Tutorial: Uso de un cuaderno con Apache Spark para consultar una base de datos de KQL
Los cuadernos son documentos legibles que contienen descripciones de análisis de datos y resultados, así como documentos ejecutables que se pueden ejecutar para realizar análisis de datos. En este artículo, aprenderá a usar un cuaderno de Microsoft Fabric para leer y escribir datos en una base de datos KQL mediante Apache Spark. En este tutorial se usan conjuntos de datos y cuadernos creados previamente tanto en análisis en tiempo real como en los entornos de Ingeniería de datos en Microsoft Fabric. Para más información sobre los cuadernos, consulte Uso de cuadernos de Microsoft Fabric.
En concreto, aprenderá a:
- Crear una base de datos KQL
- Importación de un cuaderno
- Escritura de datos en una base de datos KQL mediante Apache Spark
- Consulta de datos de una base de datos KQL
Requisitos previos
- Un área de trabajo con una capacidad habilitada para Microsoft Fabric
1- Creación de una base de datos KQL
Abra el conmutador de experiencia en la parte inferior del panel de navegación y seleccione Real-Time Analytics.
Seleccione el icono base de datos KQL.
En el campo Nombre de base de datos KQL, escriba nycGreenTaxi y seleccione Crear.
La base de datos KQL se ha creado ahora en el contexto del área de trabajo seleccionada.
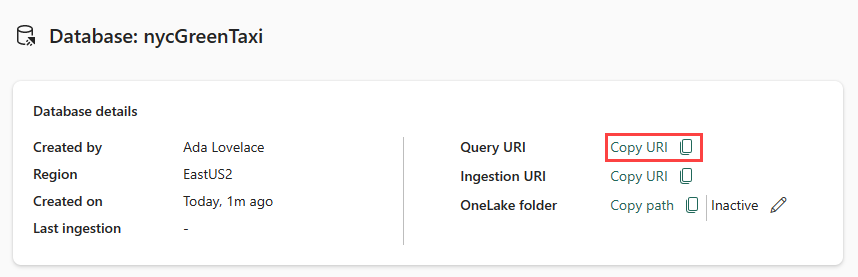
Copie el URI de consulta de la tarjeta de detalles de la base de datos en el panel de la base de datos y péguelo en algún lugar, como un bloc de notas, para usarlo en un paso posterior.
2- Descarga del cuaderno NYC GreenTaxi
Hemos creado un cuaderno de ejemplo que le lleva a través de todos los pasos necesarios para cargar datos en la base de datos mediante el conector de Spark.
Abra el repositorio de ejemplos de Fabric en GitHub para descargar el cuaderno de KQL de NYC GreenTaxi.
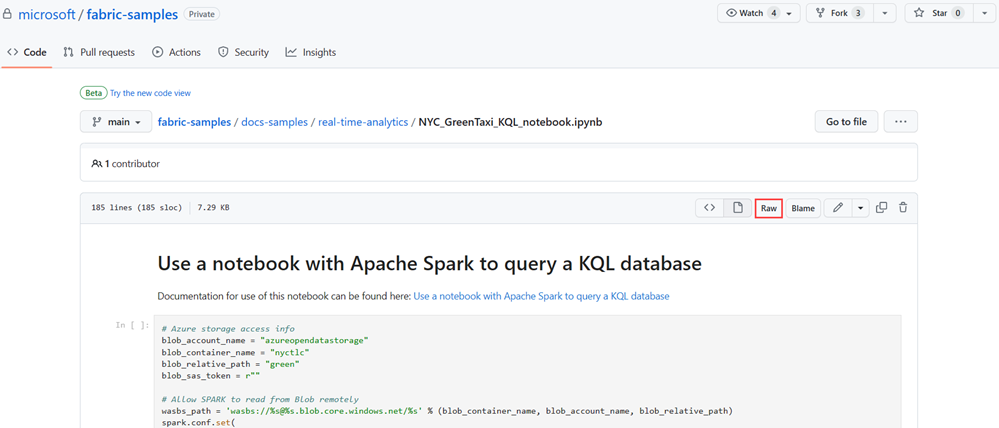
Guarde el cuaderno localmente en el dispositivo.
Nota:
El cuaderno debe guardarse en el formato de archivo
.ipynb.

3- Importación del cuaderno
El resto de este flujo de trabajo se produce en la sección Ingeniería de datos del producto y usa un cuaderno de Spark para cargar y consultar datos en la base de datos KQL.
Abra el conmutador de experiencia en la parte inferior del panel de navegación y seleccione Ingeniería de datos.
Seleccione Importar cuaderno.
En la ventana Estado de importación, seleccione Cargar.
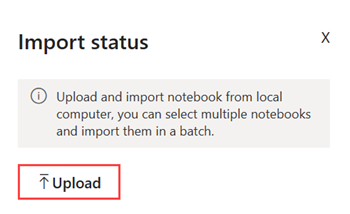
Seleccione el cuaderno NYC GreenTaxi que descargó en un paso anterior.
Una vez completada la importación, vuelva al área de trabajo para abrir este cuaderno.
4- Obtención de datos
Para consultar la base de datos mediante el conector de Spark, debe conceder acceso de lectura y escritura al contenedor de blobs de NYC GreenTaxi.
Seleccione el botón reproducir para ejecutar las celdas siguientes o seleccione la celda y presione Mayús+ Entrar. Repita este paso para cada celda de código.
Nota:
Espere a que aparezca la marca de verificación de finalización antes de ejecutar la celda siguiente.
Ejecute la celda siguiente para habilitar el acceso al contenedor de blobs de NYC GreenTaxi.
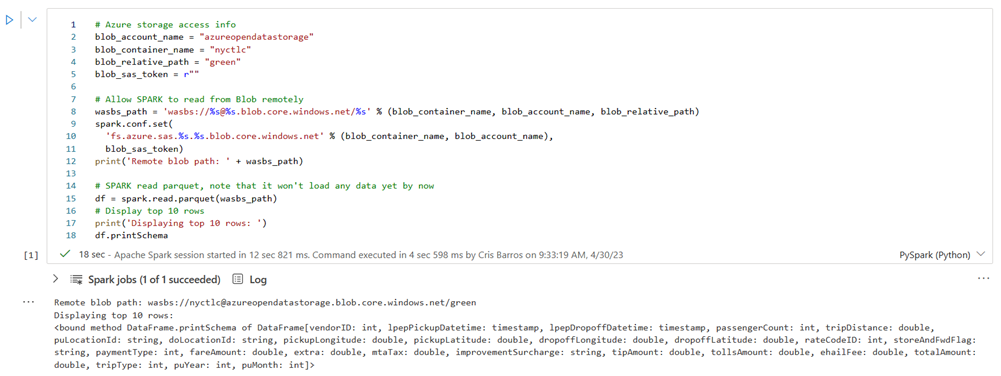
En KustoURI, pegue el URI de consulta que copió anteriormente en lugar del texto del marcador de posición.
Cambie el nombre de la base de datos de marcador de posición a nycGreenTaxi.
Cambie el nombre de la tabla de marcador de posición a GreenTaxiData.

Ejecute la celda.
Ejecute la celda siguiente para escribir datos en la base de datos. Este paso puede tardar unos minutos en completarse.




La base de datos ahora tiene datos cargados en una tabla denominada GreenTaxiData.
5- Ejecución del cuaderno
Ejecute las dos celdas restantes secuencialmente para consultar datos de la tabla. Los resultados muestran las 20 tarifas y distancias de taxi más altas y más bajas registradas por año.

6. Limpieza de recursos
Limpie los elementos creados; para ello, vaya al área de trabajo en la que se crearon.
En su área de trabajo, pase el ratón por encima del cuaderno que quiere eliminar, seleccione el menú Más>Eliminar.
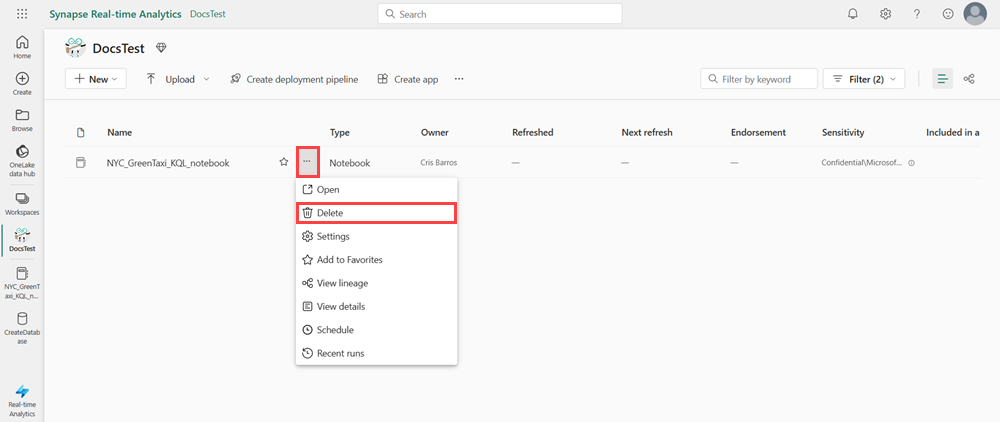
Seleccione Eliminar. No puede recuperar el cuaderno una vez que lo elimine.

Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de