Solución de problemas de latencia de replicación en Azure Database for MySQL: servidor flexible
SE APLICA A: Azure Database for MySQL: servidor único Azure Database for MySQL: servidor flexible
Azure Database for MySQL: servidor único Azure Database for MySQL: servidor flexible
Importante
El servidor único de Azure Database for MySQL está en la ruta de retirada. Se recomienda encarecidamente actualizar al servidor flexible de Azure Database for MySQL. Para más información sobre la migración al servidor flexible de Azure Database for MySQL, consulte ¿Qué ocurre con Azure Database for MySQL con servidor único?
Nota:
En este artículo se hace referencia a un término que Microsoft ya no usa. Cuando se elimine el término del software, se eliminará también de este artículo.
La característica de réplica de lectura permite replicar datos de un servidor de Azure Database for MySQL en un servidor de réplica de solo lectura. Puede escalar horizontalmente las cargas de trabajo mediante el enrutamiento de consultas de lectura e informes desde la aplicación hacia los servidores de réplica. Esta configuración reduce la presión en el servidor de origen y mejora el rendimiento general y la latencia de la aplicación a medida que se escala.
Las réplicas se actualizan asincrónicamente con la tecnología de replicación basada en la posición de los archivos de registros binarios nativos (binlog) del motor de MySQL. Para obtener más información, consulte Información general sobre la configuración de la replicación basada en la posición de los archivos binlog de MySQL.
El retraso en la replicación de las réplicas de lectura secundarias depende de varios factores. Estos factores incluyen, entre otros:
- Latencia de red.
- Volumen de transacciones en el servidor de origen.
- Nivel de proceso del servidor de origen y el de réplica de lectura secundario.
- Consultas que se ejecutan en el servidor de origen y en el secundario.
En este artículo, obtendrá información sobre cómo solucionar problemas de latencia de replicación en Azure Database for MySQL. También obtendrá una mejor idea de algunas causas comunes de una mayor latencia de replicación en los servidores de réplica.
Nota:
Este artículo contiene referencias al término esclavo, un término que Microsoft ya no usa. Cuando se elimine el término del software, se eliminará también de este artículo.
Conceptos de replicación
Cuando un registro binario está habilitado, el servidor de origen escribe las transacciones confirmadas en el registro binario. Este registro binario se usa para la replicación. Está activado de manera predeterminada en todos los servidores recién aprovisionados que admiten hasta 16 TB de almacenamiento. En los servidores de réplica, se ejecutan dos subprocesos en cada servidor de réplica. Uno es el subproceso de E/S, y el otro es el subproceso de SQL:
- El subproceso de E/S se conecta al servidor de origen y solicita los registros binarios actualizados. Este subproceso recibe las actualizaciones del registro binario. Esas actualizaciones se guardan en un servidor de réplicas, en un registro local denominado registro de retransmisión.
- El subproceso de SQL lee el registro de retransmisión y, a continuación, aplica los cambios de datos en los servidores de réplica.
Supervisar la latencia de replicación
Azure Database for MySQL proporciona la métrica de retraso de replicación en segundos en Azure Monitor. Esta métrica está disponible solo en los servidores de réplica de lectura. Se calcula con la métrica seconds_behind_master que está disponible en MySQL.
Para comprender la causa del aumento de la latencia de replicación, conéctese al servidor de réplica mediante MySQL Workbench o Azure Cloud Shell. Después, ejecute el siguiente comando.
Nota
En su código, reemplace los valores de ejemplo por el nombre de su servidor de réplica y el nombre de usuario de su administrador. El nombre de usuario del administrador requiere el valor @\<servername> para Azure Database for MySQL.
mysql --host=myreplicademoserver.mysql.database.azure.com --user=myadmin@mydemoserver -p
Este es el aspecto final en el terminal de Cloud Shell:
Requesting a Cloud Shell.Succeeded.
Connecting terminal...
Welcome to Azure Cloud Shell
Type "az" to use Azure CLI
Type "help" to learn about Cloud Shell
user@Azure:~$mysql -h myreplicademoserver.mysql.database.azure.com -u myadmin@mydemoserver -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64796
Server version: 5.6.42.0 Source distribution
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
En el mismo terminal de Cloud Shell, ejecute el siguiente comando:
mysql> SHOW SLAVE STATUS;
Esta es una salida típica:
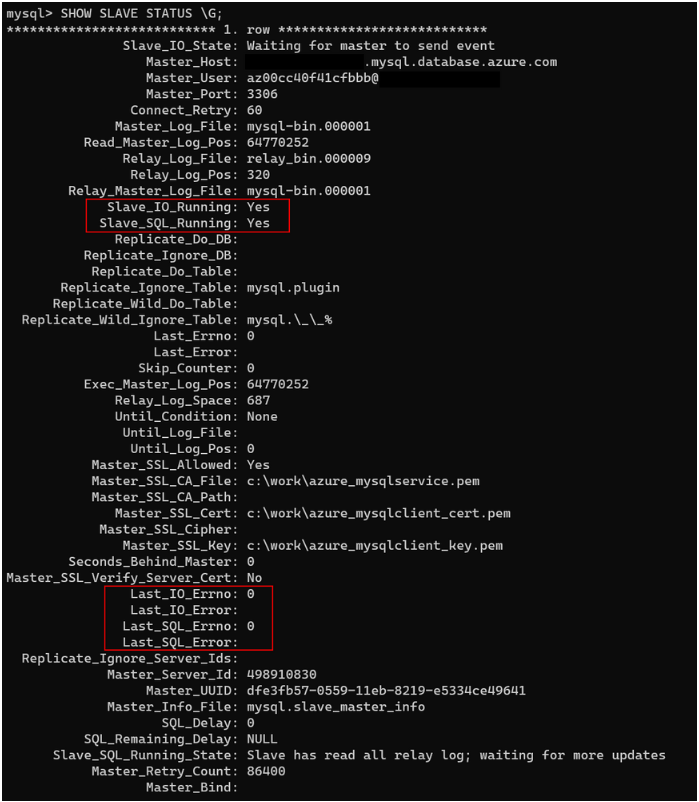
La salida contiene una gran cantidad de información. Normalmente, solo necesita centrarse en las filas que se describen en la tabla siguiente.
| Métrica | Descripción |
|---|---|
| Slave_IO_State | Representa el estado actual del subproceso de E/S. Normalmente, el estado es "Esperando a que el maestro envíe el evento" si se está sincronizando el servidor de origen (maestro). Un estado similar a "Conectando con el maestro" indica que la réplica perdió la conexión con el servidor de origen. Asegúrese de que el servidor de origen se está ejecutando, o compruebe si un firewall está bloqueando la conexión. |
| Master_Log_File | Representa el archivo de registro binario en el que está escribiendo el servidor de origen. |
| Read_Master_Log_Pos | Indica en qué parte del archivo de registro binario escribe el servidor de origen. |
| Relay_Master_Log_File | Representa el archivo de registro binario que el servidor de réplica lee del servidor de origen. |
| Slave_IO_Running | Indica si el subproceso de E/S se está ejecutando. El valor debería ser Yes. Si el valor es NO, probablemente la replicación se ha interrumpido. |
| Slave_SQL_Running | Indica si se está ejecutando el subproceso de SQL. El valor debería ser Yes. Si el valor es NO, probablemente la replicación se ha interrumpido. |
| Exec_Master_Log_Pos | Indica la posición del archivo Relay_Master_Log_File que aplica la réplica. Si hay latencia, entonces esta secuencia de posición debe ser menor que Read_Master_Log_Pos. |
| Relay_Log_Space | Indica el tamaño total combinado de todos los archivos de registro de retransmisión existentes. Para consultar el tamaño del límite superior, haga una consulta de SHOW GLOBAL VARIABLES, como relay_log_space_limit. |
| Seconds_Behind_Master | Muestra la latencia de replicación en segundos. |
| Last_IO_Errno | Muestra el código de error del subproceso de E/S, si existe. Para obtener más información acerca de estos códigos, consulte la referencia del mensaje de error de MySQL Server. |
| Last_IO_Error | Muestra el mensaje de error del subproceso de E/S, si existe. |
| Last_SQL_Errno | Muestra el código de error del subproceso de SQL, si existe. Para obtener más información acerca de estos códigos, consulte la referencia del mensaje de error de MySQL Server. |
| Last_SQL_Error | Muestra el mensaje de error del subproceso de SQL, si existe. |
| Slave_SQL_Running_State | Indica el estado actual del subproceso de SQL. En este estado, System lock es normal. También es normal ver el estado Waiting for dependent transaction to commit. Este estado indica que la réplica está esperando a que otros subprocesos de trabajo de SQL actualicen las transacciones confirmadas. |
Si Slave_IO_Running tiene el valor Yes y Slave_SQL_Running tiene el valor Yes, la replicación se ejecutará correctamente.
A continuación, compruebe el elemento Last_IO_Errno, Last_IO_Error, Last_SQL_Errno y Last_SQL_Error. Estos campos muestran el número y el mensaje del error más reciente que hizo que se detuviera el subproceso de SQL. Un número de error 0 y un mensaje vacío significan que no hay ningún error. Investigue todos los valores de error distintos de cero al comprobar el código de error en la referencia de mensajes de error del servidor MySQL.
Escenarios comunes de latencia de replicación elevada
En las siguientes secciones se describen los escenarios en los que es frecuente una alta latencia de replicación.
Latencia de red o consumo elevado de CPU en el servidor de origen
Si mira los valores siguientes, la latencia de replicación probablemente se debe a la alta latencia de red o un alto consumo de CPU en el servidor de origen.
Slave_IO_State: Waiting for master to send event
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller than Master_Log_File, e.g. mysql-bin.00010
En este caso, el subproceso de E/S se está ejecutando y está esperando al servidor de origen. El servidor de origen ya ha escrito en el archivo de registro binario número 20. La réplica solo ha recibido hasta el archivo número 10. Los principales factores de la latencia de replicación elevada en este escenario son la velocidad de red o el uso intensivo de la CPU en el servidor de origen.
En Azure, la latencia de red dentro de una región normalmente puede medirse en milisegundos. Entre regiones, la latencia oscila entre los milisegundos y los segundos.
En la mayoría de los casos, el retraso de la conexión entre los subprocesos de E/S y el servidor de origen se debe a un uso elevado de la CPU en el servidor de origen. Los subprocesos de E/S se procesan lentamente. Puede detectar este problema al usar Azure Monitor para comprobar el uso de la CPU y el número de conexiones simultáneas en el servidor de origen.
Si no ve un uso intensivo de la CPU en el servidor de origen, el problema podría ser la latencia de red. Si la latencia de red es repentinamente alta, consulte la página de estado de Azure para saber de problemas conocidos o interrupciones.
Ráfagas intensas de transacciones en el servidor de origen
Si ve los valores siguientes, una ráfaga intensa de transacciones en el servidor de origen probablemente sea la causa de la latencia de la replicación.
Slave_IO_State: Waiting for the slave SQL thread to free enough relay log space
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller then Master_Log_File, e.g. mysql-bin.00010
La salida muestra que la réplica puede recuperar el registro binario detrás del servidor de origen. No obstante, el subproceso de E/S de réplica indica que el espacio del registro de retransmisión ya está lleno.
La velocidad de la red no está causando el retraso. La réplica está intentando actualizarse, pero el tamaño del registro binario actualizado supera el límite máximo del espacio para el registro de retransmisión.
Para solucionar este problema, habilite el registro de consultas lento en el servidor de origen. Use los registros de consultas lentos para identificar las transacciones de larga duración en el servidor de origen. Después, ajuste las consultas identificadas para reducir la latencia en el servidor.
La latencia de replicación de este tipo normalmente se debe a la carga de datos en el servidor de origen. Cuando los servidores de origen tienen cargas de datos semanales o mensuales, lamentablemente la latencia de replicación no se puede evitar. Los servidores de réplica acaban de actualizarse después de que finalizara la carga de datos en el servidor de origen.
Lentitud en el servidor de réplicas
Si observa los valores siguientes, el problema podría ser el servidor de réplicas.
Slave_IO_State: Waiting for master to send event
Master_Log_File: The binary log file sequence equals to Relay_Master_Log_File, e.g. mysql-bin.000191
Read_Master_Log_Pos: The position of master server written to the above file is larger than Relay_Log_Pos, e.g. 103978138
Relay_Master_Log_File: mysql-bin.000191
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Exec_Master_Log_Pos: The position of slave reads from master binary log file is smaller than Read_Master_Log_Pos, e.g. 13468882
Seconds_Behind_Master: There is latency and the value here is greater than 0
En este escenario, la salida muestra que tanto el subproceso de E/S como el subproceso de SQL se ejecutan correctamente. La réplica lee el mismo archivo de registro binario que escribe el servidor de origen. Sin embargo, cierta latencia en el servidor de réplicas refleja la misma transacción del servidor de origen.
En las secciones siguientes se describen las causas comunes para este tipo de latencia.
No hay ninguna clave principal o única en una tabla
Azure Database for MySQL utiliza la replicación basada en filas. El servidor de origen escribe eventos en el registro binario y registra los cambios en filas individuales de la tabla. A continuación, el subproceso de SQL replica esos cambios en las filas correspondientes de la tabla que se encuentra en el servidor de réplicas. Cuando una tabla no tiene una clave principal o una clave única, el subproceso de SQL examina todas las filas de la tabla de destino para aplicar los cambios. Este análisis puede generar latencia de replicación.
En MySQL, la clave principal es un índice asociado que garantiza un rendimiento de consultas rápido, debido a que no puede incluir valores NULL. Si usa el motor de almacenamiento de InnoDB, los datos de la tabla se organizan físicamente para realizar búsquedas y ordenaciones ultrarrápidas en función de la clave principal.
Se recomienda agregar una clave principal en las tablas del servidor de origen antes de crear el servidor de réplicas. Agregue las claves principales en el servidor de origen y, a continuación, vuelva a crear las réplicas de lectura para que pueda mejorar la latencia de replicación.
Use la siguiente consulta para averiguar qué tablas no tienen una clave principal en el servidor de origen:
select tab.table_schema as database_name, tab.table_name
from information_schema.tables tab left join
information_schema.table_constraints tco
on tab.table_schema = tco.table_schema
and tab.table_name = tco.table_name
and tco.constraint_type = 'PRIMARY KEY'
where tco.constraint_type is null
and tab.table_schema not in('mysql', 'information_schema', 'performance_schema', 'sys')
and tab.table_type = 'BASE TABLE'
order by tab.table_schema, tab.table_name;
Consultas de larga duración en el servidor de réplicas
La carga de trabajo en el servidor de réplicas puede hacer que el subproceso de SQL se retrase en relación con el subproceso de E/S. Las consultas de larga duración en el servidor de réplicas son una de las causas comunes de la latencia de replicación elevada. Para solucionar este problema, habilite el registro de consultas lento en el servidor de réplicas.
Las consultas lentas pueden aumentar el consumo de recursos o ralentizar el servidor, por lo que la réplica no puede ponerse al día con el servidor de origen. En este escenario, ajuste las consultas lentas. Las consultas más rápidas evitan los bloqueos del subproceso de SQL y mejoran significativamente la latencia de replicación.
Consultas DDL en el servidor de origen
En el servidor de origen, un comando de lenguaje de definición de datos (DDL) como ALTER TABLE puede tardar mucho. Mientras se ejecuta el comando DDL, en el servidor de origen se pueden ejecutar paralelamente miles de consultas.
Cuando el comando DDL se replica, para garantizar la coherencia de la base de datos, el motor de MySQL ejecuta DDL en un único subproceso de replicación. Durante esta tarea, todas las demás consultas replicadas se bloquean y deben esperar hasta que finalice la operación DDL en el servidor de réplicas. Incluso las operaciones de DDL en línea generan este retraso. Las operaciones de DDL aumentan la latencia de replicación.
Si habilitó la opción de registro de consultas lento en el servidor de origen, puede detectar este problema de latencia al consultar un comando DDL que se haya ejecutado en el servidor de origen. A través de la eliminación, cambio de nombre y creación de índices, puede usar el algoritmo INPLACE para la instrucción ALTER TABLE. Quizá tenga que copiar los datos de la tabla y volver a generarla.
Normalmente, se admiten DML simultáneos para el algoritmo INPLACE. No obstante, puede usar brevemente un bloqueo de metadatos exclusivo en la tabla al preparar y ejecutar la operación. Por lo tanto, para la instrucción CREATE INDEX, puede usar las cláusulas ALGORITHM y LOCK para influir en el método para la copia de tablas y el nivel de simultaneidad para la lectura y escritura. Aún puede evitar las operaciones DML al agregar un índice FULLTEXT o SPATIAL.
En el ejemplo siguiente se crea un índice mediante el uso de las cláusulas ALGORITHM y LOCK.
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Desafortunadamente, para una instrucción DDL que requiere un bloqueo, no es posible evitar la latencia de replicación. Para reducir sus posibles efectos, realice este tipo de operaciones DDL durante las horas de poca actividad; por ejemplo, durante la noche.
Servidor de réplicas cambiado a una versión anterior
En Azure Database for MySQL, las réplicas de lectura usan la misma configuración que el servidor de origen. Puede cambiar la configuración del servidor de réplicas después de crearlo.
Si el servidor de réplicas se va a cambiar a una versión anterior, la carga de trabajo puede consumir más recursos que, a su vez, pueden provocar la latencia de replicación. Para detectar este problema, use Azure Monitor y compruebe el consumo de CPU y memoria del servidor de réplicas.
En este escenario, se recomienda que mantenga la configuración del servidor de réplicas con valores iguales o superiores a los valores del servidor de origen. Esta configuración permite que la réplica se mantenga al día con el servidor de origen.
Mejora de la latencia de replicación al ajustar los parámetros del servidor de origen
En Azure Database for MySQL, la replicación está optimizada de manera predeterminada para ejecutarse con subprocesos paralelos en las réplicas. Cuando las cargas de trabajo de simultaneidad elevada en el servidor de origen hacen que el servidor de réplicas se retrase, puede mejorar la latencia de replicación al configurar el parámetro binlog_group_commit_sync_delay en el servidor de origen.
El parámetro binlog_group_commit_sync_delay controla cuántos microsegundos espera la confirmación de registro binario antes de sincronizar el archivo de registro binario. La ventaja de este parámetro es que, en lugar de aplicar inmediatamente todas las transacciones confirmadas, el servidor de origen envía las actualizaciones del registro binario de forma masiva. Este retraso reduce las operaciones de E/S en la réplica y ayuda a mejorar el rendimiento.
Podría resultar útil establecer el parámetro binlog_group_commit_sync_delay en un valor de 1000, aproximadamente. A continuación, supervise la latencia de replicación. Establezca este parámetro con precaución y úselo solo para las cargas de trabajo de simultaneidad alta.
Importante
En el servidor réplica, se recomienda que el parámetro binlog_group_commit_sync_delay sea 0. Esto se recomienda porque, a diferencia de lo que ocurre con el servidor de origen, el servidor de réplica no tendrá una alta simultaneidad, y el aumento del valor de binlog_group_commit_sync_delay en el servidor de réplica podría provocar involuntariamente un retraso en la replicación.
En el caso de las cargas de trabajo con simultaneidad baja que incluyen muchas transacciones singleton, el valor binlog_group_commit_sync_delay puede aumentar la latencia. La latencia puede aumentar porque el subproceso de E/S espera las actualizaciones del registro binario masivas, aunque solo se confirmen algunas transacciones.
Opciones avanzadas de solución de problemas
Si el comando show slave status no proporciona suficiente información para solucionar problemas de latencia de replicación, pruebe a ver estas opciones adicionales para saber qué procesos están activos o en espera.
Visualizar tabla de subprocesos
La tabla performance_schema.threads muestra el estado del proceso. Un proceso con el estado En espera de bloqueo lock_type indica que hay un bloqueo en una de las tablas, lo que impide que el subproceso de replicación actualice la tabla.
SELECT name, processlist_state, processlist_time FROM performance_schema.threads WHERE name LIKE '%slave%';
Para obtener más información, consulte Estados generales de subprocesos.
Visualizar la tabla replication_connection_status
La tabla performance_schema.replication_connection_status muestra el estado actual del subproceso de E/S de replicación que controla la conexión de la réplica con el origen y cambia con más frecuencia. La tabla contiene valores que varían durante la conexión.
SELECT * FROM performance_schema.replication_connection_status;
Visualizar la tabla replication_applier_status_by_worker
En la tabla performance_schema.replication_applier_status_by_worker se muestra el estado de los subprocesos de trabajo. Última transacción vista junto con el último número de error y el mensaje, que le ayudan a encontrar la transacción que tiene un problema e identificar la causa principal.
Puede ejecutar los siguientes comandos en la replicación de datos de entrada para omitir errores o transacciones:
az_replication_skip_counter
o
az_replication_skip_gtid_transaction
SELECT * FROM performance_schema.replication_applier_status_by_worker;
Ver la instrucción SHOW RELAYLOG EVENTS
La instrucción show relaylog events muestra los eventos en el registro de retransmisión de una réplica.
· Para la replicación basada en GITD (réplica de lectura), la instrucción muestra la transacción GTID y el archivo binlog y su posición; puede usar mysqlbinlog para obtener el contenido y las instrucciones que se ejecutan. · Para la replicación de posición binlog de MySQL (que se usa para la replicación de datos de entrada), muestra las instrucciones que se ejecutan, lo que le ayudará a saber en qué tabla se están ejecutando las transacciones.
Comprobar el monitor estándar de InnoDB y la salida del monitor de bloqueo
También puede intentar comprobar el monitor estándar de InnoDB y la salida del monitor de bloqueo para ayudar a resolver bloqueos e interbloqueos y minimizar el retraso de la replicación. El monitor de bloqueo es el mismo que el monitor estándar, excepto por el hecho de que incluye información de bloqueo adicional. Para ver esta información adicional de bloqueo e interbloqueo, ejecute el comando show engine innodb status\G.
Pasos siguientes
Consulte la Información general sobre la replicación de binlog de MySQL.