNet.
Si elige valores distintos para los hiperparámetrosvalid_resize_size y valid_crop_size durante el entrenamiento, se deben usar esos valores.
Obtenga la forma de entrada necesaria para el modelo de ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Con PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Siga los siguientes pasos de preprocesamiento para la inferencia del modelo de ONNX. Estos pasos son los mismos para la clasificación de imágenes de varias clases.
Convierta la imagen a RGB.
Cambie el tamaño de la imagen a los valores valid_resize_size y valid_resize_size correspondientes a los valores usados en la transformación del conjunto de datos de validación durante el entrenamiento. El valor predeterminado para valid_resize_size es 256.
Recorte en el centro la imagen a height_onnx_crop_size y width_onnx_crop_size. Esto corresponde a valid_crop_size con el valor predeterminado de 224.
Cambio de HxWxC a CxHxW.
Convierta al tipo float.
Normalice con mean = [0.485, 0.456, 0.406] y std = [0.229, 0.224, 0.225] de ImageNet.
Si elige valores distintos para los hiperparámetrosvalid_resize_size y valid_crop_size durante el entrenamiento, se deben usar esos valores.
Obtenga la forma de entrada necesaria para el modelo de ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Con PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Para la detección de objetos con la arquitectura de Faster R-CNN, siga los mismos pasos de preprocesamiento que la clasificación de imágenes, excepto el recorte de imágenes. Puede cambiar el tamaño de la imagen cuyo alto es 600 y cuyo ancho es 800. Puede obtener el alto y ancho de entrada esperados con el código siguiente.
A continuación, siga los pasos del preprocesamiento.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Para la detección de objetos con la arquitectura de YOLO, siga los mismos pasos de preprocesamiento que la clasificación de imágenes, excepto el recorte de imágenes. Puede cambiar el tamaño de la imagen con un alto de 600 y un ancho de 800, y obtener el alto y el ancho de entrada esperados con el código siguiente.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Importante
La red Mask R-CNN es la única que se admite para las tareas de segmentación de instancias. Los pasos de preprocesamiento se basan solo en Mask R-CNN.
Siga los siguientes pasos de preprocesamiento para la inferencia del modelo de ONNX:
Convierta la imagen a RGB.
Cambie el tamaño de la imagen.
Cambio de HxWxC a CxHxW.
Convierta al tipo float.
Normalice con mean = [0.485, 0.456, 0.406] y std = [0.229, 0.224, 0.225] de ImageNet.
Para resize_height y resize_width, también puede usar los valores empleados durante el entrenamiento, enlazados por los hiperparámetrosmin_size y max_size para Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Inferencia con ONNX Runtime
La inferencia con ONNX Runtime difiere para cada tarea de Computer Vision.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
El modelo de la segmentación de instancias predice los rectángulos, las etiquetas, las puntuaciones y las máscaras. ONNX genera una máscara de predicción por instancia, junto con los rectángulos delimitadores correspondientes y la puntuación de confianza de la clase. Es posible que tenga que convertir de máscara binaria a polígono si es necesario.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Aplique softmax() en los valores de la predicción para obtener las puntuaciones (probabilidades) de confianza de la clasificación para cada clase. A continuación, la predicción será la clase con la probabilidad más alta.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Este paso difiere de la clasificación de varias clases. Debe aplicar sigmoid a los logits (salida de ONNX) para obtener las puntuaciones de confianza para la clasificación de imágenes de varias etiquetas.
Sin PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Con PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Para la clasificación de varias clases y varias etiquetas, puede seguir los mismos pasos mencionados anteriormente para todas las arquitecturas de modelos admitidas en AutoML.
Para la detección de objetos, las predicciones se encuentran automáticamente en la escala de height_onnx, width_onnx. Para transformar las coordenadas del cuadro de predicción en las dimensiones originales, puede implementar los cálculos siguientes.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Otra opción es usar el código siguiente para escalar las dimensiones del cuadro para que se encuentre en el intervalo de [0, 1]. Esto permite multiplicar las coordenadas del cuadro por el alto y el ancho de las imágenes originales con las coordenadas respectivas (como se describe en la sección Visualización de predicciones) para obtener cuadros en las dimensiones de imagen originales.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
El código siguiente crea rectángulos, etiquetas y puntuaciones. Use estos detalles del rectángulo delimitador para seguir los mismos pasos de posprocesamiento que siguió para el modelo de Faster R-CNN.
Puede usar los pasos mencionados para Faster R-CNN (en el caso de Mask R-CNN, cada muestra tiene cuatro elementos: cajas, etiquetas, puntuaciones, máscaras) o consultar la sección Visualización de predicciones para la segmentación de instancias.
 SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)