Acceso a datos en un trabajo
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo, aprenderá lo siguiente:
- Cómo leer datos de Azure Storage en un trabajo de Azure Machine Learning.
- Cómo escribir datos del trabajo de Azure Machine Learning en Azure Storage.
- Diferencia entre los modos de montaje y descarga.
- Cómo usar la identidad de usuario y la identidad administrada para acceder a los datos.
- Configuración de montaje disponible en un trabajo.
- Configuración de montaje óptima para escenarios comunes.
- Cómo acceder a los recursos de datos V1.
Requisitos previos
Suscripción a Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Un área de trabajo de Azure Machine Learning
Inicio rápido
Antes de explorar las opciones detalladas disponibles al acceder a los datos, primero se describen los fragmentos de código pertinentes para el acceso a los datos.
Lectura de datos de Azure Storage en un trabajo de Azure Machine Learning
En este ejemplo, se envía un trabajo de Azure Machine Learning que accede a los datos de una cuenta de almacenamiento de blobs pública. Sin embargo, puede adaptar el fragmento de código para acceder a sus propios datos en una cuenta privada de Azure Storage. Actualice la ruta de acceso como se describe aquí. Azure Machine Learning controla de manera sencilla la autenticación en el almacenamiento en la nube con el tránsito de Microsoft Entra. Al enviar un trabajo, puede elegir:
- Identidad del usuario: realice el tránsito de la identidad de Microsoft Entra para acceder a los datos.
- Identidad administrada: use la identidad administrada del destino de proceso para acceder a los datos.
- Ninguno: No especifique una identidad para acceder a los datos. Utilice la opción Ninguno al usar almacenes de datos basados en credenciales (token de clave/SAS) o al acceder a datos públicos.
Sugerencia
Si usa claves o tokens de SAS para autenticarse, se recomienda crear un almacén de datos de Azure Machine Learning, ya que el entorno de ejecución se conectará automáticamente al almacenamiento sin exponer la clave o el token.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data. Supported paths include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# We set the path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Escritura de datos del trabajo de Azure Machine Learning en Azure Storage
En este ejemplo, se envía un trabajo de Azure Machine Learning que escribe datos en el almacén de datos de Azure Machine Learning predeterminado. De manera opcional, puede establecer el valor name del recurso de datos para crear un recurso de datos en la salida.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the input and output URI paths for the data. Supported paths include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment name (name can be set without setting version)
# name = "<name_of_data_asset>",
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Entorno de ejecución de datos de Azure Machine Learning
Al enviar un trabajo, el runtime de datos de Azure Machine Learning controla la carga de datos desde la ubicación de almacenamiento hasta el destino de proceso. El entorno de ejecución de los datos de Azure Machine Learning se ha optimizado para ser rápido y eficaz para las tareas de aprendizaje automático. Entre las ventajas clave se incluyen las siguientes:
- La carga de datos se escribe en lenguaje Rust, que se conoce por su alta velocidad y eficiencia de memoria alta. Para descargas de datos simultáneas, Rust evita los problemas de bloqueo de intérprete global (GIL) de Python.
- Ligero; Rust no tiene dependencias en otras tecnologías, por ejemplo, JVM. Como resultado, el entorno de ejecución se instala rápidamente y no consume recursos adicionales (CPU, memoria) en el destino de proceso.
- Carga de datos de varios procesos (paralelos)
- Realiza una captura previa de datos como una tarea en segundo plano en las CPU para permitir un mejor uso de las GPU al realizar el aprendizaje profundo.
- Autenticación sencilla en el almacenamiento en la nube
- Proporciona opciones para montar datos (secuencia) o descargar todos los datos. Para más información, consulte las secciones Montaje (streaming) y Descarga.
- Integración sin problemas con fsspec: una interfaz de Python unificada a sistemas de archivos locales, remotos e incrustados y almacenamiento de byte.
Sugerencia
Se sugiere aprovechar el entorno de ejecución de los datos de Azure Machine Learning en lugar de crear su propia capacidad de montaje o descarga en el código de entrenamiento (cliente). En concreto, hemos visto que el rendimiento del almacenamiento está restringido cuando el código de cliente usa Python para descargar datos del almacenamiento debido a problemas de bloqueo de intérprete global (GIL).
Rutas de acceso
Al proporcionar una entrada y salida de datos a un trabajo, debe especificar un parámetro path que apunte a la ubicación de los datos. Esta tabla muestra las diferentes ubicaciones de datos que admite Azure Machine Learning y también muestra ejemplos del parámetro path:
| Ubicación | Ejemplos |
|---|---|
| Ruta de acceso en la máquina local | ./home/username/data/my_data |
| Ruta de acceso en un servidor http(s) público | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Ruta de acceso en Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Una ruta de acceso en un almacén de datos de Azure Machine Learning | azureml://datastores/<data_store_name>/paths/<path> |
| Ruta de acceso a un recurso de datos | azureml:<my_data>:<version> |
Modos
Al ejecutar un trabajo con entradas y salidas de datos, puede seleccionar entre estas opciones de modos:
ro_mount: monte la ubicación de almacenamiento como de solo lectura en el disco local (SSD) del destino de proceso.rw_mount: monte la ubicación de almacenamiento como de lectura-escritura en el disco local (SSD) del destino de proceso.download: descargue los datos de la ubicación de almacenamiento en el disco local (SSD) del destino de proceso.upload: cargue datos desde el destino de proceso a la ubicación de almacenamiento.eval_mount/eval_download:Estos modos son exclusivos de MLTable. En algunos escenarios, una instancia de MLTable puede producir archivos que pueden localizarse en una cuenta de almacenamiento diferente a la cuenta de almacenamiento que hospeda el archivo MLTable. Como alternativa, una instancia de MLTable puede agrupar u ordenar aleatoriamente los datos ubicados en el recurso de almacenamiento. Esa vista del subconjunto u orden aleatorio solo es visible si el entorno de ejecución de datos de Azure Machine Learning evalúa realmente el archivo MLTable. Por ejemplo, en este diagrama se muestra cómo una tabla MLTable usada coneval_mountoeval_downloadpuede tomar imágenes de dos contenedores de almacenamiento diferentes y un archivo de anotaciones ubicado en una cuenta de almacenamiento diferente y, a continuación, montar o descargar en el sistema de archivos del destino de proceso remoto.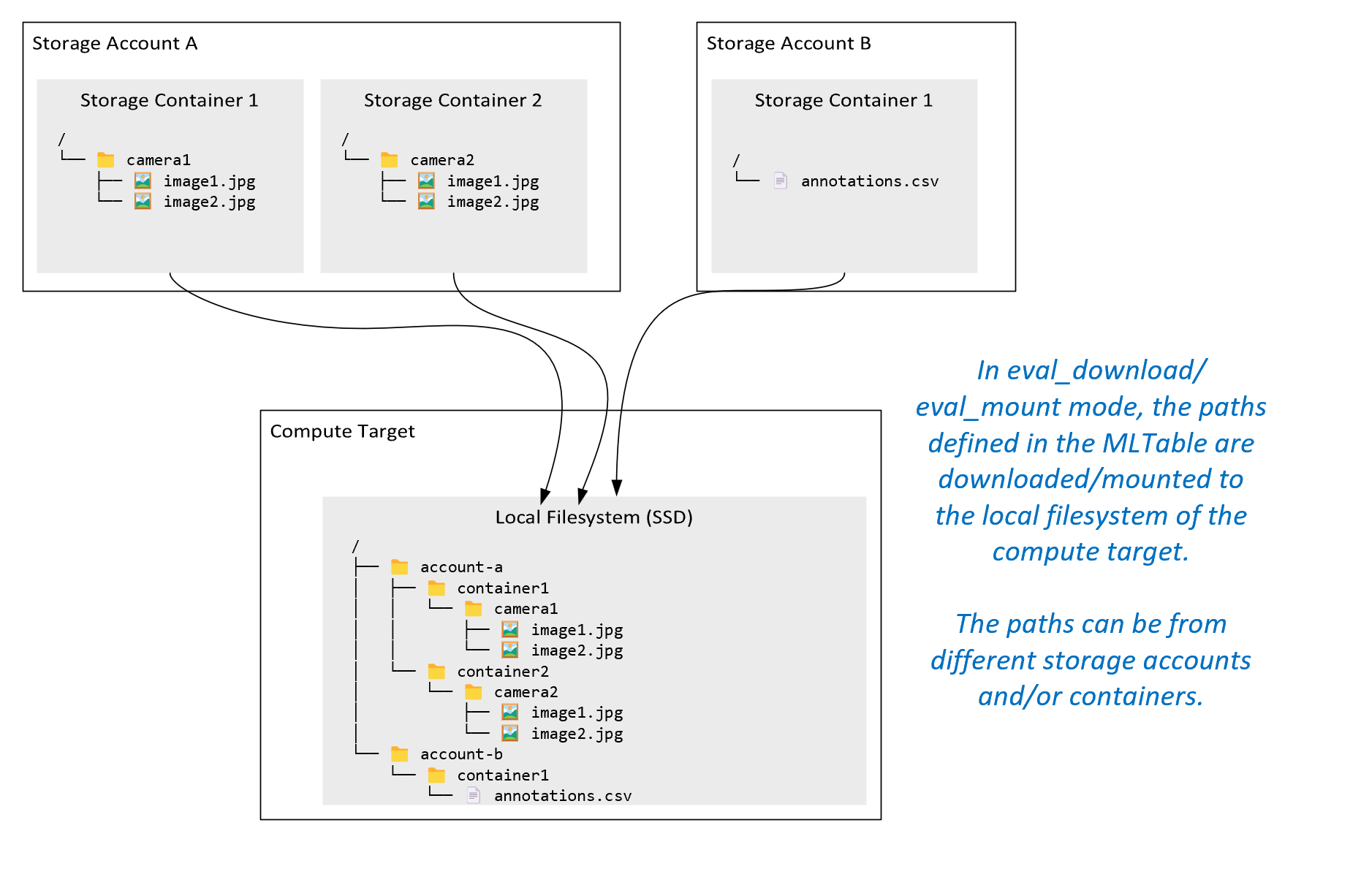
A continuación, se puede acceder a las carpetas
camera1ycamera2y al archivoannotations.csven el sistema de archivos del destino de proceso en la estructura de carpetas:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: es posible que quiera leer datos directamente desde un URI a través de otras API, en lugar de pasar por el runtime de datos de Azure Machine Learning. Por ejemplo, puede que desee acceder a los datos de un cubo s3 (con una dirección URLhttpsde estilo hospedado virtual o de estilo de ruta de acceso) mediante el cliente boto s3. Puede obtener el URI de la entrada como una cadena con el mododirect. Verá el uso del modo directo en trabajos de Spark porque los métodosspark.read_*()saben cómo procesar los URI. En el caso de los trabajos que no son de Spark, es su responsabilidad administrar las credenciales de acceso. Por ejemplo, debe usar explícitamente MSI de proceso o, de lo contrario, el acceso de agente.

En esta tabla se muestran los modos posibles para diferentes combinaciones de tipo, modo, entrada y salida:
| Tipo | Entrada/salida | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Entrada | ✓ | ✓ | ✓ | ||||
uri_file |
Entrada | ✓ | ✓ | ✓ | ||||
mltable |
Entrada | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Output | ✓ | ✓ | |||||
uri_file |
Output | ✓ | ✓ | |||||
mltable |
Output | ✓ | ✓ | ✓ |
Descargar
En el modo de descarga, todos los datos de entrada se copian en el disco local (SSD) del destino de proceso. El runtime de datos de Azure Machine Learning inicia el script de entrenamiento de usuario una vez copiados todos los datos. Cuando se inicia el script de usuario, lee datos del disco local igual que cualquier otro archivo. Cuando finaliza el trabajo, los datos se quitan del disco del destino de proceso.
| Ventajas | Inconvenientes |
|---|---|
| Cuando se inicia el entrenamiento, todos los datos están disponibles en el disco local (SSD) del destino de proceso para el script de entrenamiento. No se requiere ninguna interacción de red o almacenamiento de Azure. | El conjunto de datos debe ajustarse completamente a un disco de destino de proceso. |
| Una vez que se inicia el script de usuario, no hay dependencias en la confiabilidad del almacenamiento o la red. | Se descarga todo el conjunto de datos (si el entrenamiento necesita seleccionar aleatoriamente solo una pequeña parte de los datos, se desperdicia gran parte de la descarga). |
| El runtime de datos de Azure Machine Learning puede paralelizar la descarga (diferencia significativa en muchos archivos pequeños) y el rendimiento máximo de red o almacenamiento. | El trabajo espera hasta que todos los datos se descarguen en el disco local del destino de proceso. Si envía un trabajo de aprendizaje profundo, las GPU están inactivas hasta que los datos estén listos. |
| No hay sobrecarga inevitable agregada por la capa FUSE (ida y vuelta: llamada de espacio del usuario en el script de usuario → kernel → demonio de FUSE de espacio de usuario → kernel → respuesta al script de usuario en el espacio del usuario) | Los cambios de almacenamiento no se reflejan en los datos una vez finalizada la descarga. |
Cuándo usar la descarga
- Los datos son lo suficientemente pequeños como para que se ajusten al disco del destino de proceso sin interferir con otro entrenamiento.
- El entrenamiento usa todos o la mayoría de los conjuntos de datos.
- El entrenamiento lee los archivos de un conjunto de datos más de una vez.
- El entrenamiento debe saltar a posiciones aleatorias de un archivo grande.
- Es correcto esperar hasta que se descarguen todos los datos antes de que se inicie el entrenamiento.
Configuración de descarga disponible
Puede ajustar la configuración de descarga con las siguientes variables de entorno en el trabajo:
| Nombre de la variable de entorno | Tipo | Valor predeterminado | Descripción |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Número de descargas de subprocesos simultáneos que se pueden usar |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Número de reintentos de almacenamiento o solicitudes http individuales para recuperarse de errores transitorios. |
En el trabajo, puede cambiar los valores predeterminados anteriores estableciendo las variables de entorno, por ejemplo:
Por motivos de brevedad, solo se muestra cómo definir las variables de entorno en el trabajo.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Descarga de métricas de rendimiento
El tamaño de máquina virtual del destino de proceso tiene un efecto en el tiempo de descarga de los datos. Concretamente:
- Número de núcleos. Cuantos más núcleos estén disponibles, más simultaneidad y, por tanto, habrá una velocidad de descarga más rápida.
- Ancho de banda de red esperado. Cada máquina virtual de Azure tiene un rendimiento máximo de la tarjeta de interfaz de red (NIC).
Nota
Para las máquinas virtuales de GPU A100, el runtime de datos de Azure Machine Learning puede saturar la NIC (tarjeta de interfaz de red) al descargar datos en el destino de proceso (~24 Gbit/s): rendimiento máximo teórico posible.
En esta tabla se muestra el rendimiento de descarga que el entorno de ejecución de datos de Azure Machine Learning puede controlar para un archivo de 100 GB en una máquina virtual Standard_D15_v2 (20 núcleos, rendimiento de red de 25 Gbit/s):
| Estructura de los datos | Solo descarga (segundos) | Descargar y calcular MD5 (segundos) | Rendimiento logrado (Gbit/s) |
|---|---|---|---|
| Archivos de 10 x 10 GB | 55,74 | 260,97 | 14,35 Gbit/s |
| Archivos de 100 x 1 GB | 58,09 | 259,47 | 13,77 Gbit/s |
| Archivo de 1 x 100 GB | 96,13 | 300,61 | 8,32 Gbit/s |
Podemos ver que un archivo mayor, dividido en archivos más pequeños, puede mejorar el rendimiento de la descarga debido al paralelismo. Se recomienda evitar que los archivos se vuelvan demasiado pequeños (menos de 4 MB) ya que el tiempo necesario para los envíos de solicitudes de almacenamiento aumenta en relación con el tiempo dedicado a descargar la carga. Para obtener más información, consulte Problema relativo a muchos archivos pequeños.
Montaje (streaming)
En el modo de montaje, la funcionalidad de datos de Azure Machine Learning usa la característica FUSE (sistema de archivos en el espacio de usuario) de Linux para crear un sistema de archivos emulado. En lugar de descargar todos los datos en el disco local (SSD) del destino de proceso, el entorno de ejecución puede reaccionar a las acciones de script del usuario en tiempo real. Por ejemplo, "abrir archivo", "leer fragmento de 2 KB de la posición X", "contenido del directorio de lista".
| Ventajas | Inconvenientes |
|---|---|
| Los datos que superan la capacidad del disco local de destino de proceso se pueden usar (no limitados por el hardware de proceso). | Se agregó sobrecarga del módulo FUSE de Linux. |
| No hay retraso al principio del entrenamiento (a diferencia del modo de descarga). | Dependencia del comportamiento del código del usuario (si el código de entrenamiento que lee secuencialmente archivos pequeños en un solo montaje de subproceso también solicita datos del almacenamiento, es posible que no maximice el rendimiento de red o almacenamiento). |
| Más opciones de configuración disponibles para optimizar un escenario de uso. | Sin compatibilidad con Windows. |
| Solo se leen los datos necesarios para el entrenamiento del almacenamiento. |
Cuándo usar el montaje
- Los datos son grandes y no se ajustan al disco local de destino de proceso.
- Los nodos de proceso individual de un clúster no necesitan leer todo el conjunto de datos (archivo aleatorio o filas en la selección de archivos .csv, etc.).
- Los retrasos a la espera de que se descarguen todos los datos antes de que se inicie el entrenamiento pueden convertirse en un problema (tiempo de GPU inactivo).
Configuración de montaje disponible
Puede ajustar la configuración de montaje con las siguientes variables de entorno en el trabajo:
| Nombre de la variable del entorno | Tipo | Valor predeterminado | Descripción |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | No establecido (la memoria caché nunca expira) | Tiempo, en milisegundos, necesario para mantener los resultados de las llamadas getattr en la memoria caché y para evitar que las solicitudes posteriores de esta información vuelvan a almacenarse. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Diseñado para una configuración del sistema, para mantener el proceso correcto. Independientemente de los valores de la otra configuración, el entorno de ejecución de datos de Azure Machine Learning no usa los últimos RESERVED_FREE_DISK_SPACE bytes de espacio en disco. |
DATASET_MOUNT_CACHE_SIZE |
usize | Sin límite | Controla la cantidad de montaje de espacio en disco que puede usar. Un valor positivo establece el valor absoluto en bytes. El valor negativo establece la cantidad de espacio en disco que se va a dejar libre. En esta tabla se proporcionan más opciones de caché de disco. Admite modificadores de KB, MB y GB para mayor comodidad. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | El montaje del volumen inicia la eliminación de caché cuando la memoria caché se rellena en AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Debe estar entre 0 y 1. Si se establece en < 1, se desencadena la eliminación de la caché en segundo plano más pronto. |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | La eliminación de la memoria caché intenta liberar al menos (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) de un espacio de caché. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Tamaño del bloque de lectura de streaming. Cuando el archivo es lo suficientemente grande, solicite al menos DATASET_MOUNT_READ_BLOCK_SIZE de datos del almacenamiento y de caché, incluso cuando la operación de lectura solicitada por fuse era menor. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Número de bloques que se van a capturar previamente (el bloque de lectura k desencadena la captura previa de fondo de los bloques k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT). |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Número de subprocesos de captura previa en segundo plano. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | false | Habilite el almacenamiento en caché basado en bloques. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Solo se aplica al almacenamiento en caché basado en bloques. El tamaño del almacenamiento en caché basado en bloques de RAM lo puede usar. Un valor de 0 deshabilita completamente el almacenamiento en caché de memoria. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | true | Solo se aplica al almacenamiento en caché basado en bloques. Cuando se establece en true, el almacenamiento en caché basado en bloques usa la unidad de disco duro local para almacenar bloques en caché. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Solo se aplica al almacenamiento en caché basado en bloques. El almacenamiento en caché basado en bloques escribe el bloque almacenado en caché en un disco local en segundo plano. Esta configuración controla la cantidad de montaje de memoria que puede usar para almacenar bloques en espera de que se vacíen en la memoria caché del disco local. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Solo se aplica al almacenamiento en caché basado en bloques. Número de subprocesos en segundo plano que el almacenamiento en caché basado en bloques usa para escribir bloques descargados en el disco local del destino de proceso. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Tiempo en segundos para que unmount finalice (correctamente) todas las operaciones pendientes (por ejemplo, las llamadas de vaciado) antes de terminar el bucle de mensajes de montaje de forma forzada. |
En el trabajo, puede cambiar los valores predeterminados anteriores estableciendo las variables de entorno, por ejemplo:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Modo abierto basado en bloques
En el modo abierto basado en bloques, cada archivo se divide en bloques de un tamaño predefinido (excepto el último bloque). Una solicitud de lectura de una posición especificada solicita un bloque correspondiente del almacenamiento y devuelve los datos solicitados inmediatamente. Una lectura también desencadena la captura previa en segundo plano de N bloques siguientes mediante varios subprocesos (optimizados para lectura secuencial). Los bloques descargados se almacenan en caché en dos capas (RAM y disco local).
| Ventajas | Inconvenientes |
|---|---|
| Entrega rápida de datos al script de entrenamiento (menos bloqueo de fragmentos que aún no se solicitaron). | Las lecturas aleatorias pueden desperdiciar bloques de captura previa de reenvío. |
| Más descargas de trabajo en subprocesos en segundo plano (captura previa o almacenamiento en caché). Después, el entrenamiento puede continuar. | Se ha agregado sobrecarga para navegar entre cachés, en comparación con las lecturas directas de un archivo en una caché de disco local (por ejemplo, en modo de caché de archivos completos). |
| Solo se leen los datos solicitados (más la captura previa) del almacenamiento. | |
| Para datos lo suficientemente pequeños, se usa caché rápida basada en RAM. |
Cuándo usar el modo abierto basado en bloques
Se recomienda para la mayoría de los escenarios, excepto cuando se necesitan lecturas rápidas de ubicaciones de archivos aleatorias. En esos casos, use el modo de apertura de caché de archivos completos.
Modo de apertura de caché de archivos completos
En el modo de archivo completo, cuando se abre un archivo en una carpeta de montaje (por ejemplo, f = open(path, args)), la llamada se bloquea hasta que todo el archivo se descarga en una carpeta de caché de destino de proceso en el disco. Todas las llamadas de lectura posteriores redirigen al archivo almacenado en caché, por lo que no se necesita ninguna interacción de almacenamiento. Si la memoria caché no tiene suficiente espacio disponible para ajustarse al archivo actual, el montaje intenta eliminar desde la memoria caché el archivo que lleva más tiempo sin usarse. En los casos en los que el archivo no cabe en el disco (con respecto a la configuración de caché), el entorno de ejecución de datos vuelve al modo de streaming.
| Ventajas | Inconvenientes |
|---|---|
| No hay dependencias de confiabilidad o rendimiento de almacenamiento después de abrir el archivo. | La llamada abierta se bloquea hasta que se descarga todo el archivo. |
| Lecturas aleatorias rápidas (lectura de fragmentos de lugares aleatorios del archivo). | El archivo completo se lee del almacenamiento, incluso cuando es posible que algunas partes del archivo no sean necesarias. |
Cuándo se debe usar
Cuando se necesitan lecturas aleatorias para archivos relativamente grandes que superan los 128 MB.
Uso
Establezca la variable de entorno DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED en false en el trabajo:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Montaje: Enumeración de archivos
Al trabajar con millones de archivos, evite una lista recursiva; por ejemplo, ls -R /mnt/dataset/folder/. Una lista recursiva desencadena muchas llamadas para enumerar el contenido del directorio primario. A continuación, requiere una llamada recursiva independiente para cada directorio dentro, en todos los niveles secundarios. Normalmente, Azure Storage solo permite devolver 5000 elementos por solicitud de lista única. Como resultado, una lista recurrente de un millón de carpetas que contienen 10 archivos cada una requiere 1,000,000 / 5000 + 1,000,000 = 1,000,200 solicitudes de almacenamiento. En comparación, 1000 carpetas con 10 000 archivos solo necesitarían 1001 solicitudes para almacenar una lista recursiva.
El montaje de Azure Machine Learning controla la lista de manera diferida. Por lo tanto, para enumerar muchos archivos pequeños, es mejor usar una llamada de biblioteca cliente iterativa (por ejemplo, os.scandir() en Python) en lugar de una llamada de biblioteca cliente que devuelva la lista completa (por ejemplo, os.listdir() en Python). Una llamada de biblioteca cliente iterativa devuelve un generador, lo que significa que no es necesario esperar hasta que se cargue toda la lista. Después, puede continuar más rápido.
En la tabla siguiente se compara el tiempo necesario para que las funciones os.scandir() y os.listdir() de Python muestren una carpeta que contenga aproximadamente 4 millones de archivos en una estructura plana:
| Métrica | os.scandir() |
os.listdir() |
|---|---|---|
| Tiempo para obtener la primera entrada (segundos) | 0,67 | 553,79 |
| Tiempo para obtener las primeras 50 000 entradas (segundos) | 9,56 | 562,73 |
| Tiempo para obtener todas las entradas (segundos) | 558,35 | 582,14 |
Configuración de montaje óptima para escenarios comunes
Para determinados escenarios comunes, se muestran las opciones de montaje óptimas que debe establecer en el trabajo de Azure Machine Learning.
Lectura secuencial de un archivo grande una vez (líneas de procesamiento en archivo .csv)
Incluya esta configuración de montaje en la sección environment_variables del trabajo de Azure Machine Learning:
Nota:
Para usar el proceso sin servidor, elimine compute="cpu-cluster", en este código.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Lectura de un archivo grande una vez desde varios subprocesos (procesamiento de archivos .csv con particiones en varios subprocesos)
Incluya esta configuración de montaje en la sección environment_variables del trabajo de Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Lectura de millones de archivos pequeños (imágenes) de varios subprocesos una vez (entrenamiento de una sola época en imágenes)
Incluya esta configuración de montaje en la sección environment_variables del trabajo de Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Lectura de millones de archivos pequeños (imágenes) de varios subprocesos varias veces (entrenamiento de varias épocas en imágenes)
Incluya esta configuración de montaje en la sección environment_variables del trabajo de Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Lectura de un archivo grande con búsquedas aleatorias (como servir la base de datos de archivos desde la carpeta montada)
Incluya esta configuración de montaje en la sección environment_variables del trabajo de Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Diagnóstico y resolución de cuellos de botella de carga de datos
Cuando un trabajo de Azure Machine Learning se ejecuta con datos, el mode de una entrada determina cómo se leen los bytes del almacenamiento y se almacenan en caché en el disco SSD local de destino de proceso. Para el modo de descarga, todos los datos se almacenan en caché en el disco antes de que el código de usuario inicie la ejecución. Por lo tanto, factores como
- el número de subprocesos paralelos
- el número de archivos
- tamaño de archivo
tienen un efecto en las velocidades máximas de descarga. Para el montaje, el código de usuario debe iniciarse para abrir archivos antes de que los datos empiecen a almacenarse en caché. La configuración de montaje diferente da lugar a diferentes comportamientos de lectura y almacenamiento en caché. Varios factores tienen un efecto en la velocidad que cargan los datos desde el almacenamiento:
- Situación de los datos que se van a calcular: las ubicaciones de destino de almacenamiento y proceso deben ser las mismas. Si el almacenamiento y el destino de proceso se ubican en regiones diferentes, el rendimiento se degrada porque los datos deben transferirse entre regiones. Para más información sobre cómo asegurarse de que los datos se colocan con proceso, consulte Colocación de datos con proceso.
- Tamaño del destino de proceso: los procesos pequeños tienen recuentos de núcleos inferiores (menos paralelismo) y ancho de banda de red esperado más pequeño en comparación con tamaños de proceso más grandes: ambos factores afectan al rendimiento de la carga de datos.
- Por ejemplo, si usa un tamaño de máquina virtual pequeño, como
Standard_D2_v2(2 núcleos, 1500 Mbps NIC) e intenta cargar 50 000 MB (50 GB) de datos, el mejor tiempo de carga de datos factible sería ~270 segundos (suponiendo que satura la NIC en el rendimiento de 187,5 MB/s). Por el contrario,Standard_D5_v2(16 núcleos, 12 000 Mbps) cargaría los mismos datos en ~33 segundos (suponiendo que satura la NIC a 1500 MB/s de rendimiento).
- Por ejemplo, si usa un tamaño de máquina virtual pequeño, como
- Nivel de almacenamiento: para la mayoría de los escenarios, incluidos los modelos de lenguaje grande (LLM), el almacenamiento estándar proporciona el mejor perfil de costo y rendimiento. Sin embargo, si tiene muchos archivos pequeños, Premium Storage ofrece un mejor perfil de costo y rendimiento. Para obtener más información, consulte Opciones de Azure Storage.
- Carga de almacenamiento: si la cuenta de almacenamiento está en alta carga (por ejemplo, muchos nodos de GPU en un clúster que solicitan datos), corre el riesgo de alcanzar la capacidad de salida del almacenamiento. Para obtener más información, consulte Carga de almacenamiento. Si tiene muchos archivos pequeños que necesitan acceso en paralelo, puede alcanzar los límites de solicitud de almacenamiento. Lea información actualizada sobre los límites de la capacidad de salida y las solicitudes de almacenamiento en Destinos de escalado para cuentas de almacenamiento estándar.
- Patrón de acceso a datos en el código de usuario: cuando se usa el modo de montaje, los datos se capturan en función de las acciones de apertura y lectura en el código. Por ejemplo, al leer secciones aleatorias de un archivo grande, la configuración predeterminada de captura previa de datos de montajes puede provocar descargas de bloques que no se leerán. Es posible que tenga que ajustar algunas opciones de configuración para alcanzar el rendimiento máximo. Para obtener más información, consulte Configuración de montaje óptima para escenarios comunes.
Uso de registros para diagnosticar problemas
Para acceder a los registros del entorno de ejecución de datos desde el trabajo:
- Seleccione la pestaña Salidas y registros en la página de trabajo.
- Seleccione la carpeta system_logs, seguida de la carpeta data_capability.
- Debería ver dos archivos de registro:
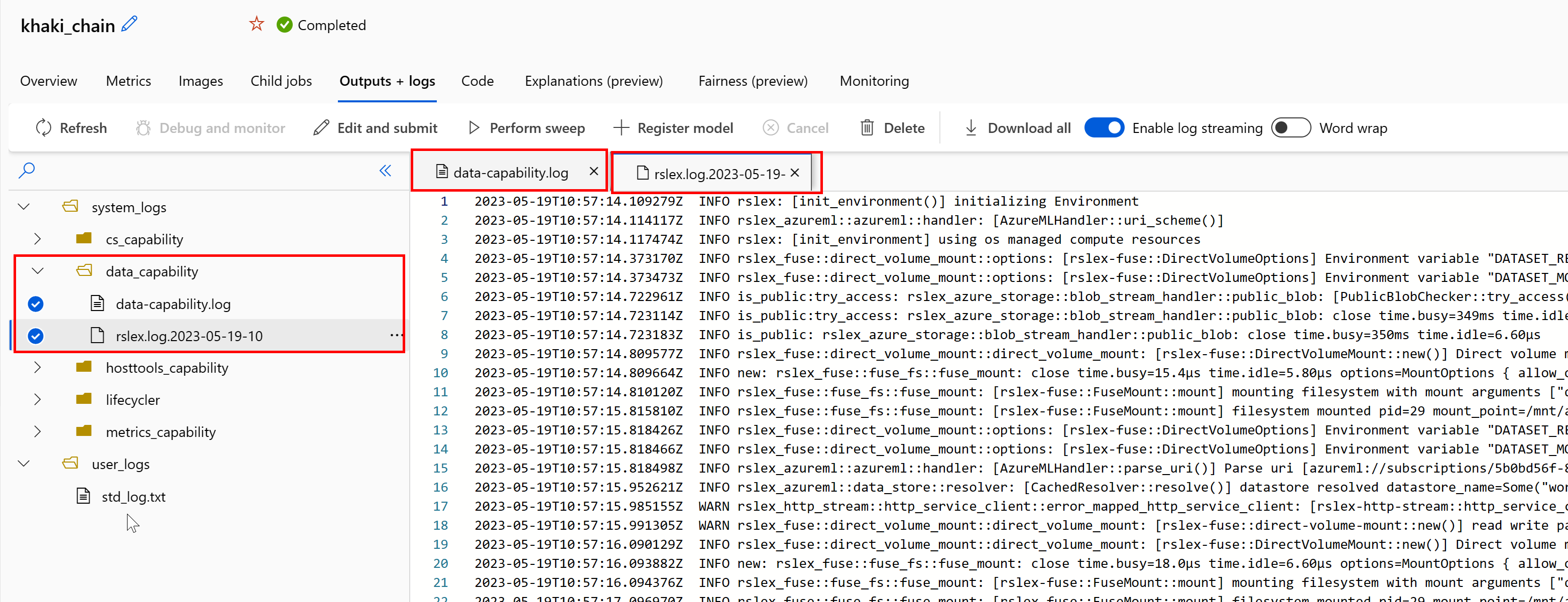

El archivo de registro data-capability.log muestra la información de alto nivel sobre el tiempo dedicado a las tareas clave de carga de datos. Por ejemplo, al descargar datos, el entorno de ejecución registra las horas de inicio y finalización de la actividad de descarga:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Si el rendimiento de descarga es una fracción del ancho de banda de red esperado para el tamaño de la máquina virtual, puede inspeccionar el archivo de registro rslex.log.<MARCA DE TIEMPO>. Este archivo contiene todo el registro específico del entorno de ejecución basado en Rust; por ejemplo, paralelización:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
El archivo rslex.log proporciona detalles sobre toda la copia de archivos, independientemente de si ha elegido o no los modos de montaje o descarga. También se describen los valores de configuración (variables de entorno) que se usan. Para iniciar la depuración, compruebe si ha establecido la configuración de montaje óptima para escenarios comunes.
Supervisión de Azure Storage
En Azure Portal, puede seleccionar la cuenta de almacenamiento y, a continuación, Métricas para ver las métricas de almacenamiento:

A continuación, trazará SuccessE2ELatency con SuccessServerLatency. Si las métricas muestran un valor de SuccessE2ELatency alto y un valor de SuccessServerLatency bajo, tiene subprocesos disponibles limitados o tiene pocos recursos, como CPU, memoria o ancho de banda de red, y debería hacer lo siguiente:
- Use la vista de supervisión en el Estudio de Azure Machine Learning para comprobar el uso de CPU y memoria del trabajo. Si tiene poca CPU y memoria, considere la posibilidad de aumentar el tamaño de máquina virtual de destino de proceso.
- Considere la posibilidad de aumentar
RSLEX_DOWNLOADER_THREADSsi está descargando y no usa la CPU y la memoria. Si usa montaje, debe aumentarDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTpara realizar más captura previa y aumentarDATASET_MOUNT_READ_THREADSpara obtener más subprocesos de lectura.
Si las métricas muestran una latencia baja de SuccessE2ELatency y SuccessServerLatency, pero el cliente experimenta una latencia alta, tiene un retraso en la solicitud de almacenamiento que alcanza el servicio. Debe comprobar lo siguiente:
- Si el número de subprocesos usados para el montaje o descarga (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) se establece demasiado bajo, en relación con el número de núcleos disponibles en el destino de proceso. Si la configuración es demasiado baja, aumente el número de subprocesos. - Si el número de reintentos para la descarga (
AZUREML_DATASET_HTTP_RETRY_COUNT) se establece demasiado alto. Si es así, disminuya el número de reintentos.
Supervisión del uso del disco durante un trabajo
Desde el Estudio de Azure Machine Learning, también puede supervisar la E/S de disco de destino de proceso y el uso durante la ejecución del trabajo. Vaya al trabajo y seleccione la pestaña Supervisión. Esta pestaña proporciona información sobre los recursos del trabajo de forma gradual cada 30 días. Por ejemplo:

Nota:
La supervisión de trabajos solo admite los recursos de proceso que administra Azure Machine Learning. Los trabajos con un tiempo de ejecución inferior a 5 minutos no tendrán suficientes datos para rellenar esta vista.
El runtime de datos de Azure Machine Learning no usa los últimos RESERVED_FREE_DISK_SPACE bytes de espacio en disco para mantener el proceso correcto (el valor predeterminado es 150MB). Si el disco está lleno, el código está escribiendo archivos en el disco sin declarar los archivos como salida. Por lo tanto, compruebe el código para asegurarse de que los datos no se escriben erróneamente en el disco temporal. Si debe escribir archivos en un disco temporal y ese recurso se está llenando, considere lo siguiente:
- Aumentar el tamaño de la máquina virtual a uno que tenga un disco temporal mayor.
- Establecer un TTL en los datos almacenados en caché (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) para purgar los datos del disco.
Colocación de datos con proceso
Precaución
Si el almacenamiento y el proceso están en regiones diferentes, el rendimiento se degrada porque los datos deben transferirse entre regiones. Esto aumenta los costos. Asegúrese de que la cuenta de almacenamiento y los recursos de proceso están en la misma región.
Si los datos y el área de trabajo de Azure Machine Learning se almacenan en regiones diferentes, se recomienda copiar los datos en una cuenta de almacenamiento de la misma región con la utilidad azcopy. AzCopy usa API de servidor a servidor, por lo que los datos se copian directamente entre servidores de almacenamiento. En estas operaciones de copia no se usa el ancho de banda de red del equipo. Puede aumentar el rendimiento de estas operaciones con la variable de entorno AZCOPY_CONCURRENCY_VALUE. Para más información, consulte Aumento de la simultaneidad.
Carga de almacenamiento
Una sola cuenta de almacenamiento se puede limitar cuando se produce una carga elevada, cuando:
- El trabajo usa muchos nodos de GPU.
- La cuenta de almacenamiento tiene muchos usuarios o aplicaciones simultáneos que acceden a los datos a medida que ejecuta el trabajo.
En esta sección se muestran los cálculos para determinar si la limitación puede convertirse en un problema para la carga de trabajo y cómo abordar las reducciones de la limitación.
Cálculo de los límites de ancho de banda
Una cuenta de Azure Storage tiene un límite de salida predeterminado de 120 Gbit/s. Las máquinas virtuales de Azure tienen diferentes anchos de banda de red, que tienen un efecto en el número teórico de nodos de proceso necesarios para alcanzar la capacidad de salida máxima predeterminada del almacenamiento:
| Size | Tarjeta GPU | vCPU | Memoria: GiB | GiB de almacenamiento temporal (SSD) | Número de tarjetas GPU | Memoria de GPU: GiB | Ancho de banda de red esperado (Gbit/s) | Valor máximo predeterminado de salida de la cuenta de almacenamiento (Gbit/s)* | Número de nodos para alcanzar la capacidad de salida predeterminada |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Ambas SKU A100/V100 tienen un ancho de banda de red máximo por nodo de 24 Gbit/s. Si cada nodo que lee datos de una sola cuenta puede leer cerca del máximo teórico de 24 Gbit/s, la capacidad de salida se produciría con cinco nodos. El uso de seis o más nodos de proceso empezaría a degradar el rendimiento de los datos en todos los nodos.
Importante
Si la carga de trabajo necesita más de 6 nodos de A100/V100, o cree que excederá la capacidad de salida predeterminada del almacenamiento (120 Gbit/s), póngase en contacto con el soporte técnico (mediante Azure Portal) y solicite un aumento del límite de salida de almacenamiento.
Escalado en varias cuentas de almacenamiento
Es posible que supere la capacidad máxima de salida del almacenamiento o que alcance los límites de velocidad de solicitud. Si se producen estos problemas, se recomienda ponerse en contacto con el soporte técnico en primer lugar para aumentar estos límites en la cuenta de almacenamiento.
Si no puede aumentar la capacidad de salida máxima o el límite de velocidad de solicitudes, considere la posibilidad de replicar los datos en varias cuentas de almacenamiento. Copie los datos en varias cuentas con Azure Data Factory, Explorador de Azure Storage o azcopy, y monte todas las cuentas del trabajo de entrenamiento. Solo se descargan los datos a los que se accede en un montaje. Por lo tanto, el código de entrenamiento puede leer RANK desde la variable de entorno para elegir desde cuál de los varios montajes de entradas se va a leer. La definición del trabajo pasa una lista de cuentas de almacenamiento:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Después, el código de Python de entrenamiento puede usar RANK para obtener la cuenta de almacenamiento específica de ese nodo:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Problema relativo a muchos archivos pequeños
La lectura de archivos del almacenamiento implica realizar solicitudes para cada archivo. El recuento de solicitudes por archivo varía en función de los tamaños de archivo y de la configuración del software que controla las lecturas del archivo.
Los archivos suelen leerse en bloques de tamaño de 1 a 4 MB. Los archivos más pequeños que un bloque se leen con una sola solicitud (GET file.jpg 0-4MB) y los archivos mayores que un bloque tienen una solicitud realizada por bloque (GET file.jpg 0-4MB, GET file.jpg 4-8MB). En esta tabla se muestra que los archivos menores que un bloque de 4 MB dan lugar a más solicitudes de almacenamiento en comparación con los archivos más grandes:
| Número de archivos | Tamaño de archivo | Tamaño total de datos | Tamaño de bloque | Número de solicitudes de almacenamiento |
|---|---|---|---|---|
| 2 000 000 | 500 KB | 1 TB | 4 MB | 2 000 000 |
| 1,000 | 1 GB | 1 TB | 4 MB | 256 000 |
En el caso de los archivos pequeños, el intervalo de latencia implica principalmente el control de las solicitudes al almacenamiento, en lugar de las transferencias de datos. Por lo tanto, ofrecemos estas recomendaciones para aumentar el tamaño del archivo:
- En el caso de datos no estructurados (imágenes, texto, vídeo, etc.), archive los archivos pequeños (.zip/.tar) para almacenarlos como un archivo más grande que se puede leer en varios fragmentos. Estos archivos archivados más grandes se pueden abrir en el recurso de proceso y DataPipes de archivos PyTorch pueden extraer los archivos más pequeños.
- Para los datos estructurados (CSV, Parquet, etc.), examine el proceso ETL para asegurarse de que fusiona archivos para aumentar el tamaño. Spark tiene métodos
repartition()ycoalesce()para ayudar a aumentar los tamaños de archivo.
Si no puede aumentar los tamaños de archivo, explore las opciones de Azure Storage.
Opciones de Azure Storage
Azure Storage ofrece dos niveles: estándar y premium:
| Storage | Escenario |
|---|---|
| Azure Blob: Estándar (HDD) | Los datos se estructuran en blobs más grandes: imágenes, vídeo, etc. |
| Azure Blob: Premium (SSD) | Altas tasas de transacción, objetos más pequeños o requisitos de latencia de almacenamiento constantemente bajos. |
Sugerencia
Para "muchos" archivos pequeños (magnitud de KB), se recomienda usar Premium (SSD) porque el costo de almacenamiento es menor que los costos de ejecución del proceso de GPU.
Lectura de recursos de datos V1
En esta sección se indica cómo leer las entidades de datos FileDataset y TabularDataset V1 en un trabajo V2.
Lectura de FileDataset
En el objeto Input, especifique type como AssetTypes.MLTABLE y mode como InputOutputModes.EVAL_MOUNT:
Nota:
Para usar el proceso sin servidor, elimine compute="cpu-cluster", en este código.
Para más información sobre el objeto MLClient, las opciones de inicialización de objetos MLClient y cómo conectarse a un área de trabajo, consulte Conexión a un área de trabajo.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Lectura de TabularDataset
En el objeto Input, especifique type como AssetTypes.MLTABLE y mode como InputOutputModes.DIRECT:
Nota:
Para usar el proceso sin servidor, elimine compute="cpu-cluster", en este código.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint
Pasos siguientes
- Entrenamiento de modelos
- Tutorial: Crear canalizaciones ML de producción con Python SDK v2
- Obtenga más información sobre los Datos en Azure Machine Learning.