Configuración del entrenamiento de AutoML sin código para datos tabulares con la interfaz de usuario de Studio
En este artículo, obtenga información sobre cómo configurar trabajos de entrenamiento de AutoML sin una sola línea de código mediante aprendizaje automático automatizado de Azure Machine Learning en Estudio de Azure Machine Learning.
El aprendizaje automático automatizado, AutoML, es un proceso en el que se selecciona automáticamente el mejor algoritmo de aprendizaje automático para sus datos específicos. Este proceso le permite generar modelos de aprendizaje automático rápidamente. Más información sobre cómo Azure Machine Learning implementa el aprendizaje automático automatizado.
Para obtener un ejemplo completo, pruebe el Tutorial: Aprendizaje automático automatizado y entrenamiento de modelos de clasificación sin código.
Si prefiere una experiencia basada en código de Python, configure sus experimentos de aprendizaje automático automatizado con el SDK de Azure Machine Learning.
Prerrequisitos
Suscripción a Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe hoy mismo la versión gratuita o de pago de Azure Machine Learning.
Un área de trabajo de Azure Machine Learning. Consulte Creación de recursos del área de trabajo.
Introducción
Inicie sesión en Azure Machine Learning Studio.
Seleccione su suscripción y área de trabajo.
Navegue al panel izquierdo. Seleccione Automated ML (ML automatizado) en la sección Creación.

Si es la primera vez que realiza experimentos, verá una lista vacía y vínculos a la documentación.
De lo contrario, verá una lista de los experimentos de aprendizaje automático automatizado recientes, incluidos los creados con el SDK.
Creación y ejecución de un experimento
Seleccione + New automated ML job (+ Nuevo trabajo de ML automatizado) y rellene el formulario.
Seleccione un recurso de datos del contenedor de almacenamiento o cree un nuevo recurso de datos. Los recursos de datos se pueden crear a partir de archivos locales, direcciones URL web, almacenes de datos o conjuntos de datos de Azure Open Datasets. Obtenga más información sobre la creación de recursos de datos.
Importante
Requisitos para los datos de entrenamiento:
- Los datos deben estar en formato tabular.
- El valor que quiere predecir (columna de destino) debe estar presente en los datos.
Para crear un nuevo conjunto de datos a partir de un archivo del equipo local, seleccione +Crear conjunto de datos y seleccione From local file (Desde archivo local).
Seleccione Siguiente para abrir el formulario Datastore and file selection (Almacén de datos y selección de archivos). , seleccione dónde quiere cargar el conjunto de datos: el contenedor de almacenamiento predeterminado que se crea automáticamente con el área de trabajo, o bien, elija un contenedor de almacenamiento que quiera usar para el experimento.
- Si los datos están detrás de una red virtual, debe habilitar la función de omitir la validación para asegurarse de que el área de trabajo pueda tener acceso a los datos. Para obtener más información, consulte Uso de Azure Machine Learning en una red virtual de Azure.
Seleccione Examinar para cargar el archivo de datos del conjunto de datos.
Revise el formulario Settings and preview (Configuración y vista previa) para ver que todo está correcto. El formulario se rellena de forma inteligente según el tipo de archivo.
Campo Descripción Formato de archivo Define el diseño y el tipo de datos almacenados en un archivo. Delimitador Uno o más caracteres para especificar el límite entre regiones independientes en texto sin formato u otros flujos de datos. Encoding Identifica qué tabla de esquema de bit a carácter se va a usar para leer el conjunto de elementos. Encabezados de columna Indica cómo se tratarán los encabezados del conjunto de datos, si existen. Omitir filas Indica el número de filas, si hay alguna, que se omiten en el conjunto de datos. Seleccione Next (Siguiente).
El formulario Esquema se rellena de forma inteligente en función de las selecciones realizadas en el formulario Settings and preview (Configuración y vista previa). Aquí se configura el tipo de datos para cada columna, se revisan los nombres de columna y se seleccionan las columnas que no se van a incluir en el experimento.
Seleccione Siguiente.
En el formulario Confirmar detalles se muestra un resumen de la información que se ha rellenado anteriormente en los formularios Información básica y Settings and preview (Configuración y vista previa). También tiene la opción de crear un perfil de datos para el conjunto de datos mediante un proceso habilitado para la generación de perfiles.
Seleccione Next (Siguiente).
Seleccione el conjunto de datos recién creado cuando aparezca. También puede ver una vista previa del conjunto de datos y las estadísticas de ejemplo.
En el formulario Configurar trabajo, seleccione Crear nuevo y escriba Tutorial-automl-deploy para el nombre del experimento.
Seleccione una columna de destino; esta es la columna en la que realizará las predicciones.
Seleccione un tipo de proceso para la generación de perfiles de los datos y el trabajo de entrenamiento. Puede seleccionar un clúster de proceso o una instancia de proceso.
Seleccione un proceso en la lista desplegable de los procesos existentes. Para crear un nuevo proceso, siga las instrucciones del paso 8.
Seleccione Create a new compute (Crear un proceso) para configurar el contexto del proceso de este experimento.
Campo Descripción Nombre del proceso Escriba un nombre único que identifique el contexto del proceso. Prioridad de la máquina virtual Las máquinas virtuales de prioridad baja son más económicas, pero no garantizan nodos de proceso. Tipo de máquina virtual Seleccione la CPU o GPU para el tipo de máquina virtual. Tamaño de la máquina virtual Seleccione el tamaño de la máquina virtual para el proceso. Nodos mín./máx. Para generar perfiles de datos, debe especificar uno o más nodos. escriba el número máximo de nodos para el proceso. El valor predeterminado es seis nodos para un Proceso de Azure Machine Learning. Configuración avanzada Esta configuración le permite configurar una cuenta de usuario y una red virtual existente para el experimento. Seleccione Crear. La creación de un nuevo proceso puede tardar unos minutos.
Seleccione Next (Siguiente).
En el formulario Task type and settings (Tipo de tarea y configuración), seleccione el tipo de tarea: clasificación, regresión o previsión. Para más información, vea los tipos de tareas admitidos.
Para classification (clasificación), también puede habilitar el aprendizaje profundo.
Para la previsión, puede:
Habilitar el aprendizaje profundo.
Seleccionar la columna de tiempo: esta columna contiene los datos de tiempo que desea usar.
Seleccionar el horizonte de previsión: Indique cuántas unidades de tiempo (minutos, horas, días, semanas, meses o años) será capaz predecir el modelo en el futuro. Cuanto más se exija al modelo que prediga en el futuro, menos preciso será. Más información sobre la previsión y el horizonte de previsión.
(Opcional) Ver el apartado sobre la adición de configuraciones: opciones de configuración adicionales que puede usar para controlar mejor el trabajo de entrenamiento. De lo contrario, los valores predeterminados se aplican en función de la selección y los datos del experimento.
Configuraciones adicionales Descripción Métrica principal Métrica principal usada para puntuar el modelo. Más información sobre las métricas del modelo. Habilitación del apilamiento de conjuntos El aprendizaje de conjunto mejora los resultados del aprendizaje automático y su rendimiento predictivo mediante la combinación de varios modelos en lugar de usar modelos únicos. Más información sobre los modelos de conjuntos. Modelos bloqueados Seleccione los modelos que desea excluir del trabajo de entrenamiento.
Permitir modelos solo está disponible para experimentos del SDK.
Consulte los algoritmos admitidos para cada tipo de tarea.Explicación del mejor modelo Muestra automáticamente la explicabilidad sobre el mejor modelo creado por ML automatizado. Etiqueta de clase positiva Etiqueta que Machine Learning Automatizado usará para calcular las métricas binarias. (Opcional) Consulte la configuración de caracterización: Si decide habilitar Caracterización automática en el formulario Ver configuración de caracterización, se aplican las técnicas de caracterización predeterminadas. En Ver configuración de caracterización, puede cambiar estos valores predeterminados y personalizarlos según corresponda. Obtenga información sobre cómo personalizar las caracterizaciones.
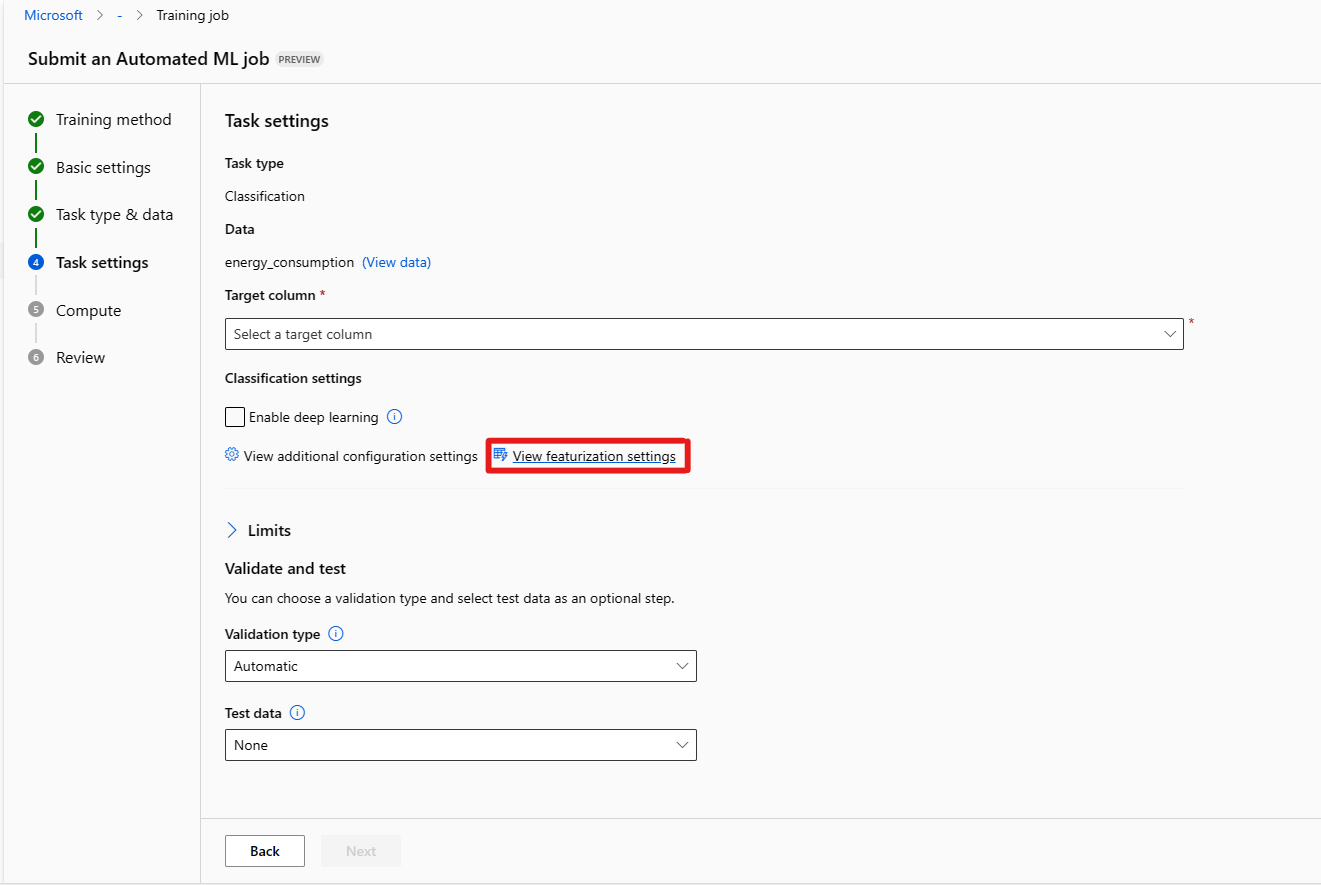
El formulario Límites [Opcional] permite hacer lo siguiente.
Opción Descripción Número máximo de pruebas El número máximo de pruebas, cada una con una combinación diferente de algoritmos e hiperparámetros para probar durante el trabajo de AutoML. Debe ser un entero entre 1 y 1000. Número máximo de pruebas concurrentes Número máximo de trabajos de prueba que se pueden ejecutar en paralelo. Debe ser un entero entre 1 y 1000. Número máximo de nodos Número máximo de nodos que este trabajo puede usar desde el destino de proceso seleccionado. Umbral de puntuación de métrica Cuando se alcance este valor de umbral en una métrica de iteración, finalizará el trabajo de entrenamiento. Tenga en cuenta que los modelos significativos tienen una correlación superior a 0; de lo contrario, son tan buenos como adivinar el umbral medio de métricas debe estar entre los límites [0, 10]. Tiempo de espera de experimento (minutos) El tiempo máximo, en minutos, durante el que se puede ejecutar todo el experimento. Una vez que se alcance este límite, el sistema cancelará el trabajo de ML automatizado, incluidas todas sus pruebas (trabajos secundarios). Tiempo de espera de iteración (minutos) El tiempo máximo, en minutos, durante el que se puede ejecutar cada trabajo de prueba. Una vez alcanzado este límite, el sistema cancelará la prueba. Habilitar terminación anticipada Seleccione esta opción para finalizar el trabajo si la puntuación no mejora a corto plazo. Con el formulario [Opcional] Validar y probar puede hacer lo siguiente:
a. Especificar el tipo de validación que se usará para el trabajo de entrenamiento. Si no especifica explícitamente un parámetro validation_data o n_cross_validations, el aprendizaje automático automatizado aplica las técnicas predeterminadas en función del número de filas proporcionadas en el conjunto de datos único training_data.
| Tamaño de datos de entrenamiento | Técnica de validación |
|---|---|
| Mayor que 20 000 filas | Se aplica la división de datos de entrenamiento o validación. El valor predeterminado consiste en usar el 10 % del conjunto de datos de entrenamiento inicial como conjunto de validación. A su vez, ese conjunto de validación se usa para calcular las métricas. |
| Menos de 20 000 filas | Se aplica el enfoque de validación cruzada. El número predeterminado de iteraciones depende del número de filas. Si el conjunto de datos tiene menos de 1000 filas, se usan diez iteraciones. Si hay entre 1000 y 20 000 filas, se usan tres iteraciones. |
b. Proporcionar un conjunto de datos de prueba (versión preliminar) para evaluar el modelo recomendado que el aprendizaje automático automatizado genera automáticamente al final del experimento. Cuando se proporcionan datos de prueba, se desencadena automáticamente un trabajo de prueba al final del experimento. Este trabajo de prueba solo se ejecuta en el mejor modelo recomendado por el ML automatizado. Obtenga información sobre cómo obtener los resultados del trabajo de pruebas remotas.
Importante
La característica para proporcionar un conjunto de datos de prueba con el fin de evaluar los modelos generados está en versión preliminar. Esta funcionalidad es una característica experimental en versión preliminar y puede cambiar en cualquier momento.
* Los datos de prueba se consideran independientes del entrenamiento y la validación, con el fin de no sesgar los resultados del trabajo de prueba del modelo recomendado. Obtenga más información sobre el sesgo durante la validación del modelo.
* Puede proporcionar su propio conjunto de datos de prueba u optar por usar un porcentaje del conjunto de datos de entrenamiento. Los datos de prueba deben tener el formato de un objeto TabularDataset de Azure Machine Learning.
* El esquema del conjunto de datos de prueba debe coincidir con el conjunto de datos de entrenamiento. La columna de destino es opcional, pero, si no se indica, no se calcula ninguna métrica de prueba.
* El conjunto de datos de prueba no debe ser el mismo que el conjunto de datos de entrenamiento o de validación.
* Los trabajos de previsión no admiten la división de entrenamiento o prueba.
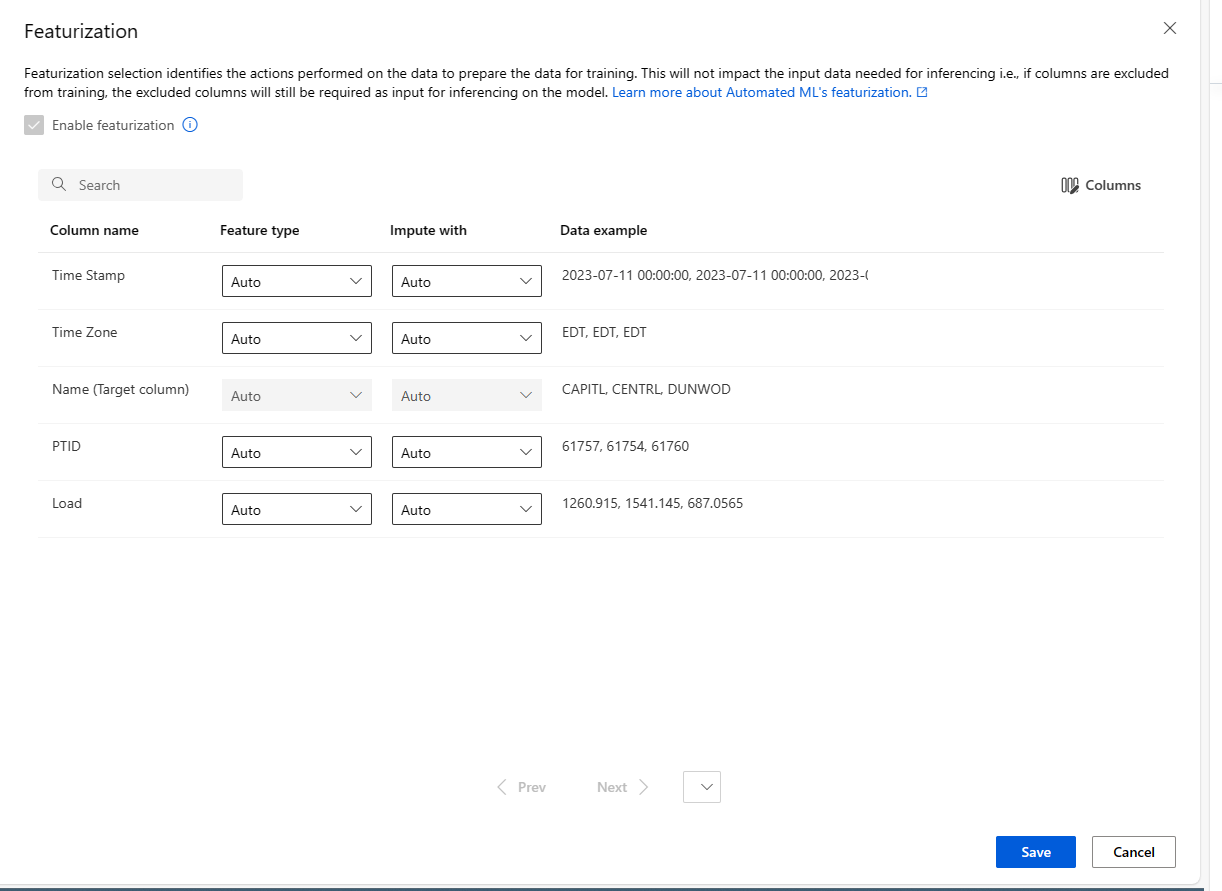
Personalización de la caracterización
En el formulario Caracterización, puede habilitar o deshabilitar la caracterización automática y personalizar la configuración de caracterización automática para su experimento. Para abrir este formulario, consulte el paso 10 de la sección Creación y ejecución de un experimento.
En la tabla siguiente se resumen las personalizaciones disponibles actualmente a través de Studio.
| Columna | Personalización |
|---|---|
| Tipo de característica | Cambia el tipo de valor de la columna seleccionada. |
| Imputar con | Selecciona el valor con los cuales imputar los valores que faltan en los datos. |
Ejecución del experimento y visualización de los resultados
Para ejecutar el experimento, seleccione Finalizar. El proceso de preparación del experimento puede tardar hasta 10 minutos. Los trabajos de entrenamiento pueden tardar de 2 a 3 minutos más para que cada canalización termine de ejecutarse. Si ha especificado generar el panel RAI para el mejor modelo recomendado, puede tardar hasta 40 minutos.
Nota
Los algoritmos que el aprendizaje automático automatizado emplea llevan inherente la aleatoriedad, que puede provocar una ligera variación en la puntuación de las métricas finales del modelo recomendado, como la precisión. El aprendizaje automático automatizado también realiza operaciones en datos, como la división de la prueba de entrenamiento, la división de la validación de entrenamiento o la validación cruzada cuando es necesario. Por lo tanto, si ejecuta un experimento con las mismas opciones de configuración y métricas principales varias veces, es probable que vea una variación en las puntuaciones de las métricas finales de los experimentos debido a estos factores.
Visualización de los detalles del experimento
Se abre la pantalla Detalles de trabajo en la pestaña Detalles. En esta pantalla se muestra un resumen del trabajo del experimento, incluida una barra de estado en la parte superior, junto al número de trabajo.
La pestaña Modelos contiene una lista de los modelos creados ordenados por la puntuación de la métrica. De forma predeterminada, el modelo que puntúa más alto en función de las métricas seleccionadas aparece en la parte superior de la lista. A medida que el trabajo de entrenamiento prueba más modelos, se agregan a la lista. Utilice esto para obtener una comparación rápida de las métricas para los modelos generados hasta ahora.
Vista de detalles de trabajo de entrenamiento
Explore en profundidad cualquiera de los modelos completados para ver los detalles de trabajo de entrenamiento.
Puede ver gráficos de métricas de rendimiento específicos del modelo en la pestaña Métricas. Más información sobre los gráficos.
Aquí también puede encontrar detalles sobre todas las propiedades del modelo junto con el código asociado, los trabajos secundarios y las imágenes.
Visualización de los resultados del trabajo de pruebas remotas (versión preliminar)
Si ha especificado un conjunto de datos de prueba o ha optado por una división de entrenamiento y prueba durante la configuración del experimento (en el formulario Validar y probar), el ML automatizado prueba automáticamente el modelo recomendado de manera predeterminada. Como resultado, el aprendizaje automático automatizado calcula las métricas de prueba para determinar la calidad del modelo recomendado y sus predicciones.
Importante
La característica para probar modelos con un conjunto de datos de prueba con el fin de evaluar los modelos generados está en versión preliminar. Esta funcionalidad es una característica experimental en versión preliminar y puede cambiar en cualquier momento.
Advertencia
Esta característica no está disponible para los siguientes escenarios de aprendizaje automático automatizado
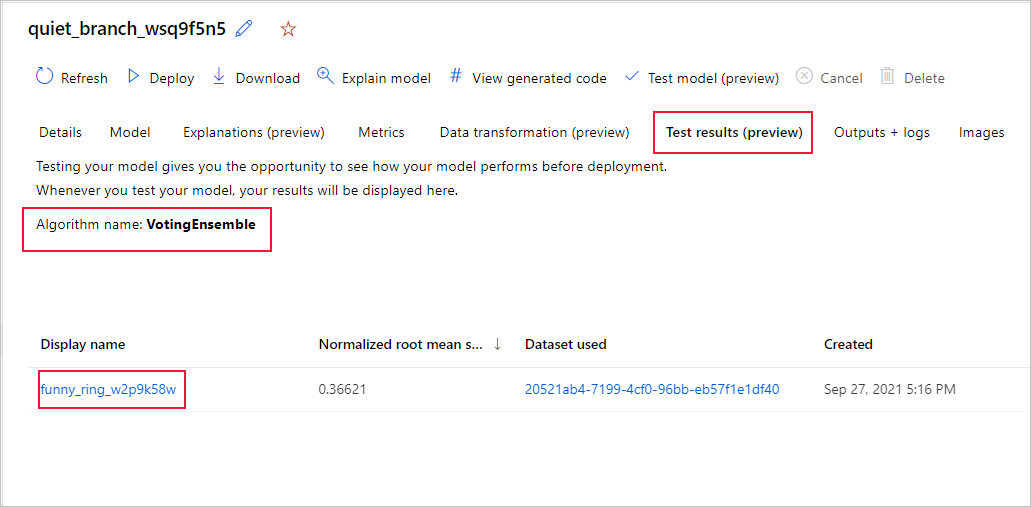
Para ver las métricas del trabajo de pruebas del modelo recomendado, haga lo siguiente:
- Vaya a la página Modelos y seleccione el mejor modelo.
- Seleccione la pestaña Resultados de la prueba (versión preliminar) .
- Seleccione el trabajo que quiere y consulte la pestaña Métricas.
Para ver las predicciones de prueba usadas para calcular las métricas de prueba, haga lo siguiente:
- Vaya a la parte inferior de la página y seleccione el vínculo de Conjunto de datos de salidas para abrir el conjunto de datos.
- En la página Conjuntos de datos, seleccione la pestaña Explorar para ver las predicciones del trabajo de pruebas.
- El archivo de predicción también se puede ver o descargar desde la pestaña Salidas y registros. Expanda la carpeta Predicciones para localizar el archivo
predicted.csv.
- El archivo de predicción también se puede ver o descargar desde la pestaña Salidas y registros. Expanda la carpeta Predicciones para localizar el archivo
El archivo de predicción también se puede ver o descargar desde la pestaña "Salidas y registros". Expanda la carpeta "Predicciones" para localizar el archivo "predictions.csv".
El trabajo de pruebas del modelo genera el archivo predictions.csv, que se almacena en el almacén de datos predeterminado creado con el área de trabajo. Este almacén de datos pueden verlo todos los usuarios con la misma suscripción. Los trabajos de pruebas no se recomiendan para ningún escenario si alguna parte de la información usada para el trabajo de pruebas, o creada por este, debe permanecer privada.
Prueba de un modelo de aprendizaje automático automatizado ya existente (versión preliminar)
Importante
La característica para probar modelos con un conjunto de datos de prueba con el fin de evaluar los modelos generados está en versión preliminar. Esta funcionalidad es una característica experimental en versión preliminar y puede cambiar en cualquier momento.
Advertencia
Esta característica no está disponible para los siguientes escenarios de aprendizaje automático automatizado
Una vez completado el experimento, puede probar los modelos que el aprendizaje automático automatizado genera por usted. Si desea probar otro modelo generado por el aprendizaje automático automatizado que no sea el recomendado, puede hacerlo mediante los siguientes pasos:
Seleccione un trabajo de experimento de ML automatizado existente.
Vaya a la pestaña Modelos del trabajo y seleccione el modelo completado que quiere probar.
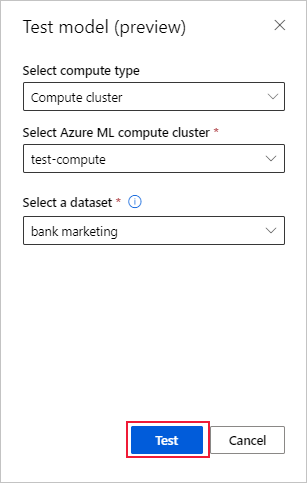
En la página Detalles del modelo, seleccione el botón Modelo de prueba (versión preliminar) para abrir el panel Modelo de prueba.
En el panel Modelo de prueba, seleccione el clúster de proceso y el conjunto de datos de prueba que quiera usar para el trabajo de pruebas.
Seleccione el botón Probar. El esquema del conjunto de datos de prueba debe coincidir con el conjunto de datos de entrenamiento, pero la columna de destino es opcional.
Una vez que se cree el trabajo de pruebas del modelo, en la página Detalles se mostrará el mensaje correspondiente. Seleccione la pestaña Resultados de la prueba para ver el progreso del trabajo.
Para ver los resultados del trabajo de pruebas, abra la página Detalles y siga los pasos descritos en la sección Visualización de los resultados del trabajo de pruebas remotas.
Creación de un panel de IA responsable (versión preliminar)
Para comprender mejor el modelo, puede ver varias conclusiones sobre el modelo mediante el panel de IA responsable. Permite evaluar y depurar el mejor modelo de aprendizaje automático automatizado. El panel de IA responsable evaluará los errores del modelo y los problemas de equidad y diagnosticará por qué se producen esos errores mediante la evaluación de los datos de entrenamiento o prueba y la observación de las explicaciones del modelo. Juntas, estas conclusiones podrían ayudarle a crear confianza con el modelo y pasar los procesos de auditoría. Los paneles de IA responsable no se pueden generar para un modelo de aprendizaje automático automatizado existente. Solo se crea para el mejor modelo recomendado cuando se crea un nuevo trabajo de ML automatizado. Los usuarios deben seguir usando solo las explicaciones del modelo (versión preliminar) hasta que se proporcione compatibilidad con los modelos existentes.
Para generar un panel de IA responsable para un modelo determinado,
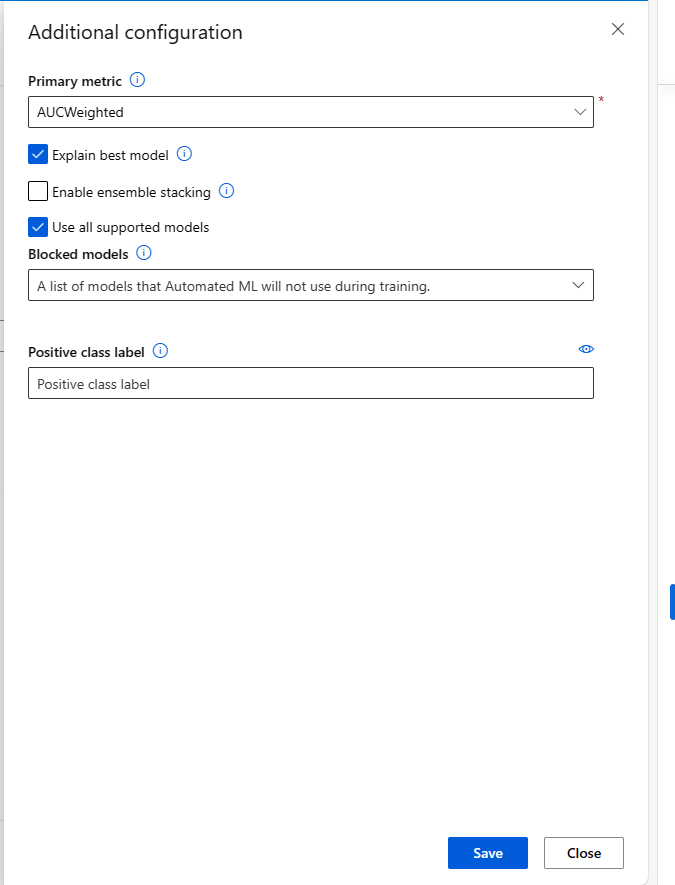
Al enviar un trabajo de ML automatizado, vaya a la sección Configuración de tareas de la barra de navegación izquierda y seleccione la opción Ver opciones de configuración adicionales.
En el nuevo formulario que aparece después de esa selección, active la casilla Explicar el mejor modelo.
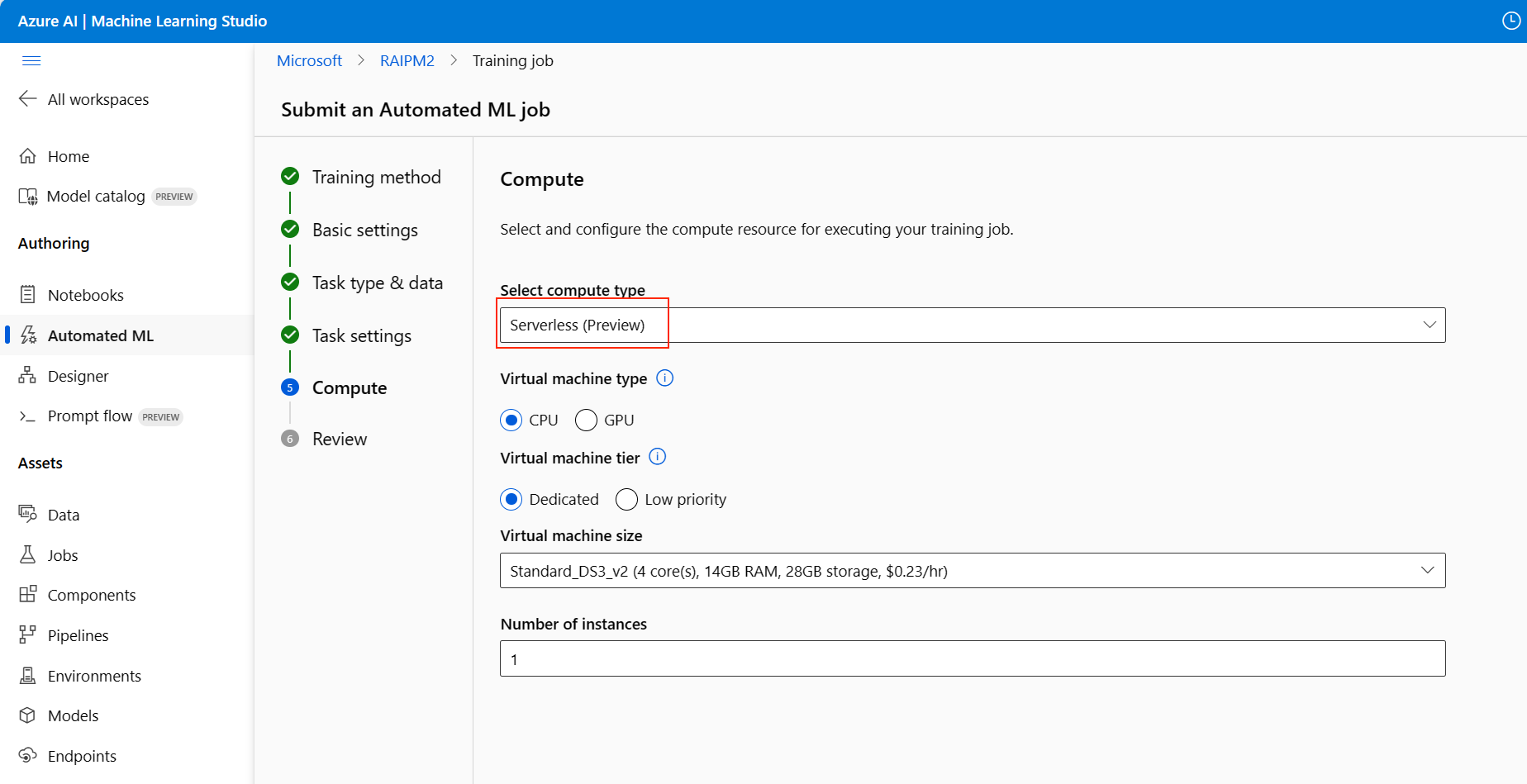
Continúe a la página Proceso del formulario de configuración y elija la opción Sin servidor como proceso.
Una vez completado, vaya a la página Modelos del trabajo de ML automatizado, que contiene una lista de los modelos entrenados. Seleccione en el vínculo Ver panel de IA responsable:
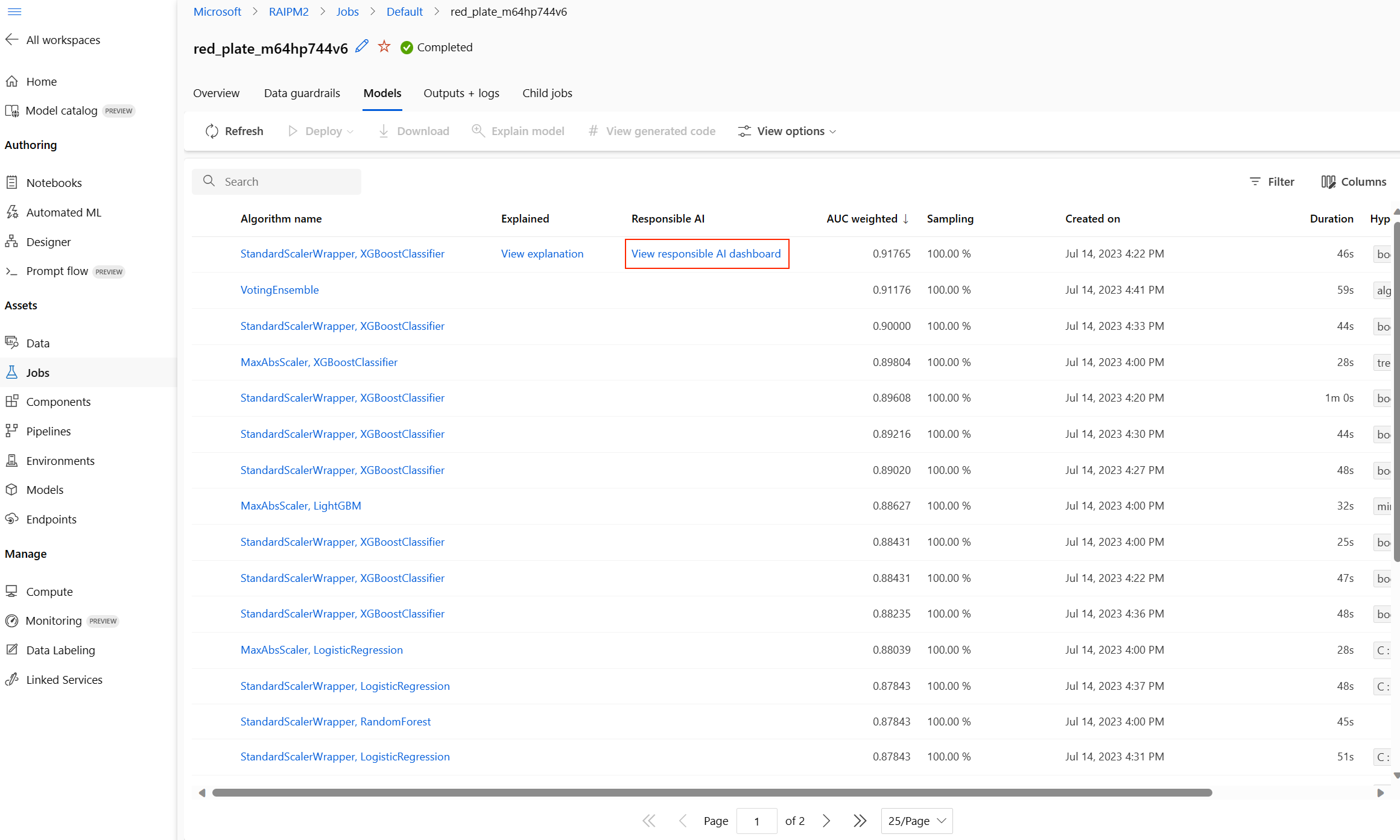
Aparece el panel de IA responsable para ese modelo, como se muestra en esta imagen:
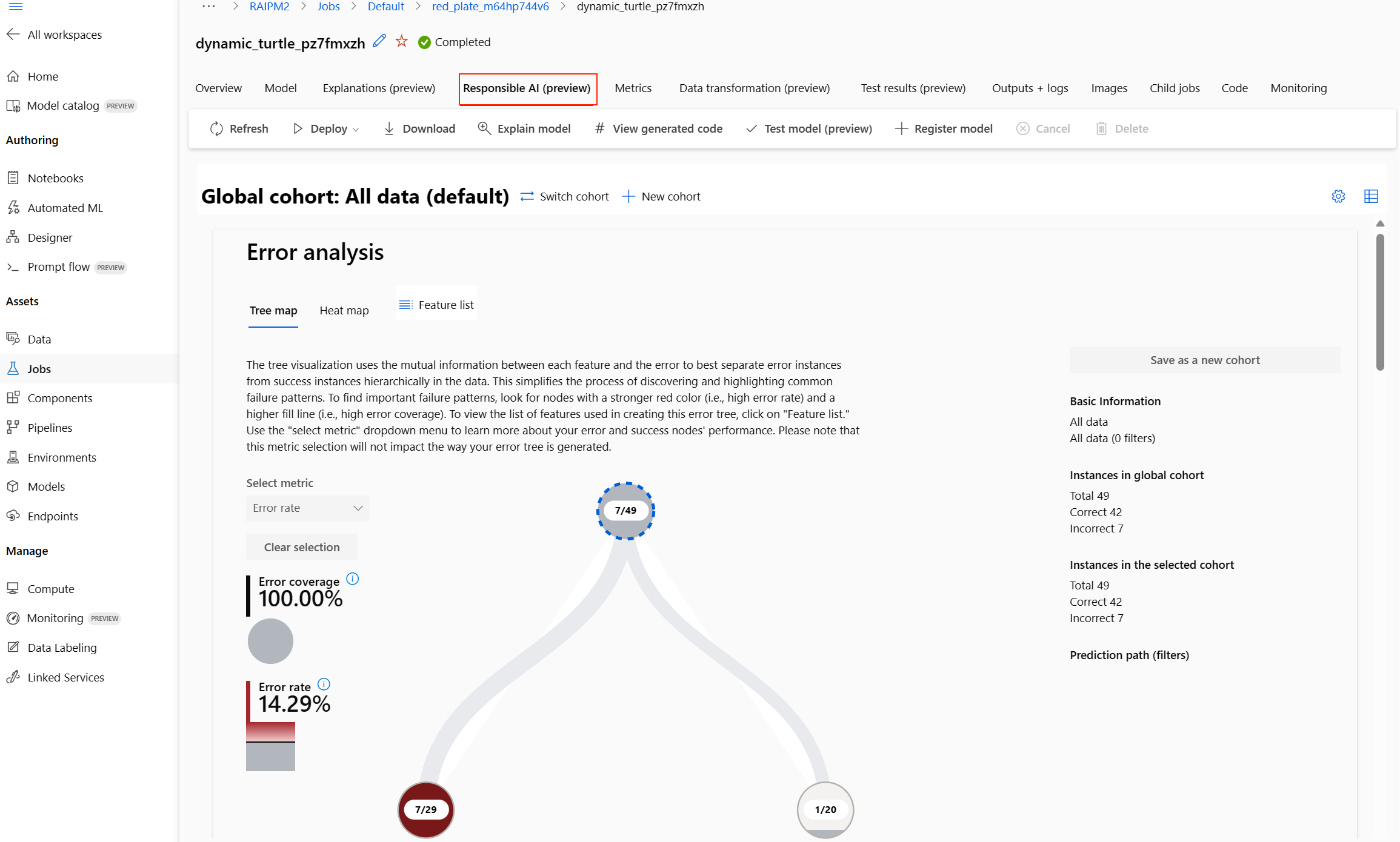
En el panel, encontrará cuatro componentes activados para el mejor modelo de ML automatizado:
| Componente | ¿Qué muestra el componente? | ¿Cómo se lee el gráfico? |
|---|---|---|
| Análisis de errores | Use el análisis de errores cuando necesite: Obtener un conocimiento profundo de cómo se distribuyen los errores del modelo en un conjunto de datos determinado y en varias dimensiones de entrada y características. Desglosar las métricas de rendimiento agregadas para detectar automáticamente cohortes erróneas para ofrecer información a los pasos de mitigación de destino. |
Gráficos de análisis de errores |
| Información general del modelo y métricas de equidad | Use este componente para: Obtener un conocimiento profundo del rendimiento del modelo en diferentes cohortes de datos. Comprender los problemas de equidad del modelo examinando las métricas de disparidad. Estas métricas pueden evaluar y comparar el comportamiento del modelo entre subgrupos identificados en términos de características confidenciales (o no confidenciales). |
Información general del modelo y gráficos de equidad |
| Explicaciones del modelo | Use el componente de explicación del modelo para generar descripciones comprensibles por humanos de las predicciones de un modelo de Machine Learning, para lo que debe examinar: Explicaciones globales: Por ejemplo, ¿qué características afectan al comportamiento general de un modelo de asignación de préstamos? Explicaciones locales: Por ejemplo, ¿por qué se ha aprobado o rechazado la solicitud de préstamo de un cliente? |
Gráficos de explicación del modelo |
| Análisis de datos | Use el análisis de datos cuando necesite: Explorar las estadísticas del conjunto de datos seleccionando distintos filtros para segmentar los datos en diferentes dimensiones (también conocidas como cohortes). Comprender la distribución del conjunto de datos entre diferentes cohortes y grupos de características. Determinar si los resultados relacionados con la equidad, el análisis de errores y la causalidad (derivados de otros componentes del panel) son el resultado de la distribución del conjunto de datos. Decidir en qué áreas debe recopilar más datos para mitigar los errores derivados de problemas de representación, ruido de etiquetas, ruido de características, sesgo de etiquetas y factores similares. |
Gráficos de Data Explorer |
- Puede crear más cohortes (subgrupos de puntos de datos que comparten características especificadas) para centrar el análisis de cada componente en diferentes cohortes. El nombre de la cohorte aplicada actualmente al panel siempre se muestra en la parte superior izquierda de este. La vista predeterminada del panel es todo el conjunto de datos, titulado “Todos los datos” (de manera predeterminada). Obtenga más información sobre el control global del panel aquí.
Edición y envío de trabajos (versión preliminar)
Importante
La posibilidad de copiar, editar y enviar un nuevo experimento basado en un experimento existente es una característica en versión preliminar. Esta funcionalidad es una característica experimental en versión preliminar y puede cambiar en cualquier momento.
En los escenarios en los que desea crear un experimento basado en la configuración de un experimento ya existente, el aprendizaje automático automatizado proporciona la opción de hacerlo con el botón Editar y enviar de la interfaz de usuario de Studio.
Esta funcionalidad se limita a los experimentos iniciados desde la interfaz de usuario de Studio y requiere que el esquema de datos del nuevo experimento coincida con el del experimento original.
El botón Editar y enviar abre el asistente para Crear un nuevo trabajo de ML automatizado con la configuración de datos, proceso y experimento rellenada previamente. Puede pasar por cada formulario y editar las selecciones según sea necesario para el nuevo experimento.
Implementación del modelo
Una vez que tenga a mano el mejor modelo, es el momento de implementarlo como un servicio web para predecir los datos nuevos.
Sugerencia
Si va a implementar un modelo que se generó a través del paquete automl con el SDK de Python, debe registrar el modelo en el área de trabajo.
Una vez que se haya registrado el modelo, puede buscarlo en el estudio seleccionando Modelos en el panel izquierdo. Después de abrir el modelo, puede seleccionar el botón Implementar en la parte superior de la pantalla y, luego, seguir las instrucciones descritas en el paso 2 de la sección Implementación del modelo.
ML automatizado le ayuda a implementar el modelo sin escribir código:
Tiene unas par de opciones de implementación.
Opción 1: implementar el mejor modelo, según los criterios de métricas que haya definido.
- Una vez finalizado el experimento, vaya a la página de trabajo primario mediante la selección de Trabajo 1 en la parte superior de la pantalla.
- Seleccione el modelo que aparece en la sección Mejor resumen del modelo.
- Seleccione Implementar en la parte superior izquierda de la ventana.
Opción 2: implementar una iteración del modelo específica de este experimento.
- Seleccione el modelo que quiera en la pestaña Modelos.
- Seleccione Implementar en la parte superior izquierda de la ventana.
Rellene el panel Implementar modelo.
Campo Valor Nombre Escriba un nombre único para la implementación. Descripción Escriba una descripción para saber mejor para qué sirve esta implementación. Compute type (Tipo de proceso) Seleccione el tipo de punto de conexión que quiera implementar: Azure Kubernetes Service (AKS) o Azure Container Instances (ACI). Nombre del proceso Solo se aplica a AKS: Seleccione el nombre del clúster de AKS en que desea realizar la implementación. Enable authentication (Habilitar autenticación) Seleccione esta opción para permitir la autenticación basada en token o basada en clave. Use custom deployment assets (Usar recursos de implementación personalizados) Habilite esta característica si desea cargar su propio archivo de entorno y script de puntuación. De lo contrario, el aprendizaje automático automatizado proporcionará estos recursos por usted de manera predeterminada. Más información sobre los scripts de puntuación. Importante
Los nombres de archivo deben tener menos de 32 caracteres y deben comenzar y terminar con caracteres alfanuméricos. Puede incluir guiones, caracteres de subrayado, puntos y caracteres alfanuméricos. No se permiten espacios.
El menú Avanzado ofrece características de implementación predeterminadas como la recopilación de datos y la configuración del uso de recursos. Si desea reemplazar estos valores predeterminados, hágalo en este menú.
Seleccione Implementar. La implementación puede tardar unos 20 minutos en completarse. Una vez iniciada la implementación, aparece la pestaña Resumen del modelo. Consulte el progreso de la implementación en la sección Estado de implementación.
Ya tiene un servicio web operativo para generar predicciones. Puede probar las predicciones consultando el servicio de soporte técnico de Azure Machine Learning de Power BI.