Servicios de recuperación ante desastres
Por motivos obvios, la recuperación de los datos de copia de seguridad es una característica habitual de los servicios de copia de seguridad. Pero un desastre no se adscribe únicamente a la pérdida de datos: una interrupción que impida que los servidores de una organización (sean reales o virtuales, locales o en la nube) estén disponibles tendrá un impacto negativo, por no decir catastrófico, en esa organización. La finalidad de un servicio de recuperación ante desastres es proporcionar una copia de seguridad no solo de los datos y los recursos individuales, sino también de los sistemas completos, de modo que si estos sistemas se desactivan o desconectan, el servicio se pueda reanudar redirigiendo el tráfico a las réplicas que están disponibles para que asuman la carga.
La recuperación ante desastres es justamente el aspecto en el que la nube pública demuestra para qué sirve verdaderamente. La nube es algo más que una unidad de cinta muy grande; como los recursos en la nube son virtuales, las réplicas se pueden poner en marcha al instante para reemplazar los recursos que hayan desaparecido repentinamente. Las réplicas pueden incluso hospedarse en partes del mundo distintas de donde están los sistemas que reflejan para evitar interrupciones en todo el área. Compare esto con el costo de mantener réplicas físicas de los sistemas de información físicos (y tratar de hacerlo en ubicaciones geográficamente distintas), y el valor de la nube para mantener la continuidad de estos sistemas empezará a ser más que evidente.
Los proveedores de servicios en la nube más importantes ofrecen recuperación ante desastres como servicio (DRaaS), pero estos servicios se deben planear y configurar deliberadamente para conseguir la conmutación por error que los clientes quieren. Por lo tanto, empezaremos examinando los objetivos y las métricas que influyen en ese planeamiento.
Objetivos y métricas
Durante un evento de desastre, una organización y sus clientes pueden perder el acceso a varias clases de recursos digitales simultáneamente. Estos son los más importantes:
Bases de datos y almacenes de datos, que aparte de registrar información fundamental sobre los clientes y los bienes y/o servicios en inventario, mantienen el estado activo de las transacciones y los procesos empresariales de toda la organización.
Datos masivos, como documentos, archivos multimedia y otros registros guardados que son los productos de las aplicaciones que los individuos usan.
Comunicaciones y conectividad con individuos y servicios empresariales; dicho de otro modo, la esencia de cualquier actividad económica que pueda desarrollarse.
Aplicaciones, que son el escaparate de la organización ante clientes y usuarios, así como ante sus propias partes interesadas.
Aunque la recuperación ante desastres se presenta a los clientes como un servicio único, el proceso de recuperación de cada una de estas clases es independiente de los demás. En la era de cliente/servidor, muchas organizaciones realizaban su actividad empresarial diaria en equipos personales. Si un equipo dejaba de funcionar y había una imagen de copia de seguridad del almacenamiento local del equipo, esta podía recuperarse en teoría en un equipo nuevo y se podía continuar con el trabajo. Con los primeros equipos en red conectados mediante sistemas operativos LAN y cable Ethernet, se podían restaurar todos los equipos de la red a partir de una imagen de copia de seguridad y, tras ello, la red podía reanudarse.
La nube no funciona de esta manera. Incluso una máquina virtual que actúa como servidor de las aplicaciones de una organización no hospeda nada del trabajo que realiza en su totalidad. Los servicios de copia de seguridad proporcionan redes de seguridad para los datos masivos y, hasta cierto punto, para los datos transaccionales y las bases de datos. Sin embargo, cada una de esas entidades es un componente particular en sí, por lo que la restauración de funciones empresariales durante un desastre requiere reconfigurar la mayor parte de la funcionalidad de cada uno de esos componentes desde una ubicación segura y sin riesgos.
Por lo tanto, el proceso de recuperación ante desastres requiere una coordinación entre cada uno de los procedimientos realizados para devolver una organización a un estado plenamente operativo. Es más, la naturaleza de la actividad empresarial que se realice durante este período es más importante debido a la existencia del propio desastre. Un evento capaz de detener la infraestructura crítica de un negocio probablemente dañe también otros aspectos funcionales: almacenes, envíos, fabricación o entregas. Probablemente, la empresa que se restaure no constituya una reanudación perfecta del negocio que se estaba desarrollando antes del evento de desastre.
Lo que une a estos procedimientos entre sí es la existencia de objetivos de nivel de servicio comunes y claramente definidos. Los servicios de recuperación ante desastres de AWS y Azure, así como de servicios de terceros basados en Google Cloud, reconocen los siguientes objetivos:
Objetivo de punto de recuperación (RPO): cantidad de datos mínima permitida que debe devolverse a los clientes para que el servicio basado en los recursos de los que se ha hecho una copia de seguridad se considere como recuperado. Desde un punto de vista contrario, esta cantidad puede considerarse como la pérdida de datos máxima aceptable, expresada como un porcentaje restado de 100.
Objetivo de tiempo de recuperación (RTO): período de tiempo máximo permitido para que se produzca un proceso de restauración, lo que también se puede considerar una medida de cuánto tiempo de inactividad está dispuesta a permitir la organización.
Período de retención: período de tiempo máximo permitido para que se retenga un conjunto de copia de seguridad antes de que sea necesario actualizarlo y reemplazarlo.
RTO y RPO se pueden considerar como equilibrados entre sí, de modo que un cliente puede decidir permitir tiempos de recuperación más largos para obtener puntos de recuperación mayores. Si el tiempo de recuperación es un problema para un cliente debido al ancho de banda disponible o al riesgo de tiempo de inactividad, es posible que el cliente no pueda alcanzar un RPO elevado.
Un asesor de riesgos profesionales o un asesor de continuidad empresarial probablemente insista en el uso de estas tres variables a la hora de formular una directiva de recuperación ante desastres. En la mayoría de los informes de análisis de impacto para empresas, el RTO y el RPO estarán en primera plana, ya que son variables críticas en las evaluaciones de los asesores de posibles pérdidas derivadas de eventos de desastre. Algunos asesores usan una variable más llamada objetivo de nivel de servicio (SLO), aunque aún no se ha llegado a una fórmula única para alcanzarlo. Que los CSP especifiquen sus niveles de servicio usando terminología que los asesores de riesgos ya reconocen y comprenden hace que sea más fácil para ambas partes trabajar conjuntamente, y este suele ser el modo en que las organizaciones eligen en última instancia a sus proveedores de recuperación ante desastres.
Metodologías y procedimientos
En la lección anterior vimos la forma más básica de recuperación del sistema de información, que conllevaba hacer copias de seguridad de los archivos, volúmenes de almacenamiento e imágenes de máquina virtual pertinentes. Aunque esto sigue ofreciéndose como una opción del servicio de recuperación ante desastres, en la práctica se aplica cada vez a menos organizaciones, sobre todo porque los objetivos del RTO no se pueden mantener de forma adecuada.
Los servicios de recuperación ante desastres profesionales ofrecen diversas metodologías de implementación y administración, algunas de las cuales conllevan un mantenimiento del servicio antes de un desastre. Estas metodologías se describen sucintamente aquí. Los tres se basan en distintas variantes de las opciones de copia de seguridad descritas en la lección anterior, y son aplicables en igual medida a todos los proveedores de servicios. Un cliente que quiera habilitar uno de estos modos de recuperación elegiría la replicación, la geolocalización y las clases de almacenamiento que mejor encajen con ese modo.
Luz piloto
Con esta metodología (Figura 5), hay espacio para un centro de datos en espera completo. En este caso, algunos servicios y aplicaciones indispensables (junto con los datos a los que dan cabida) se mantienen en un clúster de conmutación por error que se puede "iluminar" (con frecuencia, automáticamente) cuando un desastre se desencadena. Mientras tanto, los servidores virtuales se implementan solo con la funcionalidad básica necesaria para mantenerlos activos por si alguna vez debe recurrirse a ellos. Estos servidores escalonados pueden estar equipados con correo electrónico y funcionalidad web, lo que permite la comunicación con los clientes, así como dentro de la organización. Habilitar un modo de recuperación de luz piloto puede requerir una sincronización continua de los almacenes de datos volátiles, como las bases de datos transaccionales y los volúmenes de correo electrónico.
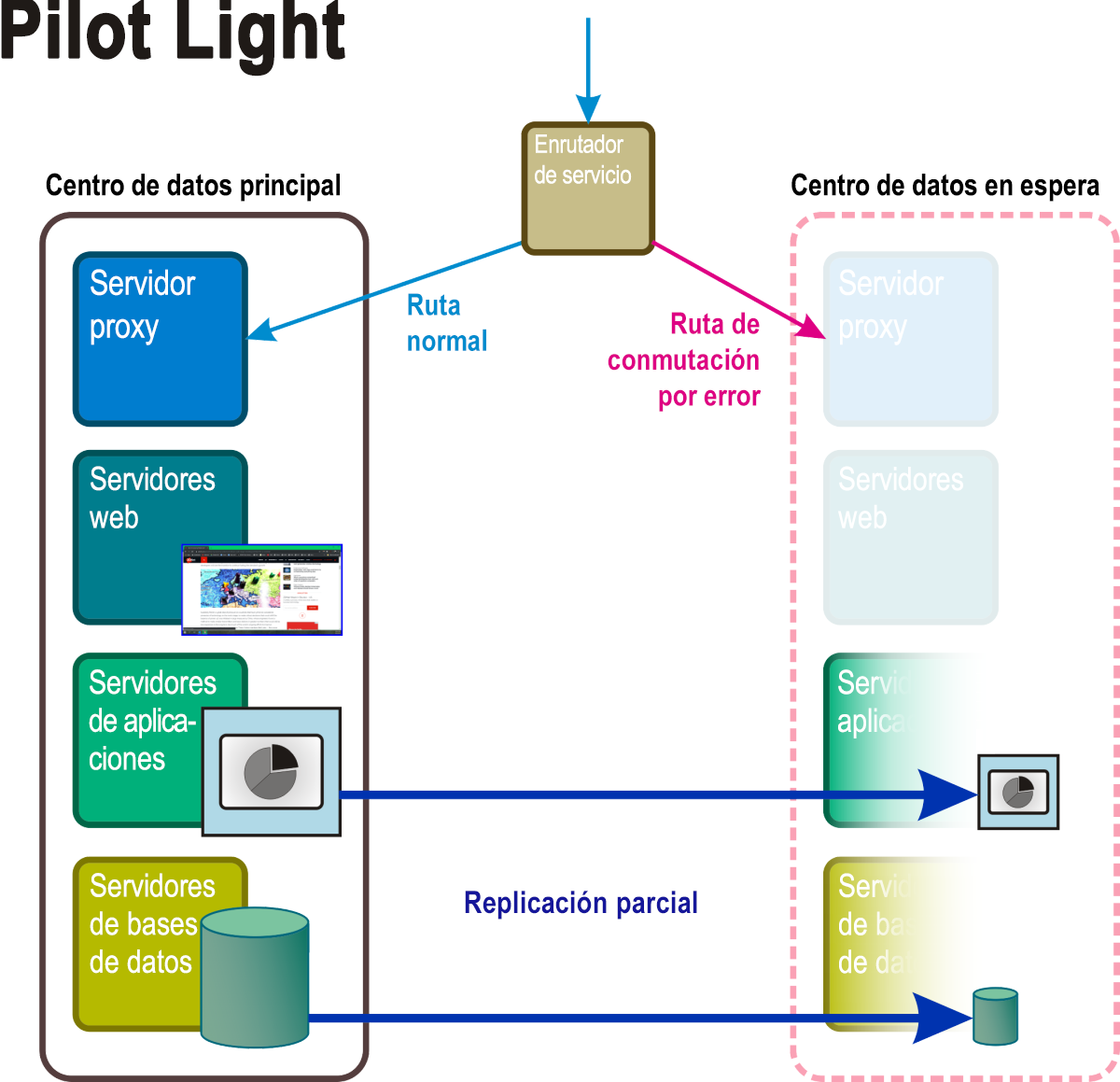
Figura 5: Componentes activos y pasivos de un escenario de recuperación de luz piloto
Estado de espera semiactiva
En este modo de recuperación, que se muestra en la Figura 6, las réplicas que funcionan de forma ininterumpida de todos los servicios y aplicaciones del sistema y de todos los datos empresariales críticos se mantienen en una ubicación geográfica independiente como mínimo. El acceso a esta réplica completa se omite en el enrutador activo hasta que un evento de desastre desencadena una regla que reemplaza la dirección de la red activa por la de dicha ruta omitida.
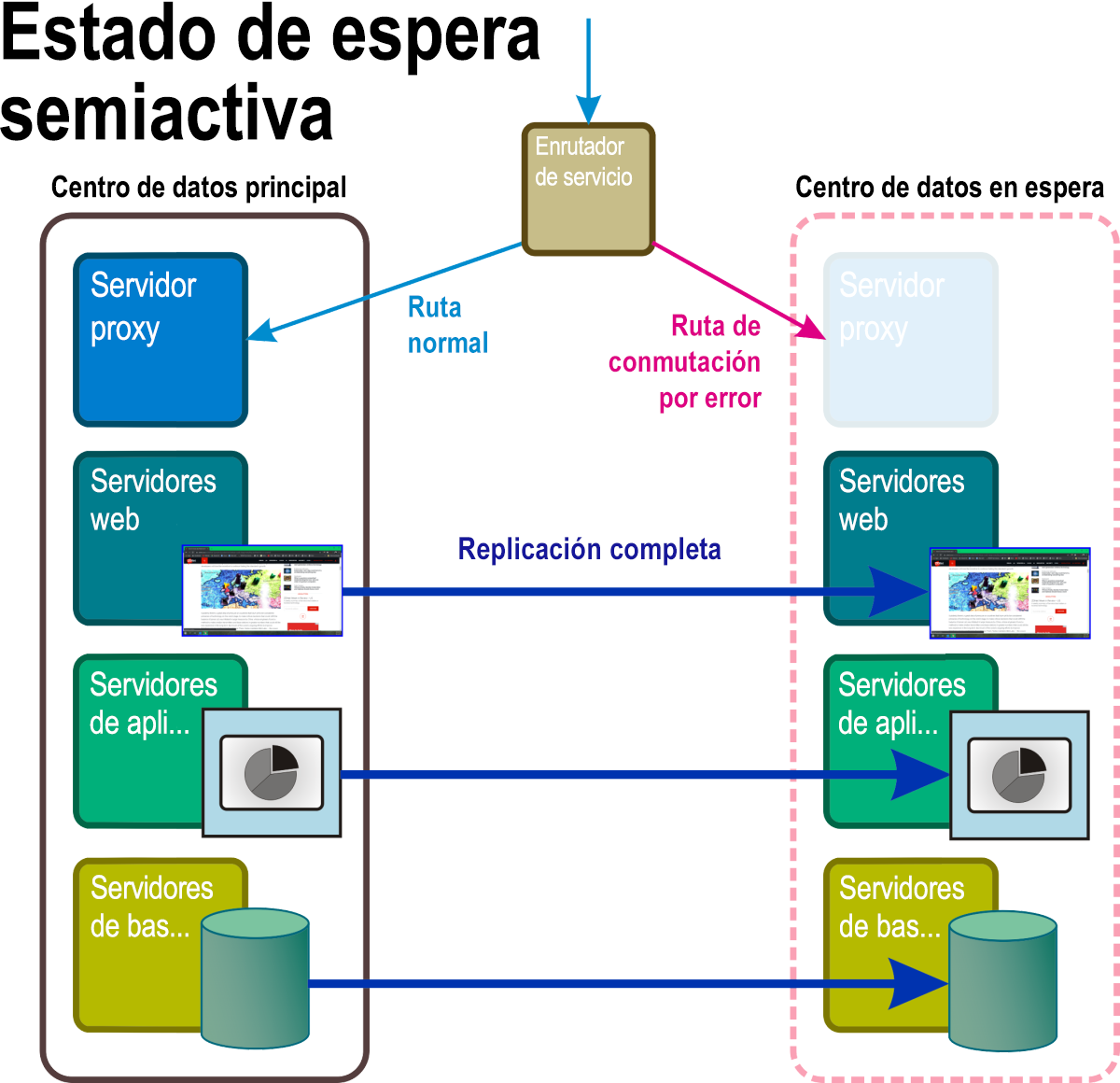
Figura 6: Escenario de recuperación en espera semiactiva con algunos componentes en el espacio de nombres en espera totalmente operativos
Espera activa
En este escenario (Figura 7), hay al menos dos réplicas completas de todos los servicios y aplicaciones funcionando en todo momento, con una sincronización de datos completa y continua entre ellas. Un enrutador maestro actúa como un tipo de equilibrador de carga general que distribuye solicitudes a todas las ubicaciones de servidor de forma más o menos proporcional. La aparición de un evento de desastre desencadena un proceso similar a un firewall, donde la dirección del sistema afectado se quita de la tabla de enrutamiento.
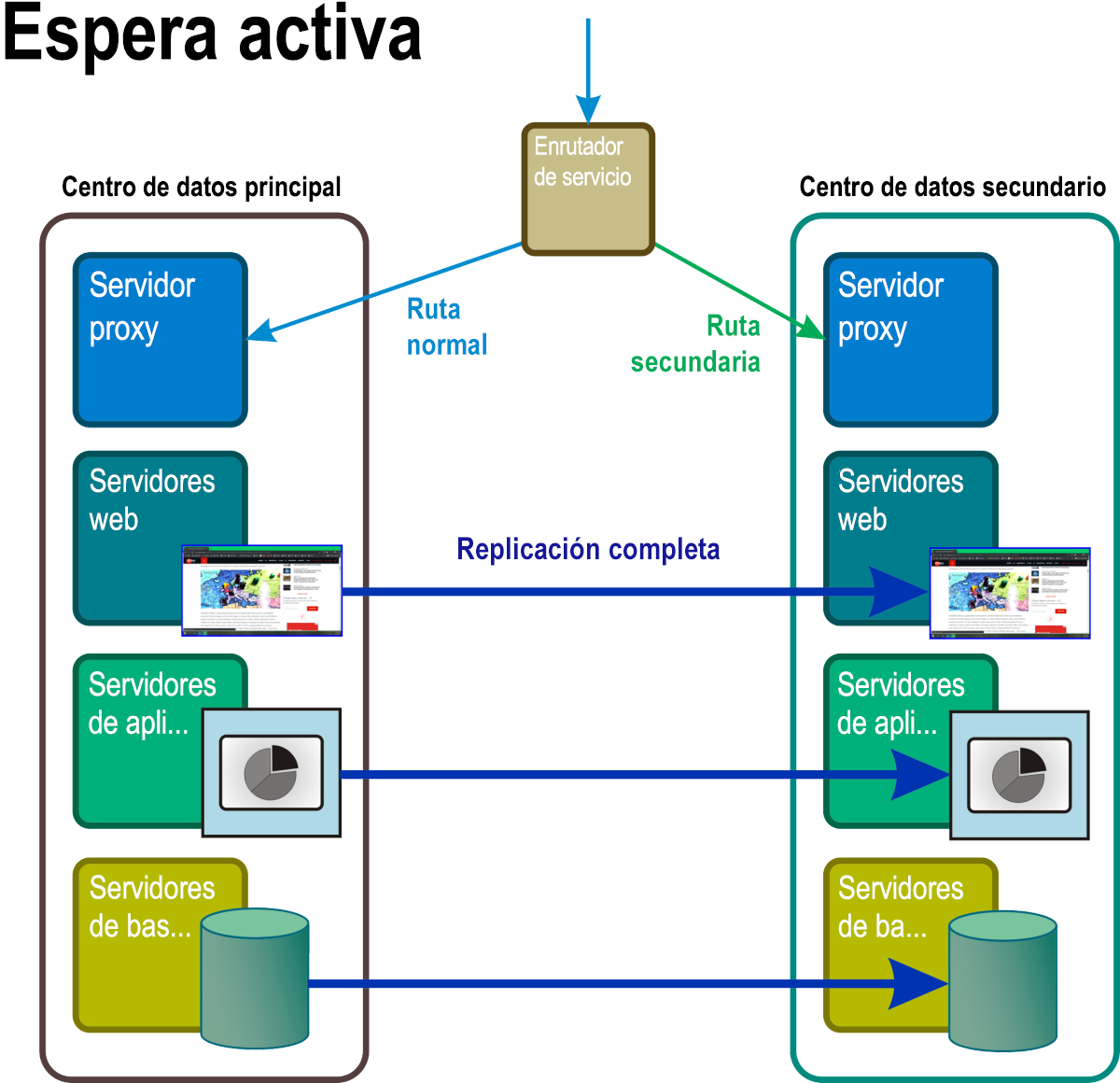
Figura 7: Con el modo de espera activa, todos los componentes del espacio de nombres de lo que normalmente habría sido el espacio en espera de reserva son réplicas activas, totalmente operativas y de procesamiento de los datos principales en tiempo real.
Aplicaciones nativas de la nube
En teoría, una organización puede elegir el servicio de recuperación ante desastres de un proveedor como una red de seguridad de los servicios hospedados por otro proveedor. En otras palabras, si existe la atención adecuada por parte del personal de TI, una infraestructura de CSP (por ejemplo, Google) puede servir de destino de conmutación por error de un procedimiento en espera semiactiva hospedado en la infraestructura de otro CSP (como Azure). Este tipo de configuración puede ser necesario por motivos de contabilidad, o si los recursos informáticos dentro de una empresa están siendo administrados por departamentos independientes en diferentes partes del mundo.
Por ahora, la presencia de una infraestructura en contenedores en el centro de datos local, así como la nube, puede tener un impacto significativo en todas estas metodologías de recuperación ante desastres. Lo que se conoce como aplicación nativa de nube, desarrollada exclusivamente para su uso en una plataforma en la nube pública o en una plataforma que funcione igual de bien (por ejemplo, Microsoft Azure Stack), distribuye funciones a varios contenedores de réplica que pueden funcionar a la vez parcial o totalmente. La razón no es tanto permitir una nueva clase de escenario de recuperación ante desastres como distribuir las cargas de trabajo entre los procesadores.
Otro aspecto de las arquitecturas nativas de nube es la posibilidad de establecer contacto con bases de datos cuyo contenido ya se haya replicado automáticamente, usando para ello una dirección de red cuya asignación sea exclusiva de la aplicación disponible (dicho de otro modo, aunque se usa el protocolo de Internet, su dirección no es una ubicación en la red pública de Internet más amplia). De este modo, durante un evento de desastre, mientras que algunos nodos conectados a la base de datos pueden dejar de funcionar, otros muchos seguirán estando operativos y otros ocuparán el lugar de los nodos no disponibles. Esto, que puede no considerarse aún como un escenario de recuperación ante desastres integrado, sí que puede calificarse como resistencia ante desastres.
Recuperación ante desastres como servicio (DRaaS)
Para un proveedor de servicios en la nube pública, la recuperación ante desastres es un medio para poner disponibles sus servicios básicos de copia de seguridad y transferencia de datos. Cada uno de los principales CSP del sector implementa una estrategia diferente para facilitar la recuperación ante desastres por encima de sus servicios de copia de seguridad.
AWS CloudEndure
Por migración de servicios se entiende la reubicación de las cargas de trabajo virtuales de una infraestructura local privada a una infraestructura en la nube pública. Esta reubicación es necesaria en algunos servicios de recuperación ante desastres que operan en la nube pública para lograr sus objetivos de misión de conmutación por error y recuperación a los pocos minutos de suceder un desastre.
En enero de 2019, Amazon adquirió el servicio de migración de servicios privados CloudEndure, que ya usaba AWS como proveedor de infraestructura. Desde entonces, ha integrado CloudEndure en su línea de servicio principal, ofreciendo funciones de migración de servicios a los clientes de Amazon sin cargo alguno. Ahora, AWS implementa la migración de servicios como un medio para habilitar rápidamente un proceso de espera semiactiva o activa. AWS no cobra a sus clientes por el proceso de migración, sino por los recursos redundantes aprovisionados en cada escenario de recuperación ante desastres. Aun así, el no acarrear una cuota extra hace que CloudEndure sea competitivo instantáneamente frente a una gran cantidad de servicios de recuperación ante desastres de terceros.
Azure Site Recovery
El servicio de recuperación ante desastres de Microsoft, Azure Site Recovery, es una implementación administrada de un método de recuperación en espera semiactiva para entornos basados en máquinas virtuales y para servidores físicos (locales) que ejecutan Linux o Windows. Las máquinas virtuales se replican activamente en una región secundaria (Figura 9.8), donde se puede iniciar una conmutación por error con un simple clic de botón. Los clientes deben abonar una cuota mensual (actualmente, de alrededor de 25 USD) por cada servidor o máquina virtual que cuente con protección de Azure Site Recovery.
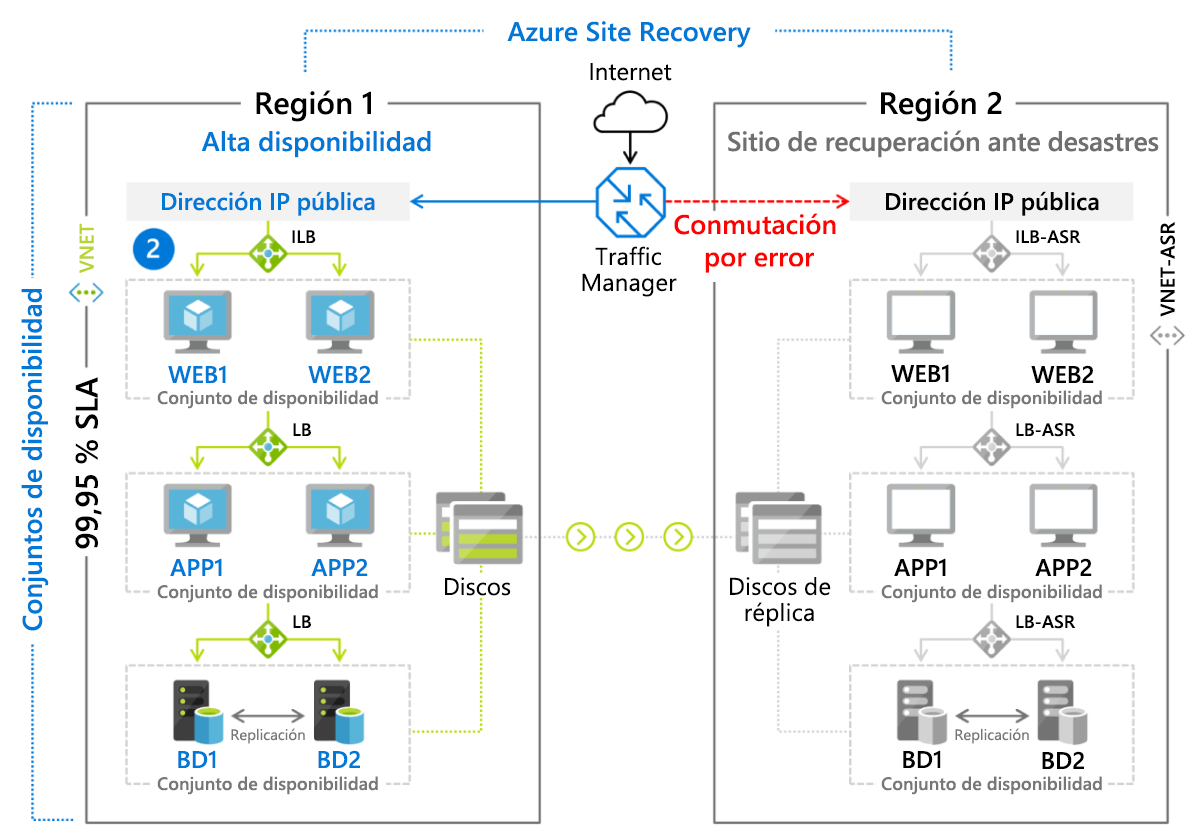
Figura 8: Escenario de conmutación por error implementado con Azure Site Recovery
Recuperación ante desastres de Google Cloud
Como sucede con las copias de seguridad, Google no presta un servicio de marca específico para la recuperación ante desastres, sino que pone a disposición de los usuarios las herramientas y los recursos necesarios para el almacenamiento de datos y la transferencia de datos, y ofrece orientación a los clientes sobre cómo usarlos en diversos escenarios de recuperación ante desastres.
Dado que Google ofrece opciones de almacenamiento de tipo Coldline y aplica un descuento, GCP se puede usar en un amplio abanico de escenarios. Coldline es una opción atractiva para organizaciones que conservan una gran cantidad de datos masivos. Los discos magnéticos giratorios no son nada prácticos para almacenar archivos multimedia cuyo tamaño medio alcanza las decenas de gigabytes. Los componentes de almacenamiento conectado a la red (NAS) proporcionan una solución de accesibilidad y capacidad de administración para crear organizaciones, pero solo en un nivel local. Tienen redundancia interna, pero no son resistentes ante desastres. Y un escenario de recuperación ante desastres como cualquiera de los tres detallados anteriormente no sería práctico (quizá ni siquiera asequible) para este tipo de cliente. Coldline constituye al menos un medio viable para que este cliente logre cierto nivel nominal de garantía de continuidad empresarial.