Alta disponibilidad para Azure SQL Database
Se aplica a:![]() Azure SQL Database
Azure SQL Database
En este artículo se describe la arquitectura de alta disponibilidad en Azure SQL Database.
Información general
El objetivo de la arquitectura de alta disponibilidad en Azure SQL Database es minimizar el impacto en las cargas de trabajo de los clientes de las operaciones de mantenimiento del servicio y las interrupciones. Para obtener información sobre acuerdos de nivel de servicio específicos para distintos niveles de servicio, consulte Acuerdo de Nivel de Servicio para Azure SQL Database.
SQL Database se ejecuta en la versión estable más reciente del motor de base de datos de SQL Server en el sistema operativo Windows con todas las revisiones aplicables. SQL Database controla automáticamente las tareas de mantenimiento críticas, como la aplicación de revisiones, copias de seguridad, actualizaciones del motor de Windows y SQL, y eventos no planeados, como los errores subyacentes de hardware, software o red. Cuando se conmute por error una base de datos o grupo elástico en Azure SQL Database o se le apliquen revisiones, no se notará el tiempo de inactividad si usa la lógica de reintento en su aplicación. SQL Database puede recuperarse rápidamente, incluso en las circunstancias más críticas, asegurando que los datos estén siempre disponibles. La mayoría de los usuarios no observan que las actualizaciones se realizan continuamente.
La solución de alta disponibilidad está diseñada para garantizar que los datos confirmados nunca se pierden debido a errores, que las operaciones de mantenimiento no afectan a la carga de trabajo y que la base de datos no será un único punto de error en la arquitectura de software.
Hay tres modelos arquitectónicos de alta disponibilidad:
- El modelo de almacenamiento remoto que se basa en la separación del proceso y el almacenamiento. Depende de la alta disponibilidad y la confiabilidad de la capa de almacenamiento remoto. Esta arquitectura va dirigida a las aplicaciones de negocio preocupadas por la economía que pueden permitirse una cierta degradación del rendimiento durante las actividades de mantenimiento.
- El modelo de almacenamiento local que se basa en un clúster de procesos del motor de base de datos. Depende del hecho de que siempre hay un quórum de nodos del motor de base de datos disponibles. Esta arquitectura va dirigida a aplicaciones críticas con alto rendimiento de E/S y elevada tasa de transacciones, y garantiza un impacto mínimo sobre el rendimiento de la carga de trabajo durante las actividades de mantenimiento.
- Modelo de hiperescala que usa un sistema distribuido de componentes de alta disponibilidad, como nodos de proceso, servidores de páginas, servicio de registro y almacenamiento persistente. Cada componente que admite una base de datos de Hiperescala proporciona su propia redundancia y resistencia a errores. Los nodos de proceso, los servidores de página y el servicio de registro se ejecutan en Azure Service Fabric, que controla el estado de cada componente y realiza conmutaciones por error en los nodos correctos disponibles según sea necesario. El almacenamiento persistente usa Azure Storage con sus funcionalidades nativas de alta disponibilidad y redundancia. Para más información, consulte Arquitectura de Hiperescala.
Dentro de cada uno de los tres modelos de disponibilidad, SQL Database admite opciones de redundancia local y redundancia zonal. La redundancia local proporciona resistencia en un centro de datos, mientras que la redundancia zonal mejora aún más la resistencia al protegerse frente a interrupciones de una zona de disponibilidad dentro de una región.
En la tabla siguiente se muestran las opciones de disponibilidad basadas en los niveles de servicio:
| Nivel de servicio | Modelo de alta disponibilidad | disponibilidad con redundancia local | Disponibilidad con redundancia de zona |
|---|---|---|---|
| Uso general (núcleo virtual) | Almacenamiento remoto | Sí | Sí |
| Crítico para la empresa (núcleo virtual) | Almacenamiento local | Sí | Sí |
| Hiperescala (núcleo virtual) | Hiperescala | Sí | Sí |
| Básico (DTU) | Almacenamiento remoto | Sí | No |
| Estándar (DTU) | Almacenamiento remoto | Sí | No |
| Premium (DTU) | Almacenamiento local | Sí | Sí |
Disponibilidad con redundancia local
La disponibilidad con redundancia local se basa en almacenar la base de datos en el almacenamiento con redundancia local (LRS), que copia los datos tres veces dentro de un único centro de datos de la región primaria y protege los datos en caso de error local, como una red a pequeña escala o un error de alimentación. LRS es la opción de redundancia de costo más bajo y ofrece la menor durabilidad en comparación con otras opciones. Si se produce un desastre a gran escala como un incendio o una inundación en una región, es posible que todas las réplicas de una cuenta de almacenamiento con LRS se pierdan o no se puedan recuperar. Por lo tanto, para proteger aún más los datos al usar la opción de disponibilidad con redundancia local, considere la posibilidad de usar una opción de almacenamiento más resistente para las copias de seguridad de la base de datos. Esto no se aplica a las bases de datos de Hiperescala, donde se usa el mismo almacenamiento para los archivos de datos y las copias de seguridad.
La disponibilidad con redundancia local está disponible para todas las bases de datos de todos los niveles de servicio y el objetivo de punto de recuperación (RPO), lo que indica que la cantidad de pérdida de datos es cero.
Niveles de servicio Básico, Estándar y De uso general
Los niveles de servicio Básico, Estándar y De uso general utilizan el modelo de disponibilidad de almacenamiento remoto para los procesos aprovisionados y sin servidor. En la siguiente ilustración se muestran cuatro nodos diferentes con las capas de proceso y almacenamiento separadas.
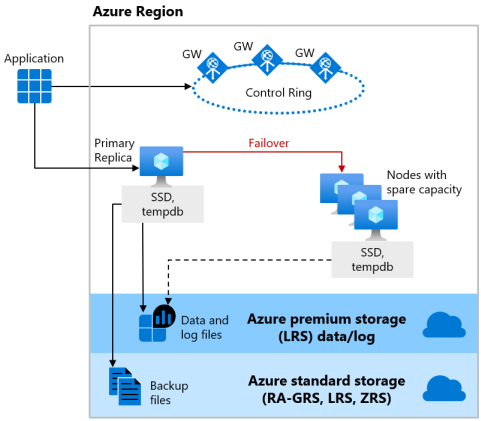
El modelo de disponibilidad de almacenamiento remoto incluye dos capas:
- Una capa de proceso sin estado que ejecuta el proceso de motor de base de datos y que solo contiene datos transitorios y almacenados en caché, como las bases de datos
tempdbymodelen la memoria SSD conectada, y la memoria caché de planes, el grupo de búferes y el grupo de almacén de columnas en la memoria. Azure Service Fabric controla este nodo sin estado, que inicializa el motor de base de datos, controla el estado del nodo y realiza la conmutación por error a otro nodo si es necesario. - Una capa de datos con estado con archivos de base de datos (
.mdfo.ldf) que se almacenan en Azure Blob Storage. Azure Blob Storage presenta características integradas de redundancia y disponibilidad de los datos. Garantiza que todos los registros del archivo de registro o de la página del archivo de datos se conservarán aunque se bloquee el proceso de motor de base de datos.
Siempre que se actualice el motor de base de datos o el sistema operativo, o se detecte un error, Azure Service Fabric moverá el proceso sin estado de motor de base de datos a otro nodo de proceso sin estado con capacidad suficiente disponible. Los datos de Azure Blob Storage no se ven afectados por esta operación y los archivos de registro o de datos se asocian al proceso de motor de base de datos recién inicializado. Aunque este proceso garantiza una alta disponibilidad, una carga de trabajo pesada podría experimentar una degradación del rendimiento durante la transición dado que el nuevo proceso de motor de proceso se inicia con la caché inactiva.
Nivel de servicio Premium y Crítico para la empresa
Los niveles de servicio Premium y Crítico para la empresa aprovechan el modelo de disponibilidad de almacenamiento local, que integra recursos de proceso (proceso del motor de base de datos) y almacenamiento (SSD conectado localmente) en un único nodo. Para conseguir alta disponibilidad se replica el proceso y el almacenamiento en nodos adicionales.
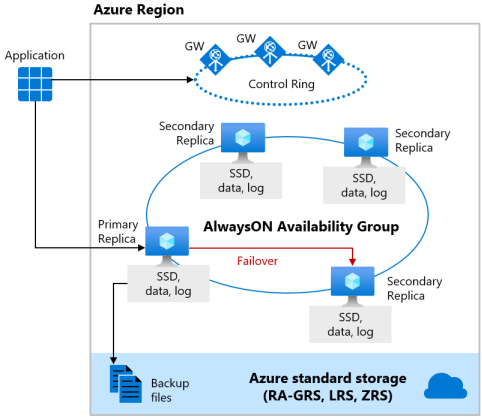
Los archivos de base de datos subyacentes (.mdf o .ldf) se colocan en el almacenamiento SSD conectado para proporcionar una latencia muy baja de E/S para la carga de trabajo. Para implementar alta disponibilidad se usa una tecnología parecida a la de los grupos de disponibilidad AlwaysOn de SQL Server. El clúster incluye una única réplica principal que es accesible para las cargas de trabajo de cliente de lectura y escritura, y hasta tres réplicas secundarias (proceso y almacenamiento) que contienen copias de los datos. La réplica principal inserta constantemente los cambios en las réplicas secundarias en orden y garantiza que los datos se conservan en un número suficiente de réplicas secundarias antes de confirmar cada transacción. Este proceso garantiza que si la réplica principal o una réplica secundaria legible se bloquea por cualquier motivo, siempre hay una réplica totalmente sincronizada al que conmutar por error. La conmutación por error se inicia en Azure Service Fabric. Una vez que una réplica secundaria se convierte en la nueva réplica principal, se crea otra réplica secundaria para asegurarse de que el clúster tiene un número suficiente de réplicas para mantener el cuórum. Una vez completada una conmutación por error, las conexiones de Azure SQL se redirigen automáticamente a la nueva réplica principal o a la réplica secundaria legible.
Como ventaja adicional, el modelo de disponibilidad de almacenamiento local incluye la posibilidad de redirigir las conexiones de Azure SQL de solo lectura a una de las réplicas secundarias. Esta característica se denomina escalado horizontal de lectura y proporciona el 100 % de capacidad de proceso adicional al mismo costo para descargar operaciones de solo lectura, como cargas de trabajo de análisis, desde la réplica principal.
Nivel de servicio Hiperescala
La arquitectura del nivel de servicio Hiperescala se describe en Arquitectura de funciones distribuidas.

El modelo de disponibilidad de Hiperescala incluye cuatro capas:
- Una capa de proceso sin estado que ejecuta los procesos de motor de base de datos y que solo contiene datos transitorios y almacenados en caché, como la memoria caché RBPEX sin cobertura,
tempdbymodel, etc. en la memoria SSD conectada, la memoria caché de planes, el grupo de búferes y el grupo de almacén de columnas en memoria. Esta capa sin estado incluye la réplica de proceso principal y, opcionalmente, un número de réplicas de proceso secundarias que pueden servir como destinos de conmutación por error. - Una capa de almacenamiento sin estado formada por servidores de páginas. Esta capa es el motor de almacenamiento distribuido para los procesos de motor de base de datos que se ejecutan en las réplicas de proceso. Cada servidor de páginas solo contiene datos transitorios y almacenados en caché, como la memoria caché de RBPEX de cobertura en la SSD conectada y las páginas de datos almacenadas en memoria caché. Cada servidor de páginas tiene un servidor de páginas emparejadas en una configuración activa-activa para proporcionar equilibrio de carga, redundancia y una alta disponibilidad.
- Una capa de almacenamiento de registro de transacciones con estado formada por el nodo de proceso que ejecuta el proceso de servicio de registro, la zona de entrada del registro de transacciones y el almacenamiento a largo plazo del registro de transacciones. La zona de aterrizaje y el almacenamiento a largo plazo usan Azure Storage, que proporciona disponibilidad y redundancia para el registro de transacciones, lo que garantiza la durabilidad de los datos para las transacciones confirmadas.
- Una capa de almacenamiento de datos con estado con los archivos de base de datos (.mdf/.ndf) que se almacenan en Azure Storage y que los servidores de páginas actualizan. Esta capa utiliza las características de disponibilidad de datos y redundancia de Azure Storage. Garantiza que todas las páginas de un archivo de datos se conserven aunque se bloqueen los procesos de otras capas de la arquitectura de Hiperescala o si se produzca un error en los nodos de proceso.
Los nodos de proceso de todas las capas de Hiperescala se ejecutan en Azure Service Fabric, que controla el estado de cada nodo y realiza conmutaciones por error en los nodos correctos disponibles según sea necesario.
Para más información sobre la alta disponibilidad en Hiperescala, consulte Alta disponibilidad de base de datos en Hiperescala.
Disponibilidad con redundancia de zona
La disponibilidad con redundancia de zona garantiza que los datos se distribuyan entre tres zonas de disponibilidad de Azure en la región primaria. Cada zona de disponibilidad es una ubicación física individual con alimentación, refrigeración y redes independientes.
La disponibilidad con redundancia de zona está disponible para las bases de datos en los niveles de servicio Premium, Crítico para la empresa, De uso general e Hiperescala y no en los niveles de servicio Básico y Estándar del modelo de compra basado en DTU. Cada nivel de servicio implementa la disponibilidad con redundancia de zona de forma diferente. Vea los detalles de cada nivel de servicio en las secciones siguientes. Todas las implementaciones garantizan un objetivo de punto de recuperación (RPO) sin pérdida de datos confirmados tras la conmutación por error.
Nivel de servicio Uso general
La configuración con redundancia de zona para el nivel de servicio De uso general se ofrece para el proceso sin servidor y aprovisionado para las bases de datos en el modelo de compra de núcleo virtual. Esta configuración emplea Azure Availability Zones para replicar las bases de datos entre varias ubicaciones físicas dentro de una región de Azure. Al seleccionar la redundancia de zona, puede hacer que las bases de datos de uso general sin servidor o aprovisionadas existentes y los grupos elásticos sean capaces de resistir a un número mucho mayor de errores, como interrupciones catastróficas de los centros de datos, sin necesidad de cambiar la lógica de la aplicación.
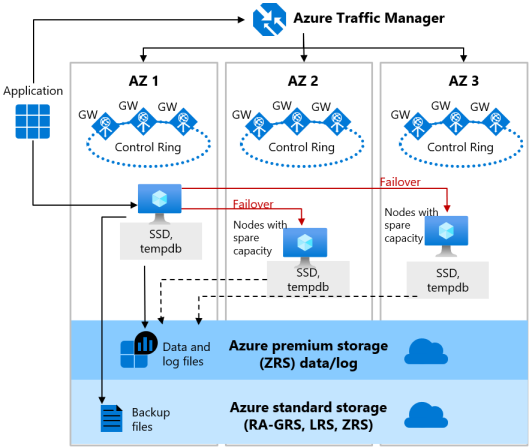
La configuración con redundancia de zona para el nivel De uso general tiene dos capas:
- Una capa de datos con estado con los archivos de base de datos (.mdf o .ldf) que se almacenan en ZRS (almacenamiento con redundancia de zona). Con ZRS, los archivos de datos y de registro se copian de forma sincrónica en tres zonas de disponibilidad de Azure aisladas físicamente.
- Una capa de proceso sin estado que ejecuta el proceso sqlservr.exe y que solo contiene datos transitorios y en caché, como las bases de datos
tempdbymodelen la memoria SSD conectada, y la memoria caché de planes, el grupo de búferes y el grupo de almacén de columnas en memoria. Azure Service Fabric controla este nodo sin estado, que inicializa sqlservr.exe, controla el estado del nodo y realiza la conmutación por error a otro nodo si es necesario. En el caso de las bases de datos de uso general sin servidor y aprovisionadas, con redundancia de zona, los nodos con capacidad de reserva están disponibles fácilmente en otras zonas de disponibilidad para la conmutación por error.
En el diagrama siguiente se ilustra la versión con redundancia de zona de la arquitectura de alta disponibilidad para el nivel de servicio De uso general:
Tenga en cuenta lo siguiente al configurar las bases de datos De uso general con redundancia de zona:
- Para el nivel de uso general, la configuración redundante por zonas está disponible de forma general en las siguientes regiones:
- (África) Norte de Sudáfrica
- (Asia Pacífico) Este de Australia
- (Asia Pacífico) Este de Asia
- (Asia Pacífico) Este de Japón
- (Asia Pacífico) Centro de Corea del Sur
- (Asia Pacífico) Sudeste de Asia
- (Asia Pacífico) Centro de la India
- (Asia Pacífico) Norte de China 3
- (Asia Pacífico) Norte de Emiratos Árabes Unidos
- (Europa) Centro de Francia
- (Europa) Centro-oeste de Alemania
- (Europa) Norte de Italia
- (Europa) Norte de Europa
- (Europa) Este de Noruega
- (Europa) Centro de Polonia
- (Europa) Oeste de Europa
- (Europa) Sur de Reino Unido
- (Europa) Norte de Suiza
- (Europa) Centro de Suecia
- (Oriente Medio) Centro de Israel
- (Oriente Medio) Centro de Catar
- (Norteamérica) Centro de Canadá
- (Norteamérica) Este de EE. UU.
- (Norteamérica) Este de EE. UU. 2
- (Norteamérica) Centro-sur de EE. UU.
- (Norteamérica) Oeste de EE. UU. 2
- (Norteamérica) Oeste de EE. UU. 3
- (Sudamérica) Sur de Brasil
- Para la disponibilidad con redundancia de zona, la elección de una ventana de mantenimiento distinta de la predeterminada está disponible actualmente en regiones seleccionadas.
- La configuración con redundancia de zona solo está disponible en SQL Database cuando se selecciona hardware de serie estándar (Gen5).
- La redundancia de zona no está disponible para los niveles de servicio Básico y Estándar en el modelo de compra de DTU.
Niveles de servicio Premium y Crítico para la empresa
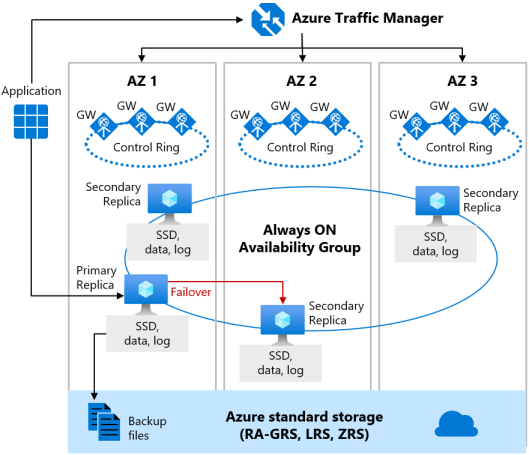
Cuando la redundancia de zona está habilitada para el nivel de servicio Premium o Crítico para la empresa, las réplicas se colocan en diferentes zonas de disponibilidad de la misma región. Para eliminar un punto de error único, también se duplica el anillo de control en varias zonas como tres anillos de puerta de enlace. El enrutamiento a un anillo de puerta de enlace específico se controla mediante Azure Traffic Manager. Como la configuración con redundancia de zona en los niveles de servicio Premium o Crítico para la empresa usa sus réplicas existentes para colocar en diferentes zonas de disponibilidad, puede habilitarla sin costo adicional. Si selecciona una configuración de redundancia de zona, puede hacer que las bases de datos de los niveles Premium o Crítico para la empresa y grupos elásticos sean resistentes a un número mucho mayor de errores, como interrupciones catastróficas de los centros de datos, sin necesidad de cambiar la lógica de la aplicación. También puede aplicar la configuración de redundancia de zona a cualquier grupo elástico o base de datos existente del nivel Premium o Crítico para la empresa.
En el diagrama siguiente se ilustra la versión con redundancia de zona de la arquitectura de alta disponibilidad:
Tenga en cuenta lo siguiente al configurar las bases de datos Premium o Crítico para la empresa con redundancia de zona:
- Para información actualizada sobre las regiones que admiten bases de datos con redundancia de zona, consulte Soporte técnico de servicios por región.
- Para la disponibilidad con redundancia de zona, la elección de una ventana de mantenimiento distinta de la predeterminada está disponible actualmente en regiones seleccionadas.
Nivel de servicio Hiperescala
Es posible configurar la redundancia de zona para las bases de datos en el nivel de servicio Hiperescala. Para más información, consulte Creación de una base de datos de Hiperescala con redundancia de zona.
La habilitación de esta configuración garantiza la resistencia de nivel de zona a través de la replicación en Availability Zones para todas las capas de Hiperescala. Al seleccionar la redundancia de zona, puede hacer que las bases de datos de Hiperescala sean capaces de resistir a un número mucho mayor de errores, como interrupciones catastróficas de los centros de datos, sin necesidad de cambiar la lógica de la aplicación. Todas las regiones de Azure que tienen Availability Zones admiten la base de datos hiperescala con redundancia de zona.
La disponibilidad con redundancia de zona se admite tanto en bases de datos independientes de Hiperescala como en grupos elásticos de Hiperescala. Para más información, consulte Grupos elásticos de Hiperescala.
En el diagrama siguiente se muestra la arquitectura subyacente para las bases de datos de Hiperescala con redundancia de zona:

Tenga en cuenta las limitaciones siguientes:
La configuración con redundancia de zona solo se puede especificar durante la creación de la base de datos. Esta configuración no se puede modificar una vez aprovisionado el recurso. Use Copia de base de datos o restauración a un momento dado, o cree una réplica geográfica para actualizar la configuración con redundancia de zona para una base de datos de Hiperescala existente. Al usar una de las opciones de actualización, si la base de datos de destino se encuentra en una región diferente a la del origen, o si la redundancia del almacenamiento de copia de seguridad de base de datos del destino difiere de la base de datos de origen, la operación de copia será una operación del tamaño de los datos.
Para la disponibilidad con redundancia de zona, la elección de una ventana de mantenimiento distinta de la predeterminada está disponible actualmente en regiones seleccionadas.
Actualmente no hay ninguna opción para especificar la redundancia de zona al migrar una base de datos a Hiperescala mediante el Azure Portal. Actualmente, se puede especificar la redundancia de zona con PowerShell, la CLI de Azure o la API de REST cuando se migra una base de datos existente a Hiperescala desde otro nivel de servicio de Azure SQL Database. Este es un ejemplo con la CLI de Azure:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant trueSe requiere al menos una réplica de proceso de alta disponibilidad y el uso del almacenamiento de copia de seguridad con redundancia de zona o geográfica para habilitar la configuración con redundancia de zona para Hiperescala.
Disponibilidad con redundancia de zona de la base de datos
En Azure SQL Database, un servidor es una construcción lógica que actúa como punto administrativo central para una colección de bases de datos. En el nivel de servidor, puedes administrar inicios de sesión, métodos de autenticación, reglas de firewall, reglas de auditoría, directivas de detección de amenazas y grupos de conmutación por error. Los datos relacionados con algunas de estas características, como inicios de sesión y reglas de firewall, se almacenan en la base de datos master. De forma similar, los datos de algunas DMV, por ejemplo , sys.resource_stats, también se almacenan en la base de datos master.
Cuando se crea una base de datos con una configuración con redundancia de zona en un servidor lógico, la base de datos master asociada al servidor también se convierte automáticamente en redundancia de zona. Esto garantiza que, en una interrupción zonal, las aplicaciones que usan la base de datos no se ven afectadas porque las características que dependen de la base de datos master, como inicios de sesión y reglas de firewall, siguen estando disponibles. Hacer que la redundancia de zona de base de datos master sea un proceso asincrónico y tardará algún tiempo en finalizar en segundo plano.
Cuando ninguna de las bases de datos de un servidor tiene redundancia de zona o cuando se crea un servidor vacío, la base de datos master asociada al servidor no tiene redundancia de zona.
Puede usar Azure PowerShell o la CLI de Azure o la API REST para comprobar la ZoneRedundant propiedad de la base de datos master:
Use el siguiente comando de ejemplo para comprobar el valor de la propiedad "ZoneRedundant" de la base de datos master.
Get-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "myServerName" -DatabaseName "master"
Prueba de la resistencia a errores de la aplicación
La alta disponibilidad es una parte fundamental de la plataforma SQL Database que funciona de modo transparente para la aplicación de base de datos. Sin embargo, podría ser conveniente probar el modo en que las operaciones de conmutación por error automáticas iniciadas durante los eventos planeados o no planeados afectarían a una aplicación antes de implementarla para producción. Puede desencadenar manualmente una conmutación por error mediante una llamada a una API especial para reiniciar una base de datos o un grupo elástico. En el caso de una base de datos de propósito general aprovisionada o sin servidor con redundancia de zona o un grupo elástico, la llamada a la API daría lugar a la redirección de las conexiones de cliente al nuevo elemento principal en una zona de disponibilidad diferente a la zona principal anterior. Por lo tanto, además de probar cómo afecta la conmutación por error a las sesiones de base de datos existentes, también puede comprobar si cambia el rendimiento de un extremo a otro debido a los cambios en la latencia de la red. Dado que la operación de reinicio es intrusiva y un gran número de ellas podría agotar la plataforma, solo se permite una llamada de conmutación por error cada 15 minutos para cada base de datos o grupo elástico.
Para más información sobre la alta disponibilidad y recuperación ante desastres de Azure SQL Database, consulte Lista de comprobación de alta disponibilidad y recuperación ante desastres.
Se puede iniciar una conmutación por error mediante PowerShell, la API REST o la CLI de Azure:
| Tipo de implementación | PowerShell | API DE REST | Azure CLI |
|---|---|---|---|
| Base de datos | Invoke-AzSqlDatabaseFailover | Conmutación por error de la base de datos | az rest se podría usar para invocar una llamada a la API REST desde la CLI de Azure |
| Grupo elástico | Invoke-AzSqlElasticPoolFailover | Conmutación por error del grupo elástico | az rest se podría usar para invocar una llamada a la API REST desde la CLI de Azure |
Importante
El comando de conmutación por error no está disponible para las réplicas secundarias legibles de las bases de datos de hiperescala.
Conclusión
Azure SQL Database presenta una solución de alta disponibilidad incorporada, que está totalmente integrada con la plataforma Azure. Depende de Service Fabric para la detección y la recuperación de errores, de Azure Blob Storage para la protección de datos y de Availability Zones para la mayor tolerancia a errores. Al mismo tiempo, SQL Database usa la tecnología de Grupo de disponibilidad AlwaysOn de SQL Server para la sincronización de datos y la conmutación por error. La combinación de estas tecnologías permite que las aplicaciones obtengan todos los beneficios de un modelo de almacenamiento mixto y admite los SLA más exigentes.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de