Estructura DML_MULTIHEAD_ATTENTION_OPERATOR_DESC (directml.h)
Realiza una operación de atención multi head (para obtener más información, consulte Atención es todo lo que necesitas). Debe haber presentes exactamente una consulta, clave y un tensor de valor, independientemente de si están apilados o no. Por ejemplo, si se proporciona StackedQueryKey, los tensores Query y Key deben ser null, ya que ya se proporcionan en un diseño apilado. Lo mismo sucede con StackedKeyValue y StackedQueryKeyValue. Los tensores apilados siempre tienen cinco dimensiones y siempre se apilan en la cuarta dimensión.
Lógicamente, el algoritmo se puede descomponer en las siguientes operaciones (las operaciones entre corchetes son opcionales):
[Add Bias to query/key/value] -> GEMM(Query, Transposed(Key)) * Scale -> [Add RelativePositionBias] -> [Add Mask] -> Softmax -> GEMM(SoftmaxResult, Value);
Importante
Esta API está disponible como parte del paquete redistribuible independiente de DirectML (consulte Microsoft.AI.DirectML versión 1.12 y posteriores). Consulte también el historial de versiones de DirectML.
Sintaxis
struct DML_MULTIHEAD_ATTENTION_OPERATOR_DESC
{
_Maybenull_ const DML_TENSOR_DESC* QueryTensor;
_Maybenull_ const DML_TENSOR_DESC* KeyTensor;
_Maybenull_ const DML_TENSOR_DESC* ValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* StackedQueryKeyValueTensor;
_Maybenull_ const DML_TENSOR_DESC* BiasTensor;
_Maybenull_ const DML_TENSOR_DESC* MaskTensor;
_Maybenull_ const DML_TENSOR_DESC* RelativePositionBiasTensor;
_Maybenull_ const DML_TENSOR_DESC* PastKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* PastValueTensor;
const DML_TENSOR_DESC* OutputTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentKeyTensor;
_Maybenull_ const DML_TENSOR_DESC* OutputPresentValueTensor;
FLOAT Scale;
FLOAT MaskFilterValue;
UINT HeadCount;
DML_MULTIHEAD_ATTENTION_MASK_TYPE MaskType;
};
Miembros
QueryTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Consulta con forma [batchSize, sequenceLength, hiddenSize], donde hiddenSize = headCount * headSize. Este tensor es mutuamente excluyente con StackedQueryKeyTensor y StackedQueryKeyValueTensor. El tensor también puede tener 4 o 5 dimensiones, siempre que las dimensiones iniciales sean 1.
KeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Clave con forma [batchSize, keyValueSequenceLength, hiddenSize], donde hiddenSize = headCount * headSize. Este tensor es mutuamente excluyente con StackedQueryKeyTensor, StackedKeyValueTensor, y StackedQueryKeyValueTensor. El tensor también puede tener 4 o 5 dimensiones, siempre que las dimensiones iniciales sean 1.
ValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Valor con forma [batchSize, keyValueSequenceLength, valueHiddenSize], donde valueHiddenSize = headCount * valueHeadSize. Este tensor es mutuamente excluyente con StackedKeyValueTensor, and StackedQueryKeyValueTensor. El tensor también puede tener 4 o 5 dimensiones, siempre que las dimensiones iniciales sean 1.
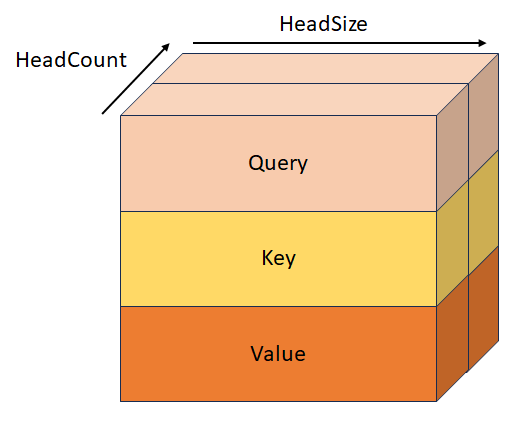
StackedQueryKeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Consulta apilada y clave con forma [batchSize, sequenceLength, headCount, 2, headSize]. Este tensor es mutuamente excluyente con QueryTensor, KeyTensor, StackedKeyValueTensor, y StackedQueryKeyValueTensor.
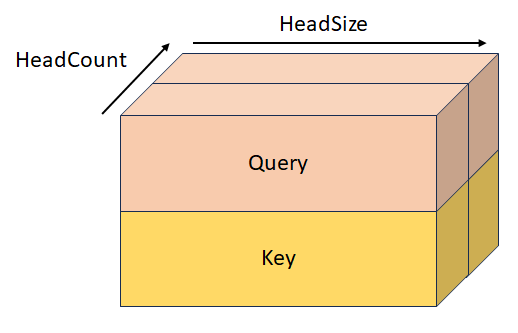
StackedKeyValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Clave apilada y valor con forma [batchSize, keyValueSequenceLength, headCount, 2, headSize]. Este tensor es mutuamente excluyente con KeyTensor, ValueTensor, StackedQueryKeyTensor, y StackedQueryKeyValueTensor.
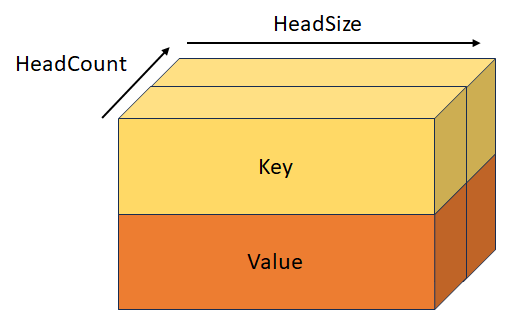
StackedQueryKeyValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Consulta apilada, clave y valor con forma [batchSize, sequenceLength, headCount, 3, headSize]. Este tensor es mutuamente excluyente con QueryTensor, KeyTensor, ValueTensor, StackedQueryKeyTensor, y StackedKeyValueTensor.
BiasTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Este es el sesgo, de la forma [hiddenSize + hiddenSize + valueHiddenSize], que se agrega al valor/ de clave/de consultaantes de la primera operación GEMM. Este tensor también puede tener 2, 3, 4 o 5 dimensiones, siempre que las dimensiones iniciales sean 1.
MaskTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Esta es la máscara que determina qué elementos obtienen su valor establecido en MaskFilterValue después de la operación GEMM de QxK. El comportamiento de esta máscara depende del valor de MaskType y se aplica después de RelativePositionBiasTensor, o después de la primera operación GEMM si RelativePositionBiasTensor es null. Para obtener más información, consulte la definición de MaskType.
RelativePositionBiasTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Este es el sesgo que se agrega al resultado de la primera operación GEMM.
PastKeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Tensor de clave de la iteración anterior con la forma [batchSize, headCount, pastSequenceLength, headSize]. Cuando este tensor no es null, se concatena con el tensor de clave, dando un tensor de forma [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize].
PastValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Tensor de valor de la iteración anterior con forma [batchSize, headCount, pastSequenceLength, headSize]. Cuando este tensor no es null, se concatena con ValueDesc, dando un tensor de forma .
OutputTensor
Tipo: const DML_TENSOR_DESC*
Salida, de la forma [batchSize, sequenceLength, valueHiddenSize].
OutputPresentKeyTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Estado presente para la clave de atención cruzada, con forma [batchSize, headCount, keyValueSequenceLength, headSize] o estado presente para la auto-atención con forma [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Contiene el contenido del tensor de clave o el contenido del tensor de clave PastKey + concatenado para pasar a la siguiente iteración.
OutputPresentValueTensor
Tipo: _Maybenull_ const DML_TENSOR_DESC*
Estado presente para el valor de atención cruzada, con forma [batchSize, headCount, keyValueSequenceLength, headSize] o estado presente para la auto atención con forma [batchSize, headCount, pastSequenceLength + keyValueSequenceLength, headSize]. Contiene el contenido del tensor de valor o el contenido del tensor de valor PastValue + concatenado para pasar a la siguiente iteración.
Scale
Tipo: FLOAT
Escala para multiplicar el resultado de la operación GEMM de QxK, pero antes de la operación Softmax. Normalmente, su valor es 1/sqrt(headSize).
MaskFilterValue
Tipo: FLOAT
Valor que se agrega al resultado de la operación GEMM de QxK a las posiciones que la máscara definió como elementos de relleno. Este valor debe ser un número negativo muy grande (normalmente -10000,0f).
HeadCount
Tipo: UINT
Número de encabezados de atención.
MaskType
Tipo: DML_MULTIHEAD_ATTENTION_MASK_TYPE
Describe el comportamiento de MaskTensor.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_BOOLEAN. Cuando la máscara contiene un valor de 0, se agrega MaskFilterValue; pero cuando contiene un valor de 1, no se agrega nada.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_LENGTH. La máscara, de la forma [1, batchSize], contiene las longitudes de secuencia del área no rellenada para cada lote y todos los elementos después de que la longitud de la secuencia obtengan su valor establecido en MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_SEQUENCE_END_START. La máscara, de la forma [2, batchSize], contiene los índices de fin (exclusivo) e inicio (inclusivo) del área no rellenada, y todos los elementos fuera del área obtienen su valor establecido en MaskFilterValue.
DML_MULTIHEAD_ATTENTION_MASK_TYPE_KEY_QUERY_SEQUENCE_LENGTH_START_END. La máscara, de forma [batchSize * 3 + 2], tiene los siguientes valores: [keyLength[0], ..., keyLength[batchSize - 1], queryStart[0], ..., queryStart[batchSize - 1], queryEnd[batchSize - 1], keyStart[0], ..., keyStart[batchSize - 1], keyEnd[batchSize - 1]].
Disponibilidad
Este operador se introdujo en DML_FEATURE_LEVEL_6_1.
Restricciones de tensor
BiasTensor, KeyTensor, OutputPresentKeyTensor, OutputPresentValueTensor, OutputTensor, PastKeyTensor, PastValueTensor, QueryTensor, RelativePositionBiasTensor, StackedKeyValueTensor, StackedQueryKeyTensor, StackedQueryKeyValueTensor y ValueTensor deben tener el mismo DataType.
Compatibilidad del tensor
| Tensor | Variante | Recuentos de dimensiones admitidos | Tipos de datos admitidos |
|---|---|---|---|
| QueryTensor | Entrada opcional | 3 a 5 | FLOAT32, FLOAT16 |
| KeyTensor | Entrada opcional | 3 a 5 | FLOAT32, FLOAT16 |
| ValueTensor | Entrada opcional | 3 a 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyTensor | Entrada opcional | 5 | FLOAT32, FLOAT16 |
| StackedKeyValueTensor | Entrada opcional | 5 | FLOAT32, FLOAT16 |
| StackedQueryKeyValueTensor | Entrada opcional | 5 | FLOAT32, FLOAT16 |
| BiasTensor | Entrada opcional | 1 a 5 | FLOAT32, FLOAT16 |
| MaskTensor | Entrada opcional | 1 a 5 | INT32 |
| RelativePositionBiasTensor | Entrada opcional | De 4 a 5 | FLOAT32, FLOAT16 |
| PastKeyTensor | Entrada opcional | De 4 a 5 | FLOAT32, FLOAT16 |
| PastValueTensor | Entrada opcional | De 4 a 5 | FLOAT32, FLOAT16 |
| OutputTensor | Salida | 3 a 5 | FLOAT32, FLOAT16 |
| OutputPresentKeyTensor | Salida opcional | De 4 a 5 | FLOAT32, FLOAT16 |
| OutputPresentValueTensor | Salida opcional | De 4 a 5 | FLOAT32, FLOAT16 |
Requisitos
| Encabezado | directml.h |