Intelligent Insights con inteligencia artificial para supervisar y solucionar problemas de rendimiento de base de datos (versión preliminar)
Se aplica a:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Intelligent Insights de Azure SQL Database y Azure SQL Managed Instance le permite saber lo que ocurre con el rendimiento de la base de datos.
Intelligent Insights usa inteligencia integrada para supervisar continuamente el uso de la base de datos mediante inteligencia artificial y detectar eventos potencialmente perjudiciales que provoquen un rendimiento bajo. Una vez detectados, se realiza un análisis detallado que genera un registro de recursos de Intelligent Insights denominado SQLInsights (que no está relacionado con Azure Monitor SQL Insights [versión preliminar]) con una evaluación inteligente de la incidencia. Esta evaluación está formada por un análisis de la causa raíz del problema de rendimiento de la base de datos y, si es posible, recomendaciones para mejorar el rendimiento.
¿Qué puede hacer Intelligent Insights por usted?
Intelligent Insights es una funcionalidad única de inteligencia integrada de Azure que permite lo siguiente:
- Supervisión proactiva
- Información reveladora personalizada acerca del rendimiento
- Detección temprana de degradación del rendimiento de la base de datos
- El análisis de la causa raíz de los problemas detectados
- Recomendaciones de mejora del rendimiento
- Funcionalidad de escalabilidad horizontal de cientos de miles de bases de datos
- Impacto positivo para los recursos de DevOps y el costo total de propiedad
¿Cómo funciona Intelligent Insights?
Intelligent Insights analiza el rendimiento de la base de datos comparando la carga de trabajo de la base de datos de la última hora con la de referencia de los últimos siete días. La carga de trabajo de la base de datos se compone de consultas determinadas para que sean las más significativas para el rendimiento de la base de datos, como las consultas más repetidas y de mayor tamaño. Dado que cada base de datos es única según su estructura, datos, uso y aplicación, cada referencia de carga de trabajo generada es específica y única para esa carga de trabajo. Intelligent Insights, que es independiente de la referencia de la carga de trabajo, también supervisa umbrales operativos absolutos y detecta problemas con los tiempos de espera excesivos, las excepciones críticas y los problemas con parametrizaciones de consulta que podrían afectar al rendimiento.
Una vez detectado un problema de degradación del rendimiento de varias métricas observadas mediante el uso de inteligencia artificial, se lleva a cabo el análisis. Se genera un registro de diagnóstico con una valoración inteligente de lo que sucede con la base de datos. Intelligent Insights facilita la realización de un seguimiento del problema de rendimiento de la base de datos desde su primera aparición hasta la resolución. Cada problema detectado se sigue a través de su ciclo de vida desde la detección inicial del mismo y la comprobación de la mejora en el rendimiento hasta su finalización.
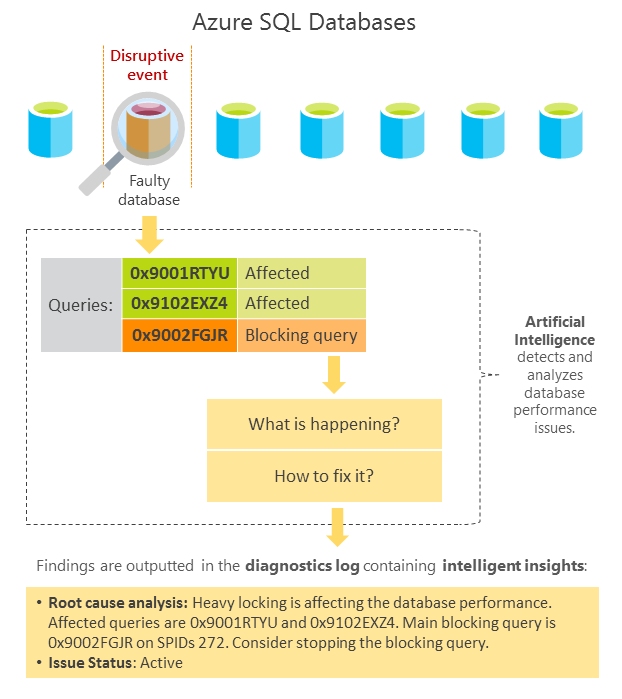
Las métricas usadas para medir y detectar problemas de rendimiento de las bases de datos se basan en la duración de las consultas, las solicitudes con tiempo de espera agotado, tiempos de espera excesivos y solicitudes con errores. Para más información sobre las métricas, vea la sección Métricas de detección.
Las degradaciones identificadas en el rendimiento de las bases de datos se guardan en el registro SQLInsights de Intelligent Insights con entradas inteligentes que tienen las siguientes propiedades:
| Propiedad | Detalles |
|---|---|
| Información de base de datos | Metadatos acerca de una base de datos en la que se ha detectado una recomendación, por ejemplo, un URI de recurso. |
| Intervalo de tiempo observado | Hora inicial y final del período de la recomendación detectada. |
| Métricas afectadas | Métricas que provocan que se genere una recomendación:
|
| Valor del impacto | Valor de una métrica medida. |
| Consultas afectadas y códigos de error | Código de error o hash de consulta. Se pueden usar para realizar una correlación fácilmente en las consultas afectadas. Se proporcionan métricas que consisten en un aumento de la duración de la consulta, tiempo de espera, recuentos de tiempo de espera o códigos de error. |
| Detecciones | Detección identificada en la base de datos durante un evento. Existen 15 patrones de detección. Para más información, consulte Troubleshoot database performance issues with Intelligent Insights (Solución de problemas de rendimiento de la base de datos con Intelligent Insights). |
| Análisis de la causa raíz | Análisis de la causa raíz (RCA) del problema identificado en un formato legible. En algunos casos, la información reveladora podría contener recomendaciones de mejora del rendimiento si es posible. |
Intelligent Insights destaca a la hora de detectar y solucionar problemas de rendimiento de las bases de datos. Para usar Intelligent Insights para solucionar problemas de rendimiento de bases de datos, consulte Solucionar problemas de rendimiento con Intelligent Insights.
Opciones de Intelligent Insights
Las opciones de Intelligent Insights disponibles son:
| Opción de Intelligent Insights | Compatibilidad con Azure SQL Database | Compatibilidad con la Instancia administrada de Azure SQL |
|---|---|---|
| Configure Intelligent Insights (Configurar Intelligent Insights): Configure el análisis de Intelligent Insights para las bases de datos. | Sí | Sí |
| Stream insights to Azure SQL Analytics (Transmitir conclusiones a Azure SQL Analytics): Transmita conclusiones a Azure SQL Analytics. | Sí | Sí |
| Stream insights to Azure Event Hubs (Transmitir conclusiones a Azure Event Hubs): transmita conclusiones a Event Hubs para integraciones personalizadas adicionales. | Sí | Sí |
| Stream insights to Azure Storage (Transmitir conclusiones a Azure Storage): transmita conclusiones a Azure Storage para análisis adicional y archivado a largo plazo. | Sí | Sí |
Nota
Intelligent Insights es una característica en versión preliminar que no está disponible en las siguientes regiones: Oeste de Europa, Norte de Europa, Oeste de EE. UU. 1 y Este de EE. UU. 1.
Configuración de la exportación del registro de Intelligent Insights
La salida de Intelligent Insights se puede transmitir a uno de varios destinos para su análisis:
- La salida transmitida a un área de trabajo de Log Analytics se puede usar con Azure SQL Analytics para ver información detallada mediante la interfaz de usuario de Azure Portal. Esta es la solución integrada de Azure y la forma más habitual de ver la información.
- La salida transmitida a Azure Event Hubs se puede usar para el desarrollo de escenarios de supervisión y alertas personalizados.
- La salida transmitida a Azure Storage se puede usar para desarrollar aplicaciones personalizadas de generación de informes personalizados, archivo de datos a largo plazo, etc.
Para realizar la integración de Azure SQL Analytics, Azure Event Hubs, Azure Storage o productos de terceros para su consumo, primero es necesario habilitar el registro de Intelligent Insights (el registro «SQLInsights») en la página Configuración de diagnóstico de una base de datos y, después, configurar los datos de registro de Intelligent Insights para transmitirlos a uno de estos destinos.
Para obtener más información acerca de cómo habilitar el registro de Intelligent Insights y cómo configurar los datos de registro de métricas y recursos para su transmisión a un producto de consumo, consulte Registros de métricas y diagnóstico.
Configurar con Azure SQL Analytics
La solución Azure SQL Analytics proporciona funcionalidades de interfaz gráfica de usuario, informes y alertas sobre el rendimiento de la base de datos, mediante los datos de registro de diagnóstico de Intelligent Insights.
Agregue Azure SQL Analytics al panel de Azure Portal desde el Marketplace y cree un área de trabajo (consulte Configuración de Azure SQL Analytics).
Para usar Intelligent Insights con Azure SQL Analytics, configure los datos de registro de Intelligent Insights que transmitirá al área de trabajo de Azure SQL Analytics creada en el paso anterior, consulte Registros de métricas y diagnóstico.
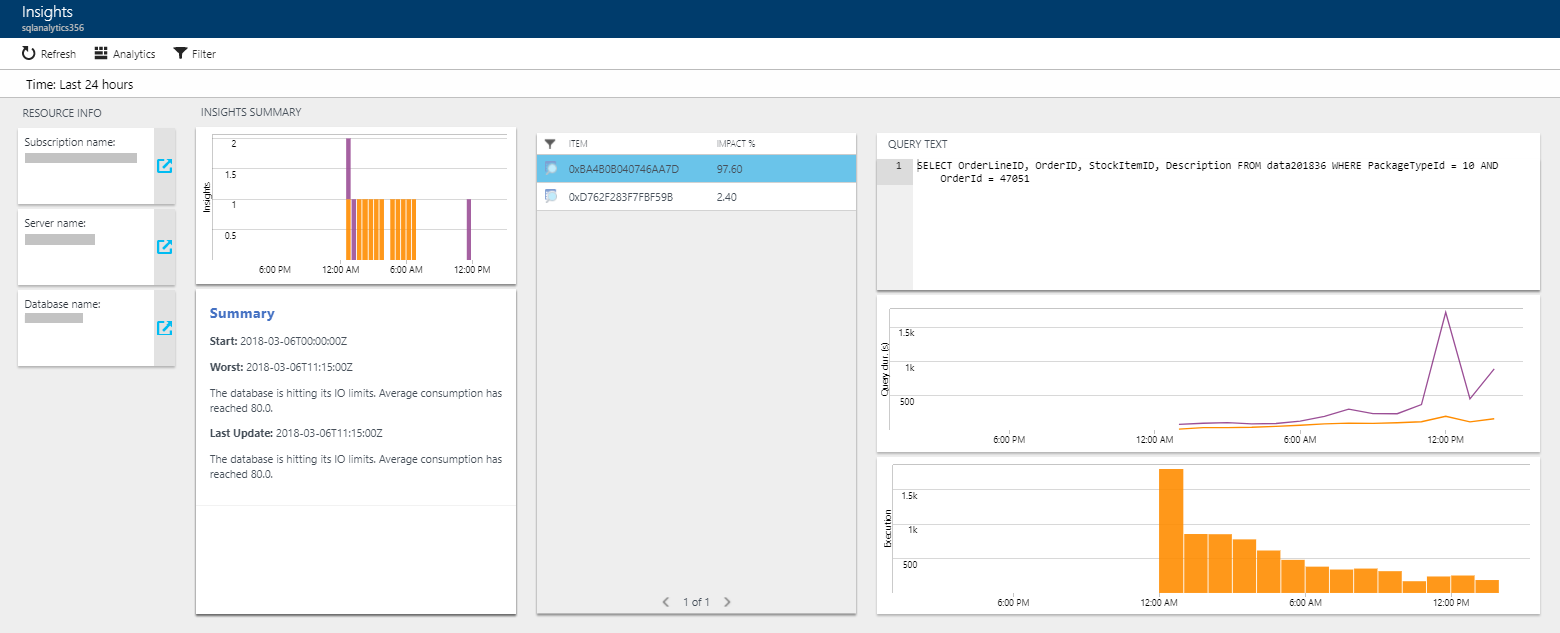
En el ejemplo siguiente se muestra un ejemplo de Intelligent Insights a través de Azure SQL Analytics:
Configuración con Event Hubs
Para usar Intelligent Insights con Event Hubs, configure los datos de registro de Intelligent Insights para que se transmitan a Event Hubs, vea Métricas y registros de diagnóstico y Transmisión de registros de diagnóstico de Azure a Event Hubs.
Para usar Event Hubs a fin de configurar la supervisión y alertas personalizadas, vea Qué hacer con las métricas y registros de diagnóstico en Event Hubs.
Configuración con Azure Storage
Para usar Intelligent Insights con Storage, configure los datos de registro de Intelligent Insights que transmitirá a Storage, consulte Registros de métricas y diagnóstico y Transmisión a Azure Storage.
Integraciones personalizadas del registro de Intelligent Insights
Para usar Intelligent Insights con herramientas de terceros, o bien para el desarrollo personalizado de supervisión y alertas, vea Uso del registro de diagnóstico de rendimiento de la base de datos de Intelligent Insights.
Métricas de detección
Las métricas utilizadas para los modelos de detección que generan Intelligent Insights se basan en la supervisión:
- Duración de la consulta
- Solicitudes con tiempo de espera
- Tiempo de espera excesivo
- Solicitudes cerradas por un error
Duración de consulta y Solicitudes con tiempo de espera se usan como modelos principales en la detección de problemas con el rendimiento de carga de trabajo de la base de datos. Se usan porque miden directamente lo que ocurre con la carga de trabajo. Para detectar todos los casos posibles de degradación del rendimiento de la carga de trabajo, se usan solicitudes cerradas por un error y tiempo de espera excesivo como modelos adicionales para indicar los problemas que afectan al rendimiento de la carga de trabajo.
El sistema considera automáticamente los cambios en la carga de trabajo y en el número de solicitudes de consulta realizadas a la base de datos para determinar de forma dinámica los umbrales de rendimiento de la base de datos normales y fuera de lo normal.
Se consideran todas las métricas juntas en distintas relaciones a través de un modelo de datos derivado científicamente que categoriza cada problema de rendimiento detectado. La información proporcionada a través de una recomendación inteligente incluye:
- Detalles del problema de rendimiento detectado.
- Análisis de la causa raíz del problema detectado.
- Recomendaciones sobre cómo mejorar el rendimiento de la base de datos supervisada, siempre que sea posible.
Duración de la consulta
El modelo de degradación de la duración de la consulta analiza las consultas individuales y detecta el aumento del tiempo que se tarda en compilar y ejecutar una consulta en comparación con la línea base de rendimiento.
Si la inteligencia integrada detecta un aumento significativo en la compilación de consultas o en su tiempo de ejecución que afecta al rendimiento de la carga de trabajo, estas consultas se marcan como problema de degradación del rendimiento de duración de la consulta.
El registro de diagnósticos de Intelligent Insights da como resultado el hash de consulta de la consulta degradada en el rendimiento. El hash de consulta indica si la degradación del rendimiento se relaciona con el aumento en el tiempo de ejecución o de compilación de la consulta, que aumentó la duración de la consulta.
Solicitudes con tiempo de espera
El modelo de degradación de solicitudes de tiempo de espera analiza las consultas individuales y detecta un aumento en los tiempos de espera en el nivel de ejecución de la consulta y los tiempos de espera de solicitud totales en el nivel de base de datos en comparación con el período de línea base de rendimiento.
El tiempo de espera de algunas consultas podría incluso superarse antes de que lleguen a la fase de ejecución. A través de la comparación entre los trabajos anulados frente a las solicitudes realizadas, la inteligencia integrada mide y analiza todas las consultas que llegaron a la base de datos y si entraron en la fase de ejecución o no.
Cuando el tiempo de espera de las consultas ejecutadas se haya agotado o bien los trabajos de solicitud se hayan anulado una cantidad de veces que supere el umbral administrado por el sistema, se rellena un registro de diagnóstico con Intelligent Insights.
La información que se genera contiene el número de solicitudes y el número de consultas que agotaron el tiempo de espera. La indicación de la degradación del rendimiento está relacionada con el aumento del tiempo de espera en la fase de ejecución, o se proporciona el nivel de base de datos general. Cuando el aumento de los tiempos de espera se considera significativo para el rendimiento de la base de datos, estas consultas se marcan como problema de degradación del rendimiento de tiempo de espera.
Tiempo de espera excesivo
El modelo de tiempo de espera excesivo supervisa las consultas de base de datos individuales. Detecta estadísticas de espera de consultas inusualmente altas que traspasan los umbrales absolutos administrados por el sistema. El comportamiento de las siguientes métricas de tiempo de espera excesivo de consulta se observa con Estadísticas de espera del Almacén de consultas (sys.query_store_wait_stats):
- Alcance de los límites de recursos
- Alcance de los límites de recursos del grupo elástico
- Número excesivo de subprocesos de sesión o trabajo
- Bloqueo de base de datos excesivo
- Presión de memoria
- Otras estadísticas de espera
Si se alcanzan los límites de recursos o los límites de recursos del grupo elástico, implica que el consumo de recursos disponibles en una suscripción o en el grupo elástico ha superado los umbrales absolutos. Estas estadísticas indican la degradación del rendimiento de la carga de trabajo. Un número excesivo de subprocesos de sesión o trabajo implica una condición en la que el número de sesiones o subprocesos de trabajo iniciado ha superado los umbrales absolutos. Estas estadísticas indican la degradación del rendimiento de la carga de trabajo.
El bloqueo de base de datos excesivo implica una condición en la que el número de bloqueos de una base de datos ha superado el umbral absoluto. Este estado indica una degradación del rendimiento de la carga de trabajo. La presión de memoria es una condición en la que el número de subprocesos que soliciten memoria concedidos superó un umbral absoluto. Este estado indica una degradación del rendimiento de la carga de trabajo.
La detección de otras estadísticas de espera indica una condición en la que varias métricas medidas a través de Query Store Wait Stats (Estadísticas de espera de Almacén de datos de consultas) han superado el umbral absoluto. Estas estadísticas indican la degradación del rendimiento de la carga de trabajo.
Una vez que se detectan tiempos de espera excesivos, en función de los datos disponibles, el registro de diagnóstico de Intelligent Insights crea un hash de las consultas afectadas con un rendimiento degradado, detalles de las métricas que provocan la espera de la ejecución de las consultas y el tiempo de espera medido.
Solicitudes cerradas por un error
El modelo de degradación de solicitudes cerradas por un error supervisa las consultas individuales y detecta un aumento en el número de consultas cerradas por un error en comparación con el período de línea base. Este modelo también supervisa las excepciones críticas que superasen los umbrales absolutos administrados por la inteligencia integrada. El sistema considera automáticamente el número de solicitudes de consulta realizadas en la base de datos y las cuentas para los cambios de carga de trabajo en el período supervisado.
Cuando se considera que el aumento medido en las solicitudes con errores relativas al número total de solicitudes realizadas es significativo en el rendimiento de la carga de trabajo, las consultas afectadas se marcan como problema de degradación del rendimiento de las solicitudes cerradas por un error.
El registro de Intelligent Insights da como resultado el número de solicitudes con errores. Indica si la degradación del rendimiento estaba relacionada con un aumento en las solicitudes con errores o con traspasar un umbral de excepción crítica supervisado y el tiempo medido de la degradación del rendimiento.
En caso de que alguna de las excepciones críticas supervisadas supere los umbrales absolutos administrados por el sistema, se genera una instancia de Intelligent Insights con detalles de la excepción crítica.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de