Esta arquitectura de referencia muestra una arquitectura de microservicios implementada en Azure Service Fabric. También muestra una configuración básica de clúster que puede ser el punto de partida para la mayoría de las implementaciones.
 Hay disponible una implementación de referencia de esta arquitectura en GitHub.
Hay disponible una implementación de referencia de esta arquitectura en GitHub.
Architecture
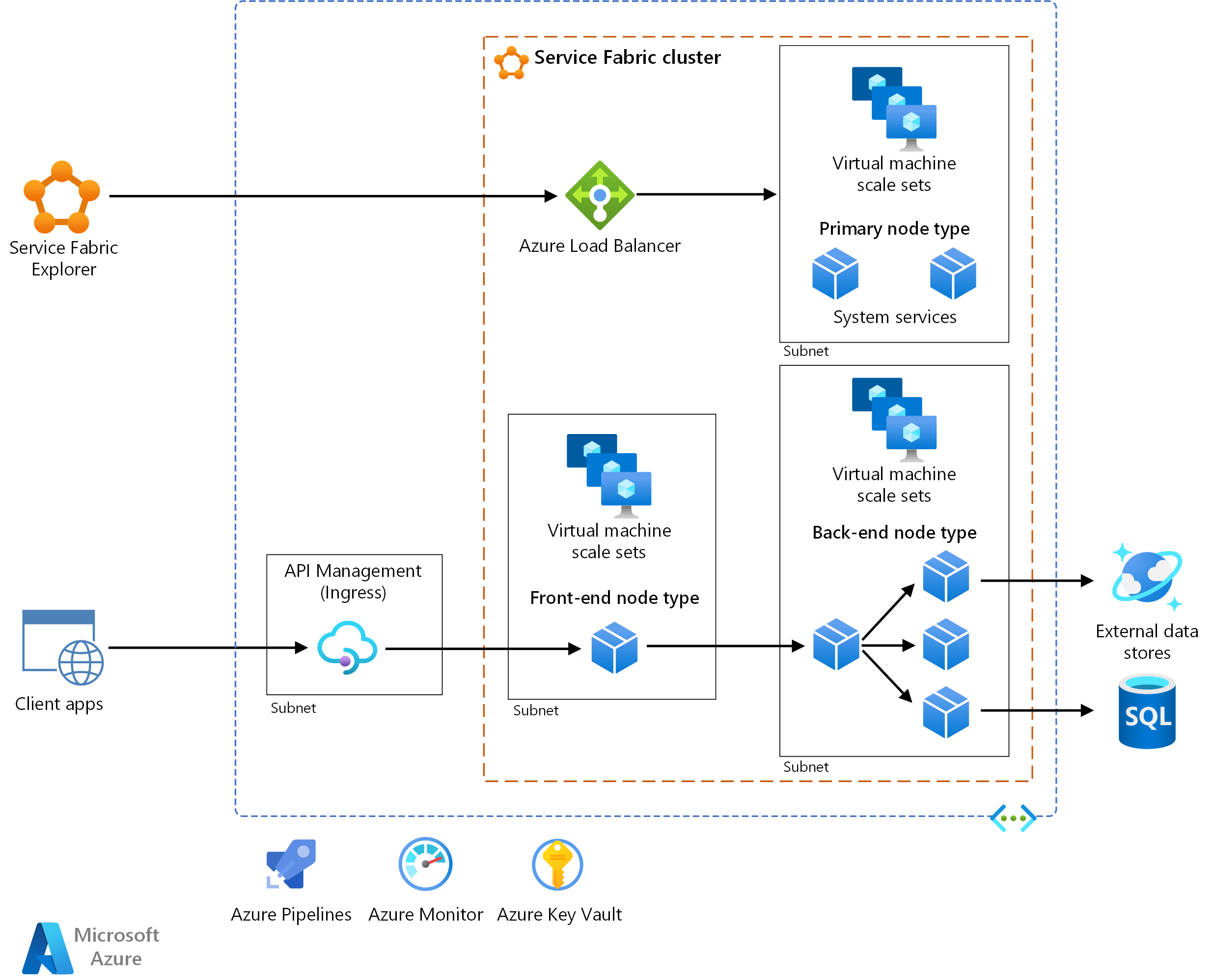
Descargue un archivo Visio de esta arquitectura.
Nota
Este artículo se centra en el modelo de programación de Reliable Services para Service Fabric. El uso de Service Fabric para implementar y administrar contenedores escapa del ámbito de este artículo.
Flujo de trabajo
La arquitectura consta de los siguientes componentes: Para más información sobre otros términos, consulte Información general sobre la terminología de Service Fabric.
Clúster de Service Fabric. Un clúster es un conjunto conectado a la red de máquinas virtuales (VM) en el que se implementan y administran los microservicios.
Conjuntos de escalado de máquinas virtuales. Los conjuntos de escalado de máquinas virtuales permiten crear y administrar un grupo de máquinas virtuales idénticas, con equilibrio de carga y escalado automático. Estos recursos de proceso también proporcionan los dominios de error y actualización.
Nodos. Los nodos son las máquinas virtuales que pertenecen al clúster de Service Fabric.
Tipos de nodo. Un tipo de nodo representa un conjunto de escalado de máquinas virtuales que implementa una colección de nodos. Un clúster de Service Fabric debe tener como mínimo un tipo de nodo.
En un clúster que tenga varios tipos de nodos, uno debe ser declarado como tipo de nodo principal. En el tipo de nodo principal del clúster se ejecutan los servicios del sistema de Service Fabric. Estos servicios proporcionan las funcionalidades de plataforma de Service Fabric. El tipo de nodo principal también funciona como nodo de inicialización. Este tipo de nodos mantiene la disponibilidad del clúster subyacente.
Configure tipos de nodo adicionales para ejecutar los servicios.
Servicios. Un servicio realiza una función independiente que puede iniciarse y ejecutarse con independencia de otros servicios. Se implementan instancias de los servicios en los nodos del clúster. Hay dos clases de servicios en Service Fabric:
- Servicio sin estado. Un servicio sin estado no mantiene el estado dentro del servicio. Si es necesario conservar el estado, este se escribe en un almacén externo y se recupera de él, como es el caso de Azure Cosmos DB.
- Servicio con estado. El estado del servicio se mantiene dentro del propio servicio. La mayoría de los servicios con estado implementan esto a través de Reliable Collections en Service Fabric.
Service Fabric Explorer. Service Fabric Explorer es una herramienta de código abierto para inspeccionar y administrar clústeres de Service Fabric.
Azure Pipelines. Azure Pipelines forma parte de Azure DevOps Services y ejecuta compilaciones, pruebas e implementaciones automatizadas. También puede usar soluciones de integración continua y entrega continua (CI/CD) de terceros, como Jenkins.
Azure Monitor. Azure Monitor recopila y almacena métricas y registros, como las métricas de la plataforma de los servicios de Azure de la solución y los datos de telemetría de la aplicación. Use estos datos para supervisar la aplicación, configurar alertas y paneles y realizar el análisis de causa principal de los errores. Azure Monitor se integra con Service Fabric para recopilar métricas de controladores, nodos y contenedores, junto con registros de contenedores y nodos.
Azure Key Vault Use Key Vault para almacenar cualquier secreto de aplicación que utilicen los microservicios, como las cadenas de conexión.
Azure API Management. En esta arquitectura, API Management funciona como puerta de enlace de API que acepta solicitudes de clientes y las dirige a los servicios.
Consideraciones
Estas consideraciones implementan los pilares de Azure Well-Architected Framework, que es un conjunto de principios rectores para mejorar la calidad de una carga de trabajo.
Consideraciones de diseño
Esta arquitectura de referencia se centra en las arquitecturas de microservicios. Un microservicio es una unidad de código pequeña, independiente y con control de versiones. Es reconocible a través de los mecanismos de detección de servicios y puede comunicarse con otros servicios a través de las API. Los servicios son independientes entre sí y cada uno debe implementar una funcionalidad de negocio individual. Para más información sobre cómo descomponer el dominio de aplicación en microservicios, consulte Uso de análisis de dominios para modelar microservicios.
Service Fabric proporciona una infraestructura para compilar, implementar y actualizar los microservicios de forma eficaz. También proporciona opciones para el escalado automático, administración de estados, supervisión de estados y reinicio de los servicios en caso de error.
Service Fabric sigue un modelo de aplicación en el que una aplicación es una colección de microservicios. La aplicación se describe en un archivo de manifiesto de aplicación. Este archivo define los tipos de servicios que contiene la aplicación, junto con punteros a los paquetes de servicio independientes.
El paquete de la aplicación también suele contener parámetros que sirven para anular determinadas configuraciones que utilizan los servicios. Cada paquete de servicio tiene un archivo de manifiesto que describe los archivos y carpetas físicos necesarios para ejecutar ese servicio, como los archivos binarios, los archivos de configuración y los datos de solo lectura. El control de versiones y actualizaciones de los servicios y aplicaciones se realiza de forma independiente.
De manera opcional, en el manifiesto de aplicación se pueden describir los servicios que se aprovisionan automáticamente cuando se crea una instancia de la aplicación. Estos servicios se conocen como predeterminados. En este caso, el manifiesto de aplicación también describe cómo deben crearse estos servicios. Esa información incluye el nombre del servicio, el recuento de instancias, la directiva de seguridad o aislamiento y las restricciones de selección de ubicación.
Nota
Si quiere controlar la duración de los servicios, evite el uso de servicios predeterminados. Los servicios predeterminados se crean cuando se crea la aplicación y se ejecutan mientras se ejecuta esta.
Para obtener más información, consulte ¿Qué desea saber sobre Service Fabric?.
Modelo de empaquetado de aplicación a servicio
Uno de los principios de los microservicios es que cada servicio puede implementarse de forma independiente. En Service Fabric, si agrupa todos sus servicios en un único paquete de aplicaciones y falla la actualización de un servicio, se anula toda la actualización de la aplicación. Esa reversión impide que se actualice otro servicio.
Por ese motivo, en una arquitectura de microservicios, se recomienda usar varios paquetes de aplicación. Coloque uno o varios tipos de servicio estrechamente relacionados en un único tipo de aplicación. Por ejemplo, coloque los tipos de servicio en el mismo tipo de aplicación si el equipo es responsable de un conjunto de servicios que tienen uno de estos atributos:
- Se ejecutan durante la misma duración y deben actualizarse al mismo tiempo.
- Tienen el mismo ciclo de vida.
- Comparten recursos como dependencias o configuración.
Modelos de programación de Service Fabric
Al agregar un microservicio a una aplicación de Service Fabric, decida si tiene un estado o datos que deban ser confiables y tener una alta disponibilidad. Si es así, ¿se pueden almacenar los datos externamente o se incluyen estos como parte del servicio? Elija un servicio sin estado si no necesita almacenar datos o si quiere almacenarlos en un almacenamiento externo. Considere la posibilidad de elegir un servicio con estado si se aplica una de estas instrucciones:
- Quiere mantener el estado o los datos como parte del servicio. Por ejemplo, necesita que los datos residan en la memoria cerca del código.
- No se puede tolerar una dependencia en un almacén externo.
Si tiene código que quiera ejecutar en Service Fabric, puede ejecutarlo como un ejecutable invitado: un archivo ejecutable arbitrario que se ejecuta como un servicio. Como alternativa, puede empaquetar el archivo ejecutable en un contenedor que tenga todas las dependencias que necesita para la implementación.
Service Fabric modela los contenedores y los archivos ejecutables invitados como servicios sin estado. Para instrucciones sobre cómo elegir un modelo, consulte Información general del modelo de programación de Service Fabric.
Es responsable de mantener el entorno en el que se ejecuta un archivo ejecutable invitado. Por ejemplo, supongamos que un archivo ejecutable invitado necesita Python. Si el archivo ejecutable no es independiente, debe asegurarse de que la versión necesaria de Python esté preinstalada en el entorno. Service Fabric no administra el entorno. Azure ofrece varios mecanismos para configurar el entorno, como imágenes y extensiones de máquina virtual personalizadas.
Para acceder a un archivo ejecutable invitado a través de un proxy inverso, asegúrese de que ha agregado el atributo UriScheme al elemento Endpoint del manifiesto de servicio del archivo ejecutable invitado.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Si el servicio tiene rutas adicionales, especifíquelas en el valor PathSuffix. El valor no debe tener la barra oblicua (/) ni delante ni detrás. Otra manera consiste en agregar la ruta en el nombre del servicio.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Para más información, consulte:
- Empaquetado de una aplicación
- Empaquetado e implementación de un ejecutable existente en Service Fabric
Puerta de enlace de API
Una puerta de enlace de API (entrada) se encuentra entre los clientes externos y los microservicios. Actúa como un proxy inverso, enrutando las solicitudes de los clientes a los microservicios. También podría realizar tareas transversales como la autenticación, la terminación SSL y la limitación de la velocidad.
Recomendamos Azure API Management para la mayoría de los escenarios, pero Traefik es una popular alternativa de código abierto. Ambas opciones de tecnología se integran con Service Fabric.
API Management. Expone una dirección IP pública y dirige el tráfico a sus servicios. Se ejecuta en una subred dedicada de la misma red virtual que el clúster de Service Fabric.
API Management puede acceder a los servicios en un tipo de nodo que se expone a través de un equilibrador de carga con una dirección IP privada. Esta opción solo está disponible en los niveles Premium y Desarrollador de API Management. Utilice el nivel Premium para cargas de trabajo de producción. Puede encontrar información sobre el precio en Precios de API Management.
Para más información, consulte Información general de Service Fabric con Azure API Management.
Traefik Admite características como el enrutamiento, el seguimiento, los registros y las métricas. Traefik se ejecuta como un servicio sin estado en el clúster de Service Fabric. El control de versiones del servicio es posible mediante enrutamiento.
Para obtener más información sobre cómo configurar Traefik para la entrada del servicio y como proxy inverso dentro del clúster, consulte el Proveedor de Azure Service Fabric en el sitio web de Traefik. Para más información sobre el uso de Traefik con Service Fabric, consulte la entrada de blog Enrutamiento inteligente en Service Fabric con Traefik.
Traefik, a diferencia de Azure API Management, no tiene funcionalidad para resolver la partición de un servicio con estado (con más de una partición) al que se enruta una solicitud. Para más información, consulte Adición de un buscador de coincidencias para la creación de particiones de los servicios.
Otras opciones de API Management incluyen Azure Application Gateway y Azure Front Door. Puede utilizar estos servicios junto con API Management para realizar tareas como el enrutamiento, la terminación SSL y el firewall.
Comunicación entre servicios
Para facilitar la comunicación entre servicios, tenga en cuenta las siguientes recomendaciones:
Protocolo de comunicación En una arquitectura de microservicios, los servicios deben comunicarse entre sí con un acoplamiento mínimo en tiempo de ejecución. Para permitir una comunicación independiente del lenguaje, HTTP es un estándar del sector con una amplia variedad de herramientas y servidores HTTP que están disponibles en muchos lenguajes diferentes. Service Fabric admite todas esas herramientas y servidores.
Para la mayoría de las cargas de trabajo, se recomienda usar HTTP en lugar de la comunicación remota del servicio integrada en Service Fabric.
Detección de servicios. Para comunicarse con otros servicios dentro de un clúster, un servicio de cliente debe resolver la ubicación actual del servicio de destino. En Service Fabric, los servicios pueden moverse entre nodos y hacer que los puntos de conexión del servicio cambien dinámicamente.
Para evitar conexiones a puntos de conexión obsoletos, puede usar el servicio de nomenclatura en Service Fabric para recuperar la información actualizada del punto de conexión. Sin embargo, Service Fabric también proporciona un servicio de proxy inverso integrado que abstrae el servicio de nomenclatura. Se recomienda esta opción para la detección de servicios como base de referencia para la mayoría de los escenarios, ya que es más fácil de usar y da como resultado código más sencillo.
Otras opciones para la comunicación entre servicios son:
- Traefik para el enrutamiento avanzado.
- DNS para escenarios de compatibilidad en los que un servicio prevé utilizar DNS.
- La clase ServicePartitionClient<TCommunicationClient>, que almacena en caché los puntos de conexión de servicio. Puede permitir un mejor rendimiento, porque las llamadas pasan directamente entre los servicios sin intermediarios ni protocolos personalizados.
Escalabilidad
Service Fabric admite el escalado de estas entidades de clúster:
- Escalado del número de nodos de cada tipo de nodo.
- Escalado de los servicios
Esta sección se centra en el escalado automático. Puede elegir la reducción horizontal de forma manual cuando sea necesario. Por ejemplo, podría ser necesaria la intervención manual para fijar el número de instancias.
Configuración inicial del clúster para la escalabilidad
Cuando cree un clúster de Service Fabric, aprovisione los tipos de nodo en función de sus necesidades de seguridad y escalabilidad. Cada tipo de nodo se asigna a un conjunto de escalado de máquinas virtuales y se puede escalar de forma independiente.
- Cree un tipo de nodo para cada grupo de servicios que tengan distintos requisitos de escalabilidad o de recursos. Comience por el aprovisionamiento de un tipo de nodo (que se convierte en el tipo de nodo principal) para los servicios del sistema de Service Fabric. Cree tipos de nodo independientes para ejecutar los servicios públicos o front-end. Cree otros tipos de nodo según sea necesario para el back-end y los servicios privados o aislados. Especifique restricciones de selección de ubicación para que los servicios se implementen solo en los tipos de nodo previstos.
- Especifique el nivel de durabilidad de cada tipo de nodo. El nivel de durabilidad representa la capacidad de Service Fabric para influir en las actualizaciones y las operaciones de mantenimiento en los conjuntos de escalado de máquinas virtuales. Para las cargas de trabajo de producción, elija un nivel de durabilidad Silver o superior. Para más información, consulte Características de durabilidad del clúster.
- Si usa el nivel de durabilidad Bronze, algunas operaciones requieren pasos manuales. Los tipos de nodo con el nivel de durabilidad Bronze requieren pasos adicionales durante el escalado. Para más información sobre las operaciones de escalado, consulte esta guía.
Escalado de los nodos
Service Fabric admite el escalado automático en la reducción y la escalabilidad horizontales entrante y saliente. Puede configurar cada tipo de nodo para el escalado automático de forma independiente.
Cada clúster puede tener hasta 100 nodos. Comience con un conjunto más pequeño de nodos y vaya agregando más en función de la carga. Si necesita más de 100 nodos en un tipo de nodo, tendrá que agregar más tipos de nodo. Para más información, consulte Consideraciones de planeamiento de la capacidad del clúster de Service Fabric. Un conjunto de escalado de máquinas virtuales no se escala de forma instantánea, por lo que debe tener en cuenta ese factor al configurar las reglas de escalado automático.
Para admitir el escalado automático, configure el tipo de nodo para que tenga el nivel de durabilidad Silver o Gold. Esta configuración garantiza que el escalado se retrase hasta que Service Fabric finalice la reubicación de los servicios. También se asegura de que los conjuntos de escalado de máquinas virtuales informen a Service Fabric de que las máquinas virtuales se han retirado, y no solo de que están inactivas temporalmente.
Para más información sobre el escalado en el nivel de nodo o clúster, consulte Escalado de clústeres de Azure Service Fabric.
Escalado de los servicios
Los servicios sin estado y con estado aplican enfoques diferentes sobre el escalado.
Para un servicio sin estado (escalado automático):
- Use el desencadenador de cargas de particiones medias. Este desencadenador determina el momento en el que el servicio se escala o se reduce horizontalmente, en función del umbral de carga que se especifica en la directiva de escalado. También puede establecer la frecuencia con que se comprueba el desencadenador. Consulte Desencadenador de carga de partición media con escalado basado en instancias. Este enfoque le permite escalar hasta el número de nodos disponibles.
- Establezca
InstanceCounten -1 en el manifiesto de servicio, que indica a Service Fabric que ejecute una instancia del servicio en cada nodo. Este enfoque permite escalar el servicio dinámicamente a medida que se escala el clúster. Cuando el número de nodos del clúster cambia, Service Fabric crea y elimina automáticamente las instancias de servicio para ajustarlas al cambio.
Nota
En algunos casos, podría escalar el servicio manualmente. Por ejemplo, si tiene un servicio que lee de Azure Event Hubs, es posible que desee una instancia dedicada para leer de cada partición del centro de eventos. De este modo, puede evitar el acceso simultáneo a la partición.
Para un servicio con estado, el escalado está controlado por el número de particiones, el tamaño de cada partición y el número de particiones o réplicas que se ejecutan en una máquina:
Si va a crear servicios con particiones, asegúrese de que cada nodo obtenga las réplicas adecuadas para la distribución uniforme de la carga de trabajo sin provocar contenciones de recursos. Si agrega más nodos, Service Fabric distribuye las cargas de trabajo en las nuevas máquinas de forma predeterminada. Por ejemplo, si hay 5 nodos y 10 particiones, Service Fabric colocará dos réplicas principales en cada nodo de forma predeterminada. Si escala horizontalmente los nodos, puede lograr un mejor rendimiento, ya que el trabajo se distribuye uniformemente entre más recursos.
Para información sobre los escenarios que aprovechan esta estrategia, consulte Reducción horizontal en Service Fabric.
No se admite la adición o eliminación de particiones. Otra opción que se suele usar para escalar es crear o eliminar de forma dinámica servicios o instancias de aplicación completas. Un ejemplo de este patrón se describe en Escalado mediante la creación o eliminación de nuevos servicios con nombre.
Para más información, consulte:
- Escalado o reducción horizontal de un clúster de Service Fabric mediante reglas de escalado automático o manualmente
- Escalado mediante programación de un clúster de Service Fabric
- Escalar horizontalmente un clúster de Service Fabric añadiendo un conjunto de escalado de máquinas virtuales
Uso de métricas para equilibrar la carga
En función de cómo diseñe la partición, es posible que tenga nodos con réplicas que reciban más tráfico que otros. Para evitar esta situación, particione el estado del servicio para que se distribuya entre todas las particiones. Use el esquema de creación de particiones de intervalo con un buen algoritmo hash. Consulte Introducción a la creación de particiones.
Service Fabric usa métricas para saber cómo colocar y equilibrar los servicios dentro de un clúster. Puede especificar una carga predeterminada para cada métrica asociada a un servicio cuando se crea dicho servicio. Service Fabric tiene en cuenta entonces esa carga al colocar el servicio, o cada vez que el servicio debe moverse (por ejemplo, durante las actualizaciones) para equilibrar los nodos del clúster.
La carga predeterminada especificada inicialmente para un servicio no cambiará durante la vigencia del servicio. Para capturar las métricas variables de un servicio, se recomienda supervisar el servicio y, luego, notificar la carga dinámicamente. Este enfoque permite a Service Fabric ajustar la asignación en función de la carga comunicada en un momento dado. Use el método IServicePartition.ReportLoad para notificar las métricas personalizadas. Para más información, consulte Carga dinámica.
Disponibilidad
Coloque los servicios en un tipo de nodo distinto del tipo de nodo principal. Los servicios del sistema de Service Fabric se implementan siempre en el tipo de nodo principal. Si sus servicios se implementan en el tipo de nodo primario, podrían competir (e interferir) con los servicios del sistema por los recursos. Si un tipo de nodo va a hospedar servicios con estado, asegúrese de que haya al menos cinco instancias de nodo y seleccione el nivel de durabilidad Silver o Gold.
Considere la posibilidad de restringir los recursos de los servicios. Consulte Mecanismo de gobernanza de recursos.
Estas son las consideraciones comunes:
- No mezcle servicios que se rigen por recursos y que no se rigen por recursos en el mismo tipo de nodo. Los servicios no regulados podrían consumir demasiados recursos y afectar a los servicios regulados. Especifique restricciones de selección de ubicación para que esos tipos de servicios no se ejecuten en el mismo conjunto de nodos. (Este es un ejemplo del patrón Bulkhead).
- Especifique los núcleos de CPU y la memoria que se reservará para una instancia de servicio. Para información sobre el uso y las limitaciones de las directivas de gobernanza de recursos, consulte Gobernanza de recursos.
Para evitar un único punto de error (SPOF), asegúrese de que la instancia de destino o el recuento de réplicas de cada servicio es mayor que uno. El mayor número que puede utilizar como instancia de servicio o recuento de réplicas es igual al número de nodos que limitan el servicio.
Asegúrese de que todos los servicios con estado tengan al menos dos réplicas secundarias activas. Se recomiendan cinco réplicas para cargas de trabajo de producción.
Para más información, consulte Disponibilidad de los servicios de Service Fabric.
Seguridad
La seguridad proporciona garantías contra ataques deliberados y el abuso de datos y sistemas valiosos. Para más información, consulte Introducción al pilar de seguridad.
Estos son algunos puntos clave que se deben tener en cuenta para proteger la aplicación en Service Fabric.
Virtual network
Considere la posibilidad de definir límites de subred para cada conjunto de escalado de máquinas virtuales con el fin de controlar el flujo de comunicación. Cada tipo de nodo tiene su propio conjunto de escalado de máquinas virtuales en una subred dentro de la red virtual del clúster de Service Fabric. Puede agregar grupos de seguridad de red (NSG) a las subredes para permitir o rechazar el tráfico de red. Por ejemplo, con los tipos de nodo front-end y back-end, puede agregar un grupo de seguridad de red a la subred de back-end para aceptar solo el tráfico entrante de la subred de front-end.
Al llamar a servicios de Azure externos desde el clúster, use puntos de conexión de servicio de red virtual si el servicio de Azure los admite. El uso de un punto de conexión de servicio protege el servicio solo en la red virtual del clúster.
Por ejemplo, si usa Azure Cosmos DB para almacenar datos, configure la cuenta de Azure Cosmos DB con un punto de conexión de servicio para permitir el acceso solo desde una subred específica. Consulte Acceso a los recursos de Azure Cosmos DB desde redes virtuales.
Puntos de conexión y comunicación entre servicios
No cree un clúster de Service Fabric desprotegido. Si el clúster expone puntos de conexión de administración a la red pública de Internet, podrían conectarse a él usuarios anónimos. Los clústeres sin protección no se admiten para cargas de trabajo de producción. Consulte Escenarios de seguridad de los clústeres de Service Fabric.
Para ayudar a proteger las comunicaciones entre servicios:
- Podría habilitar puntos de conexión HTTPS en los servicios web ASP.NET Core o Java.
- Establezca una conexión segura entre el proxy inverso y los servicios. Para más información, consulte Conexión a un servicio seguro.
Si va a usar una instancia de API Gateway, puede descargar la autenticación en la puerta de enlace. Asegúrese de que no se pueda llegar directamente a los servicios individuales (sin la puerta de enlace de API) a menos que se implemente seguridad adicional para autenticar.
No exponga públicamente el proxy inverso de Service Fabric. Hacerlo provoca que todos los servicios que exponen puntos de conexión HTTP sean direccionables desde fuera del clúster. Esto introducirá vulnerabilidades de seguridad y potencialmente expondrá información adicional fuera del clúster innecesariamente. Si quiere acceder a un servicio públicamente, use una puerta de enlace de API. La sección Puerta de enlace de API más adelante en este artículo menciona algunas opciones.
El Escritorio remoto es útil para el diagnóstico y la solución de problemas, pero asegúrese de cerrarlo. Dejarlo abierto provoca una vulnerabilidad de seguridad.
Secretos y certificados
Almacene secretos, como cadenas de conexión a almacenes de datos, en un almacén de claves. La instancia de Key Vault debe estar en la misma región que el conjunto de escalado de máquinas virtuales. Para usar un almacén de claves:
Autenticar el acceso del servicio a Key Vault.
Habilitar la identidad administrada en el conjunto de escalado de máquinas virtuales que hospeda el servicio.
Almacenar los secretos en Key Vault.
Agregar secretos en un formato que se pueda traducir a un par clave-valor. Por ejemplo, use
CosmosDB--AuthKey. Cuando se compila la configuración, el guión doble (--) se convierte en un punto (:).Acceder a esos secretos en el servicio.
Agregue el URI del almacén de claves en el archivo appSettings.json. En el servicio, agregue el proveedor de configuración que realiza lecturas en Key Vault, compila la configuración y accede al secreto desde la configuración compilada.
Este es un ejemplo en el que el servicio Workflow almacena un secreto en Key Vault con el formato CosmosDB--Database.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Para acceder al secreto, especifique el nombre del secreto en la configuración de compilación.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
No use certificados de cliente para acceder a Service Fabric Explorer. En su lugar, use el identificador de Entra de Microsoft. Consultar Servicios de Azure que admiten la autenticación de Microsoft Entra.
No utilice un certificado autofirmado en un entorno de producción.
Protección de datos en reposo
Si asoció discos de datos a los conjuntos de escalado de máquinas virtuales del clúster de Service Fabric y los servicios guardan los datos en esos discos, debe cifrar los discos. Para más información, consulte Cifrado de discos de datos conectados y de sistema operativo en un conjunto de escalado de máquinas virtuales con Azure PowerShell (versión preliminar).
Para más información sobre la protección de Service Fabric, consulte:
- Introducción a la seguridad de Azure Service Fabric
- Procedimientos recomendados de seguridad de Azure Service Fabric
- Lista de comprobación de seguridad de Azure Service Fabric
Resistencia
Para recuperarse de los errores y mantener un estado totalmente funcional, la aplicación debe implementar determinados patrones de resistencia. Estos son algunos patrones habituales:
- Reintento: para controlar los errores que espera que sean transitorios, como los recursos que no están disponibles temporalmente.
- Disyuntor: para solucionar los errores que podrían tardar más tiempo en solucionarse.
- Compartimentado: para aislar los recursos de cada servicio.
Esta implementación de referencia utiliza Polly, una opción de código abierto, para implementar todos esos patrones.
Supervisión
Antes de explorar las opciones de supervisión, se recomienda leer este artículo sobre el diagnóstico de escenarios comunes con Service Fabric. Puede considerar supervisar los datos de estos conjuntos:
- Métricas y registros de aplicaciones
- Datos de estado y eventos de Service Fabric
- Métricas y registros de infraestructura
- Métricas y registros de servicios dependientes
Estas son las dos opciones principales para analizar esos datos:
- Application Insights
- Log Analytics
Puede usar Azure Monitor para configurar paneles de supervisión y para enviar alertas a los operadores. Algunas herramientas de supervisión de terceros también están integradas con Service Fabric, como Dynatrace. Para más información, consulte Asociados de supervisión de Azure Service Fabric.
Métricas y registros de aplicaciones
La telemetría de las aplicaciones proporciona datos que pueden ayudarle a controlar la salud de su servicio y a identificar problemas. Para agregar seguimientos y eventos en el servicio:
- Use Microsoft.Extensions.Logging si va a desarrollar el servicio con ASP.NET Core. En el caso de otros marcos, use la biblioteca de registro que prefiera, por ejemplo, Serilog.
- Agregue su propia instrumentación mediante la clase TelemetryClient del SDK y ver los datos en Application Insights. Consulte Agregar instrumentación personalizada a la aplicación.
- Registre eventos de Seguimiento de eventos para Windows (ETW) mediante EventSource. Esta opción está disponible de forma predeterminada en una solución de Service Fabric para Visual Studio.
Application Insights proporciona una gran cantidad de información de telemetría integrada: solicitudes, seguimientos, eventos, excepciones, métricas y dependencias. Si el servicio expone puntos de conexión HTTP, habilite Application Insights llamando al método de extensión UseApplicationInsights para Microsoft.AspNetCore.Hosting.IWebHostBuilder. Para información sobre cómo instrumentar el servicio para Application Insights, consulte estos artículos:
- Tutorial: Supervisión y diagnóstico de una aplicación de ASP.NET Core de Service Fabric mediante Application Insights
- Application Insights para ASP.NET Core
- SDK de .NET de Application Insights
- SDK de Application Insights para Service Fabric
Para ver los seguimientos y los registros de eventos, use Application Insights como uno de los receptores de registro estructurado. Configure Application Insights con la clave de instrumentación llamando al método de extensión AddApplicationInsights. En este ejemplo, la clave de instrumentación se almacena como un secreto en Key Vault.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Si el servicio no expone puntos de conexión HTTP, debe escribir una extensión personalizada que envíe seguimientos a Application Insights. Para ver un ejemplo, consulte el servicio Workflow en la implementación de referencia.
Los servicios de ASP.NET Core usan la interfaz ILogger para el registro de aplicaciones. Para que estos registros de aplicaciones estén disponibles en Azure Monitor, envíe los eventos ILogger a Application Insights. Application Insights puede agregar propiedades de correlación a eventos ILogger, lo que resulta de utilidad para visualizar el seguimiento distribuido.
Para más información, consulte:
Datos de estado y eventos de Service Fabric
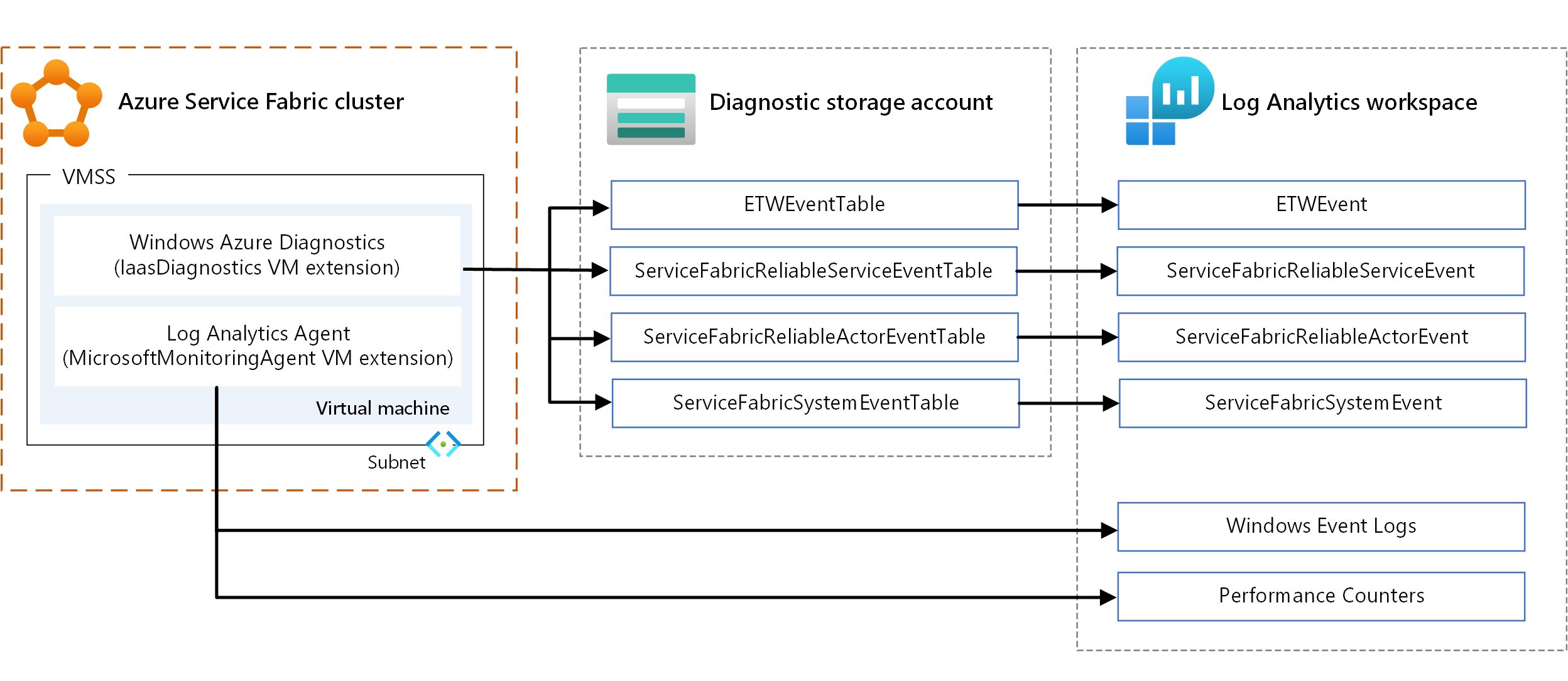
La telemetría de Service Fabric incluye métricas de estado y eventos sobre el funcionamiento y el rendimiento de un clúster de Service Fabric y de sus entidades: sus nodos, aplicaciones, servicios, particiones y réplicas. Los datos de mantenimiento y eventos pueden proceder de:
EventStore. Este servicio de sistema con estado recopila los eventos relacionados con el clúster y sus entidades. Service Fabric utiliza EventStore para escribir eventos de Service Fabric con el fin de proporcionar información sobre su clúster para las actualizaciones de estado, la solución de problemas y la supervisión. EventStore también puede correlacionar eventos de diferentes entidades en un momento dado para identificar problemas en el clúster. El servicio expone esos eventos mediante una API REST.
Para más información sobre cómo consultar las API de EventStore, vea Consulta de las API del servicio EventStore para obtener eventos de clúster. Puede ver los eventos de EventStore en Log Analytics mediante la configuración del clúster con la extensión Azure Diagnostics para Windows (WAD).
HealthStore. Este servicio con estado proporciona una instantánea del estado actual del clúster. Agrega todos los datos de mantenimiento indicados por las entidades de una jerarquía. Los datos se visualizan en Service Fabric Explorer. HealthStore también supervisa las actualizaciones de la aplicación. Puede usar las consultas de estado en PowerShell, las aplicaciones .NET o las API REST. Consulte Introducción a la supervisión del mantenimiento de Service Fabric.
Informes de mantenimiento personalizados. Considere la posibilidad de implementar servicios de vigilancia internos que puedan informar periódicamente de datos de mantenimiento personalizados, como estados defectuosos de los servicios en ejecución. Puede leer los informes de mantenimiento en Service Fabric Explorer.
Métricas y registros de infraestructura
Las métricas de infraestructura le ayudan a comprender la asignación de recursos en el clúster. A continuación, se indican las opciones principales para recopilar esta información:
- WAD. Recopile los registros y las métricas en el nivel de nodo en Windows. Puede utilizar WAD configurando la extensión IaaSDiagnostics VM en cualquier conjunto de escalas de máquinas virtuales que esté asignado a un tipo de nodo para recopilar eventos de diagnóstico. Estos eventos pueden incluir registros de eventos de Windows, contadores de rendimiento, eventos operativos y del sistema ETW/manifiesto, y registros personalizados.
- Agente de Log Analytics. Configure la extensión de máquina virtual MicrosoftMonitoringAgent para enviar registros de eventos de Windows, contadores de rendimiento y registros personalizados a Log Analytics.
Hay cierta superposición en el tipo de métricas recopiladas mediante los mecanismos anteriores, como es el caso de los contadores de rendimiento. Cuando esto suceda, se recomienda usar el agente de Log Analytics. Dado que el agente de Log Analytics no usa Azure Storage, la latencia es baja. Además, los contadores de rendimiento de IaaSDiagnostics no se pueden introducir fácilmente en Log Analytics.
Para información sobre las extensiones de máquina virtual, consulte Características y extensiones de las máquinas virtuales de Azure.
Para ver los datos, configure Log Analytics para que muestre los datos recopilados a través de WAD. Para información sobre cómo configurar Log Analytics para leer eventos de una cuenta de almacenamiento, consulte Configuración de Log Analytics para un clúster.
También puede ver los registros de rendimiento y los datos de telemetría relacionados con un clúster de Service Fabric, las cargas de trabajo, el tráfico de red, las actualizaciones pendientes y mucho más. Consulte Supervisión del rendimiento con Log Analytics.
En Uso de la solución Service Map en Azure se proporciona información sobre la topología del clúster (es decir, los procesos que se ejecutan en cada nodo). Envíe los datos de la cuenta de almacenamiento a Application Insights. Puede que haya algún retraso en la introducción de datos en Application Insights. Si quiere ver los datos en tiempo real, considere la posibilidad de configurar Event Hubs mediante receptores y canales. Para más información, consulte Recopilación y agregación de eventos con WAD.
Métricas de servicios dependientes
- Application Map en Application Insights proporciona la topología de la aplicación mediante llamadas de dependencia HTTP realizadas entre servicios, con el SDK de Application Insights instalado.
- Service Map en Log Analytics proporciona información sobre el tráfico entrante y saliente desde y hacia servicios externos. Service Map se integra con otras soluciones, por ejemplo, de actualizaciones o seguridad.
- Los guardianes personalizados pueden notificar condiciones de error en servicios externos. Por ejemplo, el servicio puede proporcionar un informe de estado de error si no puede acceder a un servicio externo o a un almacenamiento de datos (Azure Cosmos DB).
Seguimiento distribuido
En la arquitectura de microservicios, varios servicios suelen participar en la realización de una tarea. La telemetría de cada uno de esos servicios se correlaciona a través de campos de contexto (como el ID de operación y el ID de solicitud) en un seguimiento distribuido.
Mediante el Mapa de aplicación de Application Insights, puede compilar la vista de una operación lógica distribuida y visualizar todo el grafo de servicios de la aplicación. También puede usar el diagnóstico de transacciones de Application Insights para correlacionar la telemetría del lado servidor. Para más información, consulte Diagnósticos de transacción entre componentes unificados.
También es importante correlacionar las tareas que se envían de forma asincrónica mediante una cola. Para más información sobre cómo enviar telemetría de correlación en un mensaje de cola, consulte Instrumentación de colas.
Para más información, consulte:
Alertas y paneles
Application Insights y Log Analytics admiten un lenguaje de consulta extenso (lenguaje de consulta Kusto) que permite recuperar y analizar los datos de registro. Use las consultas para crear conjuntos de datos y visualizarlos en los paneles de diagnóstico.
Utilice las alertas de Azure Monitor para informar a los administradores del sistema cuando se produzcan determinadas condiciones en recursos concretos. La notificación podría ser un correo electrónico, una función de Azure o un webhook, por ejemplo. Para más información, consulte Alertas en Azure Monitor.
Las reglas de alertas de búsqueda de registros permiten definir y ejecutar una consulta de Kusto en un área de trabajo de Log Analytics a intervalos regulares. Se crea una alerta si el resultado de la consulta coincide con una condición determinada.
Optimización de costos
Puede usar la calculadora de precios de Azure para calcular los costos. Otras consideraciones se describen en el pilar optimización de costes del Marco de buena arquitectura de Microsoft Azure.
Estos son algunos puntos que se deben tener en cuenta para algunos de los servicios que se usan en esta arquitectura.
Azure Service Fabric
Se le cobra por las instancias de proceso, el almacenamiento, los recursos de red y las direcciones IP que elija al crear un clúster de Service Fabric. La implementación de Service Fabric conlleva unos cargos.
Conjuntos de escalado de máquinas virtuales
En esta arquitectura, los microservicios se implementan en nodos que son conjuntos de escalado de máquinas virtuales. Se le cobra por las máquinas virtuales de Azure que implemente como parte del clúster y por los recursos de infraestructura subyacente, como el almacenamiento y las redes. No hay cargos incrementales por los conjuntos de escalado de máquinas virtuales en sí.
Azure API Management
Azure API Management es una puerta de enlace para enrutar las solicitudes desde los clientes hasta los servicios del clúster.
Hay varias opciones de precios. La opción Consumo se factura según el modelo de pago por uso e incluye un componente de puerta de enlace. En función de la carga de trabajo, elija una de las opciones descritas en Precios de API Management.
Application Insights
Puede utilizar Application Insights para recopilar telemetría de todos los servicios y ver los seguimientos y los registros de eventos de manera estructurada. El precio de Application Insights es un modelo de pago por uso que se basa en el volumen de datos ingeridos y las opciones de retención de datos. Para más información, consulte Administración del uso y los costos de Application Insights.
Azure Monitor
Por Log Analytics de Azure Monitor, se le cobra por la ingesta y la retención de datos. Para obtener más información, consulte Precios de Azure Monitor.
Azure Key Vault
Use Azure Key Vault para almacenar la clave de instrumentación de Application Insights como secreto. Azure ofrece Key Vault en dos niveles de servicio. Si no necesita claves protegidas HSM, elija el nivel Estándar. Para información sobre las características de cada nivel, consulte Precios de Key Vault.
Azure DevOps Services
Esta arquitectura de referencia usa Azure Pipelines para la implementación. El servicio Azure Pipelines permite un trabajo gratuito hospedado en Microsoft con 1.800 minutos al mes para CI/CD y un trabajo autohospedado con minutos ilimitados al mes. Los trabajos adicionales tienen cargos. Para más información, consulte Precios de Azure DevOps Services.
Para saber los aspectos que hay que tener en cuenta sobre DevOps en una arquitectura de microservicios, consulte CI/CD para microservicios.
Para aprender a implementar una aplicación de contenedor con CI/CD en un clúster de Service Fabric, consulte este tutorial.
Implementación de este escenario
Para implementar la solución de referencia de esta arquitectura, siga los pasos del repositorio de GitHub.
Pasos siguientes
- Curso: Introducción a Azure Service Fabric
- Información general de Azure Service Fabric
- Documentación de API Management
- ¿Qué es Azure Pipelines?