Escenarios de tabla calculada y casos de uso
Usar tablas calculadas en un flujo de datos tiene ventajas. En este artículo se describen los casos de uso de las tablas calculadas y cómo funcionan internamente.
¿Qué es una tabla calculada?
Una tabla representa la salida de datos de una consulta creada en un flujo de datos, una vez actualizado el flujo de datos. Representa los datos de un origen y, opcionalmente, las transformaciones que se le aplicaron. A veces, es posible que desee crear nuevas tablas que sean una función de una tabla ingerida previamente.
Aunque es posible repetir las consultas que crearon una tabla y aplicarles nuevas transformaciones, este enfoque tiene inconvenientes: los datos se ingieren dos veces y se duplica la carga en el origen de datos.
Las tablas calculadas resuelven ambos problemas. Las tablas calculadas son similares a otras tablas porque obtienen datos de un origen y se pueden aplicar transformaciones adicionales para crearlas. Pero sus datos se originan en el flujo de datos de almacenamiento usado, y no en el origen de datos original. Es decir, se crearon previamente mediante un flujo de datos y, a continuación, se reutilizaron.
Las tablas calculadas se pueden crear haciendo referencia a una tabla en el mismo flujo de datos o haciendo referencia a una tabla creada en un flujo de datos diferente.

¿Por qué usar una tabla calculada?
Realizar todos los pasos de transformación en una tabla puede ser lento. Puede haber muchas razones para esta ralentización: el origen de datos puede ser lento o las transformaciones que está realizando podrían necesitar replicarse en dos o más consultas. Puede ser ventajoso ingerir primero los datos del origen y reutilizarlos en una o varias tablas. En tales casos, puede optar por crear dos tablas: una que obtenga datos del origen de datos y otra, una tabla calculada, que aplique más transformaciones a los datos ya escritos en el lago de datos que usa un flujo de datos. Este cambio puede aumentar el rendimiento y la reutilización de los datos, lo que ahorra tiempo y recursos.
Por ejemplo, si dos tablas comparten aunque sea solo una parte de su lógica de transformación, sin una tabla calculada, la transformación debe realizarse dos veces.
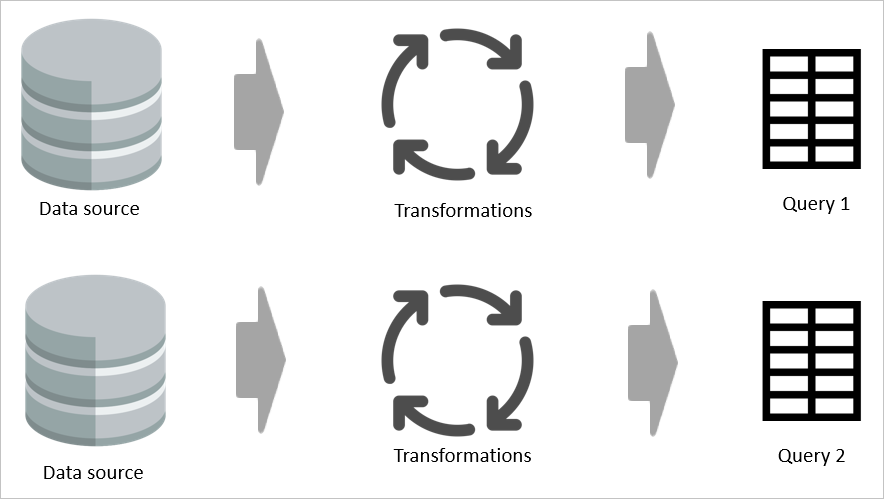
Sin embargo, si se usa una tabla calculada, la parte común (compartida) de la transformación se procesa una vez y se almacena en Azure Data Lake Storage. Las transformaciones restantes se procesan a partir de la salida de la transformación común. En general, este procesamiento es mucho más rápido.
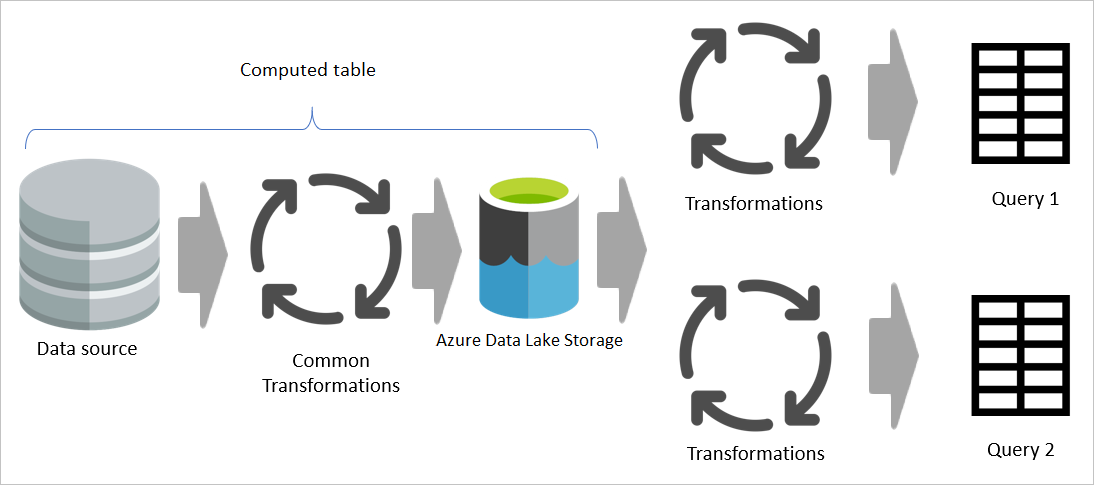
Una tabla calculada proporciona un lugar como código fuente para la transformación y acelera la transformación porque solo debe realizarse una vez en lugar de varias veces. También se reduce la carga en el origen de datos.
Escenario de ejemplo del uso de una tabla calculada
Si va a crear una tabla agregada en Power BI para acelerar el modelo de datos, puede compilar la tabla agregada haciendo referencia a la tabla original y aplicando más transformaciones a ella. Con este enfoque, no es necesario replicar la transformación desde el origen (la parte que procede de la tabla original).
Por ejemplo, la siguiente figura muestra una tabla Orders.

Con una referencia de esta tabla, puede crear una tabla calculada.
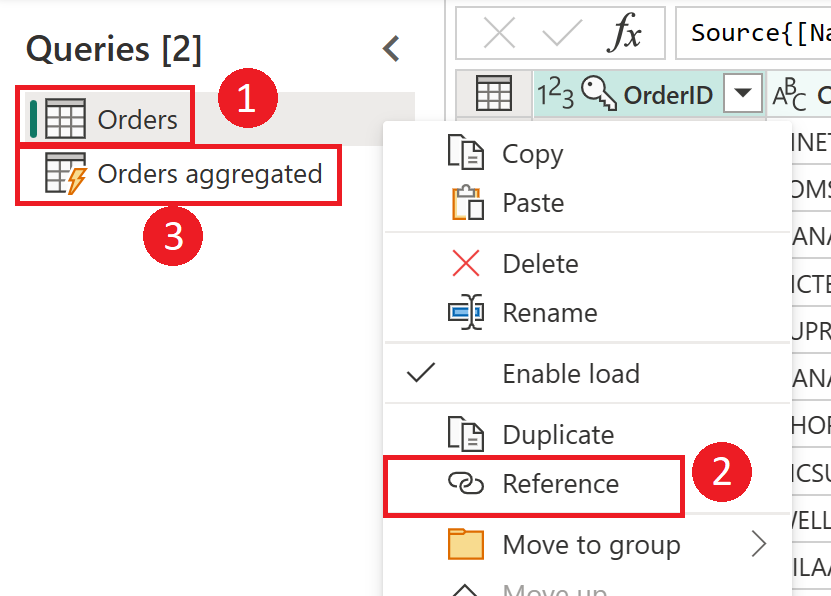
Captura de pantalla que muestra cómo crear una tabla calculada a partir de la tabla Orders. En primer lugar, haga clic con el botón derecho en la tabla Orders en el panel Consultas y seleccione la opción Referencia en el menú desplegable. Esta acción crea la tabla calculada, cuyo nombre se cambia aquí a Orders aggregated.
La tabla calculada puede tener transformaciones adicionales. Por ejemplo, puede usar Agrupar por para agregar los datos en el nivel de cliente.
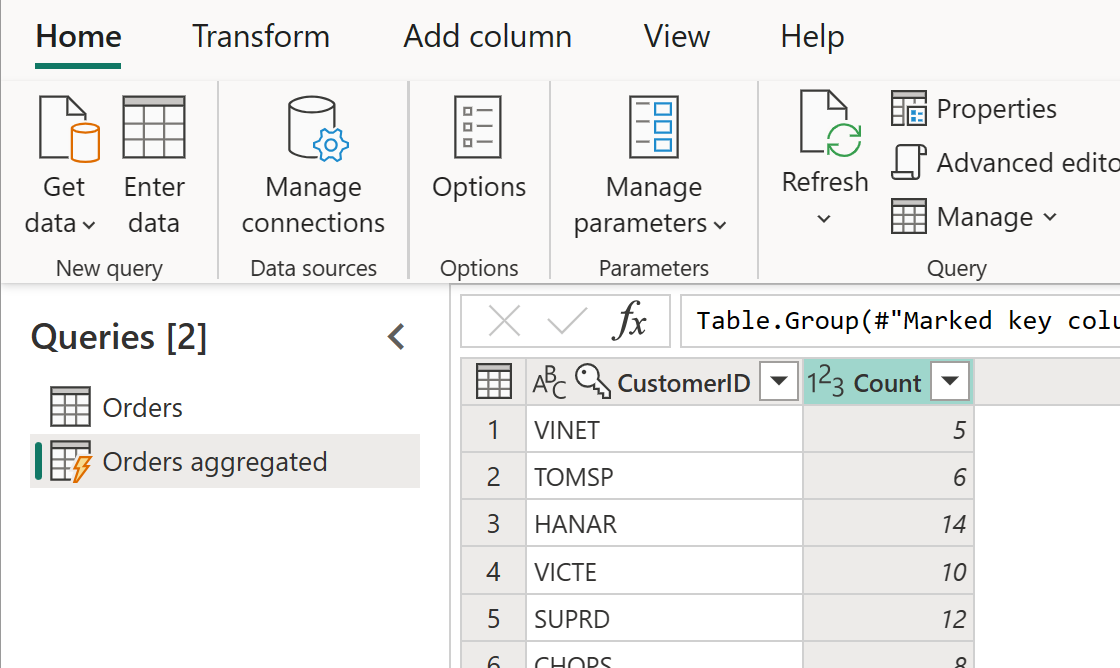
Esto significa que la tabla Orders Aggregated obtiene datos de la tabla Orders y no del origen de datos de nuevo. Dado que algunas de las transformaciones que deben realizarse ya se han realizado en la tabla Orders, el rendimiento es mejor y la transformación de datos es más rápida.
Tabla calculada en otros flujos de datos
También puede crear una tabla calculada en otros flujos de datos. Se puede crear mediante la obtención de datos de un flujo de datos con el conector de flujo de datos de Microsoft Power Platform.
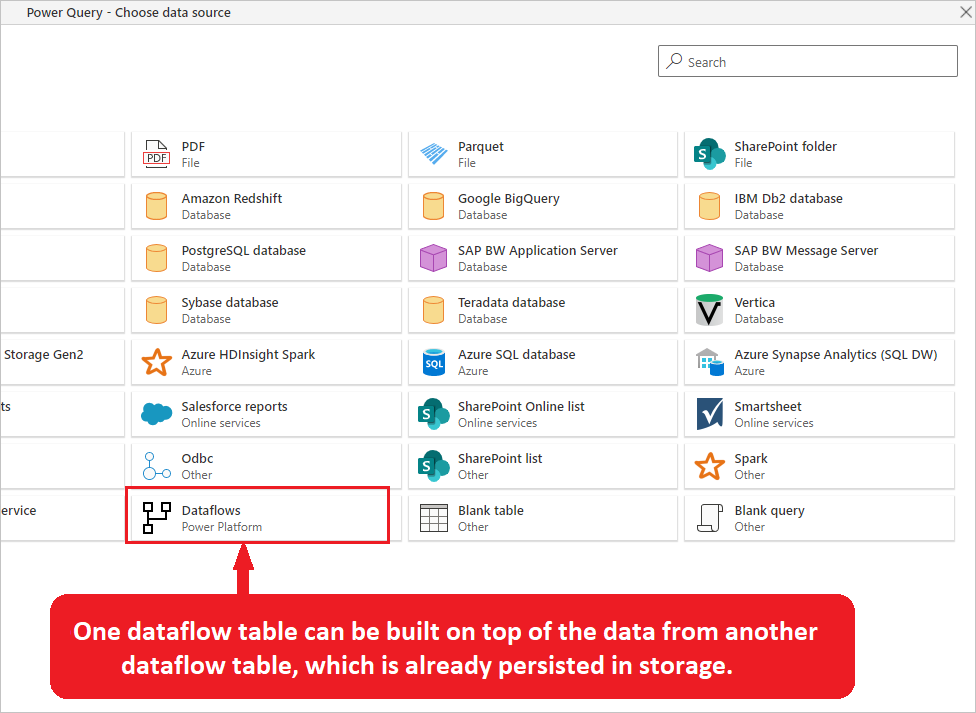
La imagen resalta el conector de flujos de datos de Power Platform de la ventana de origen de datos de Power Query. También se incluye una descripción que indica que una tabla de flujo de datos se puede compilar sobre los datos de otra tabla de flujo de datos, que ya se conserva en el almacenamiento.
El concepto de la tabla calculada es tener una tabla persistente en el almacenamiento y otras tablas procedentes de ella, de modo que pueda reducir el tiempo de lectura del origen de datos y compartir algunas de las transformaciones comunes. Esta reducción se puede lograr obteniendo datos de otros flujos de datos a través del conector de flujo de datos o haciendo referencia a otra consulta en el mismo flujo de datos.
Tabla calculada: ¿con o sin transformaciones?
Ahora que sabe que las tablas calculadas son excelentes para mejorar el rendimiento de la transformación de datos, una buena pregunta que se debe formular es si las transformaciones siempre deben diferirse a la tabla calculada o si se deben aplicar a la tabla de origen. Es decir, ¿deben ingerirse los datos siempre en una tabla y, a continuación, transformarse en una tabla calculada? ¿Cuáles son las ventajas y desventajas?
Carga de datos sin transformación para archivos Text/CSV
Cuando un origen de datos no admite el plegado de consultas (como archivos Text/CSV), hay pocas ventajas en la aplicación de transformaciones al obtener datos del origen, especialmente si los volúmenes de datos son grandes. La tabla de origen solo debe cargar datos del archivo Text/CSV sin aplicar ninguna transformación. A continuación, las tablas calculadas pueden obtener datos de la tabla de origen y realizar la transformación sobre los datos ingeridos.
Puede preguntar, ¿cuál es el valor de crear una tabla de origen que solo ingiere datos? Esta tabla puede ser útil, ya que si los datos del origen se usan en más de una tabla, reduce la carga en el origen de datos. Además, otros usuarios y flujos de datos pueden reutilizar los datos. Las tablas calculadas son especialmente útiles en escenarios en los que el volumen de datos es grande o cuando se accede a un origen de datos a través de una puerta de enlace de datos local, ya que reducen el tráfico de la puerta de enlace y la carga en orígenes de datos detrás de ellas.
Realizar algunas de las transformaciones comunes para una tabla SQL
Si el origen de datos admite el plegado de consultas, es bueno realizar algunas de las transformaciones de la tabla de origen porque la consulta se pliega en el origen de datos y solo se capturan los datos transformados. Estos cambios mejoran el rendimiento general. El conjunto de transformaciones que es común en las tablas calculadas descendentes se debe aplicar en la tabla de origen, por lo que se pueden plegar en el origen. Otras transformaciones que solo se aplican a las tablas descendentes deben realizarse en tablas calculadas.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de