Configuraciones y operaciones de infraestructura de SAP HANA en Azure
En este documento se proporcionan instrucciones para configurar la infraestructura de Azure y sobre el funcionamiento de los sistemas SAP HANA que se implementaron en máquinas virtuales nativas de Azure. En el documento también se incluye información sobre la configuración de la escalabilidad horizontal de SAP HANA para la SKU de máquinas virtuales M128s. Este documento no pretende reemplazar ninguna documentación estándar de SAP, incluido el contenido siguiente:
Prerrequisitos
Para utilizar esta guía, necesita un conocimiento básico de los siguientes componentes de Azure:
Para obtener más información acerca de SAP NetWeaver y otros componentes de SAP en Azure, consulte la sección SAP en Azure de la documentación de Azure.
Consideraciones básicas sobre la configuración
En las siguientes secciones se describen las consideraciones de configuración básicas para implementar sistemas SAP HANA en máquinas virtuales de Azure.
Conectarse a Azure Virtual Machines
Como se documenta en la guía de planeamiento de Azure Virtual Machines, existen dos métodos básicos para conectarse a máquinas virtuales de Azure:
- Conéctese a través de Internet y de los puntos de conexión públicos en una máquina virtual de Jump o en la máquina virtual que ejecuta SAP HANA.
- Conéctese a través de una VPN o de Azure ExpressRoute.
La conectividad de sitio a sitio a través de VPN o ExpressRoute es necesaria para los escenarios de producción. Este tipo de conexión también es necesario para escenarios de no producción que se incorporan en escenarios de producción cuando se usa el software SAP. La imagen siguiente muestra un ejemplo de conectividad entre sitios:
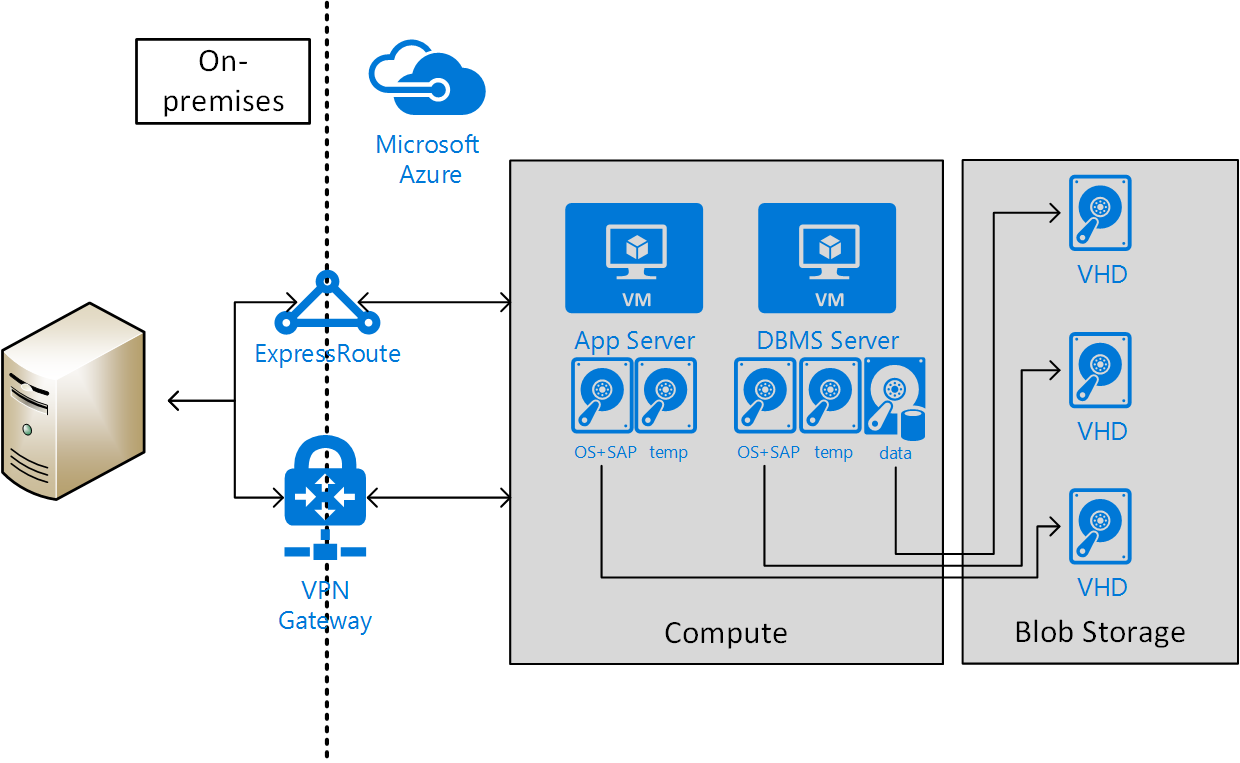
Elegir tipos de máquina virtual de Azure
SAP muestra los tipos de máquina virtual de Azure que puede usar en escenarios de producción. En el caso de los escenarios que no son de producción, existe una variedad más amplia de tipos de máquinas virtuales de Azure disponible.
Nota
Para escenarios no de producción, use los tipos de máquinas virtuales que se enumeran en la nota de SAP 1928533. Para el uso de máquinas virtuales de Azure en escenarios de producción, compruebe las máquinas virtuales certificadas para SAP HANA en el documento publicado por SAP con la lista de plataformas de IaaS certificadas.
Implemente las máquinas virtuales en Azure mediante:
- Azure Portal.
- Los cmdlets de Azure PowerShell.
- La CLI de Azure.
También puede implementar una plataforma SAP HANA completamente instalada en los servicios de máquina virtual de Azure a través de la plataforma en la nube de SAP. El proceso de instalación se describe en Implementación de SAP S/4HANA o BW/4HANA en Azure.
Importante
Para usar máquinas virtuales M208xx_v2, tendrá que seleccionar la imagen de Linux. Para más información, consulte Tamaños de máquina virtual optimizada para memoria.
Configuración del almacenamiento en SAP HANA
Para las configuraciones de almacenamiento y los tipos de almacenamiento que se usan con SAP HANA en Azure, lea el documento Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA
Configurar Azure Virtual Network
Si tiene conectividad de sitio a sitio a Azure por medio de VPN o de ExpressRoute, debe tener como mínimo una red de Azure Virtual Network conectada a través de una puerta de enlace virtual al circuito VPN o ExpressRoute. En las implementaciones sencillas, la puerta de enlace virtual puede implementarse en una subred de la instancia de Azure Virtual Network (VNet) que también hospeda las instancias de SAP HANA. Para instalar SAP HANA, debe crear dos subredes más en la instancia de Azure Virtual Network. Una subred hospeda las máquinas virtuales para ejecutar las instancias de SAP HANA. La otra subred ejecuta Jumpbox o máquinas virtuales de administración para hospedar SAP HANA Studio, otro software de administración o el software de la aplicación.
Importante
Además de por la funcionalidad y, lo que es más importante, por motivos de rendimiento, no se puede configurar Aplicaciones virtuales de red de Azure en la ruta de comunicación entre la aplicación de SAP y la capa DBMS de un sistema SAP basado en SAP NetWeaver, Hybris o S/4HANA. La comunicación entre la capa de la aplicación de SAP y la capa de DBMS debe ser directa. La restricción no incluye reglas ASG ni NSG de Azure, siempre y cuando dichas reglas ASG y NSG permitan una comunicación directa. Más escenarios donde no se admiten los NVA se dan en las rutas de comunicación entre las máquinas virtuales de Azure que representan los nodos de clúster de Linux Pacemaker y los dispositivos SBD, según se describe en Alta disponibilidad para SAP NetWeaver en máquinas virtuales de Azure en SUSE Linux Enterprise Server para SAP Applications. O bien, en las rutas de comunicación establecidas entre las máquinas virtuales de Azure y Windows Server SOFS configuradas como se describe en Agrupación de una instancia de ASCS/SCS de SAP en un clúster de conmutación por error de Windows con un recurso compartido de archivos en Azure. Las aplicaciones virtuales de red en las rutas de comunicación pueden duplicar fácilmente la latencia de red entre dos socios de comunicación y restringir el rendimiento en las rutas críticas entre la capa de la aplicación de SAP y la capa de DBMS. En algunos escenarios que se han observado con los clientes, las aplicaciones virtuales de red pueden ocasionar que los clústeres Pacemaker Linux produzcan un error cuando las comunicaciones entre los nodos del clúster de Linux Pacemaker necesiten comunicarse con su dispositivo SBD mediante una NVA.
Importante
Otro diseño que NO se admite es la segregación de la capa de la aplicación de SAP ni la capa de DBMS en diferentes redes virtuales de Azure que no están emparejadas entre sí. Se recomienda separar la capa de la aplicación de SAP y la capa de DBMS con subredes dentro de una red virtual de Azure, en lugar de usar diferentes redes virtuales de Azure. Si decide no seguir la recomendación y, en su lugar, separa las dos capas en redes virtuales diferentes, las dos redes virtuales deben estar emparejadas. Tenga en cuenta que el tráfico entre dos redes virtuales de Azure emparejadas está sujeto a costes de transferencia. Debido al intercambio de un gran volumen de datos en terabytes entre la capa de la aplicación de SAP y la capa de DBMS, pueden acumularse costos sustanciales si la capa de la aplicación de SAP y la capa de DBMS se separan entre dos redes virtuales de Azure emparejadas.
Si ha implementado Jumpbox o máquinas virtuales de administración en una subred independiente, puede definir varias tarjetas de interfaz de red virtual (vNIC) para la máquina virtual de HANA, con cada vNIC asignada a una subred diferente. Con la capacidad de tener varias VNIC, puede configurar la separación del tráfico de red, si es necesario. Por ejemplo, el tráfico de cliente se puede enrutar a través de la vNIC principal y el tráfico de administrador se enruta a través de una segunda vNIC.
También se asignan direcciones IP privadas estáticas que se implementan para ambas NIC virtuales.
Nota:
Debería asignar direcciones IP estáticas mediante Azure a NIC virtuales individuales. No debería asignar direcciones IP estáticas dentro del sistema operativo invitado a una NIC virtual. Algunos servicios de Azure como el servicio Azure Backup se basan en el hecho de que al menos el vNIC principal está establecido en DHCP y no en direcciones IP estáticas. Consulte también el documento Solución de problemas de copia de seguridad de máquinas virtuales de Azure. Si necesita asignar varias direcciones IP estáticas a una máquina virtual, tiene que asignar varias NIC virtuales a una máquina virtual.
Sin embargo, para implementaciones permanentes, deberá crear una arquitectura de red del centro de datos virtual en Azure. Esta arquitectura recomienda separar la instancia de Azure VNet Gateway que se conecta a entornos locales en una instancia independiente de Azure Virtual Network. Esta red virtual independiente debe hospedar todo el tráfico que sale a entornos locales o a Internet. Este enfoque permite implementar software para la auditoría y el registro de tráfico que entra en el centro de datos virtual de Azure en esta red virtual hub independiente. De esta forma, dispondrá de una red virtual que hospeda todo el software y las configuraciones relacionados con el tráfico de entrada y salida de la implementación de Azure.
En los artículos Centro de datos virtual de Azure: una perspectiva de red y Centro de datos virtual de Azure y el plano de control empresarial se ofrece más información sobre el enfoque del centro de datos virtual y el diseño relacionado de Azure Virtual Network.
Nota
El tráfico que fluye entre una red virtual hub y otra spoke mediante emparejamiento de redes virtuales de Azure supone costos adicionales. Según estos costos, puede que deba plantearse la opción de asumir compromisos entre la ejecución de un diseño de red hub-and-spoke estricto y la ejecución de varias puertas de enlace de Azure ExpressRoute que conecta a los "radios" para omitir el emparejamiento de redes virtuales. Sin embargo, las puertas de enlace de Azure ExpressRoute también generan costos adicionales. También puede incurrir en costos adicionales por el software de terceros que usa para el registro, la auditoría y la supervisión del tráfico de red. En función de los costos derivados del intercambio de datos mediante el emparejamiento de redes virtuales, por una parte, y de los costos que generan las puertas de enlace de Azure ExpressRoute adicionales y las licencias de software adicionales, por otra, puede que deba plantearse la microsegmentación dentro de una red virtual con el uso de subredes como unidad de aislamiento en lugar de utilizar redes virtuales.
Para obtener información general sobre los distintos métodos para asignar direcciones IP, consulte Tipos de direcciones IP y métodos de asignación en Azure.
Para máquinas virtuales que ejecutan SAP HANA, debe trabajar con direcciones IP estáticas asignadas. La razón es que algunos atributos de configuración de HANA hacen referencia a direcciones IP.
Los grupos de seguridad de red (NSG) de Azure se usan para dirigir el tráfico que se enruta a la instancia de SAP HANA o al Jumpbox. Los NSG y los posibles grupos de seguridad de aplicaciones se asocian a la subred de SAP HANA y a la subred de administración.
Para implementar SAP HANA en Azure sin una conexión de sitio a sitio, todavía debe blindar la instancia de SAP HANA desde la red pública de Internet y ocultarla detrás de un proxy de reenvío. En este escenario básico, la implementación depende de los servicios DNS integrados en Azure para resolver los nombres de host. En una implementación más compleja en la que se usan direcciones IP de acceso público, los servicios DNS integrados en Azure son especialmente importantes. Use los grupos de seguridad de red de Azure y las aplicaciones virtuales de red de Azure para controlar y supervisar el enrutamiento desde Internet a la arquitectura de Azure Virtual Network. En la imagen siguiente se muestra un esquema aproximado de implementación de SAP HANA sin una conexión de sitio a sitio en una arquitectura de red virtual tipo hub-and-spoke:
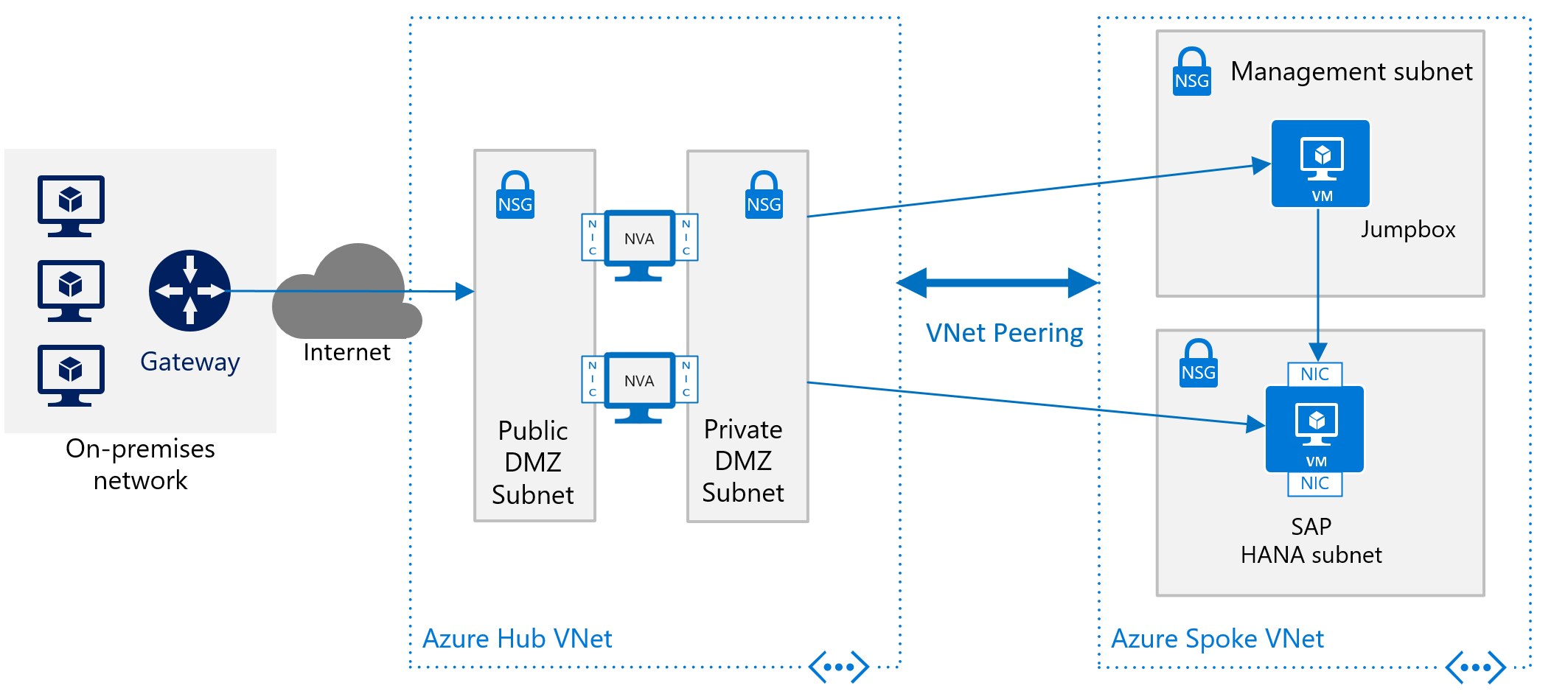
Se puede consultar otra descripción sobre cómo usar las aplicaciones virtuales de red de Azure para controlar y supervisar el acceso desde Internet sin la arquitectura de red virtual tipo hub-and-spoke en el artículo Implementación de aplicaciones virtuales de red de alta disponibilidad.
Configuración de la infraestructura de Azure para la escalabilidad horizontal de SAP HANA
Para averiguar los tipos de máquina virtual de Azure que están certificadas para la escalabilidad horizontal de OLAP o la escalabilidad horizontal de S/4HANA, consulte el directorio de hardware de SAP HANA. Una marca de verificación en la columna "Clustering" (Agrupación en clústeres) indica compatibilidad con la escalabilidad horizontal. La columna "Application Type" (Tipo de aplicación) indica si se admite la escalabilidad horizontal de OLAP o la escalabilidad horizontal de S/4HANA. Para más información sobre los nodos certificados en el escalado horizontal, revise la entrada de una SKU de máquina virtual específica que aparece en el directorio de hardware de SAP HANA.
Para conocer las versiones mínimas del sistema operativo para implementar configuraciones de escalabilidad horizontal en máquinas virtuales de Azure, compruebe los detalles de las entradas de la SKU de máquina virtual específica que aparecen en el directorio de hardware de SAP HANA. De una configuración de escalabilidad horizontal de OLAP de n nodos, un nodo funciona como nodo principal. Los demás nodos hasta el límite de la certificación funcionan como nodos de trabajo. Los nodos en espera extra no cuentan en el número de nodos certificados
Nota
Las implementaciones de escalabilidad horizontal de máquinas virtuales de Azure de SAP HANA con un nodo en espera solo son posibles mediante el almacenamiento Azure NetApp Files. Ningún otro almacenamiento de Azure certificado para SAP HANA permite la configuración de nodos en espera de SAP HANA.
Para /hana/shared, se recomienda usar Azure NetApp Files o Azure Files.
Un diseño básico típico para un solo nodo en una configuración de escalabilidad horizontal, con /hana/shared implementado en Azure NetApp Files, tiene el siguiente aspecto:
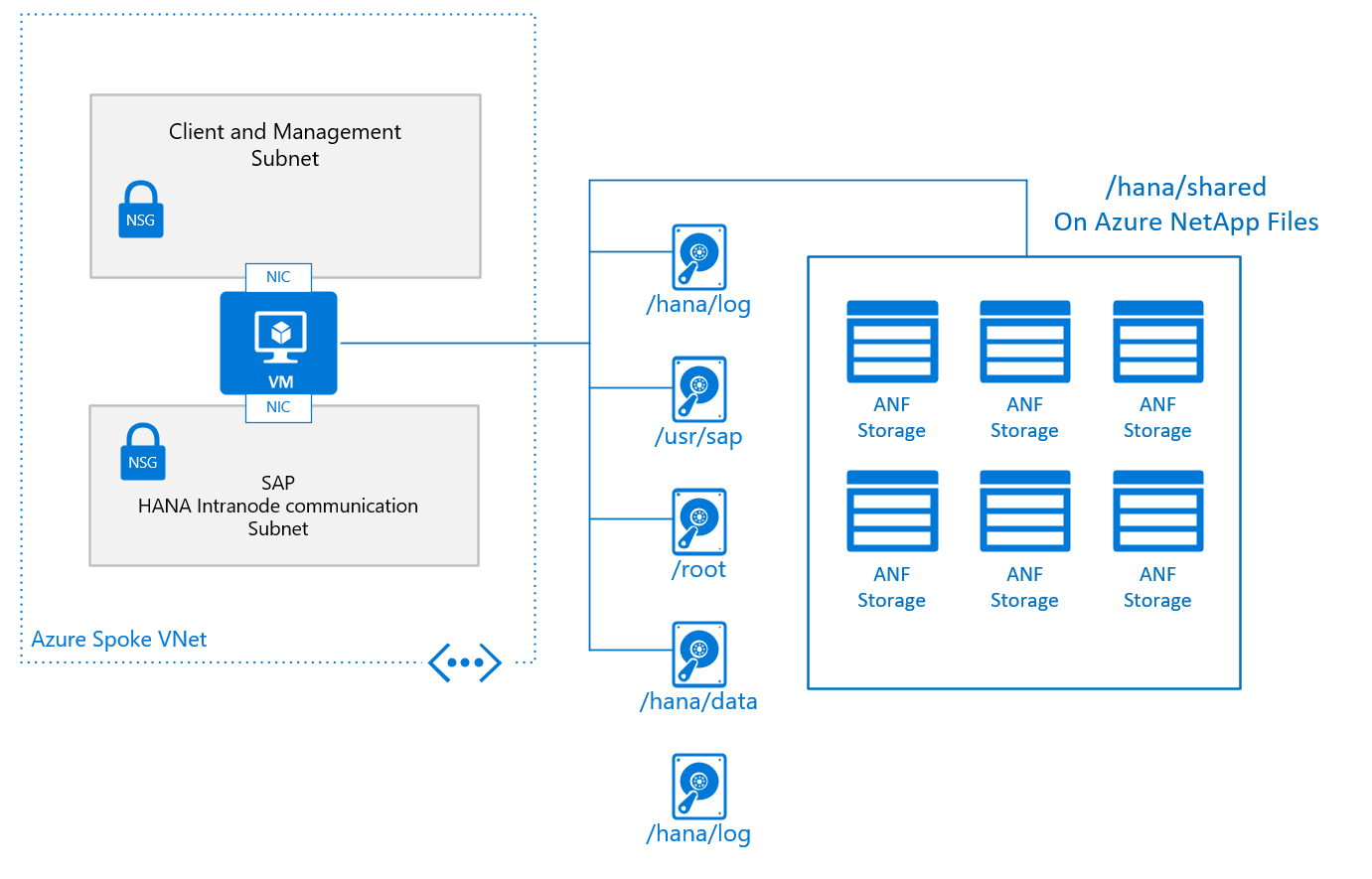
La configuración básica de un nodo de máquina virtual para escalabilidad horizontal de SAP HANA presenta este aspecto:
- Para /hana/shared, se usa el servicio NFS nativo proporcionado a través de Azure NetApp Files o Azure Files.
- Todos los demás volúmenes de disco no se comparten entre los diferentes nodos y no se basan en NFS. Más adelante en este documento se proporcionan las configuraciones de instalación y los pasos para la escalabilidad horizontal de instalaciones HANA con los recursos no compartidos /hana/data y /hana/log. Para conocer el almacenamiento certificado para HANA que se puede usar, consulte el artículo Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA.
Para ajustar el tamaño de los volúmenes o discos, debe consultar el documento Requisitos de almacenamiento de TDI para SAP HANA. El tamaño necesario depende del número de nodos de trabajo. En el documento se incluye una fórmula que debe aplicar para obtener la capacidad necesaria del volumen.
El otro criterio de diseño que se muestra en los gráficos de la configuración de un único nodo para una máquina virtual de SAP HANA de escalabilidad horizontal es la red virtual, o mejor dicho la configuración de subred. SAP recomienda encarecidamente una separación del tráfico orientado al cliente y a la aplicación de las comunicaciones entre los nodos HANA. Como se muestra en los gráficos, esto se logra al tener dos VNIC diferentes conectados a la máquina virtual. Ambos VNIC están en subredes diferentes, con dos direcciones IP distintas. Puede controlar el flujo del tráfico con reglas de enrutamiento mediante grupos de seguridad de red o rutas definidas por el usuario.
Especialmente en Azure, no hay ningún medio o método para exigir la calidad de servicio y las cuotas en VNIC específicos. Como resultado, la separación de las comunicaciones entre nodos y aquellas orientadas al cliente y a la aplicación no ofrece ninguna oportunidad de dar prioridad a un flujo de tráfico con respecto a otro. En su lugar, la separación sigue siendo una medida de seguridad al blindar las comunicaciones entre nodos de las configuraciones de escalabilidad horizontal.
Nota
SAP recomienda separar el tráfico de red hacia el cliente o la aplicación y el tráfico entre nodos como se describe en este documento. Por tanto, resulta muy conveniente establecer una arquitectura como la que se muestra en los últimos gráficos. Si tiene requisitos que se desvían de la recomendación, consulte también al equipo de seguridad y cumplimiento.
Desde el punto de vista de las redes, la arquitectura de red mínima requerida sería:
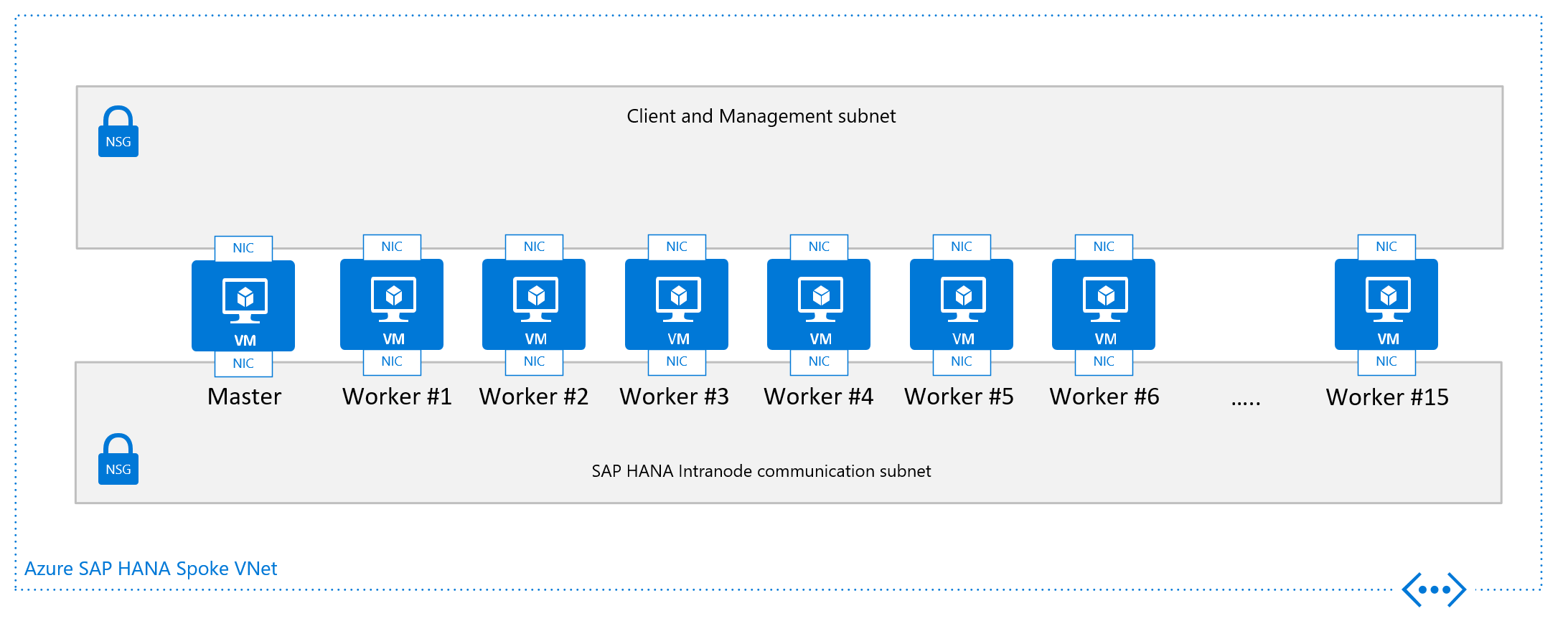
Instalación de la escalabilidad horizontal de SAP HANA en Azure
Para instalar una configuración de SAP para escalabilidad horizontal, debe seguir estos pasos:
- Implementación de una nueva infraestructura de red virtual de Azure o adaptación de una existente
- Implementación de las nuevas máquinas virtuales mediante Premium Storage administrado de Azure, volúmenes de discos Ultra y/o volúmenes NFS basados en ANF
-
- Adaptar el enrutamiento de red para asegurarse de que, por ejemplo, la comunicación entre nodos de las máquinas virtuales no se enruta mediante una NVA.
- Instalar el nodo principal de SAP HANA.
- Adaptar los parámetros de configuración del nodo principal de SAP HANA
- Continuar con la instalación de los nodos de trabajo de SAP HANA.
Instalación de SAP HANA en la configuración de escalabilidad horizontal
Como se implementa la infraestructura de máquina virtual de Azure y se realizan todos los demás preparativos, deberá instalar las configuraciones de escalabilidad horizontal de SAP HANA en estos pasos:
- Instale el nodo principal de SAP HANA según la documentación de SAP
- Cuando se usa el Premium Storage de Azure o Almacenamiento en disco Ultra con discos no compartidos de
/hana/datay/hana/log, añada el parámetrobasepath_shared = noal archivoglobal.ini. Este parámetro habilita SAP HANA para que se ejecute la escalabilidad horizontal sin volúmenes/hana/datay/hana/logcompartidos entre los nodos. Los detalles están documentados en la nota de SAP n.º 2080991. Si usa volúmenes NFS basados en ANF para /hana/data y /hana/log, no es necesario que realice este cambio - Después del cambio definitivo en el parámetro global.ini, reinicie la instancia de SAP HANA.
- Adición de más nodos de trabajo. Para obtener más información, consulte el artículo sobre cómo agregar hosts mediante la interfaz de la línea de comandos. Especifique la red interna para la comunicación entre nodos de SAP HANA durante la instalación o después con, por ejemplo, el hdblcm local. Para obtener documentación más detallada, consulte la nota de SAP n.º 2183363.
Para configurar un sistema de escalabilidad horizontal de SAP HANA con un nodo en espera, consulte las instrucciones de implementación de SUSE Linux o las instrucciones de implementación de Red Hat.
Dynamic Tiering 2.0 de SAP HANA para máquinas virtuales de Azure
Además de las certificaciones de SAP HANA en máquinas virtuales de la serie M de Azure, Dynamic Tiering 2.0 de SAP HANA también se admite en Microsoft Azure. Para obtener más información, vea Vínculos a la documentación de DT 2.0. No hay ninguna diferencia en la instalación o el funcionamiento del producto. Por ejemplo, puede instalar SAP HANA Cockpit dentro de una máquina virtual de Azure. Sin embargo, hay algunos requisitos obligatorios, como se describe en la sección siguiente, para obtener soporte técnico oficial en Azure. En este artículo, se va a usar la abreviatura "DT 2.0" en lugar del nombre completo Dynamic Tiering 2.0.
Dynamic Tiering 2.0 de SAP HANA no se admite en SAP BW ni en S4HANA. Los casos de uso principales son ahora las aplicaciones nativas de HANA.
Información general
La ilustración siguiente proporciona información general sobre la compatibilidad de DT 2.0 en Microsoft Azure. Hay un conjunto de requisitos obligatorios, que deben seguirse para cumplir con la certificación oficial:
- DT 2.0 debe instalarse en una máquina virtual de Azure dedicada. No se puede ejecutar en la misma máquina virtual donde se ejecuta SAP HANA.
- Las máquinas virtuales de DT 2.0 y de SAP HANA deben implementarse dentro de la misma red virtual de Azure.
- Las máquinas virtuales de DT 2.0 y de SAP HANA deben implementarse con las redes aceleradas de Azure habilitadas.
- El tipo de almacenamiento para las máquinas virtuales de DT 2.0 debe ser Azure Premium Storage.
- Deben conectarse varios discos de Azure a la máquina virtual de DT 2.0.
- Es necesario crear una matriz redundante de discos independientes de software o volumen seccionado (ya sea a través de lvm o de mdadm) mediante la creación de bandas en los discos de Azure.
Esto se va a explicar con más detalle en las secciones siguientes.
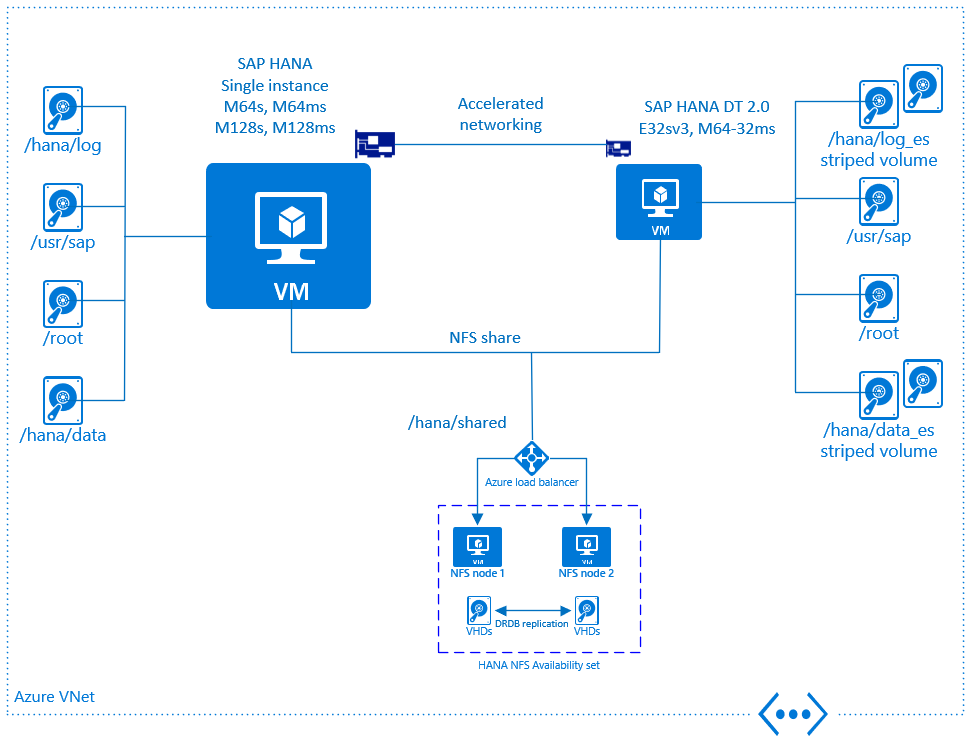
Máquina virtual de Azure dedicada para DT 2.0 de SAP HANA
En Azure IaaS, DT 2.0 solo se admite en una máquina virtual dedicada. No se permite ejecutar DT 2.0 en la misma máquina virtual de Azure donde se está ejecutando la instancia de HANA. Inicialmente, se pueden usar dos tipos de máquina virtual para ejecutar DT 2.0 de SAP HANA:
- M64-32ms
- E32sv3
Para más información sobre la descripción del tipo de VM, consulte Tamaños de las máquinas virtuales de Azure: memoria.
Dada la idea básica de DT 2.0, que es la descarga de datos "semiactivos" con el fin de ahorrar costos, tiene sentido usar los tamaños de máquina virtual correspondientes. Sin embargo, no hay ninguna regla estricta referente a las combinaciones posibles. Depende de la carga de trabajo específica del cliente.
Las configuraciones recomendadas serían:
| Tipo de máquina virtual de SAP HANA | Tipo de máquina virtual de DT 2.0 |
|---|---|
| M128ms | M64-32ms |
| M128s | M64-32ms |
| M64ms | E32sv3 |
| M64s | E32sv3 |
Son posibles todas las combinaciones de máquinas virtuales de la serie M certificadas para SAP HANA con máquinas virtuales admitidas de DT 2.0 (M64-32ms, E32sv3).
Redes de Azure y DT 2.0 de SAP HANA
Instalar DT 2.0 en una máquina virtual dedicada requiere un rendimiento de la red entre las máquinas virtuales de DT 2.0 y de SAP HANA de 10 Gb, como mínimo. Por lo tanto, es imprescindible colocar todas las máquinas virtuales dentro de la misma red virtual de Azure y habilitar las redes aceleradas de Azure.
Consulte información adicional sobre las redes aceleradas de Azure en Creación de una máquina virtual Azure con Accelerated Networking mediante la CLI de Azure.
Almacenamiento de máquinas virtuales para DT 2.0 de SAP HANA
Según las instrucciones de procedimientos recomendados de DT 2.0, el rendimiento de E/S de disco debe ser de 50 MB/s por núcleo físico, como mínimo.
Según las especificaciones de los dos tipos de máquina virtual de Azure, que son compatibles con DT 2.0, el límite máximo de rendimiento de E/S de disco para la máquina virtual es:
- E32sv3: 768 MB/s (no almacenado en caché), lo que significa una proporción de 48 MB/s por núcleo físico
- M64-32ms: 1000 MB/s (no almacenado en caché), lo que significa una proporción de 62,5 MB/s por núcleo físico
Es necesario conectar varios discos de Azure a la máquina virtual de DT 2.0 y crear una matriz redundante de discos independientes de software (seccionado) en el nivel del sistema operativo para lograr el límite máximo de rendimiento de disco por máquina virtual. Un único disco de Azure no puede proporcionar el rendimiento para alcanzar el límite máximo para las máquinas virtuales en este sentido. Se requiere Azure Premium Storage para ejecutar DT 2.0.
- Puede encontrar detalles sobre los tipos de discos de Azure disponibles en la página Selección de un tipo de disco para máquinas virtuales IaaS de Azure: discos administrados.
- Puede encontrar detalles sobre la creación de software RAID mediante mdadm en la página Configuración del software RAID en una máquina virtual Linux.
- Si desea detalles sobre la configuración de una VM Linux para crear un volumen seccionado para lograr un rendimiento máximo, consulte la página Configuración de LVM en una máquina virtual que ejecuta Linux.
Según los requisitos de tamaño, existen diferentes opciones para alcanzar el máximo rendimiento de una máquina virtual. Estas son las configuraciones de disco para volúmenes de datos posibles para cada tipo de máquina virtual de DT 2.0 a fin de alcanzar el límite superior de rendimiento para las máquinas virtuales. La máquina virtual E32sv3 debe considerarse como un nivel de entrada para las cargas de trabajo menores. En caso de que resultara no ser suficientemente rápida, podría ser necesario cambiar el tamaño de la máquina virtual a M64-32ms estándar. Como la máquina virtual M64-32ms estándar tiene mucha memoria, la carga de E/S podría no alcanzar el límite, especialmente para cargas de trabajo con muchas lecturas. Por lo tanto, podrían ser suficientes menos discos en el conjunto seccionado, según la carga de trabajo específica del cliente. Sin embargo, por seguridad, se eligieron las configuraciones de disco siguientes a fin de garantizar el máximo rendimiento:
| SKU de la máquina virtual | Configuración de disco 1 | Configuración de disco 2 | Configuración de disco 3 | Configuración de disco 4 | Configuración de disco 5 |
|---|---|---|---|---|---|
| M64-32ms | 4 x P50 -> 16 TB | 4 x P40 -> 8 TB | 5 x P30 -> 5 TB | 7 x P20 -> 3,5 TB | 8 x P15 -> 2 TB |
| E32sv3 | 3 x P50 -> 12 TB | 3 x P40 -> 6 TB | 4 x P30 -> 4 TB | 5 x P20 -> 2,5 TB | 6 x P15 -> 1,5 TB |
Especialmente en el caso de que la carga de trabajo suponga muchas lecturas, podría aumentar el rendimiento de la E/S si se activa la memoria caché de host de Azure "de solo lectura", como se recomienda para los volúmenes de datos de software de base de datos. Sin embargo, la memoria caché del disco host de Azure del registro de transacciones debe ser "none" (ninguna).
En relación con el tamaño del volumen de registro, el punto de partida recomendado es el valor heurístico del 15 % del tamaño de datos. La creación del volumen de registro puede llevarse a cabo con diferentes tipos de disco de Azure, según los requisitos de costo y rendimiento. Para el volumen de registro, se requiere una capacidad de proceso de E/S alta.
Cuando se usa el tipo de máquina virtual M64-32ms, se recomienda habilitar el Acelerador de escritura. Este Acelerador de escritura de Azure proporciona la latencia de escritura en disco óptima para el registro de transacciones (solo disponible para la serie M). Sin embargo, hay algunos elementos que deben tenerse en cuenta, como el número máximo de discos por tipo de máquina virtual. Puede encontrar detalles sobre el Acelerador de escritura en la página Acelerador de escritura de Azure.
Estos son algunos ejemplos sobre cómo cambiar el tamaño del volumen de registro:
| tipo de disco y el tamaño del volumen de datos | configuración de tipo de disco y volumen de registro 1 | configuración de tipo de disco y volumen de registro 2 |
|---|---|---|
| 4 x P50 -> 16 TB | 5 x P20 -> 2,5 TB | 3 x P30 -> 3 TB |
| 6 x P15 -> 1,5 TB | 4 x P6 -> 256 GB | 1 x P15 -> 256 GB |
Al igual que para el escalado horizontal de SAP HANA, el directorio /hana/shared tiene que compartirse entre la máquina virtual de SAP HANA y la máquina virtual de DT 2.0. Se recomienda la misma arquitectura que para la escalabilidad horizontal de SAP HANA con las máquinas virtuales, que actúan como un servidor NFS de alta disponibilidad. Con el fin de proporcionar un volumen compartido de copia de seguridad, se puede usar un diseño idéntico. Pero es decisión del cliente si se requiere una alta disponibilidad o si basta con usar una máquina virtual dedicada con suficiente capacidad de almacenamiento para que actúe como un servidor de copia de seguridad.
Vínculos a la documentación de DT 2.0
- SAP HANA Dynamic Tiering installation and update guide (Guía de instalación y actualización de Dynamic Tiering de SAP HANA)
- SAP HANA Dynamic Tiering tutorials and resources (Tutoriales y recursos de Dynamic Tiering de SAP HANA)
- SAP HANA Dynamic Tiering PoC (Poc de Dynamic Tiering de SAP HANA)
- SAP HANA 2.0 SPS 02 dynamic tiering enhancements (Mejoras de Dynamic Tiering de SAP HANA 2.0 SPS 02)
Operaciones de implementación de SAP HANA en máquinas virtuales de Azure
En las siguientes secciones se describen algunas de las operaciones relacionadas con la implementación de sistemas SAP HANA en máquinas virtuales de Azure.
Operaciones de copia de seguridad y restauración en máquinas virtuales Azure
En los documentos siguientes se describe cómo realizar la copia de seguridad y la restauración de una implementación de SAP HANA:
- SAP HANA: información general sobre copias de seguridad
- Azure Backup de SAP HANA en el nivel de archivo
- Copia de seguridad de SAP HANA basada en instantáneas de almacenamiento
Iniciar y reiniciar máquinas virtuales que contienen SAP HANA
Una característica fundamental de la nube pública de Azure es que solo se le cobra por los minutos de computación. Por ejemplo, cuando se apaga una máquina virtual que ejecuta SAP HANA, se le facturan solo los costos de almacenamiento durante ese tiempo. Otra característica está disponible cuando se especifican las direcciones IP estáticas de las máquinas virtuales de la implementación inicial. Cuando se reinicia una máquina virtual con SAP HANA, lo hace con sus direcciones IP anteriores.
Usar SAPRouter para la compatibilidad remota de SAP
Si tiene una conexión de sitio a sitio entre sus ubicaciones locales y Azure, y ejecuta componentes de SAP, es probable que ya está ejecutando SAProuter. En este caso, realice las siguientes acciones para obtener compatibilidad remota:
- Mantener la dirección IP estática y privada de la máquina virtual que hospeda SAP HANA en la configuración de SAProuter.
- Configurar el NSG de la subred que hospeda la máquina virtual de HANA para permitir el tráfico a través del puerto TCP/IP 3299.
Si se está conectando a Azure a través de Internet y no tiene un enrutador SAP para la máquina virtual con SAP HANA, tiene que instalar el componente. Instale SAProuter en una máquina virtual independiente en la subred de administración. La imagen siguiente muestra un esquema aproximado de implementación de SAP HANA sin una conexión de sitio a sitio y con SAProuter:
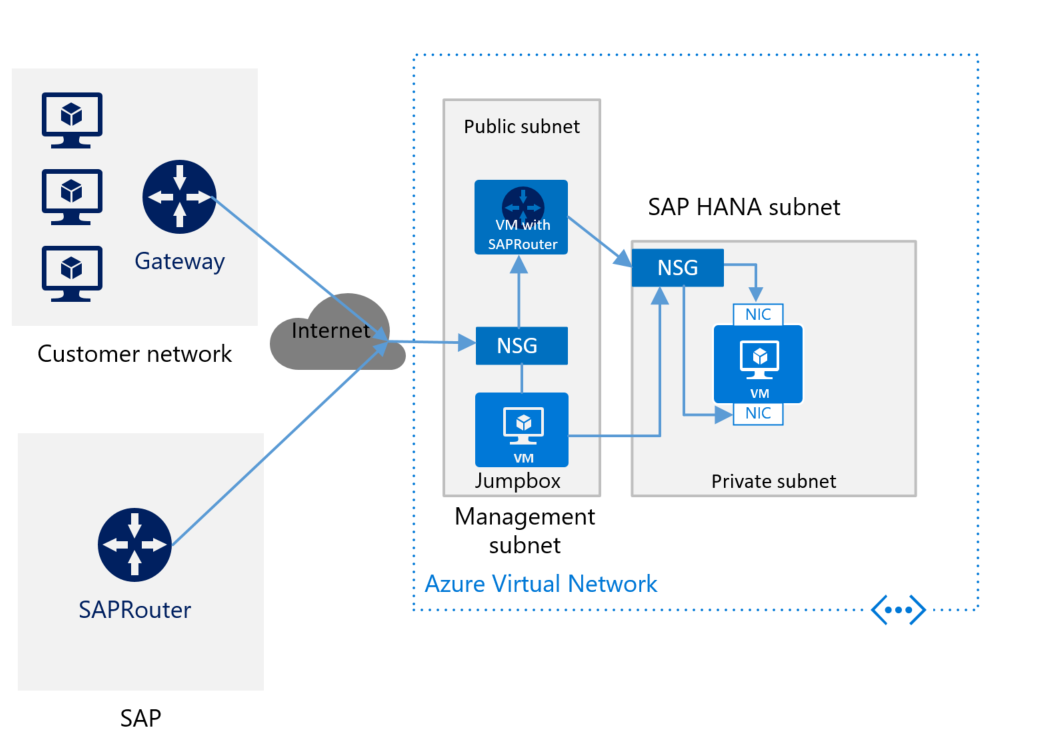
Asegúrese de instalar SAPRouter en otra máquina virtual y no en la máquina virtual de JumpBox. La máquina virtual independiente debe tener una dirección IP estática. Para conectar la instancia de SAProuter a la instancia de SAProuter hospedada en SAP, póngase en contacto con SAP para obtener una dirección IP. (La instancia de SAProuter hospedada en SAP es el equivalente de la instancia de SAProuter que se instala en la máquina virtual). Utilice la dirección IP de SAP para configurar la instancia de SAProuter. En la configuración, el único puerto necesario es el puerto TCP 3299.
Para más información sobre cómo configurar y mantener conexiones de compatibilidad remota a través de SAPRouter, consulte la documentación de SAP.
Alta disponibilidad con SAP HANA en máquinas virtuales nativas de Azure
Si ejecuta SUSE Linux Enterprise Server o Red Hat, puede establecer un clúster Pacemaker con dispositivos barrera. Puede usar los dispositivos para establecer una configuración de SAP HANA que utilice la replicación sincrónica con conmutación por error automática y replicación del sistema de HANA. Para más información, consulte la sección Pasos siguientes.
Pasos siguientes
Familiarícese con los artículos que se muestran.
- Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con nodo en espera en VM de Azure mediante Azure NetApp Files en SUSE Linux Enterprise Server
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con nodo en espera en VM de Azure mediante Azure NetApp Files en Red Hat Enterprise Linux
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con HSR y Pacemaker en máquinas virtuales de Azure en SUSE Linux Enterprise Server
- Implementación de un sistema de escalabilidad horizontal de SAP HANA con HSR y PAcemaker en máquinas virtuales de Azure en Red Hat Enterprise Linux
- Alta disponibilidad de SAP HANA en máquinas virtuales de Azure en SUSE Linux Enterprise Server
- Alta disponibilidad de SAP HANA en máquinas virtuales de Azure en Red Hat Enterprise Linux