Extracción de texto e información de las imágenes en enriquecimiento con IA
A través del enriquecimiento con IA, Azure AI Search proporciona varias opciones para crear y extraer texto que permite búsquedas de imágenes, entre las que se incluyen:
- OCR para el reconocimiento óptico de caracteres de texto y dígitos
- Análisis de imágenes que describe imágenes a través de características visuales
- Aptitudes personalizadas para invocar cualquier procesamiento de imágenes externo que quiera proporcionar
A través de OCR, puede extraer texto de fotos o imágenes que contengan texto alfanumérico, como la palabra "STOP" en un signo de detención. A través del análisis de imágenes, puede generar una representación en texto de una imagen, por ejemplo, "diente de león" para una foto de un diente de león o el color "amarillo". También puede extraer metadatos sobre la imagen, como su tamaño.
Este artículo explica los fundamentos del trabajo con imágenes, y también describe varios escenarios comunes, como el trabajo con imágenes incrustadas, habilidades personalizadas y la superposición de visualizaciones sobre imágenes originales.
Para trabajar con contenido de imagen en un conjunto de aptitudes, necesitará lo siguiente:
- Archivos de origen con imágenes
- Un indexador de búsqueda configurado para acciones en imágenes
- Un conjunto de aptitudes con aptitudes integradas o personalizadas que invocan OCR o análisis de imágenes
- Un índice de búsqueda con campos para recibir la salida de texto analizada, además de asignaciones de campos de salida en el indexador que establecen la asociación.
Opcionalmente, puede definir proyecciones para aceptar la salida analizada de imágenes en un almacén de conocimiento para escenarios de minería de datos.
Configuración de archivos de origen
El procesamiento de imágenes está controlado por indexadores, lo que significa que las entradas sin procesar deben estar en un origen de datos admitido.
- El análisis de imágenes admite JPEG, PNG, GIF y BMP
- OCR admite JPEG, PNG, GIF, BMP y TIF
Las imágenes son archivos binarios independientes o se encuentran incrustadas en documentos (PDF, RTF y archivos de aplicaciones de Microsoft). Un máximo de 1000 imágenes se puede extraer de un documento determinado. Si hay más de 1000 imágenes en un documento, se extraen los primeros 1000 y, a continuación, se genera una advertencia.
Azure Blob Storage es el almacenamiento usado con más frecuencia para el procesamiento de imágenes en Azure AI Search. Hay tres tareas principales relacionadas con la recuperación de imágenes de un contenedor de blobs:
Habilite el acceso al contenido del contenedor. Si usa un cadena de conexión de acceso completo que incluye una clave, la clave le proporciona permiso para acceder al contenido. Como alternativa, puede autenticarse mediante Microsoft Entra ID o conectarse como un servicio de confianza.
Cree un origen de datos de tipo "azureblob" que se conecte al contenedor de blobs que almacena los archivos.
Revise los límites del nivel de servicio para asegurarse de que los datos de origen no superen el tamaño máximo y los límites de cantidad para indexadores y enriquecimiento.
Configuración de indexadores para el procesamiento de imágenes
Una vez configurados los archivos de origen, habilite la normalización de imágenes estableciendo el parámetro en la configuración del imageAction indexador. La normalización de imágenes ayuda a que las imágenes sean más uniformes para el procesamiento descendente. Algunas de las operaciones de la normalización de imágenes son:
- Las imágenes grandes se cambian de tamaño a un alto máximo y ancho para que sean uniformes.
- En el caso de las imágenes que tienen metadatos sobre la orientación, la rotación de la imagen se ajusta para la carga vertical.
Los ajustes de metadatos se capturan en un tipo complejo que se crea para cada imagen. No se puede rechazar el requisito de normalización de imágenes. Las aptitudes que recorren en iteración imágenes, como OCR y análisis de imágenes, esperan imágenes normalizadas.
Cree o actualice un indexador para establecer las propiedades de configuración:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Establezca
dataToExtractencontentAndMetadata(obligatorio).Compruebe que está
parsingModeestablecido en predeterminado (obligatorio).Este parámetro determina la granularidad de los documentos de búsqueda creados en el índice. El modo predeterminado configura una correspondencia uno a uno para que un blob de como resultado un documento de búsqueda. Si los documentos son grandes o si las aptitudes requieren fragmentos de texto más pequeños, puede agregar la aptitud de división de texto, que subdivide un documento en paginación con fines de procesamiento. Pero en escenarios de búsqueda, se requiere un blob por documento si el enriquecimiento incluye el procesamiento de imágenes.
Establezca
imageActionpara habilitar el nodo normalized_images en un árbol de enriquecimiento (obligatorio):generateNormalizedImagespara generar una matriz de imágenes normalizadas como parte del descifrado de documentos.generateNormalizedImagePerPage(solo se aplica a PDF) para generar una matriz de imágenes normalizadas donde cada página del PDF se representa en una imagen de salida. En el caso de los archivos que no son PDF, el comportamiento de este parámetro es similar a no haber establecido "generateNormalizedImages". Sin embargo, tenga en cuenta que establecer "generateNormalizedImagePerPage" puede hacer que la operación de indexación sea menos eficaz por diseño (especialmente para documentos grandes), ya que varias imágenes tendrían que generarse.
Opcionalmente, ajuste el ancho o alto de las imágenes normalizadas generadas:
normalizedImageMaxWidth(en píxeles). El valor predeterminado es 2000. El valor máximo es 10 000.normalizedImageMaxHeight(en píxeles). El valor predeterminado es 2000. El valor máximo es 10 000.
El valor predeterminado es de 2000 píxeles para el ancho máximo de las imágenes normalizadas, y la altura se basa en los tamaños máximos admitidos por la habilidad de OCR y la habilidad de análisis de imágenes. La aptitud de OCR admite un ancho y un alto máximos de 4200 para los idiomas distintos del inglés y 10 000 para el inglés. Si aumenta los límites máximos, el procesamiento podría generar un error en imágenes de mayor tamaño en función de la definición del conjunto de aptitudes y del idioma de los documentos.
Opcionalmente, establezca criterios de tipo de archivo si la carga de trabajo tiene como destino un tipo de archivo específico. La configuración del indexador de blobs incluye opciones de inclusión y exclusión de archivos. Puede filtrar los archivos que no quiera.
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
Acerca de las imágenes normalizadas
Cuando imageAction se establece en un valor distinto de "none", el nuevo campo normalized_images contiene una matriz de imágenes. Cada imagen es un tipo complejo que tiene los siguientes miembros:
| Miembro de la imagen | Descripción |
|---|---|
| datos | Cadena codificada en BASE64 de la imagen normalizada en formato JPEG. |
| width | Ancho de la imagen normalizada en píxeles. |
| alto | Altura de la imagen normalizada en píxeles. |
| originalWidth | El ancho original de la imagen antes de la normalización. |
| originalHeight | La altura original de la imagen antes de la normalización. |
| rotationFromOriginal | Rotación a la izquierda en grados, que se produjo para crear la imagen normalizada. Un valor entre 0 y 360 grados. Este paso lee mediante una cámara o escáner los metadatos de la imagen que se genera. Normalmente, es un múltiplo de 90 grados. |
| contentOffset | El desplazamiento de caracteres en el campo de contenido desde donde se extrajo la imagen. Este campo solo es aplicable para los archivos con imágenes incrustadas. El contentOffset para imágenes extraídas de documentos PDF siempre está al final del texto de la página de la que se extrajo en el documento. Esto significa que las imágenes aparecen después de todo el texto de esa página, independientemente de la ubicación original de la imagen en la página. |
| pageNumber | Si la imagen se extrajo o se representó desde un archivo PDF, este campo contiene el número de página en el PDF del que se extrajo o se representó, empezando por 1. Si la imagen no procede de un PDF, este campo es 0. |
Muestra el valor de normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
Definición de conjuntos de aptitudes para el procesamiento de imágenes
Esta sección complementa los artículos de referencia de las aptitudes proporcionando el contexto para trabajar con las entradas, salidas y patrones de las habilidades, ya que se relacionan con el procesamiento de imágenes.
Cree o actualice un conjunto de aptitudes para agregar aptitudes.
Agregue plantillas para OCR y análisis de imágenes desde el portal o copie las definiciones de la documentación de referencia de aptitudes. Insértelos en la matriz de aptitudes de la definición del conjunto de aptitudes.
Si es necesario, incluya la clave de varios servicios en la propiedad de servicios de Azure AI del conjunto de aptitudes. Azure AI Search realiza llamadas a un recurso facturable de servicios de Azure AI para OCR y análisis de imágenes para transacciones que superan el límite libre (20 por indexador al día). Los servicios de Azure AI deben estar en la misma región que el servicio de búsqueda.
Si las imágenes originales están incrustadas en archivos PDF o de aplicación como PPTX o DOCX, deberá agregar una aptitud de combinación de texto si desea la salida de imagen y la salida de texto juntas. En este artículo se explica con más detalle cómo trabajar con imágenes insertadas.
Una vez creado el marco básico del conjunto de aptitudes y configurados los servicios de Azure AI, puede centrarse en cada aptitud de imagen individual, definir entradas y contexto de origen y asignar salidas a campos de un índice o almacén de conocimiento.
Nota:
Consulte Tutorial de REST: Uso de REST y AI para generar contenido en el que se pueden realizar búsquedas desde blobs de Azure para obtener un conjunto de aptitudes de ejemplo que combina el procesamiento de imágenes con el procesamiento de lenguaje natural de bajada. Muestra cómo alimentar la salida de la creación de imágenes de aptitudes en el reconocimiento de entidades y la extracción de frases clave.
Acerca de las entradas para el procesamiento de imágenes
Como se indicó, las imágenes se extraen durante el descifrado de documentos y, a continuación, se normalizan como un paso preliminar. Las imágenes normalizadas son las entradas de cualquier aptitud de procesamiento de imágenes y siempre se representan en un árbol de documentos enriquecidos de una de estas dos maneras:
/document/normalized_images/*es para los documentos que se procesan en su totalidad./document/normalized_images/*/pageses para documentos que se procesan en fragmentos (páginas).
Tanto si usa OCR como el análisis de imágenes en la misma, las entradas tienen prácticamente la misma construcción:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Asignación de salidas a campos de búsqueda
En un conjunto de aptitudes, la salida de la aptitud Image Analysis y OCR siempre es texto. El texto de salida se representa como nodos en un árbol de documentos enriquecido interno y cada nodo debe asignarse a campos de un índice de búsqueda o a proyecciones de un almacén de conocimiento para que el contenido esté disponible en la aplicación.
En el conjunto de aptitudes, revise la
outputssección de cada aptitud para determinar qué nodos existen en el documento enriquecido:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Cree o actualice un índice de búsqueda para agregar campos para aceptar las salidas de aptitud.
En el siguiente ejemplo de colección de campos, "content" es contenido de blobs. "Metadata_storage_name" contiene el nombre del archivo (asegúrese de que es "retrievable"). "Metadata_storage_path" es la ruta de acceso única del blob y es la clave de documento predeterminada. "Merged_content" es la salida de la combinación de texto (útil cuando se incrustan imágenes).
"Text" y "layoutText" son salidas de habilidades de OCR y deben ser una colección de cadenas para poder capturar todas las salidas generadas por OCR para todo el documento.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Actualice el indexador para asignar la salida del conjunto de aptitudes (nodos de un árbol de enriquecimiento) a los campos de índice.
Los documentos enriquecidos son internos. Para externalizar los nodos de un árbol de documentos enriquecidos, configure una asignación de campos de salida que especifique qué campo de índice recibe el contenido del nodo. La aplicación accede a los datos enriquecidos a través de un campo de índice. En el ejemplo siguiente se muestra un nodo "text" (salida OCR) en un documento enriquecido asignado a un campo "text" en un índice de búsqueda.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Ejecute el indexador para invocar la recuperación del documento de origen, el procesamiento de imágenes y la indexación.
Comprobar los resultados
Ejecute una consulta en el índice para comprobar los resultados del procesamiento de imágenes. Use el Explorador de búsqueda como cliente de búsqueda o cualquier herramienta que envíe solicitudes HTTP. La consulta siguiente selecciona los campos que contienen la salida del procesamiento de imágenes.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR reconoce texto en archivos de imagen. Esto significa que los campos OCR ("text" y "layoutText") están vacíos si los documentos de origen son texto puro o imágenes puras. Del mismo modo, los campos de análisis de imágenes ("imageCaption" y "imageTags") están vacíos si las entradas del documento de origen son estrictamente texto. La ejecución del indexador emite advertencias si las entradas de creación de imágenes están vacías. Estas advertencias deben esperarse cuando los nodos se vacían en el documento enriquecido. Recuerde que la indexación de blobs le permite incluir o excluir tipos de archivo si desea trabajar con tipos de contenido de forma aislada. Puede usar esta configuración para reducir el ruido durante las ejecuciones del indexador.
Una consulta alternativa para comprobar los resultados podría incluir los campos "content" y "merged_content". Tenga en cuenta que esos campos incluyen contenido para cualquier archivo de blob, incluso aquellos en los que no se realizó ningún procesamiento de imágenes.
Acerca de las salidas de aptitudes
Las salidas de aptitudes incluyen "text" (OCR), "layoutText" (OCR), "merged_content", "captions" (análisis de imágenes), "tags" (análisis de imágenes):
"text" almacena la salida generada por OCR. Este nodo debe asignarse al campo de tipo
Collection(Edm.String). Hay un campo de "texto" por documento de búsqueda que consta de cadenas delimitadas por comas para documentos que contienen varias imágenes. En la ilustración siguiente se muestra la salida de OCR para tres documentos. El primero es un documento que contiene un archivo sin imágenes. El segundo es un documento (archivo de imagen) que contiene una palabra, "Microsoft". El tercero es un documento que contiene varias imágenes, algunas sin texto ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]"layoutText" almacena información generada por OCR sobre la ubicación del texto en la página, descrita en términos de rectángulos delimitadores y coordenadas de la imagen normalizada. Este nodo debe asignarse al campo de tipo
Collection(Edm.String). Hay un campo "layoutText" por documento de búsqueda que consta de cadenas delimitadas por comas."merged_content" almacena la salida de una aptitud de combinación de texto y debe ser un campo grande de tipo
Edm.Stringque contenga texto sin formato del documento de origen, con "texto" insertado en lugar de una imagen. Si los archivos son de solo texto, OCR y el análisis de imágenes no tienen nada que hacer y "merged_content" es el mismo que "content" (una propiedad de blob que contiene el contenido del blob)."imageCaption" captura una descripción de una imagen como etiquetas individuales y una descripción de texto más larga.
"imageTags" almacena etiquetas sobre una imagen como una colección de palabras clave, una colección para todas las imágenes del documento de origen.
La captura de pantalla siguiente es una ilustración de un PDF que incluye texto e imágenes incrustadas. El descifrado de documentos detectó tres imágenes incrustadas: bandada de gaviotas, mapa, águila. Otro texto del ejemplo (incluidos los títulos, los encabezados y el texto del cuerpo) se extrajo como texto y se excluyó del procesamiento de imágenes.
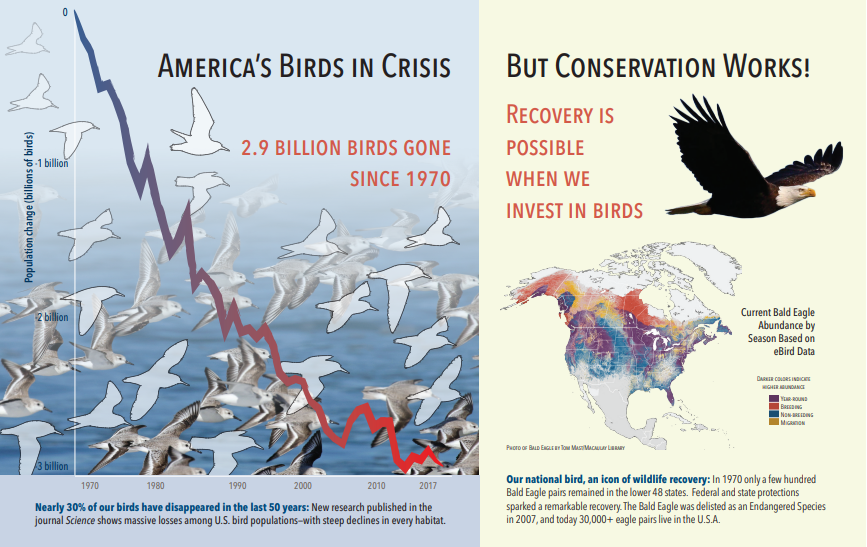
La salida del análisis de imágenes se muestra en el código JSON siguiente (resultado de la búsqueda). La definición de aptitud permite especificar qué características visuales son de interés. En este ejemplo, se generaron etiquetas y descripciones, pero hay más salidas entre las que elegir.
La salida "imageCaption" es una matriz de descripciones, una por imagen, indicada por "etiquetas" que consta de palabras únicas y frases más largas que describen la imagen. Observe las etiquetas que consisten en "una bandada de gaviotas nadando en el agua", o "un primer plano de un pájaro".
"La salida "imageTags" es una matriz de etiquetas individuales, listadas en el orden de creación. Observe que las etiquetas se repiten. No hay ninguna agregación ni agrupación.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Escenario: imágenes incrustadas en archivos PDF
Cuando las imágenes que desea procesar se insertan en otros archivos, como PDF o DOCX, la canalización de enriquecimiento extrae solo las imágenes y, a continuación, las pasa a OCR o análisis de imágenes para su procesamiento. La extracción de imágenes se produce durante la fase de descifrado del documento y, una vez separadas las imágenes, permanecen separadas a menos que se combine explícitamente la salida procesada en el texto de origen.
Combinación de texto se usa para volver a colocar la salida de procesamiento de imágenes en el documento. Aunque Text Merge no es un requisito difícil, se invoca con frecuencia para que la salida de la imagen (texto OCR, OCR layoutText, etiquetas de imagen, subtítulo s de imagen) se pueda volver a introducir en el documento. Dependiendo de la aptitud, la salida de la imagen reemplaza una imagen binaria incrustada por un equivalente de texto en su lugar. La salida del análisis de imágenes se puede combinar en la ubicación de la imagen. La salida de OCR siempre aparece al final de cada página.
El siguiente flujo de trabajo describe el proceso de extracción, análisis y combinación de imágenes y cómo ampliar la canalización para insertar la salida procesada por imágenes en otras aptitudes basadas en texto, como reconocimiento de entidades o traducción de texto.
Después de conectarse al origen de datos, el indexador carga y descifra los documentos de origen, extrae las imágenes y el texto y hace una cola de cada tipo de contenido para su procesamiento. Se crea un documento enriquecido que consta solo de un nodo raíz (
"document").Las imágenes de la cola se normalizan y se pasan a documentos enriquecidos como un nodo
"document/normalized_images".Los enriquecimientos de imágenes se ejecutan con
"/document/normalized_images"como entrada.Las salidas de imagen se pasan al árbol de documentos enriquecidos, con cada salida como un nodo independiente. Las salidas varían según la aptitud (text y layoutText para OCR, etiquetas y títulos para el análisis de imágenes).
Opcional, pero recomendado si desea que los documentos de búsqueda incluyan texto y texto con origen de imagen juntos, ejecuciones de la combinación de texto, combinación de la representación de texto de imágenes con el texto sin formato extraído del archivo. Los fragmentos de texto se consolidan en una sola cadena grande, donde el texto se inserta primero en la cadena y, a continuación, las etiquetas y subtítulos de texto OCR.
La salida de la combinación de texto es ahora el texto definitivo para analizar las aptitudes descendentes que realizan el procesamiento de texto. Por ejemplo, si el conjunto de aptitudes incluye OCR y reconocimiento de entidades, la entrada al reconocimiento de entidades debe ser
"document/merged_text"(el valor de targetName de la salida de la aptitud de combinación de texto).Una vez ejecutadas todas las aptitudes, se completa el documento enriquecido. En el último paso, los indexadores hacen referencia a las asignaciones de campos de salida para enviar contenido enriquecido a campos individuales en el índice de búsqueda.
El siguiente conjunto de aptitudes de ejemplo crea un campo "merged_text" que contiene el texto original del documento con texto del OCR incrustado en lugar de imágenes incrustadas. También incluye una aptitud de reconocimiento de entidades que usa "merged_text" como entrada.
Sintaxis del cuerpo de la solicitud
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Ahora que tiene un campo merged_text, puede asignarlo como un campo que se puede buscar en la definición del indexador. Podrá buscar todo el contenido de los archivos, incluido el texto de las imágenes.
Escenario: visualización de rectángulos delimitadores
Otro escenario común es la visualización de información de diseño de los resultados de búsqueda. Por ejemplo, puede querer resaltar donde se encontró un fragmento de texto en una imagen como parte de los resultados de búsqueda.
Dado que el paso OCR se realiza en las imágenes normalizadas, las coordenadas de diseño se encuentran en el espacio de imagen normalizado, pero si necesita mostrar la imagen original, convierta los puntos de coordenadas en el diseño en el sistema de coordenadas de imagen original.
El algoritmo siguiente muestra el patrón:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Escenario: aptitudes de imagen personalizadas
Las imágenes también se pueden pasar y devolver desde aptitudes personalizadas. Un conjunto de aptitudes codifica en base64 la imagen que se pasa a la aptitud personalizada. Para usar la imagen dentro de la aptitud personalizada, establezca "/document/normalized_images/*/data" como entrada para la aptitud personalizada. Dentro del código de la aptitud personalizada, descodifique la cadena en base64 antes de convertirla en imagen. Para devolver una imagen al conjunto de aptitudes, codifique en base64 la imagen antes de devolverla al conjunto de aptitudes.
La imagen se devuelve como objeto con las siguientes propiedades.
{
"$type": "file",
"data": "base64String"
}
El repositorio de ejemplos de Python de Azure Search tiene una muestra completa implementada en Python de una aptitud personalizada que enriquece las imágenes.
Paso de imágenes a habilidades personalizadas
En los casos en los que se requiera que una habilidad personalizada trabaje con imágenes, se pueden pasar imágenes a la habilidad personalizada y hacer que esta devuelva texto o imágenes. El siguiente conjunto de aptitudes procede de un ejemplo.
El siguiente conjunto de habilidades toma la imagen normalizada (obtenida durante el descifrado de documentos) y genera los segmentos de la imagen.
Conjunto de habilidades de ejemplo
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Ejemplo de aptitud personalizada
La habilidad personalizada en sí es externa al conjunto de habilidades. En este caso, es código de Python que recorre primero el lote de registros de solicitud en el formato de aptitud personalizado y, a continuación, convierte la cadena codificada en base64 en una imagen.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Del mismo modo, para devolver una imagen, devuelve una cadena codificada en base64 dentro de un objeto JSON con una propiedad $type de file.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}