Configuración de búsqueda y análisis para casos de eDiscovery (Premium)
Puede configurar los valores de cada caso de Microsoft Purview eDiscovery (Premium) para controlar la siguiente funcionalidad:
- Casi duplicados y subprocesos de correo electrónico
- Temas
- Consulta de conjunto de revisión generado automáticamente
- Omitir texto
- Reconocimiento óptico de caracteres
Sugerencia
Si no es cliente de E5, use la prueba de soluciones de Microsoft Purview de 90 días para explorar cómo las funcionalidades adicionales de Purview pueden ayudar a su organización a administrar las necesidades de cumplimiento y seguridad de datos. Comience ahora en el centro de pruebas de portal de cumplimiento Microsoft Purview. Obtenga más información sobre los términos de suscripción y evaluación.
Configuración de los valores de análisis para un caso
Para configurar las opciones de búsqueda y análisis de un caso:
- En la página de eDiscovery (Premium), seleccione el caso.
- En la pestaña Configuración , en Buscar & análisis, elija Seleccionar. Se muestra la página de configuración del caso. Esta configuración se aplica a todos los conjuntos de revisión en un caso.
En las secciones siguientes de este artículo se describen los valores de análisis que puede configurar para un caso.
Casi duplicados y subprocesos de correo electrónico
En esta sección, puede establecer parámetros para la detección de duplicados, la detección de duplicados cercana y el subproceso de correo electrónico. Para obtener más información, vea Near duplicate detection and Email threading (Detección casi de duplicados y subprocesos de Email).
- Subprocesos de correo electrónico o duplicados cercanos: Cuando está activado, la detección de duplicados, la detección casi duplicada y el subproceso de correo electrónico se incluyen como parte del flujo de trabajo al ejecutar análisis en los datos de un conjunto de revisión.
- Umbral de similitud de documentos y correo electrónico: Si el nivel de similitud de dos documentos está por encima del umbral, ambos documentos se colocan en el mismo conjunto casi duplicado.
- Número mínimo o máximo de palabras: Esta configuración especifica que los análisis de subprocesos de correo electrónico y duplicados cercanos solo se realizan en documentos que tienen al menos el número mínimo de palabras y, como máximo, el número máximo de palabras.
Temas
En esta sección, puede establecer parámetros para los temas. Para obtener más información, vea Temas.
- Temas: Cuando está activado, la agrupación en clústeres de temas se realiza como parte del flujo de trabajo al ejecutar análisis en los datos de un conjunto de revisión.
- Número máximo de temas: Especifica el número máximo de temas que se pueden generar al ejecutar análisis en los datos de un conjunto de revisión.
- Incluir números en temas: Cuando está activado, los números (que identifican un tema) se incluyen al generar temas.
- Ajuste el número máximo de temas dinámicamente: En determinadas situaciones, es posible que no haya suficientes documentos en un conjunto de revisión para generar el número deseado de temas. Cuando esta configuración está activada, eDiscovery (Premium) ajusta el número máximo de temas de forma dinámica en lugar de intentar imponer el número máximo de temas.
Consulta de un conjunto de revisión
Si activa la casilla Crear automáticamente una búsqueda guardada después del análisis , eDiscovery (Premium) genera automáticamente una consulta de conjunto de revisión denominada Para revisión.
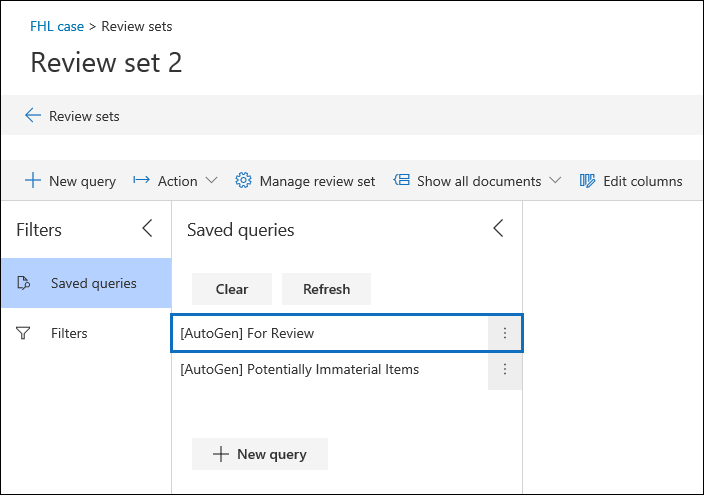
Esta consulta filtra básicamente los elementos duplicados del conjunto de revisión. Esto le permite revisar los elementos únicos del conjunto de revisión. Esta consulta se crea solo al ejecutar análisis para un conjunto de revisión en el caso. Para obtener más información, sobre las consultas de conjuntos de revisión, consulte Consulta de los datos de un conjunto de revisión.
Omitir texto
Hay situaciones en las que cierto texto disminuirá la calidad del análisis, como largas declinaciones de responsabilidades que se agregan a los mensajes de correo electrónico independientemente del contenido del correo electrónico. Si sabe de texto que debe omitirse, puede excluirlo del análisis especificando la cadena de texto y la función de análisis (casi duplicados, conversación por correo electrónico, temas y relevancia) para las que se debe excluir el texto. También se admite el uso de expresiones regulares (RegEx) como texto omitido.
Reconocimiento óptico de caracteres (OCR)
Cuando esta configuración está activada, el procesamiento de OCR se ejecutará en archivos de imagen. El procesamiento de OCR se ejecuta en las siguientes situaciones:
- Cuando los custodios y los orígenes de datos que no son de custodia se agregan a un caso. Cuando se aplica OCR a los archivos de imagen, el texto de esos archivos se puede buscar durante una colección. El procesamiento de OCR se realiza durante el proceso de indexación avanzada . OCR solo se ejecuta en elementos que se procesan durante la indexación avanzada. Por ejemplo, si durante la indexación avanzada se procesa un archivo PDF de gran tamaño parcialmente indexado o que tenía otros errores de indexación, el archivo también tendrá aplicado OCR. En otras palabras, el procesamiento ocr solo se produce en los archivos que se vuelven a indexar durante el proceso de indexación avanzada. Esto significa que puede haber situaciones en las que los custodios se agregan a un caso, pero algunos datos adjuntos de correo electrónico no se procesarán para OCR porque esos archivos no se procesan durante la indexación avanzada.
- Cuando el contenido de otros orígenes de datos (que no están asociados a un custodio y que se agregan al caso en un origen de datos que no es de custodia) se agrega a un conjunto de revisión.
Una vez agregados los datos a un conjunto de revisión, se puede revisar, buscar, etiquetar y analizar el texto de la imagen. Puede ver el texto extraído en el Visor de texto del archivo de imagen seleccionado en el conjunto de revisión. Para más información, vea:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de