Configuración de la interfaz de paso de mensajes para HPC
Precaución
En este artículo se hace referencia a CentOS, una distribución de Linux que está cerca de su estado Final de ciclo vida (EOL). Tenga en cuenta su uso y planifique en consecuencia. Para más información, consulte la Guía de fin de ciclo de vida de CentOS.
Se aplica a: ✔️ Máquinas virtuales Linux ✔️ Máquinas virtuales Windows ✔️ Conjuntos de escalado flexibles ✔️ Conjuntos de escalado uniformes
La interfaz de paso de mensajes (MPI) es una biblioteca abierta y con estándar de facto para operaciones de paralelización de memoria distribuida. Se suele usar en muchas cargas de trabajo de HPC. Las cargas de trabajo de HPC de las máquinas virtuales de serie HB y serie Ncompatibles con RDMA pueden usar MPI para comunicarse a través de la red InfiniBand de baja latencia y ancho de banda alto.
- Los tamaños de máquina virtual habilitados para SR-IOV en Azure permiten que se use prácticamente cualquier tipo de MPI con Mellanox OFED.
- En las máquinas virtuales que no están habilitadas para SR-IOV, las implementaciones de MPI compatibles usan la interfaz Microsoft Network Direct (ND) para comunicarse entre máquinas virtuales. Por lo tanto, solo se admiten las versiones de Microsoft MPI (MS-MPI) 2012 R2 o posterior e Intel MPI 5.x. Las versiones posteriores (2017 y 2018) de la biblioteca en tiempo de ejecución de MPI pueden ser o no compatibles con los controladores de Azure RDMA.
En el caso de las máquinas virtuales compatibles con RDMA habilitadas para SR-IOV, las imágenes de máquina virtual Ubuntu-HPC y almaLinux-HPC son adecuadas. Estas imágenes de máquina virtual, que se han optimizado y cargado previamente con los controladores OFED para RDMA y varias bibliotecas de MPI y paquetes de informática científica más usados, son la manera más fácil de empezar.
Aunque el ejemplo que se muestra aquí es para RHEL/CentOS, los pasos son generales y se pueden usar en cualquier sistema operativo de Linux compatible, como Ubuntu (18.04, 20.04, 22.04) y SLES (12 SP4 y 15 SP4). Hay más ejemplos para configurar otras implementaciones de MPI en otras distribuciones en el repositorio azhpc-images.
Nota
La ejecución de trabajos de MPI en máquinas virtuales habilitadas para SR-IOV con ciertas bibliotecas MPI (como la plataforma MPI) puede requerir la configuración de claves de partición (claves p) en un inquilino para el aislamiento y la seguridad. Siga los pasos descritos en la sección Detección de claves de partición para obtener más información sobre cómo determinar los valores de la clave p y configurarlos correctamente para un trabajo de MPI con la biblioteca de MPI.
Nota
Los fragmentos de código siguientes son ejemplos. Se recomienda usar las versiones estables más recientes de los paquetes o hacer referencia al repositorio azhpc-images.
Elección de la biblioteca MPI
Si una aplicación de HPC recomienda una biblioteca de MPI concreta, pruebe esa versión primero. Si tiene flexibilidad en cuanto a la MPI que puede elegir y quiere el mejor rendimiento, pruebe HPC-X. En general, la MPI de HPC-X realiza el mejor uso del marco UCX para la interfaz de InfiniBand y aprovecha todas las funciones de hardware y software de Mellanox InfiniBand. Asimismo, HPC-X y OpenMPI son compatibles con ABI, por lo que puede ejecutar dinámicamente una aplicación de HPC con HPC-X que se compiló con OpenMPI. De forma similar, Intel MPI, MVAPICH y MPICH son compatibles con ABI.
En la ilustración siguiente se muestra la arquitectura de las bibliotecas de MPI populares.
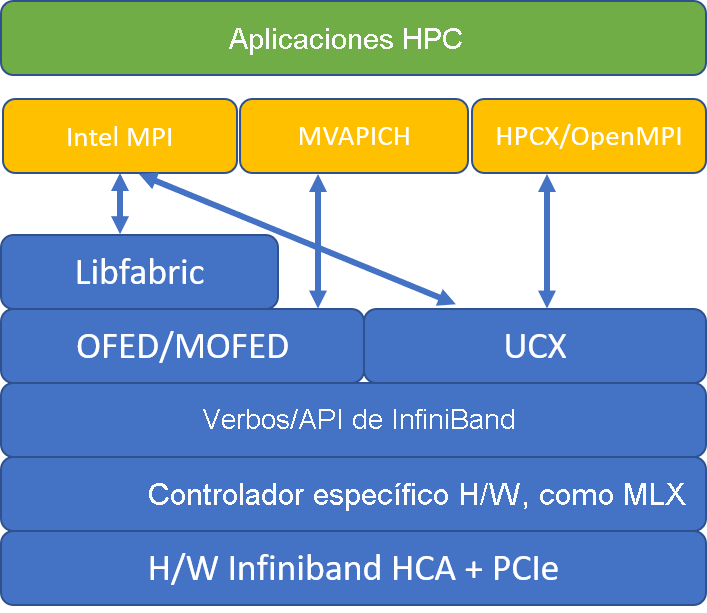
HPC-X
El Kit de herramientas de software HPC-X contiene UCX y HCOLL y se puede compilar con UCX.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
El siguiente comando muestra algunos argumentos mpirun recomendados para HPC-X y OpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
donde:
| Parámetro | Descripción |
|---|---|
NPROCS |
Especifica el número de procesos de MPI. Por ejemplo: -n 16. |
$HOSTFILE |
Especifica un archivo que contiene el nombre de host o la dirección IP, para indicar la ubicación de dónde se ejecutan los procesos de MPI. Por ejemplo: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Especifica el número de procesos MPI que se ejecutan en cada dominio NUMA. Por ejemplo, para especificar cuatro procesos de MPI por NUMA, use --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Especifica el número de subprocesos por proceso de MPI. Por ejemplo, para especificar un proceso de MPI y cuatro procesos por NUMA, use --map-by ppr:1:numa:pe=4. |
-report-bindings |
Imprime la asignación de procesos de MPI a núcleos, lo que resulta útil para comprobar que el anclaje del procesos de MPI es correcto. |
$MPI_EXECUTABLE |
Especifica el ejecutable de MPI compilado mediante la vinculación en bibliotecas MPI. Los contenedores del compilador de MPI lo hacen automáticamente. Por ejemplo, mpicc o mpif90. |
Un ejemplo de ejecución del micropunto de referencia de la latencia de OSU es el siguiente:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
Optimización de las comunicaciones colectivas de MPI
Las primitivas de comunicación colectiva de MPI ofrecen una forma flexible y portátil de implementar operaciones de comunicación de grupos. Se usan ampliamente en varias aplicaciones científicas paralelas y tienen un impacto significativo en el rendimiento general de la aplicación. Consulte el artículo de TechCommunity para más información sobre los parámetros de configuración para optimizar el rendimiento de la comunicación colectiva mediante HPC-X y la biblioteca HCOLL para la comunicación colectiva.
Como ejemplo, si sospecha que la aplicación de MPI estrechamente acoplada realiza una cantidad excesiva de comunicaciones colectivas, puede intentar habilitar las colectivas jerárquicas (HCOLL). Para habilitar esas características, use los parámetros siguientes.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Nota
Con HPC-X 2.7.4 +, puede que sea necesario pasar explícitamente LD_LIBRARY_PATH si la versión de UCX en MOFED frente a la de HPC-X es diferente.
OpenMPI
Instale UCX como se describió anteriormente. HCOLL forma parte del kit de herramientas de software HPC-X y no requiere una instalación especial.
Se puede instalar OpenMPI desde los paquetes disponibles en el repositorio.
sudo yum install –y openmpi
Se recomienda crear una versión más reciente y estable de OpenMPI con UCX.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
Para obtener un rendimiento óptimo, ejecute OpenMPI con ucx y hcoll. Consulte también el ejemplo con HPC-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
Compruebe la clave de partición como se indicó anteriormente.
Intel MPI
Descargue su elección de versión de Intel MPI. La versión Intel MPI 2019 cambió del marco Open Fabrics Alliance (OFA) al marco Open Fabrics Interfaces (OFI), y actualmente admite libfabric. Hay dos proveedores para la compatibilidad con InfiniBand: mlx y verbs. Cambie la variable de entorno I_MPI_FABRICS según la versión.
- Intel MPI 2019 y 2021: uso
I_MPI_FABRICS=shm:ofi,I_MPI_OFI_PROVIDER=mlx. El proveedormlxusa UCX. Se ha descubierto que la utilización de verbos es inestable y tiene menos rendimiento. Para más detalles, consulte el artículo TechCommunity. - Intel MPI 2018: uso
I_MPI_FABRICS=shm:ofa - Intel MPI 2016: uso
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
Estos son algunos argumentos de mpirun sugeridos para Intel MPI 2019 update 5+.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
donde:
| Parámetro | Descripción |
|---|---|
FI_PROVIDER |
Especifica qué proveedor de libfabric se va a usar, que afectará a la API, el protocolo y la red que se usan. El verbo es otra opción, pero por lo general, la combinación ofrece un mejor rendimiento. |
I_MPI_DEBUG |
Especifica el nivel de salida de depuración adicional, que puede proporcionar detalles sobre dónde se anclan los procesos y qué protocolo y red se usan. |
I_MPI_PIN_DOMAIN |
Especifica cómo se quieren anclar los procesos. Por ejemplo, puede anclar a núcleos, sockets o dominios NUMA. En este ejemplo, se establece esta variable de entorno en NUMA, lo que significa que los procesos se anclarán a los dominios de nodo NUMA. |
Optimización de las comunicaciones colectivas de MPI
Hay otras opciones que puede probar, especialmente si las operaciones colectivas consumen una cantidad de tiempo considerable. Intel MPI 2019 update 5+ admite el proveedor mlx y usa el marco UCX para comunicarse con InfiniBand. También admite HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Máquinas virtuales que no son SR-IOV
En el caso de las máquinas virtuales que no son SR-IOV, un ejemplo de descarga de la versión de evaluación gratuita del runtime 5.x es el siguiente:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
Para ver los pasos de instalación, vea la guía de instalación de la Biblioteca de Intel MPI. Si lo desea, habilite ptrace para los procesos que no son de depurador no raíz (necesario para las versiones más recientes de Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
Para las versiones de imágenes de máquina virtual de SUSE Linux Enterprise Server SLES 12 SP3 para HPC, SLES 12 SP3 para HPC (Premium), SLES 12 SP1 para HPC, SLES 12 SP1 para HPC (Premium), SLES 12 SP4 y SLES 15, los controladores RDMA se instalan y los paquetes de Intel MPI se distribuyen en la máquina virtual. Instale MPI ejecutando el comando siguiente:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
A continuación se presenta un ejemplo de una compilación MVAPICH2. Tenga en cuenta que es posible que tenga disponibles versiones más recientes que las que se van a usar a continuación.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
Un ejemplo de ejecución del micropunto de referencia de la latencia de OSU es el siguiente:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
La lista siguiente contiene varios argumentos de mpirun recomendados.
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
donde:
| Parámetro | Descripción |
|---|---|
MV2_CPU_BINDING_POLICY |
Especifica la directiva de enlace que se va a usar, que afectará a cómo se anclan los procesos a los identificadores de núcleo. En este caso, se especifica scatter, por lo que los procesos se distribuyen de manera uniforme entre los dominios NUMA. |
MV2_CPU_BINDING_LEVEL |
Especifica dónde anclar los procesos. En este caso, se establece en un nodo NUMA, lo que significa que los procesos se anclan a las unidades de los dominios NUMA. |
MV2_SHOW_CPU_BINDING |
Especifica si se quiere obtener información de depuración sobre dónde están anclados los procesos. |
MV2_SHOW_HCA_BINDING |
Especifica si se quiere obtener información de depuración sobre qué adaptador de canal de host usa cada proceso. |
MPI de plataforma
Instale los paquetes necesarios para la Plataforma MPI de edición Community.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
Siga el proceso de instalación.
Los siguientes comandos son ejemplos de ejecución de MPI pingpong y admite varias mediante la plataforma MPI en VM HBv3 usando imágenes de VM de CentOS-HPC 7.6, 7.8 y 8.1.
/opt/ibm/platform_mpi/bin/mpirun -hostlist 10.0.0.8:1,10.0.0.9:1 -np 2 -e MPI_IB_PKEY=0x800a -ibv /home/jijos/mpi-benchmarks/IMB-MPI1 pingpong
/opt/ibm/platform_mpi/bin/mpirun -hostlist 10.0.0.8:120,10.0.0.9:120 -np 240 -e MPI_IB_PKEY=0x800a -ibv /home/jijos/mpi-benchmarks/IMB-MPI1 allreduce -npmin 240
MPICH
Instale UCX como se describió anteriormente. Compile MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
Ejecute MPICH.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
Compruebe la clave de partición como se indicó anteriormente.
Pruebas comparativas OSU MPI
Descargue los bancos de pruebas de MPI de OSU y descomprima el archivo.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
Compilar las pruebas comparativas con una biblioteca de MPI particular:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
Las pruebas comparativas de MPI están en la carpeta mpi/.
Detección de claves de partición
Detecte las claves de partición (p-keys) para comunicarse con otras máquinas virtuales dentro del mismo inquilino (conjunto de disponibilidad o conjunto de escalado de máquinas virtuales).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
La mayor de las dos es la clave de inquilino que debe usarse con MPI. Ejemplo: Si las siguientes son las claves p, se debe usar 0x800b con MPI.
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
Las interfaces de nota se denominan mlx5_ib* dentro de las imágenes de máquina virtual de HPC.
Tenga en cuenta también que, siempre y cuando el inquilino exista (conjunto de disponibilidad o conjunto de escalado de máquinas virtuales), las PKEY seguirán siendo las mismas. Esto sucede incluso cuando se agregan o eliminan nodos. Los nuevos inquilinos obtienen PKEY diferentes.
Configuración de los límites de usuario para MPI
Configure los límites de usuario para MPI.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
Configure las claves SSH para MPI
Configure las claves SSH para los tipos MPI que lo requieran.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
La sintaxis anterior asume un directorio principal compartido; de lo contrario, hay que copiar el directorio .ssh a cada nodo.
Pasos siguientes
- Más información sobre las máquinas virtuales de las series HB y series Nhabilitadas para InfiniBand.
- Revise la información general de la serie HBv3 y la información general de la serie HC.
- Lea el artículo sobre la ubicación del proceso MPI óptimo para las máquinas virtuales de la serie HB.
- En los blogs de Azure Compute Community Tech, encontrará los anuncios más recientes, ejemplos de la carga de trabajo HPC y resultados de HPC.
- Si desea una visión general de la arquitectura de la ejecución de cargas de trabajo de HPC, consulte Informática de alto rendimiento (HPC) en Azure.