Inicio rápido: Creación y puntuación de un modelo predictivo en R con el aprendizaje automático de SQL
Se aplica a:![]() SQL Server 2016 (13.x) y versiones posteriores
SQL Server 2016 (13.x) y versiones posteriores ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
En este inicio rápido, creará y entrenará un modelo predictivo con T. Guardará el modelo en una tabla de su instancia de SQL Server y, después, usará el modelo para predecir valores a partir de datos nuevos mediante SQL Server Machine Learning Services o en clústeres de macrodatos.
En este inicio rápido, creará y entrenará un modelo predictivo con T. Guardará el modelo en una tabla de su instancia de SQL Server y, después, usará el modelo para predecir valores a partir de datos nuevos mediante SQL Server Machine Learning Services.
En este inicio rápido, creará y entrenará un modelo predictivo con T. Guardará el modelo en una tabla de su instancia de SQL Server y, después, usará el modelo para predecir valores a partir de datos nuevos mediante SQL Server R Services.
En este inicio rápido, creará y entrenará un modelo predictivo con T. Guardará el modelo en una tabla de su instancia de SQL Server y, después, usará el modelo para predecir valores a partir de datos nuevos mediante Machine Learning Services en Azure SQL Managed Instance.
Creará y ejecutará dos procedimientos almacenados que se ejecutan en SQL. El primero usa el conjunto de datos mtcars incluido con R y genera un sencillo modelo lineal generalizado (GLM) que predice la probabilidad de que un vehículo tenga transmisión manual. El segundo procedimiento es para puntuación: realiza una llamada al modelo generado en el primer procedimiento para generar un conjunto de predicciones basadas en datos nuevos. Al colocar código de R en un procedimiento almacenado en SQL, las operaciones se incluyen en SQL, son reutilizables y pueden recibir llamadas de otros procedimientos almacenados y aplicaciones cliente.
Sugerencia
Para más información sobre los modelos lineales, pruebe este tutorial, donde se describe el proceso para adaptar un modelo mediante rxLinMod: Ajuste de modelos lineales
Después de completar este inicio rápido, aprenderá a:
- Insertar código de R en un procedimiento almacenado
- Pasar entradas en el código mediante entradas en el procedimiento almacenado
- Usar procedimientos almacenados para hacer operativos los modelos
Prerrequisitos
Para ejecutar este inicio rápido, debe cumplir los siguientes requisitos previos.
- SQL Server Machine Learning Services. Para instalar Machine Learning Services, vea la Guía de instalación para Windows o la Guía de instalación para Linux. También puede habilitar Machine Learning Services en clústeres de macrodatos de SQL Server.
- SQL Server Machine Learning Services. Para instalar Machine Learning Services, vea la Guía de instalación para Windows.
- SQL Server 2016 R Services. Para instalar R Services, consulte la Guía de instalación de Windows.
- Machine Learning Services en Azure SQL Managed Instance. Para obtener información, vea Machine Learning Services de Instancia administrada de Azure SQL (versión preliminar).
- Una herramienta para ejecutar consultas de SQL que contengan scripts de R. En este inicio rápido se utiliza Azure Data Studio.
Creación del modelo
Para crear el modelo, creará los datos de origen para el entrenamiento, creará el modelo y lo entrenará con los datos; después, guardará el modelo en una base de datos, donde podrá usarse para generar predicciones con datos nuevos.
Crear el origen de datos
Abra Azure Data Studio, conéctese a su instancia y abra una nueva ventana de consulta.
En primer lugar, cree una tabla para guardar los datos de entrenamiento.
CREATE TABLE dbo.MTCars( mpg decimal(10, 1) NOT NULL, cyl int NOT NULL, disp decimal(10, 1) NOT NULL, hp int NOT NULL, drat decimal(10, 2) NOT NULL, wt decimal(10, 3) NOT NULL, qsec decimal(10, 2) NOT NULL, vs int NOT NULL, am int NOT NULL, gear int NOT NULL, carb int NOT NULL );Inserte los datos desde el conjunto de datos integrado
mtcars.INSERT INTO dbo.MTCars EXEC sp_execute_external_script @language = N'R' , @script = N'MTCars <- mtcars;' , @input_data_1 = N'' , @output_data_1_name = N'MTCars';Sugerencia
Muchos conjuntos de datos, pequeños y grandes, se incluyen con el entorno en tiempo de ejecución de R. Para obtener una lista de los conjuntos de datos instalados en R, escriba
library(help="datasets")desde un símbolo del sistema de R.
Creación y entrenamiento del modelo
Los datos de velocidad de coches contienen dos columnas, ambas numéricas: caballos de vapor (hp) y peso (wt). Con estos datos, creará un modelo lineal generalizado (GLM) que calcula la probabilidad de que un vehículo tenga transmisión manual.
Para crear el modelo, defina la fórmula contenida en el código de R y pase los datos como un parámetro de entrada.
DROP PROCEDURE IF EXISTS generate_GLM;
GO
CREATE PROCEDURE generate_GLM
AS
BEGIN
EXEC sp_execute_external_script
@language = N'R'
, @script = N'carsModel <- glm(formula = am ~ hp + wt, data = MTCarsData, family = binomial);
trained_model <- data.frame(payload = as.raw(serialize(carsModel, connection=NULL)));'
, @input_data_1 = N'SELECT hp, wt, am FROM MTCars'
, @input_data_1_name = N'MTCarsData'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model VARBINARY(max)));
END;
GO
- El primer argumento de
glmes el parámetro formula, que defineamcomo dependiente dehp + wt. - Los datos de entrada se almacenan en la variable
MTCarsData, que se rellena con la consulta SQL. Si no asigna un nombre específico a los datos de entrada, el nombre predeterminado de la variable será InputDataSet.
Almacenamiento del modelo en la base de datos
A continuación, almacene el modelo en una base de datos para que pueda usarlo con fines de predicción o para volver a entrenarlo.
Cree una tabla para almacenar el modelo.
El resultado de un paquete de R que crea un modelo suele ser un objeto binario. Por tanto, la tabla donde se almacena el modelo necesita tener una columna del tipo varbinary(max) .
CREATE TABLE GLM_models ( model_name varchar(30) not null default('default model') primary key, model varbinary(max) not null );Ejecute la siguiente instrucción Transact-SQL para llamar al procedimiento almacenado, genere el modelo y guárdelo en la tabla que ha creado.
INSERT INTO GLM_models(model) EXEC generate_GLM;Sugerencia
Si ejecuta este código una segunda vez, se mostrará el error siguiente: "Infracción de restricción de CLAVE PRINCIPAL… No se puede insertar una clave duplicada en el objeto dbo.stopping_distance_models". Una opción para evitar este error consiste en actualizar el nombre de cada nuevo modelo. Por ejemplo, podría cambiar el nombre a algo más descriptivo e incluir el tipo de modelo, el día en que lo creó, etc.
UPDATE GLM_models SET model_name = 'GLM_' + format(getdate(), 'yyyy.MM.HH.mm', 'en-gb') WHERE model_name = 'default model'
Puntuación de datos nuevos con el modelo entrenado
Puntuación es un término usado en ciencia de datos que equivale a generar predicciones, probabilidades y otros valores basándose en datos nuevos proporcionados a un modelo entrenado. Usará el modelo que ha creado en la sección anterior para puntuar predicciones en relación con datos nuevos.
Creación de una tabla de datos nuevos
Primero, cree una tabla con datos nuevos.
CREATE TABLE dbo.NewMTCars(
hp INT NOT NULL
, wt DECIMAL(10,3) NOT NULL
, am INT NULL
)
GO
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (110, 2.634)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (72, 3.435)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (220, 5.220)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (120, 2.800)
GO
Predicción de transmisión manual
Para obtener predicciones basándose en su modelo, escriba un script de SQL que realice lo siguiente:
- Obtener el modelo que quiere
- Obtener los nuevos datos de entrada
- Llamar a una función de predicción de R que sea compatible con ese modelo
Con el tiempo, la tabla puede contener varios modelos de R, todos creados con parámetros o algoritmos diferentes o entrenados a partir de distintos subconjuntos de datos. En este ejemplo, usaremos el modelo denominado default model.
DECLARE @glmmodel varbinary(max) =
(SELECT model FROM dbo.GLM_models WHERE model_name = 'default model');
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(glmmodel));
new <- data.frame(NewMTCars);
predicted.am <- predict(current_model, new, type = "response");
str(predicted.am);
OutputDataSet <- cbind(new, predicted.am);
'
, @input_data_1 = N'SELECT hp, wt FROM dbo.NewMTCars'
, @input_data_1_name = N'NewMTCars'
, @params = N'@glmmodel varbinary(max)'
, @glmmodel = @glmmodel
WITH RESULT SETS ((new_hp INT, new_wt DECIMAL(10,3), predicted_am DECIMAL(10,3)));
El script anterior realiza los pasos siguientes:
Utilice una instrucción SELECT para obtener un modelo único de la tabla y pasarlo como parámetro de entrada.
Después de recuperar el modelo de la tabla, llame a la función
unserializeen el modelo.Aplique la función
predictcon los argumentos apropiados al modelo y proporcione los nuevos datos de entrada.
Nota
En el ejemplo, la función str se agrega durante la fase de pruebas para comprobar el esquema de los datos que se devuelven desde R. Puede quitar la instrucción más tarde.
Los nombres de columna usados en el script de R no tienen que pasarse necesariamente al resultado del procedimiento almacenado. Esta es la cláusula WITH RESULTS usada para definir nuevos nombres de columna.
Resultados
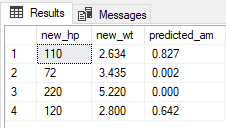
También puede usar la instrucción PREDICT (Transact-SQL) para generar una puntuación o un valor predicho basándose en un modelo almacenado.
Pasos siguientes
Para obtener más información sobre los tutoriales de R con el aprendizaje automático de SQL, consulte:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de