Tutorial de C#: uso de conjuntos de aptitudes para generar contenido que se puede buscar en la Búsqueda de Azure AI
En este tutorial aprenderá a usar el SDK de Azure para .NET para crear una canalización de enriquecimiento de inteligencia artificial para la extracción y las transformaciones de contenido durante la indexación.
Los conjuntos de aptitudes agregan procesamiento de IA al contenido sin procesar, lo que hace que ese contenido sea más uniforme y se pueda buscar. Una vez que sepa cómo funcionan los conjuntos de aptitudes, puede admitir una amplia gama de transformaciones: desde el análisis de imágenes hasta el procesamiento de lenguaje natural, para el procesamiento personalizado que proporcione externamente.
En este tutorial, aprenderá a:
- Definir objetos en una canalización de enriquecimiento.
- Crear un conjunto de aptitudes. Invocar OCR, detección de idioma, reconocimiento de entidades y extracción de frases clave.
- Ejecutar la canalización. Crear y cargar un índice de búsqueda.
- Comprobar los resultados mediante la búsqueda de texto completo.
Si no tiene una suscripción a Azure, abra una cuenta gratuita antes de empezar.
Información general
En este tutorial se usa C# y la biblioteca cliente Azure.Search.Documents para crear un origen de datos, un índice, un indexador y un conjunto de aptitudes.
El indexador controla cada paso de la canalización, empezando por la extracción de contenido de datos de ejemplo (texto e imágenes no estructurados) en un contenedor de blobs en Azure Storage.
Una vez extraído el contenido, el conjunto de aptitudes ejecuta aptitudes integradas de Microsoft para buscar y extraer información. Estas aptitudes incluyen el reconocimiento óptico de caracteres (OCR) en imágenes, la detección de idiomas en texto, la extracción de frases clave y el reconocimiento de entidades (organizaciones). La nueva información creada por el conjunto de aptitudes se envía a los campos de un índice. Una vez que se rellenan los datos del índice, se pueden usar los campos en las consultas, las facetas y los filtros.
Requisitos previos
Nota:
Puede usar un servicio de búsqueda gratuito para este tutorial. El nivel gratis le limita a tres índices, tres indexadores y tres orígenes de datos. En este tutorial se crea uno de cada uno. Antes de empezar, asegúrese de que haya espacio en el servicio para aceptar los nuevos recursos.
Descarga de archivos
Descargue un archivo ZIP del repositorio de datos de ejemplo y extraiga el contenido. Más información.
Carga de datos de ejemplo en Azure Storage
En Azure Storage, cree un contenedor y asígnele el nombre cog-search-demo.
Obtenga una cadena de conexión de almacenamiento para poder formular una conexión en Azure AI Search.
A la izquierda, seleccione Teclas de acceso.
Copie la cadena de conexión para la clave uno o la clave dos. La cadena de conexión es parecida a la del ejemplo siguiente:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Servicios de Azure AI
El enriquecimiento con IA integrado tiene el respaldo de los servicios de Azure AI, lo que incluye el servicio de lenguaje y Visión de Azure AI para el procesamiento de imágenes y del lenguaje natural. Para cargas de trabajo pequeñas como este tutorial, puede usar la asignación gratuita de 20 transacciones por indexador. Para cargas de trabajo más grandes, adjunte un recurso de varias regiones de Servicios de Azure AI a un conjunto de aptitudes para los precios de pago por uso.
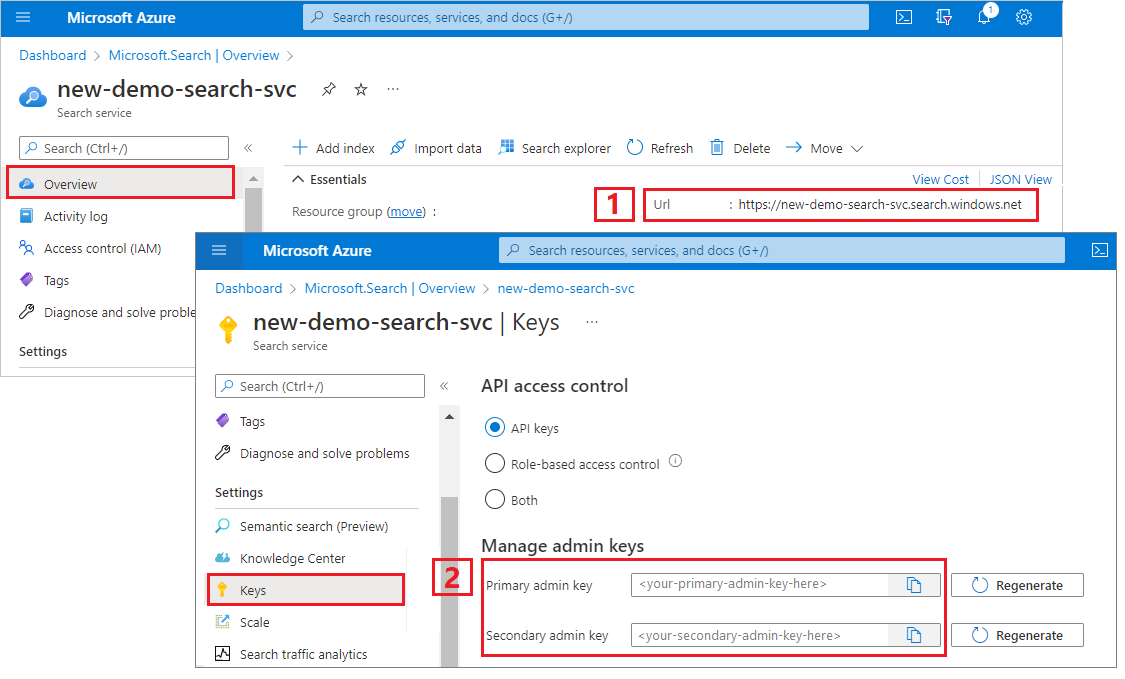
Copia de una dirección URL del servicio de búsqueda y una clave de API
Para este tutorial, las conexiones a la búsqueda de Azure AI requieren un punto de conexión y una clave de API. Puede obtener estos valores en Azure Portal.
Inicie sesión en Azure Portal, vaya a la página Información general del servicio de búsqueda y copie la dirección URL. Un punto de conexión de ejemplo podría ser similar a
https://mydemo.search.windows.net.En Configuración>Claves, copie una clave de administrador. Las claves de administrador se utilizan para agregar, modificar y eliminar objetos. Hay dos claves de administrador intercambiables. Copie una de las dos.
Configurar el entorno
Para comenzar, abra Visual Studio y cree un nuevo proyecto de Aplicación de consola que pueda ejecutarse en .NET Core.
Instalación de Azure.Search.Documents
El SDK de .NET de Azure AI Search consta de una biblioteca cliente que permite administrar los índices, los orígenes de datos, los indexadores y los conjuntos de aptitudes, así como cargar y administrar documentos y ejecutar consultas, y todo ello sin tener que encargarse de los detalles de HTTP y JSON. Esta biblioteca cliente se distribuye como si fuera un paquete NuGet.
Para este proyecto, instale la versión 11 u otra versión posterior de Azure.Search.Documents y la versión más reciente de Microsoft.Extensions.Configuration.
En Visual Studio, seleccione Herramientas>Administrador de paquetes NuGet>Administrar paquetes NuGet para la solución...
Busque Azure.Search.Document.
Seleccione la versión más reciente y, luego, seleccione Instalar.
Repita los pasos anteriores para instalar Microsoft.Extensions.Configuration y Microsoft.Extensions.Configuration.Json.
Incorporación de la información de conexión del servicio
Haga clic con el botón derecho en el proyecto en el Explorador de soluciones y seleccione Agregar>Nuevo elemento...
Asigne el nombre
appsettings.jsonal archivo y seleccione Agregar.Incluya este archivo en el directorio de salida.
- Haga clic con el botón derecho en
appsettings.jsony seleccione Propiedades. - Cambie el valor de Copiar en el directorio de salida a Copiar si es posterior.
- Haga clic con el botón derecho en
Copie el siguiente código JSON en el nuevo archivo JSON.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Agregue la información del servicio de búsqueda y de la cuenta de almacenamiento de blobs. Recuerde que puede obtener esta información en los pasos de aprovisionamiento del servicio indicados en la sección anterior.
En SearchServiceUri, escriba la dirección URL completa.
Agregar espacios de nombres
En Program.cs, agregue los siguientes espacios de nombres.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Creación de un cliente
Cree una instancia de SearchIndexClient y SearchIndexerClient en Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Nota
Los clientes se conectan a su servicio de búsqueda. Para evitar que se abran demasiadas conexiones, debe intentar, si es posible, compartir una única instancia en la aplicación. Los métodos son seguros para subprocesos lo que permite habilitar este tipo de uso compartido.
Adición de una función para salir del programa durante un error
Este tutorial está pensado para ayudarle a conocer los distintos pasos de la canalización de indexación. Si hay algún problema crítico que impida que el programa cree el origen de datos, conjunto de aptitudes, índice o indexador, el programa generará el mensaje de error y se cerrará, con el fin de que el problema se pueda entender y resolver.
Agregue ExitProgram a Main para controlar los escenarios que requieran que el programa se cierre.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Creación de la canalización
En Azure AI Search, el procesamiento de la inteligencia artificial se produce durante la indexación (o la ingesta de datos). En esta parte del tutorial se crean cuatro objetos: origen de datos, definición de índice, conjunto de aptitudes, indexador.
Paso 1: Creación de un origen de datos
SearchIndexerClient tiene una propiedad DataSourceName que se puede establecer en un objeto SearchIndexerDataSourceConnection. Este objeto proporciona todos los métodos necesarios para crear, enumerar, actualizar o eliminar orígenes de datos de Azure AI Search.
Cree una nueva instancia de SearchIndexerDataSourceConnection mediante una llamada a indexerClient.CreateOrUpdateDataSourceConnection(dataSource). El siguiente código crea un origen de datos del tipo AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Para una solicitud correcta, el método devuelve el origen de datos que se creó. Si hay un problema con la solicitud, como un parámetro no válido, el método produce una excepción.
Ahora, agregue una línea a Main para llamar a la función CreateOrUpdateDataSource que acaba de agregar.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Compile y ejecute la solución. Puesto que se trata de su primera solicitud, consulte Azure Portal para confirmar el origen de datos se creó en Azure AI Search. En la página de información general del servicio de búsqueda, compruebe que la lista de Data Sources tiene un nuevo elemento. Debe esperar unos minutos a que la página del portal se actualice.

Paso 2: Creación de un conjunto de aptitudes
En esta sección, definirá un conjunto de pasos de enriquecimiento que quiere aplicar en los datos. Cada paso de enriquecimiento se denomina una aptitud, mientras que el conjunto de pasos de enriquecimiento se llama un conjunto de aptitudes. Este tutorial usa un conjunto de aptitudes integradas para el conjunto de aptitudes:
Reconocimiento óptico de caracteres para reconocer texto escrito a mano e impreso en los archivos de imagen.
Combinación de texto para consolidar el texto de una colección de campos en un solo campo, "merged content".
Detección de idioma para identificar el idioma del contenido.
Reconocimiento de entidades para extraer los nombres de las organizaciones del contenido del contenedor de blobs.
División de texto para dividir contenido grande en fragmentos más pequeños antes de llamar a la aptitud de extracción de frases clave y a la aptitud de reconocimiento de entidades. La extracción de frases clave y el reconocimiento de entidades aceptan entradas de 50 000 caracteres, o menos. Algunos de los archivos de ejemplo deben dividirse para no superar este límite.
Extracción de frases clave para extraer las frases clave principales.
Durante el procesamiento inicial, Azure AI Search descifra cada documento para extraer el contenido de distintos formatos de archivo. El texto procedente del archivo de origen se coloca en un campo content generado, uno para cada documento. Por lo tanto, establezca la entrada como "/document/content" para usar este texto. El contenido de la imagen se coloca en un campo normalized_images generado, especificado en un conjunto de aptitudes como /document/normalized_images/*.
Las salidas se pueden asignar a un índice, usar como entrada para una aptitud descendente, o ambas cosas como sucede con el código de idioma. En el índice, un código de idioma es útil para el filtrado. Como entrada, el código de idioma se usa en las aptitudes de análisis de texto para informar a las reglas lingüísticas de la separación de palabras.
Para obtener más información sobre los conceptos básicos del conjunto de aptitudes, consulte el tema sobre la definición de un conjunto de aptitudes.
Habilidad de OCR
OcrSkill extrae texto de imágenes. Esta aptitud supone que existe un campo normalized_images. Para generar este campo, más adelante en el tutorial también establecemos la configuración de "imageAction" en la definición del indexador en "generateNormalizedImages".
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Aptitud Combinar
En esta sección, crea una MergeSkill que combina el campo de contenido del documento con el texto que se ha producido con la aptitud de OCR.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Aptitud Detección de idioma
LanguageDetectionSkill detecta el idioma del texto de entrada e informa de un único código de idioma para cada documento enviado en la solicitud. Usamos la salida de la aptitud Detección de idioma como parte de la entrada de la aptitud División de texto.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Aptitud División de texto
La SplitSkill siguiente divide el texto por páginas y limita la longitud de la página a 4 000 caracteres, según lo medido por String.Length. El algoritmo intenta dividir el texto en fragmentos que tengan un tamaño de maximumPageLength como máximo. En este caso, el algoritmo hace todo lo posible por dividir la frase en un límite de oración, por lo que el tamaño del fragmento puede ser ligeramente inferior a maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Aptitud Reconocimiento de entidades
Esta instancia EntityRecognitionSkill está configurada para reconocer el tipo de categoría organization. EntityRecognitionSkill también puede reconocer los tipos de categoría person y location.
Tenga en cuenta que el campo "context" se establece en "/document/pages/*" con un asterisco, lo que significa que se llama al paso de enriquecimiento para cada página en "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Aptitud Extracción de frases clave
Al igual que la instancia EntityRecognitionSkill recién creada, se llama a KeyPhraseExtractionSkill en cada página del documento.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Compilar y crear el conjunto de aptitudes
Compile SearchIndexerSkillset con las aptitudes que ha creado.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Agregue las siguientes líneas a Main.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Paso 3: Creación de un índice
En esta sección, se define el esquema de índice. Para ello, se especifican los campos que se incluirán en el índice que permite búsquedas y los atributos de búsqueda de cada campo. Los campos tienen un tipo y pueden tener atributos que determinen cómo se utiliza el campo (si permite búsquedas, se puede ordenar, etc.). Los nombres de campos de un índice no tienen que coincidir exactamente con los nombres de campo del origen. En un paso posterior, agregará asignaciones de campos en un indexador para conectar los campos de origen y destino. Para este paso, defina el índice con convenciones de nomenclatura de campos adecuadas para la aplicación de búsqueda.
En este ejercicio se utilizan los siguientes campos y tipos de campos:
| Nombres de campo | Tipos de campo |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
List<Edm.String> |
organizations |
List<Edm.String> |
Crear la clase DemoIndex
Los campos de este índice se definen mediante una clase de modelo. Cada propiedad de la clase de modelo tiene atributos que determinan los comportamientos relacionados con la búsqueda del campo de índice correspondiente.
Vamos a agregar la clase del modelo a un nuevo archivo de C#. Haga clic con el botón derecho para seleccionar el proyecto y seleccione Agregar>Nuevo elemento..., seleccione "Class" y el nombre del archivo DemoIndex.cs. Luego, seleccione Agregar.
Asegúrese de indicar que quiere usar tipos de los espacios de nombres Azure.Search.Documents.Indexes y System.Text.Json.Serialization.
Agregue la siguiente definición de la clase de modelo en DemoIndex.cs e inclúyala en el mismo espacio de nombres donde crea el índice.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Ahora que ha definido una clase de modelo, de nuevo en Program.cs, puede crear una definición de índice con bastante facilidad. El nombre de este índice será demoindex. Si ya existe un índice con ese nombre, se elimina.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Durante las pruebas, es posible que intente crear el índice más de una vez. Por este motivo, compruebe si el índice que está por crear ya existe antes de intentar crearlo.
Agregue las siguientes líneas a Main.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Agregue la instrucción using para resolver la referencia relativa a la eliminación de ambigüedad.
using Index = Azure.Search.Documents.Indexes.Models;
Para más información sobre los conceptos de índices, consulte Creación de un índice (API REST de Azure Cognitive Search).
Paso 4: Creación y ejecución de un indexador
Hasta ahora, ha creado un origen de datos, un conjunto de aptitudes y un índice. Estos tres componentes pasan a formar parte de un indexador que extrae todas las piezas juntas en una sola operación de varias fases. Para unirlas en un indexador, debe definir las asignaciones de campos.
Los campos fieldMappings se procesan antes que el conjunto de aptitudes, lo que asigna los campos de origen del origen de datos a los campos de destino de un índice. Si los tipos y nombres de campo son los mismos en ambos extremos, no se requiere ninguna asignación.
Los campos outputFieldMappings se procesan después que el conjunto de aptitudes y hacen referencia a las asignaciones sourceFieldNames que no existen hasta que el descifrado o enriquecimiento de documentos las crean. targetFieldName es un campo de un índice.
Además de enlazar las entradas con las salidas, también puede usar las asignaciones de campos para aplanar las estructuras de datos. Para más información, consulte Asignación de campos enriquecidos a un índice de búsqueda.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Agregue las siguientes líneas a Main.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Lo habitual es que el procesamiento del indexador tarde un tiempo en completarse. Aunque el conjunto de datos es pequeño, las aptitudes analíticas realiza un uso intensivo de los recursos. Algunas aptitudes, como el análisis de imágenes, son de larga ejecución.
Sugerencia
La creación de un indexador invoca la canalización. Si hay problemas para conectar con los datos, las entradas y salidas de asignación o el orden de las operaciones, se muestran en esta fase.
Explorar la creación del indexador
El código establece "maxFailedItems" en -1, lo que indica al motor de indexación que ignore los errores que se produzcan durante la importación de datos. Esto es útil porque hay muy pocos documentos en el origen de datos de demostración. Para un origen de datos mayor, debería establecer un valor mayor que 0.
Observe también que "dataToExtract" se estable en "contentAndMetadata". Esta instrucción indica al indexador que extraiga automáticamente el contenido de diferentes formatos de archivo, así como los metadatos relacionados con cada archivo.
Una vez extraído el contenido, puede establecer imageAction para que se extraiga el texto de las imágenes que se encuentran en el origen de datos. La configuración de "imageAction" establecido en "generateNormalizedImages", combinada con la aptitud de OCR y la aptitud de Combinación de texto, indica al indexador que extraiga el texto de las imágenes (por ejemplo, la palabra "stop" de la señal de tráfico Stop) y lo inserte como parte del campo de contenido. Este comportamiento se aplica a las imágenes incrustadas en los documentos (piense en una imagen de un archivo PDF), así como a las imágenes que se encuentran en el origen de datos, como un archivo JPG.
Supervisión de la indexación
Una vez definido el indexador, se ejecuta automáticamente cuando se envía la solicitud. Dependiendo de las aptitudes definidas, la indexación puede tardar más de lo esperado. Para averiguar si el indexador todavía se está ejecutando, use el método GetStatus.
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo representa el estado actual y el historial de ejecución de un indexador.
Las advertencias son comunes con algunas combinaciones de aptitudes y archivos de origen y no siempre indican un problema. En este tutorial, las advertencias son benignas (por ejemplo, no hay entradas de texto de archivos JPEG).
Agregue las siguientes líneas a Main.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Buscar
En las aplicaciones de consola del tutorial de Azure AI Search, normalmente se agrega un retraso de 2 segundos antes de ejecutar consultas que devuelvan resultados, pero como el enriquecimiento tarda varios minutos en completarse, cerraremos la aplicación de consola y usaremos otro enfoque.
La opción más sencilla es usar el Explorador de búsqueda en el portal. En primer lugar, puede ejecutar una consulta vacía que devuelva todos los documentos o una búsqueda más concreta que devuelva el nuevo contenido del campo creado por la canalización.
En Azure Portal, en la página de información general de la búsqueda, seleccione Índices.
Busque
demoindexen la lista. Debería tener 14 documentos. Si el número de documentos es cero, significa que el indexador se sigue ejecutando o que la página aún no se ha actualizado.Seleccione
demoindex. Explorador de búsqueda es la primera pestaña.Se podrán realizar búsquedas en el contenido en cuanto se cargue el primer documento. Para comprobar que el contenido existe, ejecute una consulta sin especificar haciendo clic en Buscar. Esta consulta devuelve todos los documentos indexados actualmente, lo que le da una idea de lo que contiene el índice.
Luego, pegue la cadena siguiente para obtener resultados más fáciles de administrar:
search=*&$select=id, languageCode, organizations
Restablecer y volver a ejecutar
En las primeras etapas experimentales de desarrollo, el enfoque más práctico para la iteración de diseño es eliminar los objetos de Azure AI Search y permitir que el código vuelva a generarlos. Los nombres de los recursos son únicos. La eliminación de un objeto permite volver a crearlo con el mismo nombre.
En el código de ejemplo de este tutorial se comprueban los objetos existentes y se eliminan para que pueda volver a ejecutar el código. También puede usar el portal para eliminar los índices, los indexadores y los conjuntos de aptitudes.
Puntos clave
En este tutorial se han mostrado los pasos básicos para la creación de una canalización de indexación enriquecida a través de la creación de componentes: un origen de datos, un conjunto de aptitudes, un índice y un indexador.
Se presentaron las aptitudes integradas, junto con la definición del conjunto de aptitudes y los mecanismos de encadenamiento de aptitudes, mediante entradas y salidas. También ha aprendido que outputFieldMappings en la definición del indexador se necesita para enrutar los valores enriquecidos de la canalización a un índice que permita búsquedas en un servicio Azure AI Search.
Por último, ha aprendido cómo probar los resultados y restablecer el sistema para otras iteraciones. Ha aprendido que emitir consultas en el índice devuelve la salida creada por la canalización de indexación enriquecida. También ha aprendido cómo comprobar el estado del indexador y qué objetos se deben eliminar antes de volver a ejecutar una canalización.
Limpieza de recursos
Cuando trabaje con su propia suscripción, al final de un proyecto, es recomendable eliminar los recursos que ya no necesite. Los recursos que se dejan en ejecución pueden costarle mucho dinero. Puede eliminar los recursos de forma individual o eliminar el grupo de recursos para eliminar todo el conjunto de recursos.
Puede encontrar y administrar recursos en el portal, mediante el vínculo Todos los recursos o Grupos de recursos en el panel de navegación izquierdo.
Pasos siguientes
Ahora que está familiarizado con todos los objetos de una canalización de enriquecimiento de AI, echemos un vistazo más de cerca a las definiciones de actitudes y a los conocimientos individuales.