Errores y tolerancia a errores
En el día a día, se tiende a hablar a la ligera sobre los motivos por los que se producen errores en los sistemas. Error, fallo, avería, incidencia, defecto... estos términos suelen usarse de forma indistinta. En un centro de datos, conviene que los profesionales no confundan nunca estas palabras ni usar una en lugar de otra. Aquí mostramos una definición precisa de los términos que son relevantes en las discusiones sobre tolerancia a errores:
Una incidencia es una anomalía en el diseño de un sistema que hace que su comportamiento difiera sistemáticamente de sus requisitos o expectativas. De algún modo, podría considerarse la incapacidad del sistema o del software de cumplir las expectativas, pero una incidencia no es un fallo del sistema. En realidad, muchas incidencias son producto justamente de sistemas que funcionan exactamente como se han diseñado, pero que es contrario a lo que se pretendía. La palabra clave aquí es "sistemáticamente". El comportamiento de una incidencia se puede reproducir en todas las instancias del sistema. La depuración es el acto de volver a diseñar el sistema para poner fin a las incidencias.
Un fallo es una anomalía en un sistema que hace que se comporte de forma contraria a su diseño, o que deje de funcionar por completo. En este caso, el diseño del sistema puede estar perfectamente bien, pero una implementación o instancia concreta de ese diseño no funciona como debe. Un fallo genera un comportamiento que no se espera que se reproduzca en ninguna otra instancia del sistema. El acto de eliminar un fallo se conoce como reparación. Un fallo del sistema se puede manifestar de tres maneras:
Un fallo permanente, que es una interrupción del sistema cuya causa es irreparable si el componente responsable no se sustituye completamente
Un fallo transitorio, que es una interrupción del sistema puntual que no suele repetirse y que se puede reparar o corregir in situ en contexto, o bien posiblemente desaparezca solo sin intervención alguna
Un fallo intermitente, que es una interrupción del sistema puntual que suele repetirse y que viene provocado por la degradación o diseño inadecuado de un componente, lo que puede conducir a un fallo permanente si no se corrige
Una avería es la caída por completo de un sistema en parte o en su totalidad, a menudo desencadenada por un fallo que no se ha solucionado. En este caso, el fallo es la causa y la avería, el resultado. Un sistema con tolerancia a errores es aquel que se comporta según lo previsto o de acuerdo con las expectativas del contrato de nivel de servicio (SLA) en circunstancias adversas y, por tanto, evita posibles averías ante la existencia de fallos.
Un defecto es una anomalía en la fabricación de un componente de hardware o en la creación de una instancia de un componente de software, lo que provoca un mal funcionamiento y, probablemente, la incapacidad de un sistema de implementar ese componente. Este tipo de anomalía solo se puede corregir reemplazando el componente.
Un error surge como consecuencia de una operación que produce un resultado no deseado o incorrecto. En un dispositivo informático, un error puede ser síntoma de una incidencia en el diseño o de un fallo de implementación, y puede ser un indicador eficaz de una avería inminente.
El mantenimiento de sistemas tolerantes a errores precisa de un especialista en TI, de un administrador o de un operador para comprender estos conceptos y ser conscientes de las diferencias entre ellos. Una plataforma de informática en la nube es, por definición, un sistema tolerante a errores. Está diseñada e integrada previendo posibles fallos y funciona para evitar averías en el servicio. Desde el punto de vista del diseño, esta resistencia es la esencia de lo que significa el concepto "nube". Cuando los ingenieros de telefonía usaron por primera vez una forma de nube en sus diagramas de sistemas, dicha nube representaba los componentes de la red que no era necesario ver o entender, pero cuyos niveles de servicio eran lo suficientemente confiables como para que no tuvieran que formar parte del diagrama. Quedaban, pues, tapados por una nube.
Cuando un sistema de información, como una red de TI empresarial, se pone en contacto con una plataforma en la nube pública, esa plataforma tiene la obligación de comportarse como un sistema con tolerancia a errores, pero no hace (no puede, de hecho) que el sistema que se comunica con ella tenga más tolerancia a errores de la que ya tiene. La tolerancia a errores no es una inmunidad ni garantiza la aparición de fallos en un sistema. Es más, en un sistema con tolerancia a errores pueden surgir fallos. La tolerancia a errores es más bien la capacidad de un sistema para mantener los niveles de servicio esperados cuando haya un fallo.
El propósito de cualquier sistema de información es automatizar las funciones que usan información. La tolerancia a errores solo se puede automatizar hasta cierto punto. El propio Internet, en su primera aparición como ARPANET, tenía la tolerancia a errores como uno de sus objetivos principales. Ante un desastre, las comunicaciones digitales podrían redirigirse para omitir un sistema cuya dirección ya no fuera accesible. Pero Internet no es un equipo que se mantenga por sí mismo; de hecho, ningún sistema lo es.
Para que un sistema de información logre y mantenga sus objetivos de servicio se necesita la intervención humana constantemente. Los mejores sistemas hacen que la intervención humana y la corrección sean sencillas, inmediatas y dentro de lo previsto.
Tolerancia a errores en plataformas en la nube
Las primeras plataformas de servicios en la nube eran, por decirlo de algún modo, menos tolerantes a errores de lo que pretendían sus arquitectos. Por ejemplo, el hecho de que un cliente pudiera aprovisionar recursos de servicios en exceso, como varias instancias de base de datos o memorias caché duplicadas, puso de manifiesto la ineficacia de una supervisión insuficiente, lo que a veces derivaba en la inexistencia de copias de seguridad o réplicas a las que recurrir en situaciones de desastre. Además, el aprovisionamiento en exceso contraviene uno de los principios básicos del modelo empresarial en la nube: pagar solo por los recursos que se necesitan. Una organización nunca ahorrará en gastos operativos si alquila instancias de máquina virtual de más por si acaso la máquina virtual principal deja de funcionar.
Un sistema con tolerancia a errores permite la redundancia, pero de forma sensata y dinámica, adaptándose a las necesidades y los límites de disponibilidad de los recursos en el momento concreto que sea. En la era de cliente/servidor, se hacían copias de seguridad periódicamente de todos los servidores, incluidos el almacenamiento de datos local y los volúmenes de almacenamiento de red a los que estaban conectados. "Hacer copias de seguridad de todo" se convirtió por sí mismo en un principio ético corporativo. En el momento en que los servicios de nube pública comenzaron a ser prácticos y asequibles, las organizaciones empezaron a usarlos para "hacer copias de seguridad de todo". Con el tiempo, se dieron cuenta de que la nube hacía más que perpetuar los métodos anteriores. Para empezar, las plataformas en la nube podían diseñarse con tolerancia a errores, en vez de convertirlas en tolerantes a errores una vez implementadas.
Técnicas reactivas
Independientemente de la minuciosidad con la que un sistema se haya diseñado, la mayor parte de la tolerancia a errores dependerá de cómo de adecuada sea la respuesta del sistema y de las personas que lo administran ante la primera evidencia de un error. Aquí se enumeran algunas de las técnicas reactivas que las organizaciones usan para mitigar fallos cuando estos se producen.
Migración de trabajos no preferente
La técnica de migración de trabajos no preferente impide que el host de una carga de trabajo que parece haber sufrido un fallo se reasigne para hospedar la misma carga de trabajo. Esto protege el "trabajo", aunque podría dificultar al sistema la recopilación de instancias repetidas de un error como prueba de un fallo, lo que podría ser más fácil de controlar con una ruta de acceso bien registrada.
Replicación de tareas
Muchos sistemas de información distribuidos ejecutan varias instancias (o en la orquestación de Kubernetes, réplicas) de una tarea a la vez. Los sistemas de administración basados en directivas pueden estar ajustados para replicar una tarea si se produce un fallo de sistema aparente o sospechoso.
Puntos de control y puntos de restauración
En su forma más sencilla, los puntos de control y los puntos de restauración conllevan tomar instantáneas de un sistema en varios momentos en el tiempo y permitir que los administradores "reviertan" a un momento determinado en el tiempo, en caso de que sea necesario realizar una restauración. Esta estrategia es más complicada cuando hay transacciones de por medio, por ejemplo, cuando una aplicación realiza dos o más acciones en una base de datos y todas ellas deben realizarse correctamente o fallar como un todo (una "transacción"). Un ejemplo común es una aplicación que acredita dinero de una cuenta mientras lo adeuda de otra. Estas operaciones deben realizarse correctamente o fallar como un todo para evitar la creación o destrucción de recursos financieros.
En un sistema de recuperación de puntos de control de transacción, los registros recuperables de las transacciones se almacenan en memoria en un árbol de procesos. En determinados momentos durante una transacción, los recursos de memoria que el sistema usa se replican y depositan en un grupo de restauración. En caso de que un análisis de registros indique un error, posiblemente debido al software, el árbol de procesos se bifurca, el estado de la transacción vuelve a un punto anterior y se intenta llevar a cabo una transacción nueva. Si la nueva transacción es más correcta que la errónea (por ejemplo, si se supera sin trabas una prueba de corrección de errores), la rama del proceso anterior se elimina y se sigue la nueva rama a partir de ese punto en el árbol. Es lo que los ingenieros llaman cambio de contexto.1
Una versión sofisticada de esta metodología implementa un sistema de seguimiento en el árbol de procesos, de modo que cuando se vuelva a producir un error, el sistema pueda reproducir el proceso hacia atrás y detectar la causa del error. Así, puede seleccionar un punto de restauración (o "punto de rescate") adecuado antes de que el error se desencadene.[2]
Otra implementación, denominada SGuard, fue creada por investigadores de la Universidad de Washington y Microsoft Research para el procesamiento con tolerancia a errores de grandes flujos de datos. SGuard aprovecha el sistema de archivos distribuido de Hadoop (HDFS) para programar la escritura simultánea de varias instantáneas de flujos de datos durante el procesamiento. Estas instantáneas se dividen en partes más pequeñas según sea necesario, a la vez que subdivide el procesamiento de secuencias en segmentos más pequeños. Los puntos de control se almacenan en HDFS. Este sistema tiene a virtud de mantener un registro de las transacciones de datos de la secuencia, así como varias réplicas viables de los datos de secuencia, en ubicaciones muy distribuidas. Aunque implementar SGuard requiere un trabajo de preparación considerable, se sigue considerando una técnica de tolerancia a errores reactiva, ya que su funcionamiento principal se activa como respuesta a un evento de error.3
Técnicas proactivas
Una técnica de tolerancia a errores proactiva se despliega antes de que se conozca la existencia de un error. Se busca ser preventivo, pero en la implementación moderna esto es más una metodología que un mantra. Estas son algunas de las técnicas que actualmente se usan las plataformas modernas en la nube.
Replicación de recursos
La clave de una estrategia de replicación de recursos eficaz probablemente no se reduzca exclusivamente a "hacer copias de seguridad de todo". Un analista de sistemas debe ser capaz de determinar qué recursos de un sistema (por ejemplo, un motor de base de datos, un servidor web o un enrutador de red virtual) pueden restaurarse tras un evento de error y cuáles pueden ser irrecuperables. Una replicación inteligente puede ser la primera línea de defensa de un sistema tolerante a errores.
Hay cuatro estrategias comunes que se usan para implementar la replicación de recursos, ilustrados en la Figura 1:
Replicación activa: todos los recursos replicados están activos a la vez, y cada uno de ellos mantiene individualmente su propio estado; esto es, sus propios datos locales que lo hacen funcional. Esta propiedad significa que todos los recursos replicados de una clase reciben la solicitud de un cliente y todos ellos procesan una respuesta, pero será la respuesta del recurso principal designado en esa clase la que se envíe al cliente. Si se produce un error en un recurso, incluido el nodo principal, otro nodo se designa como su sucesor. Este sistema requiere que el procesamiento entre el nodo principal y el de réplica sea determinista, para actuar tanto de manera conjunta como siguiendo un itinerario establecido.
Replicación semiactiva: la replicación semiactiva es similar a la replicación activa, con la diferencia de que los nodos de réplica pueden procesar solicitudes de forma no determinista, o no conjuntamente con el nodo principal. Las salidas de los recursos secundarios se suprimen y registran y están listas para intercambiarse en cuanto se produzca un error en el recurso principal.
Replicación pasiva: el nodo de recursos principal es el único que procesa solicitudes, mientras que las otras (las réplicas) mantienen su estado y esperan a ser designadas como principales si se produce un error. El recurso principal con el que el cliente está en contacto transmite cualquier cambio de estado a todas las réplicas. Todos los originales y las réplicas que pertenecen a una clase se consideran "miembros" de un grupo, y un miembro se puede quitar del grupo si parece que se ha producido un error en él (aun cuando el error no se haya producido). Existe la posibilidad de que se produzcan latencias o una degradación de calidad de servicio durante un evento de error, aunque la replicación pasiva consume menos recursos mientras el funcionamiento es normal.
Replicación semipasiva: esta metodología tiene el mismo patrón de relación que la replicación pasiva, salvo que no hay ningún recurso principal permanente. En su lugar, cada recurso recibe a cambio el rol de coordinador, con la coordinación de turnos establecida por un modelo de paso de tokens denominado paradigma de rotación de coordinadores.
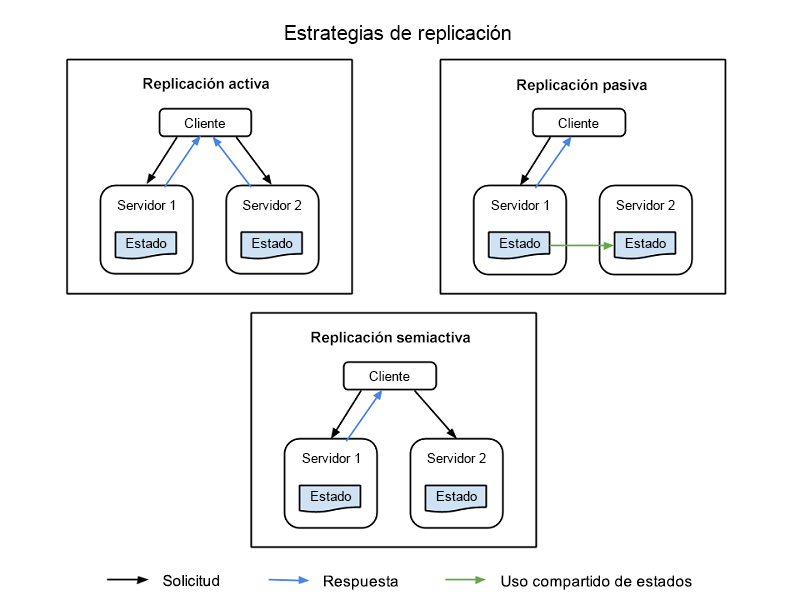
Figura 1: Nodos de cliente, nodos principales y nodos de réplica en un sistema de información replicado
Equilibrio de carga
Los equilibradores de carga distribuyen las solicitudes de varios clientes entre varios servidores que ejecutan la misma aplicación, con lo que la carga de trabajo se distribuye y se reduce la sobrecarga en los componentes del sistema. Un efecto secundario positivo de usar un equilibrador de carga es que algunos evitan automáticamente que el tráfico pase por servidores que no responden, lo que reduce las posibilidades de que se produzcan errores. En las versiones más modernas, en las que el software está diseñado para distribuirse a través de una plataforma en la nube (por ejemplo, microservicios), las cargas de trabajo se subdividen en funciones independientes que se distribuyen a través de procesadores del lado servidor, con el objetivo de lograr una distribución igualitaria y unos niveles de uso moderados.
La virtualización (el ingrediente clave de la informática en la nube) permite una distribución más igualitaria de las cargas de trabajo entre los procesadores, por lo que se pueden mover al procesador físico que pueda hacer el mejor uso posible de ellas. La inclusión en contenedores mejora esta técnica al separar las cargas de trabajo virtualizadas de los procesadores virtuales, de modo que residen en el nodo de servidor que tenga el sistema operativo mejor preparado para dichas cargas. Este principio es clave para la orquestación de cargas de trabajo, lo que se pone de manifiesto en sistemas como Kubernetes.
Rejuvenecimiento y reconfiguración
En los sistemas de información en los que las instancias de software se implementan durante largos períodos de tiempo, puede que sea necesario reiniciar el software. Aunque algunas plataformas en la nube anteriores intentaban muestrear los niveles de servicio de las instancias de software a lo largo del tiempo para determinar cuándo era necesario reiniciar, en versiones posteriores se ha recurrido a un método más sencillo consistente en programar reinicios periódicos. Durante estas fases de reinicio, los archivos de configuración se pueden ajustar automáticamente para que tengan en cuenta el cambio de circunstancias del sistema, o para prever un posible error tras el inicio.
Migración preferente
Cuando la virtualización pasó a ser básica en los centros de datos, se propuso usar la migración preferente como método para equilibrar el "estrés" sufrido por el hardware de servidor a causa de la rotación de asignaciones de las cargas de trabajo en los procesadores, quizás a modo de distribución equilibrada. Las plataformas en la nube redistribuyen las cargas de trabajo a través de la infraestructura virtual con una frecuencia suficiente tal que ha hecho que este método sea totalmente innecesario. Con todo, el asunto ha saltado a la palestra de nuevo en algunas discusiones recientes junto con los métodos con inteligencia artificial para predecir el estrés de las cargas de trabajo en diversos sistemas de información. Estos sistemas podrían elaborar sus propias reglas para desviar las cargas de trabajo más críticas de los nodos de servidor con una mayor predisposición a generar errores.
Recuperación automática
En un sistema de información ampliamente distribuido, como una red de entrega de contenido (CDN) o una plataforma de redes sociales, las funciones de los servidores individuales pueden estar distribuidas por varias direcciones, normalmente en ubicaciones o centros de datos diferentes. Una red de recuperación automática sondea las distintas conexiones en intervalos regulares (como una plataforma de administración de rendimiento) para conocer el flujo de tráfico y la capacidad de respuesta. Cuando haya una discrepancia de rendimiento, los enrutadores pueden desviar las solicitudes para que no pasen por los componentes sospechosos y, en última instancia, detener el flujo de tráfico que atraviesa dichos componentes. Tras ello, se puede probar el estado operativo de ese componente en busca de indicios de error, una vez hecho lo cual el componente se puede reiniciar para comprobar si el comportamiento persiste. Solo se devolverá a un estado activo si los diagnósticos no revelan la probabilidad de que se produzca un fallo. Este tipo de capacidad de respuesta transaccional automatizada es un ejemplo moderno de recuperación automática en centros de datos altamente distribuidos.4
Programación de procesos basada en trueque
Una plataforma en la nube (que incluye servicios públicos basados en la nube, pero que también puede incluir la infraestructura local) es capaz como nadie de informar de su propio estado. Cuando Amazon comenzó a implementar un modelo de SaaS revisado en 2009, sus ingenieros diseñaron un concepto denominado programación de instancias puntuales. En este sistema, un proxy silencioso que actúa en nombre del cliente avisa de los requisitos de recursos necesarios para un trabajo determinado y difunde una especie de solicitud de ofertas, concretamente desde los nodos de servidor a través de la plataforma en la nube. Cada nodo informa de su propia capacidad para satisfacer los requisitos de la oferta en términos de tiempo y recursos consumidos. La oferta menos costosa se hace con el contrato y se designa como la instancia puntual para el trabajo en cuestión. Esta forma de programación es una opción actualmente en Amazon Elastic Compute Cloud.5
Referencias
Ioana, Cristescu. A Record-and-Replay Fault Tolerant System for Multithreading Applications. Technical University of Cluj Napoca. http://scholar.harvard.edu/files/cristescu/files/paper.pdf.
Sidiroglou, Stelios, et al.ASSURE: Automatic Software Self-healing Using Rescue Points (ASSURE: Recuperación automática de software automático mediante puntos de rescate). Columbia University, 2009.
Kwon Yong-Chul, et al. Fault-tolerant Stream Processing Using a Distributed, Replicated File System (Procesamiento de flujos tolerante a errores mediante un sistema de archivos replicado y distribuido). Association for Computing Machinery, 2008. https://db.cs.washington.edu/projects/moirae/moirae-vldb08.pdf.
Yang, Chen. Checkpoint and Restoration of Micro-service in Docker Containers (Punto de control y restauración de microservicios en contenedores de Docker). School of Information Security Engineering, Shanghai Jiao Tong University, China, 2015. https://download.atlantis-press.com/article/25844460.pdf.
Amazon Web Services, Inc. Spot Instance Requests (Solicitudes de instancia de Spot), en Amazon, 2020. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html.